WildBox: A Dataset and Benchmark for Aerial Monocular 3D Detection of African Savanna Wildlife
Pith reviewed 2026-06-26 14:39 UTC · model grok-4.3
The pith
A new drone dataset for African wildlife shows that monocular 3D detection fails completely in zero-shot settings, with depth estimation as the dominant error source.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Open-vocabulary 2D foundation models achieve usable zero-shot wildlife localisation at 50.55 AP@50, but zero-shot 3D detection collapses to 0.00 AP across architectures and input conditions; fine-tuning on WildBox recovers 8.68 AP-BEV@0.50 and 13.17 AP3D macro, with depth accounting for 84 percent of normalised Hausdorff distance after training and over 99 percent in zero-shot.
What carries the argument
WildBox dataset of 237,505 scale-normalised 3D bounding box annotations in per-segment camera frame, used to benchmark zero-shot versus fine-tuned performance and isolate depth as the primary failure mode.
If this is right
- Fine-tuning on domain-specific aerial data is required to obtain any usable 3D detections for savanna wildlife.
- Depth estimation errors drive nearly all of the 3D bounding-box inaccuracy both before and after training.
- A coarse-to-fine curriculum that first merges similar classes improves subclass performance with lower total compute.
Where Pith is reading between the lines
- General 3D models trained on ground-level or urban scenes do not transfer directly to small, distant animals viewed from above in natural terrain.
- Future work on aerial 3D perception for conservation will need targeted improvements in monocular depth for distant, low-contrast objects.
- The released video splits and checkpoints can support development of models that maintain identity across frames for population tracking.
Load-bearing premise
The 237,505 3D bounding box annotations accurately reflect the true 3D positions and extents of the wildlife instances in the drone footage.
What would settle it
A zero-shot method achieving non-zero AP on the WildBox test set without fine-tuning would contradict the reported collapse of 3D detection performance.
Figures

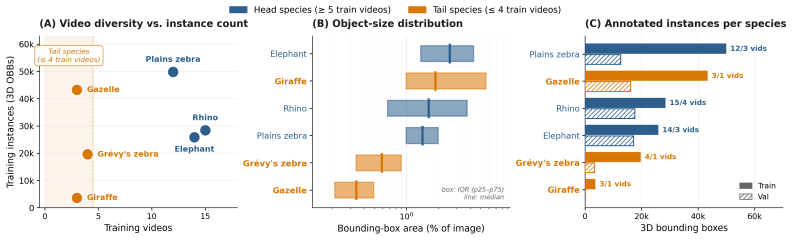
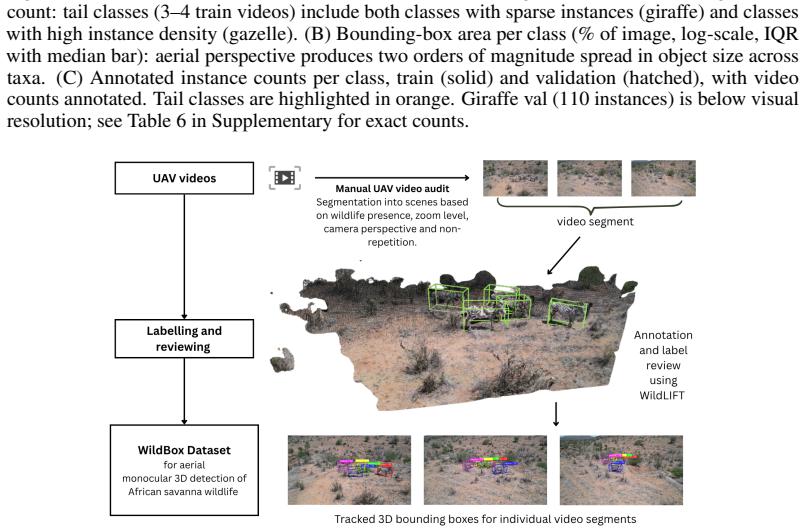


read the original abstract
We introduce WildBox, a dataset and benchmark for monocular 3D detection of wildlife from drone video, comprising 237,505 3D bounding box annotations across seven African savanna species grouped into six benchmark classes. Annotations follow a KITTI/Omni3D-compatible format in a per-segment scale-normalised camera frame, with instance identities maintained across each segment. We evaluate two open-vocabulary monocular 3D architectures, OVMono3D-LIFT and DetAny3D, under zero-shot, ground-truth 2D box prompt, and supervised fine-tuning protocols. Open-vocabulary 2D foundation models provide usable zero-shot wildlife localisation (50.55 AP@50), but zero-shot 3D detection collapses to 0.00 AP across both architectures and every 2D-input condition tested, including ground-truth 2D box prompts, thus isolating the failure to the 3D stage. Fine-tuning on WildBox recovers performance to 8.68 +/- 0.47 AP-BEV@0.50 and 13.17 +/- 0.69 AP3D macro. Depth contributes 84% of normalised Hausdorff distance after fine-tuning and over 99% in zero-shot, identifying monocular aerial depth as the dominant open problem in this regime. A coarse-to-fine curriculum, i.e. pretraining on a merged zebra class before fine-tuning on the Grevy's/plains split, improves macro 3D performance with less total compute, with the largest gains on the two zebra subclasses. WildBox is released with video-level splits, evaluation code, and baseline checkpoints to enable progress in 3D wildlife perception from drone video.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WildBox, a dataset with 237,505 3D bounding box annotations for seven African savanna wildlife species from drone footage, formatted in a per-segment scale-normalised camera frame compatible with KITTI/Omni3D. It evaluates open-vocabulary 3D detectors OVMono3D-LIFT and DetAny3D in zero-shot and fine-tuned settings, reporting that zero-shot 3D detection yields 0.00 AP even with ground-truth 2D prompts while 2D detection achieves 50.55 AP@50, and fine-tuning reaches 8.68 AP-BEV@0.50 and 13.17 AP3D. Depth is identified as contributing 84% of Hausdorff error post-fine-tuning and >99% in zero-shot, with a curriculum pretraining on merged zebra class improving results.
Significance. If the 3D annotations are reliable, the paper makes a significant contribution by releasing a large-scale benchmark for aerial monocular 3D wildlife detection, an underexplored domain, and by empirically isolating monocular depth estimation as the key bottleneck. The public release of splits, code, and checkpoints supports reproducibility and future work. The curriculum learning result is a practical finding.
major comments (1)
- [Dataset Construction / Annotation Protocol] Dataset Construction / Annotation Protocol: The 237,505 per-segment scale-normalised 3D annotations are load-bearing for every quantitative claim, including the isolation of zero-shot failure to the 3D stage (0.00 AP even with GT 2D prompts) and the attribution of 84–99% of normalised Hausdorff distance to depth. No independent validation against known species dimensions, SfM, stereo, or any other 3D reference is provided; systematic error in the scale-normalisation step would directly inflate the reported depth fraction and undermine the central conclusion.
minor comments (2)
- [§5 (or Results)] §5 (or Results): The reported standard deviations on fine-tuned metrics (e.g., 8.68 +/- 0.47) should state the number of independent runs or random seeds used.
- [Evaluation Protocol] Evaluation code release is a strength; ensure the released splits and metrics exactly reproduce the zero-shot 0.00 AP and fine-tuned numbers reported in Tables 2–4.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for emphasizing the centrality of annotation reliability to our claims. We address the single major comment below.
read point-by-point responses
-
Referee: [Dataset Construction / Annotation Protocol] Dataset Construction / Annotation Protocol: The 237,505 per-segment scale-normalised 3D annotations are load-bearing for every quantitative claim, including the isolation of zero-shot failure to the 3D stage (0.00 AP even with GT 2D prompts) and the attribution of 84–99% of normalised Hausdorff distance to depth. No independent validation against known species dimensions, SfM, stereo, or any other 3D reference is provided; systematic error in the scale-normalisation step would directly inflate the reported depth fraction and undermine the central conclusion.
Authors: We agree that the absence of independent validation (e.g., against literature species dimensions, SfM, or stereo) is a genuine limitation of the current manuscript and that systematic bias in per-segment scale normalisation could affect the reported depth-error fractions. The annotations were generated by domain experts who applied average species body dimensions drawn from wildlife biology references to normalise scale within each video segment, with frame-to-frame consistency enforced via instance tracking; however, no external 3D reference data were collected during the drone flights. We will revise the manuscript to (1) expand the annotation-protocol subsection with the exact normalisation procedure and any inter-annotator consistency checks performed, (2) explicitly discuss the lack of independent 3D validation as a limitation, and (3) add a note that future releases could incorporate such validation where possible. This revision does not alter the reported numbers but improves transparency around their provenance. revision: yes
Circularity Check
Empirical dataset and benchmark paper with no derivations or self-referential predictions
full rationale
The paper introduces WildBox as a new dataset with 237505 annotations and reports empirical model evaluations (zero-shot AP=0.00, fine-tuned AP-BEV@0.50=8.68) using standard metrics on released code. No equations, fitted parameters, or predictions are claimed; results are direct measurements against the provided ground truth. No self-citations are load-bearing for any derivation, and the annotation process is presented as input rather than derived output. This is a standard empirical benchmark contribution with independent external metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-segment scale normalisation
axioms (1)
- domain assumption 3D bounding box annotations can be reliably produced from monocular drone video for moving wildlife
Reference graph
Works this paper leans on
-
[1]
WildDepth: A Multimodal Dataset for 3D Wildlife Perception and Depth Estimation, 2026
Muhammad Aamir, Naoya Muramatsu, Sangyun Shin, Matthew Wijers, Jia-Xing Zhong, Xinyu Hou, Amir Patel, Andrew Loveridge, and Andrew Markham. WildDepth: A Multimodal Dataset for 3D Wildlife Perception and Depth Estimation, 2026
2026
-
[2]
Impact of drone disturbances on wildlife: A review.Drones, 9(4):311, 2025
Saadia Afridi, Lucie Laporte-Devylder, Guy Maalouf, Jenna M Kline, Samuel G Penny, Kasper Hlebowicz, Dylan Cawthorne, and Ulrik Pagh Schultz Lundquist. Impact of drone disturbances on wildlife: A review.Drones, 9(4):311, 2025
2025
-
[3]
SurFree: a fast surrogate-free black-box attack,
Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jianing Wei, and Matthias Grundmann. Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7818–7827, June 2021. doi: 10.1109/CVPR46437.2021.00773. URL https://ieeexplore. ieee.org/do...
-
[4]
Drones in ecology: Ten years back and forth.BioScience, 75(8):664–680, June 2025
Karen Anderson, Felipe Gonzalez, and Kevin J Gaston. Drones in ecology: Ten years back and forth.BioScience, 75(8):664–680, June 2025. ISSN 1525-3244. doi: 10.1093/biosci/biaf069
-
[5]
Arkitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. Arkitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data. InNeurIPS, 2021. URLhttps://arxiv.org/pdf/2111.08897.pdf
Pith/arXiv arXiv 2021
-
[6]
Fast Image Reconstruction with an Event Camera
Elizabeth Bondi, Raghav Jain, Palash Aggrawal, Saket Anand, Robert Hannaford, Ashish Kapoor, Jim Piavis, Shital Shah, Lucas Joppa, Bistra Dilkina, and Milind Tambe. BIRDSAI: A Dataset for Detection and Tracking in Aerial Thermal Infrared Videos. In2020 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1736–1745, Snowmass Village, CO,...
-
[7]
Synthetic Data-Based Detection of Zebras in Drone Imagery
Elia Bonetto and Aamir Ahmad. Synthetic Data-Based Detection of Zebras in Drone Imagery. In2023 European Conference on Mobile Robots (ECMR), pages 1–8, September 2023. doi: 10.1109/ECMR59166.2023.10256293. URL https://ieeexplore.ieee.org/document/ 10256293
-
[8]
Elia Bonetto, Chenghao Xu, and Aamir Ahmad. GRADE: Generating Realistic and Dynamic Environments for robotics research with Isaac Sim.The International Journal of Robotics Research, 45(2):204–232, February 2026. ISSN 0278-3649. doi: 10.1177/02783649251346211. URLhttps://doi.org/10.1177/02783649251346211
-
[9]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Garrick Brazil, Abhinav Kumar, Julian Straub, Nikhila Ravi, Justin Johnson, and Georgia Gkioxari. Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13154–13164, Vancouver, BC, Canada, June 2023. IEEE. ISBN 979-8-3503-0129-8. doi: 10.1109/CVPR52729.2023.01264
-
[10]
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A Multimodal Dataset for Autonomous Driving. In2020 IEEE/CVF Conference on Computer Vision and 10 Pattern Recognition (CVPR), pages 11618–11628, Seattle, W A, USA, June 2020. IEEE. ISBN 978-1-7281-7...
-
[11]
Argoverse: 3D Tracking and Forecasting With Rich Maps
Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jagjeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, and James Hays. Argoverse: 3D Tracking and Forecasting With Rich Maps. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8748–8757, 2019
2019
-
[12]
WildLive: Near Real-time Visual Wildlife Tracking onboard UA Vs, May 2025
Nguyen Ngoc Dat, Tom Richardson, Matthew Watson, Kilian Meier, Jenna Kline, Sid Reid, Guy Maalouf, Duncan Hine, Majid Mirmehdi, and Tilo Burghardt. WildLive: Near Real-time Visual Wildlife Tracking onboard UA Vs, May 2025
2025
-
[13]
Timothy W. Dunn, Jesse D. Marshall, Kyle S. Severson, Diego E. Aldarondo, David G. C. Hildebrand, Selmaan N. Chettih, William L. Wang, Amanda J. Gellis, David E. Carlson, Dmitriy Aronov, Winrich A. Freiwald, Fan Wang, and Bence P. Ölveczky. Geometric deep learning enables 3D kinematic profiling across species and environments.Nature Methods, 18(5): 564–57...
-
[14]
Isla Duporge, Maksim Kholiavchenko, Roi Harel, Scott Wolf, Daniel I. Rubenstein, Margaret C. Crofoot, Tanya Berger-Wolf, Stephen J. Lee, Julie Barreau, Jenna Kline, Michelle Ramirez, and Charles V . Stewart. BaboonLand Dataset: Tracking Primates in the Wild and Automating Behaviour Recognition from Drone Videos.International Journal of Computer Vision, 13...
-
[15]
Are we ready for autonomous driving? The KITTI vision benchmark suite,
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? The KITTI vision benchmark suite. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361, June 2012. doi: 10.1109/CVPR.2012.6248074
-
[16]
William Grolleau, Achraf Chaouch, Astrid Sabourin, Guillaume Lapouge, and Catherine Achard. MOO: A Multi-view Oriented Observations Dataset for Viewpoint Analysis in Cattle Re- Identification, March 2026. URL http://arxiv.org/abs/2603.04314. arXiv:2603.04314 [cs]
Pith/arXiv arXiv 2026
-
[17]
Rui Huang, Henry Zheng, Yan Wang, Zhuofan Xia, Marco Pavone, and Gao Huang. Training an Open-V ocabulary Monocular 3D Detection Model without 3D Data.Advances in Neural In- formation Processing Systems, 37:72145–72169, December 2024. doi: 10.52202/079017-2303
-
[18]
Daniel Joska, Liam Clark, Naoya Muramatsu, Ricardo Jericevich, Fred Nicolls, Alexander Mathis, Mackenzie W. Mathis, and Amir Patel. Acinoset: A 3d pose estimation dataset and baseline models for cheetahs in the wild. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13901–13908, 2021. doi: 10.1109/ICRA48506.2021.9561338
-
[19]
KABR: In-Situ Dataset for Kenyan Animal Behavior Recognition from Drone Videos
Maksim Kholiavchenko, Jenna Kline, Michelle Ramirez, Sam Stevens, Alec Sheets, Reshma Babu, Namrata Banerji, Elizabeth Campolongo, Matthew Thompson, Nina Van Tiel, Jackson Miliko, Eduardo Bessa, Isla Duporge, Tanya Berger-Wolf, Daniel Rubenstein, and Charles Stewart. KABR: In-Situ Dataset for Kenyan Animal Behavior Recognition from Drone Videos. In2024 IE...
-
[20]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment Anything, April 2023. URL http://arxiv.org/abs/2304.02643. arXiv:2304.02643 [cs]
Pith/arXiv arXiv 2023
-
[21]
Jenna Kline, Maksim Kholiavchenko, Samuel Stevens, Nina van Tiel, Alison Zhong, Namrata Banerji, Alec Sheets, Sowbaranika Balasubramaniam, Isla Duporge, Matthew Thompson, Elizabeth Campolongo, Jackson Miliko, Neil Rosser, Tanya Berger-Wolf, Charles V . Stewart, and Daniel I. Rubenstein. kabr-tools: Automated framework for multi-species behavioral monitori...
arXiv 2025
-
[22]
MMLA: Multi-Environment, Multi-Species, Low-Altitude Drone Dataset, October 2025
Jenna Kline, Samuel Stevens, Guy Maalouf, Camille Rondeau Saint-Jean, Dat Nguyen Ngoc, Majid Mirmehdi, David Guerin, Tilo Burghardt, Elzbieta Pastucha, Blair Costelloe, Matthew Watson, Thomas Richardson, and Ulrik Pagh Schultz Lundquist. MMLA: Multi-Environment, Multi-Species, Low-Altitude Drone Dataset, October 2025
2025
-
[23]
Kabr raw videos: Unprocessed drone footage for kenyan animal behavior anal- ysis (revision d002bb6), 2026
Jenna Kline, Maksim Kholiavchenko, Michelle Ramirez, Samuel Stevens, Alec Sheets, Reshma Ramesh Babu, Namrata Banerji, Elizabeth Campolongo, Matthew Thompson, Nina Van Tiel, Jackson Miliko, Neil Rosser, Isla Duporge, Charles Stewart, Tanya Berger-Wolf, and Daniel Rubenstein. Kabr raw videos: Unprocessed drone footage for kenyan animal behavior anal- ysis ...
2026
-
[24]
Animal Ecol.92, 1357–1371, DOI: 10.1111/1365-2656.13904 (2023)
Benjamin Koger, Adwait Deshpande, Jeffrey T. Kerby, Jacob M. Graving, Blair R. Costel- loe, and Iain D. Couzin. Quantifying the movement, behaviour and environmental con- text of group-living animals using drones and computer vision.Journal of Animal Ecol- ogy, 92(7):1357–1371, 2023. ISSN 1365-2656. doi: 10.1111/1365-2656.13904. URL https://onlinelibrary....
-
[25]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection, July 2024
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection, July 2024. URL http://arxiv.org/ abs/2303.05499. arXiv:2303.05499 [cs]
Pith/arXiv arXiv 2024
-
[26]
Ulrik Pagh Schultz Lundquist, Saadia Afridi, Clément Berthelot, Nguyen Ngoc Dat, Kasper Hlebowicz, Elena Iannino, Lucie Laporte-Devylder, Guy Maalouf, Giacomo May, Kilian Meier, Constanza A. Molina Catricheo, Edouard G. A. Rolland, Camille Rondeau Saint-Jean, Vandita Shukla, Tilo Burghardt, Anders Lyhne Christensen, Blair R. Costelloe, Matthijs Damen, And...
-
[27]
Marshall, Ugne Klibaite, Amanda Gellis, Diego E
Jesse D. Marshall, Ugne Klibaite, Amanda Gellis, Diego E. Aldarondo, Bence P. Ölveczky, and Timothy W. Dunn. The PAIR-R24M Dataset for Multi-animal 3D Pose Estimation, Novem- ber 2021. URL https://www.biorxiv.org/content/10.1101/2021.11.23.469743v1. Pages: 2021.11.23.469743 Section: New Results
-
[28]
POLO – Point- Based, Multi-class Animal Detection
Giacomo May, Emanuele Dalsasso, Benjamin Kellenberger, and Devis Tuia. POLO – Point- Based, Multi-class Animal Detection. InComputer Vision – ECCV 2024 Workshops: Mi- lan, Italy, September 29–October 4, 2024, Proceedings, Part II, pages 169–177, Berlin, Heidelberg, September 2024. Springer-Verlag. ISBN 978-3-031-92386-9. doi: 10.1007/ 978-3-031-92387-6_12...
-
[29]
Chao Mou, Tengfei Liu, Chengcheng Zhu, and Xiaohui Cui. WAID: A Large-Scale Dataset for Wildlife Detection with Drones.Applied Sciences, 13(18):10397, January 2023. ISSN 2076-3417. doi: 10.3390/app131810397
-
[30]
Chao Mou, Chengcheng Zhu, Tengfei Liu, and Xiaohui Cui. A novel efficient wildlife detecting method with lightweight deployment on UA Vs based on YOLOv7.IET Im- age Processing, 18(5):1296–1314, 2024. ISSN 1751-9667. doi: 10.1049/ipr2.13027. URL https://onlinelibrary.wiley.com/doi/abs/10.1049/ipr2.13027. _eprint: https://ietresearch.onlinelibrary.wiley.com...
-
[31]
Wild- Pose: A Long-Range 3D Wildlife Motion Capture System, March 2024
Naoya Muramatsu, Sangyun Shin, Qianyi Deng, Andrew Markham, and Amir Patel. Wild- Pose: A Long-Range 3D Wildlife Motion Capture System, March 2024. URL https://www. biorxiv.org/content/10.1101/2024.02.05.578861v3. Pages: 2024.02.05.578861 Sec- tion: New Results. 12
-
[32]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hemal Naik, Alex Hoi Hang Chan, Junran Yang, Mathilde Delacoux, Iain D. Couzin, Fu- mihiro Kano, and Máté Nagy. 3D-POP - An Automated Annotation Approach to Facilitate Markerless 2D-3D Tracking of Freely Moving Birds with Marker-Based Motion Capture. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21274–21284, Vancouve...
-
[33]
BuckTales: A multi-UA V dataset for multi-object tracking and re-identification of wild antelopes
Hemal Naik, Junran Yang, Dipin Das, Margaret C Crofoot, Akanksha Rathore, and Vivek Hari Sridhar. BuckTales: A multi-UA V dataset for multi-object tracking and re-identification of wild antelopes. InProceedings of the 38th International Conference on Neural Information Processing Systems, volume 37 ofNIPS ’24, pages 81992–82009, Red Hook, NY , USA, Decemb...
2024
-
[34]
The Aerial Elephant Dataset: A New Public Benchmark for Aerial Object Detection
Johannes Naude and Deon Joubert. The Aerial Elephant Dataset: A New Public Benchmark for Aerial Object Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 48–55, 2019
2019
-
[35]
DINOv2: Learning Robust Visual Features without Supervision, February 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Ass- ran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patric...
Pith/arXiv arXiv 2024
-
[36]
Advancing animal behaviour research using drone technology.Animal Behaviour, 222: 123147, 2025
Lucia Pedrazzi, Hemal Naik, Chris Sandbrook, Miguel Lurgi, Ines Fürtbauer, and Andrew J King. Advancing animal behaviour research using drone technology.Animal Behaviour, 222: 123147, 2025
2025
-
[37]
In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. UniDepth: Universal Monocular Metric Depth Estimation. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10106–10116, Seattle, W A, USA, June 2024. IEEE. ISBN 979-8-3503-5300-6. doi: 10.1109/CVPR52733.2024.00963. URLh...
-
[38]
Learning Transferable Visual Models From Natural Language Supervision, February 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision, February 2021
2021
-
[39]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, 2021. URL https://arxiv.org/pdf/2011. 02523.pdf
2021
-
[40]
Edouard G. A. Rolland, Kilian Meier, Kasper A. R. Grøntved, Lucie Laporte-Devylder, Guy Maalouf, Ulrik P. S. Lundquist, and Anders L. Christensen. Drone swarms for multi-perspective monitoring of large mammals in their natural habitats: Deployment and field trials. InAdvances in Practical Applications of Agents, Multi-Agent Systems, and Computational Soci...
-
[41]
Lukas Schad and Julia Fischer. Opportunities and risks in the use of drones for studying animal behaviour.Methods in Ecology and Evolution, 14(8):1864–1872, 2023. ISSN 2041-210X. doi: 10.1111/2041-210X.13922. URL https://onlinelibrary.wiley.com/doi/abs/10. 1111/2041-210X.13922
-
[42]
The Role of Photogrammetry for a Sustainable World
Vandita Shukla, Luca Morelli, Fabio Remondino, Andrea Micheli, Devis Tuia, and Benjamin Risse. Towards Estimation of 3D Poses and Shapes of Animals from 13 Oblique Drone Imagery.The International Archives of the Photogrammetry, Re- mote Sensing and Spatial Information Sciences, XLVIII-2-2024:379–386, June 2024. ISSN 1682-1750. doi: 10.5194/isprs-archives-...
work page doi:10.5194/isprs-archives-xlviii-2-2024-379-2024 2024
-
[43]
WildLIFT: Lifting monocular drone video to 3D for species-agnostic wildlife monitoring, April 2026
Vandita Shukla, Fabio Remondino, Blair Costelloe, and Benjamin Risse. WildLIFT: Lifting monocular drone video to 3D for species-agnostic wildlife monitoring, April 2026
2026
-
[44]
Frank, Ben- jamin Koger, Blair R
Peter Skovorodnikov, Janet Zhao, Friederike Buck, Tomas Kay, Dominic D. Frank, Ben- jamin Koger, Blair R. Costelloe, Iain D. Couzin, and Jacopo Razzauti. FERAL: A Video- Understanding System for Direct Video-to-Behavior Mapping, November 2025. ISSN 2692- 8205
2025
-
[45]
Lichtenberg, and Jianxiong Xiao
Shuran Song, Samuel P. Lichtenberg, and Jianxiong Xiao. SUN RGB-D: A RGB-D scene understanding benchmark suite. In2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 567–576, Boston, MA, USA, June 2015. IEEE. ISBN 978-1- 4673-6964-0. doi: 10.1109/CVPR.2015.7298655. URL http://ieeexplore.ieee.org/ document/7298655/
-
[46]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception...
2020
-
[47]
Adapting the Re-ID Challenge for Static Sensors
Avirath Sundaresan, Jason Parham, Jonathan Crall, Rosemary Warungu, Timothy Muthami, Jackson Miliko, Margaret Mwangi, Jason Holmberg, Tanya Berger-Wolf, Daniel Ruben- stein, Charles Stewart, and Sara Beery. Adapting the Re-ID Challenge for Static Sensors. IET Computer Vision, 19(1):e70027, 2025. ISSN 1751-9640. doi: 10.1049/cvi2.70027. URL https://onlinel...
-
[48]
Costelloe, Silvia Zuffi, Benjamin Risse, Alexander Mathis, Mackenzie W
Devis Tuia, Benjamin Kellenberger, Sara Beery, Blair R. Costelloe, Silvia Zuffi, Benjamin Risse, Alexander Mathis, Mackenzie W. Mathis, Frank van Langevelde, Tilo Burghardt, Roland Kays, Holger Klinck, Martin Wikelski, Iain D. Couzin, Grant van Horn, Margaret C. Cro- foot, Charles V . Stewart, and Tanya Berger-Wolf. Perspectives in machine learning for wi...
2022
-
[49]
Commun.13, 792, DOI: 10.1038/s41467-022-27980-y (2022)
doi: 10.1038/s41467-022-27980-y. URL https://www.nature.com/articles/ s41467-022-27980-y
-
[50]
Aaron Wirsing, Aaron Johnston, and Jeremy Kiszka. The rapidly expanding role of drones as a tool for wildlife research.Wildlife Research, 49, February 2022. doi: 10.1071/WR22006
-
[51]
In: IEEE/CVF International Conference on Computer Vision
Jiacong Xu, Yi Zhang, Jiawei Peng, Wufei Ma, Artur Jesslen, Pengliang Ji, Qixin Hu, Jiehua Zhang, Qihao Liu, Jiahao Wang, Wei Ji, Chen Wang, Xiaoding Yuan, Prakhar Kaushik, Guofeng Zhang, Jie Liu, Yushan Xie, Yawen Cui, Alan Yuille, and Adam Kortylewski. Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape. In2023 IEEE/CVF International Conferenc...
-
[52]
Open vocabulary monocular 3d object detection.arXiv preprint arXiv:2411.16833, 2024
Jin Yao, Hao Gu, Xuweiyi Chen, Jiayun Wang, and Zezhou Cheng. Open vocabulary monocular 3d object detection.arXiv preprint arXiv:2411.16833, 2024
arXiv 2024
-
[53]
Dwyer, and Zezhou Cheng
Jin Yao, Radowan Mahmud Redoy, Sebastian Elbaum, Matthew B. Dwyer, and Zezhou Cheng. Labelany3d: Label any object 3d in the wild. 2025. 14
2025
-
[54]
Detect anything 3d in the wild.arXiv preprint arXiv:2504.07958, 2025
Hanxue Zhang, Haoran Jiang, Qingsong Yao, Yanan Sun, Renrui Zhang, Hao Zhao, Hongyang Li, Hongzi Zhu, and Zetong Yang. Detect anything 3d in the wild.arXiv preprint arXiv:2504.07958, 2025
arXiv 2025
-
[55]
Silvia Zuffi, Angjoo Kanazawa, Tanya Berger-Wolf, and Michael Black. Three-D Safari: Learning to Estimate Zebra Pose, Shape, and Texture From Images “In the Wild”. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 5358–5367, Seoul, Korea (South), October 2019. IEEE. ISBN 978-1-7281-4803-8. doi: 10.1109/ICCV .2019.00546. 15 A Supple...
-
[56]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.