Vaani Benchmark V1.0: An Inclusive Multimodal Benchmark Dataset for Hindi
Pith reviewed 2026-06-26 13:05 UTC · model grok-4.3
The pith
Vaani Benchmark collects spontaneous Hindi speech from 104 districts with three transcriptions each to enable more representative ASR testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
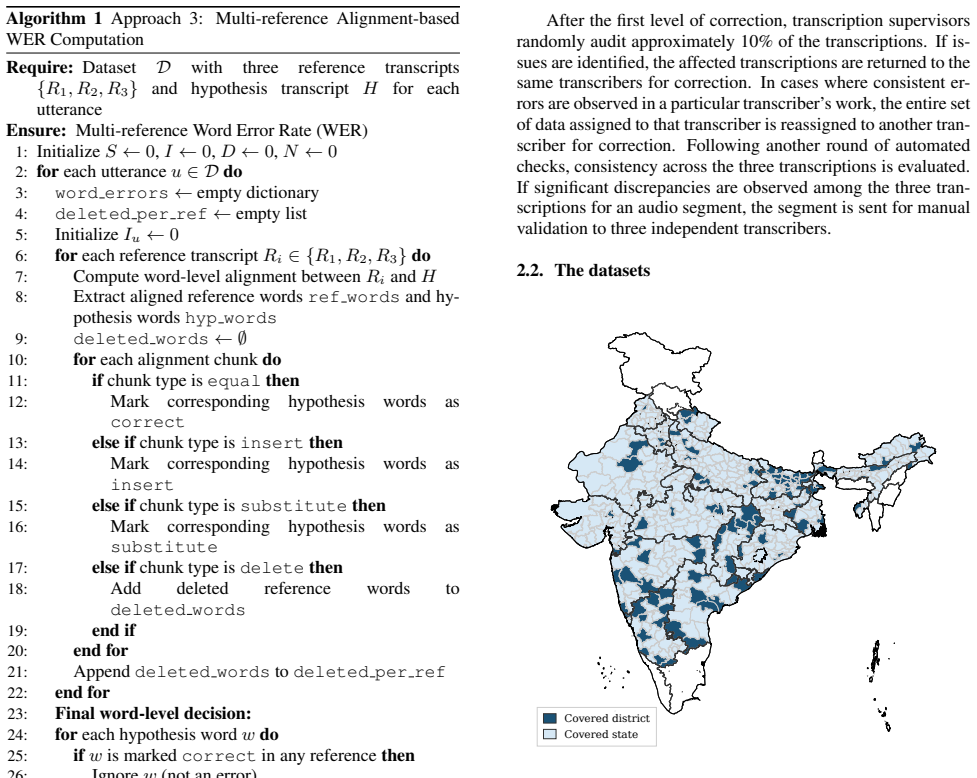
The central claim is that an inclusive multimodal Hindi ASR benchmark dataset collected from 104 districts across India, featuring spontaneous speech elicited by image prompts and recorded in real-world conditions across diverse demographic groups, with each segment annotated by three independent transcriptions, enables more robust, inclusive, and realistic evaluation of ASR systems than prior resources.
What carries the argument
The Vaani Benchmark V1.0 dataset of spontaneous speech recordings elicited via image prompts, captured in real-world conditions, and supplied with three independent transcriptions per segment to support multi-reference scoring.
If this is right
- ASR models can be evaluated for performance across wider geographic and demographic ranges within India.
- Multi-reference transcriptions allow scoring that tolerates natural orthographic and lexical variations.
- Real-world acoustic conditions test how systems handle everyday noise and environments.
- Direct comparisons between open-source and proprietary models become possible on the same inclusive data.
- Benchmark results can guide improvements in handling spontaneous rather than read speech.
Where Pith is reading between the lines
- Model developers may shift toward collecting training data from similarly broad regional samples to close performance gaps.
- The image-prompt method could transfer to speech data collection for other languages where scripted prompts limit naturalness.
- Public releases of such benchmarks might accelerate community efforts to build region-aware Hindi ASR tools.
Load-bearing premise
The collection of spontaneous speech via image prompts from 104 districts across diverse demographic groups in real-world conditions will produce data that meaningfully improves upon the geographic and demographic limitations of existing Hindi ASR benchmarks.
What would settle it
A direct comparison finding that ASR model rankings and error rates on this dataset match those on existing Hindi benchmarks with no added insight from the wider coverage or multiple transcriptions would falsify the claim of improved evaluation robustness.
Figures

read the original abstract
Benchmarking is critical for the systematic evaluation and comparison of automatic speech recognition (ASR) systems. While several open-source datasets are available for Hindi ASR, existing benchmarks remain limited in geographic diversity, demographic representation, and transcription robustness. We introduce an inclusive, multimodal Hindi ASR benchmark collected from 104 districts across India. The dataset consists of spontaneous speech elicited using image prompts and recorded in real-world acoustic conditions across diverse demographic groups. Each audio segment is annotated with three independent transcriptions, enabling multi-reference evaluation that accounts for permissible orthographic and lexical variations. This design supports more robust, inclusive, and realistic ASR evaluation. We benchmark multiple open-source and proprietary ASR models and report their comparative performance on the benchmark dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Vaani Benchmark V1.0, a multimodal Hindi ASR dataset collected from 104 districts across India. Spontaneous speech is elicited via image prompts and recorded in real-world conditions from diverse demographic groups; each audio segment receives three independent transcriptions to support multi-reference evaluation accounting for orthographic and lexical variation. The authors benchmark multiple open-source and proprietary ASR models and assert that the design enables more robust, inclusive, and realistic evaluation than existing Hindi benchmarks.
Significance. A dataset with verified broad geographic coverage, demographic diversity, real-world acoustics, and multi-reference transcriptions would be a useful addition for Hindi ASR evaluation, as it could expose model weaknesses missed by narrower existing resources. The triple-transcription protocol is a constructive design choice for handling permissible variation. However, the manuscript supplies no quantitative evidence (demographics, coverage metrics, acoustic statistics, or side-by-side comparisons) that these benefits are realized.
major comments (2)
- [Abstract] Abstract: the central claim that the collection 'supports more robust, inclusive, and realistic ASR evaluation' is asserted without any speaker-level statistics (age/gender/dialect/education), district-level coverage map or sampling protocol, acoustic-condition quantifiers (SNR, reverberation), or direct comparison of coverage against Common Voice Hindi or IndicTTS; this evidence is required to substantiate the inclusivity improvement over prior benchmarks.
- [Abstract] Abstract and methods description: no error analysis, verification procedure, or ablation is reported to confirm that image-prompted spontaneous speech from 104 districts actually overcomes the geographic and demographic limitations cited for existing datasets; benchmarking models on the new set alone does not test the inclusivity claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative support of our inclusivity claims. We address each major comment below, indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the collection 'supports more robust, inclusive, and realistic ASR evaluation' is asserted without any speaker-level statistics (age/gender/dialect/education), district-level coverage map or sampling protocol, acoustic-condition quantifiers (SNR, reverberation), or direct comparison of coverage against Common Voice Hindi or IndicTTS; this evidence is required to substantiate the inclusivity improvement over prior benchmarks.
Authors: We agree that the manuscript would be strengthened by including quantitative evidence. In the revised version, we will add a dedicated section with available speaker-level demographics (age, gender, education where recorded), a district coverage summary with sampling protocol details, acoustic statistics including average SNR, and a comparison table against Common Voice Hindi and IndicTTS to directly substantiate the coverage improvements. revision: yes
-
Referee: [Abstract] Abstract and methods description: no error analysis, verification procedure, or ablation is reported to confirm that image-prompted spontaneous speech from 104 districts actually overcomes the geographic and demographic limitations cited for existing datasets; benchmarking models on the new set alone does not test the inclusivity claim.
Authors: The multi-reference transcriptions and real-world recording conditions are designed to address variation and realism, with benchmarking results showing model performance differences attributable to these factors. We acknowledge the value of additional validation. In revision, we will expand the methods with transcription verification procedures, include an error analysis stratified by district or demographic factors where possible, and add discussion of how the dataset design targets the cited limitations of prior resources. revision: yes
Circularity Check
No circularity: dataset creation paper with no derivations or fitted predictions
full rationale
The paper introduces a new Hindi ASR benchmark dataset collected from 104 districts using image prompts, with multi-reference transcriptions, and reports model benchmarks. No equations, parameters, or predictions appear in the provided text. The abstract and description contain only descriptive claims about inclusivity and robustness; these do not reduce to prior fitted values or self-citations by construction. No self-definitional steps, uniqueness theorems, or ansatzes are invoked. This matches the default case of a self-contained dataset paper with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Three independent transcriptions adequately capture permissible orthographic and lexical variations in Hindi spontaneous speech.
Reference graph
Works this paper leans on
-
[1]
Introduction Benchmarking is a critical stage in the model development pro- cess, as it evaluates model performance under unseen condi- tions using standardized benchmark datasets. This process re- veals the strengths and limitations of models, enables mean- ingful comparison across systems, and informs decisions about their real-world applicability. Stat...
Pith/arXiv arXiv 2011
-
[2]
Vaani Benchmark The benchmark targets systematic assessment of Hindi ASR robustness by pairing spoken utterances with multiple human references. It comprises 20.64 hours of spontaneous speech collected from an inclusive, geographically distributed speaker population spanning 104 districts across 22 Indian states and Union Territories, enabling fine-graine...
-
[3]
The evaluated models comprise base versions as well as fine- tuned variants, and include both monolingual and multilingual architectures
Evaluations We evaluated multiple models on the proposed benchmark dataset, including both open-source and commercial systems. The evaluated models comprise base versions as well as fine- tuned variants, and include both monolingual and multilingual architectures. While the Vaani dataset inherently supports mul- timodal benchmarking—such as speech-image r...
-
[4]
We evaluate multiple open-source and proprietary ASR models on this dataset
Conclusion We present an inclusive, multimodal Hindi ASR benchmark comprising speech data collected from 104 districts, with three independent reference transcriptions for each segment. We evaluate multiple open-source and proprietary ASR models on this dataset. Our analysis reveals substantial differences in Word Error Rate (WER) when using multi-referen...
-
[5]
Quantifying bias in automatic speech recognition,
S. Feng, O. Kudina, B. M. Halpern, and O. Scharenborg, “Quantifying bias in automatic speech recognition,” 2021. [Online]. Available: https://arxiv.org/abs/2103.15122
arXiv 2021
-
[6]
Hey asr system! why aren’t you more inclusive? automatic speech recognition sys- tems’ bias and proposed bias mitigation techniques. a literature review,
M. K. Ngueajio and G. Washington, “Hey asr system! why aren’t you more inclusive? automatic speech recognition sys- tems’ bias and proposed bias mitigation techniques. a literature review,” inInternational conference on human-computer interac- tion. Springer, 2022, pp. 421–440
2022
-
[7]
Census of india 2011: Language data,
Office of the Registrar General , “Census of india 2011: Language data,” 2011
2011
-
[8]
Indicsuperb: A speech processing universal performance benchmark for indian languages,
T. Javed, K. Bhogale, A. Raman, P. Kumar, A. Kunchukuttan, and M. M. Khapra, “Indicsuperb: A speech processing universal performance benchmark for indian languages,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 11, 2023, pp. 12 942–12 950
2023
-
[9]
Lahaja: A robust multi-accent benchmark for evaluating hindi asr systems,
T. Javed, J. Nawale, S. Joshi, E. George, K. Bhogale, D. Mehen- dale, and M. M. Khapra, “Lahaja: A robust multi-accent benchmark for evaluating hindi asr systems,”arXiv preprint arXiv:2408.11440, 2024
arXiv 2024
-
[10]
Vistaar: Diverse benchmarks and training sets for indian language asr,
K. S. Bhogale, S. Sundaresan, A. Raman, T. Javed, M. M. Khapra, and P. Kumar, “Vistaar: Diverse benchmarks and training sets for indian language asr,”arXiv preprint arXiv:2305.15386, 2023
arXiv 2023
-
[11]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” in2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 798–805
2023
-
[12]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,”arXiv preprint arXiv:1912.06670, 2019
arXiv 1912
-
[13]
Mucs 2021: Multilingual and code-switching asr challenges for low resource indian languages,
A. Diwan, R. Vaideeswaran, S. Shah, A. Singh, S. Raghavan, S. Khare, V . Unni, S. Vyas, A. Rajpuria, C. Yarra, A. Mittal, P. K. Ghosh, P. Jyothi, K. Bali, V . Seshadri, S. Sitaram, S. Bharadwaj, J. Nanavati, R. Nanavati, and K. Sankaranarayanan, “Mucs 2021: Multilingual and code-switching asr challenges for low resource indian languages,” inInterspeech 20...
2021
-
[14]
Gram vaani asr challenge on spontaneous telephone speech recordings in regional variations of hindi,
A. R. K. Kumar, N. Ravi, A. Seth, A. Seth, and A. Singh, “Gram vaani asr challenge on spontaneous telephone speech recordings in regional variations of hindi,” 2022
2022
-
[15]
Respin- s1. 0: A read speech corpus of 10000+ hours in dialects of nine in- dian languages,
S. Kumar, A. Singh, J. Bandekar, S. Murthy, S. Sharma, S. Badi- ger, S. Udupa, A. Nagireddi, S. R. KM, R. Saxenaet al., “Respin- s1. 0: A read speech corpus of 10000+ hours in dialects of nine in- dian languages,” inThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track
-
[16]
Style-agnostic evaluation of asr using multiple reference transcripts,
Q. McNamara, M. ´Angel del R ´ıo Fern ´andez, N. Bhandari, M. Ratajczak, D. Chen, C. Miller, and M. Jett ´e, “Style-agnostic evaluation of asr using multiple reference transcripts,” 2024. [Online]. Available: https://arxiv.org/abs/2412.07937
arXiv 2024
-
[17]
Multi-reference wer for evaluating asr for languages with no orthographic rules,
A. Ali, W. Magdy, P. Bell, and S. Renais, “Multi-reference wer for evaluating asr for languages with no orthographic rules,” in 2015 IEEE Workshop on Automatic Speech Recognition and Un- derstanding (ASRU). IEEE, 2015, pp. 576–580
2015
-
[18]
Cultural bias in large language models: Evaluating ai agents through moral questionnaires,
S. M ¨unker, “Cultural bias in large language models: Evaluating ai agents through moral questionnaires,” 2025. [Online]. Available: https://arxiv.org/abs/2507.10073
arXiv 2025
-
[19]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, p. 1–38, Mar. 2023. [Online]. Available: http://dx.doi.org/10.1145/3571730
-
[20]
Code-switching and mixing in communication- a study on language contact in indian media,
C. Barnali, “Code-switching and mixing in communication- a study on language contact in indian media,” inThe Future of Ethics, Education and Research. Scientia Moralitas Research Institute, 2017, pp. 110–123
2017
-
[21]
Code-switching in end-to-end automatic speech recognition: A systematic literature review,
M. T. Agro, A. Kulkarni, K. Kadaoui, Z. Talat, and H. Aldarmaki, “Code-switching in end-to-end automatic speech recognition: A systematic literature review,”arXiv preprint arXiv:2507.07741, 2025
arXiv 2025
-
[22]
Speech recognition in noisy environments: A survey,
Y . Gong, “Speech recognition in noisy environments: A survey,” Speech communication, vol. 16, no. 3, pp. 261–291, 1995
1995
-
[23]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen et al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabil- ities,”arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[24]
Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras,
Microsoft, :, A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chen, D. Chen, D. Chen, J. Chen, W. Chen, Y .-C. Chen, Y . ling Chen, Q. Dai, X. Dai, R. Fan, M. Gao, M. Gao, A. Garg, A. Goswami, J. Hao, A. Hendy, Y . Hu, X. Jin, M. Khademi, D. Kim, Y . J. Kim, G. Lee, J. Li, Y . Li, C. Liang, X. Lin...
-
[25]
Available: https://arxiv.org/abs/2503.01743
[Online]. Available: https://arxiv.org/abs/2503.01743
-
[26]
Vaani: Capturing the language landscape for an inclusive digital india,
S. Pulikodan, A. Singh, A. Basu, N. Desai, P. K. J, P. D. Bhat, R. Dharmaraju, R. Gupta, S. Udupa, S. Kumar, S. Sharma, V . Sanka, D. Tewari, H. Dhand, A. Kamat, S. Singh, S. Vashishth, P. Talukdar, R. Acharya, and P. K. Ghosh, “Vaani: Capturing the language landscape for an inclusive digital india,” 2026. [Online]. Available: https://arxiv.org/abs/2603.28714
Pith/arXiv arXiv 2026
-
[27]
Indicconformer-600m-multilingual,
AI4Bharat, “Indicconformer-600m-multilingual,” https: //huggingface.co/ai4bharat/indic-conformer-600m-multilingual, 2025
2025
-
[28]
ASR Models,
Speech Lab, IIT Madras, “ASR Models,” https://asr.iitm.ac.in/ models/, accessed: March 2, 2026
2026
-
[29]
Harveenchadha/hindi large wav2vec2,
Harveen Singh Chadha, “Harveenchadha/hindi large wav2vec2,” https://huggingface.co/Harveenchadha/hindi large wav2vec2, 2022, hugging Face model card, Apache-2.0 license; access: March 2, 2026
2022
-
[30]
Robust speech recognition via large- scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
Pith/arXiv arXiv 2022
-
[31]
Omnilingual asr: Open-source multilingual speech recognition for 1600+ languages,
O. A. team, G. Keren, A. Kozhevnikov, Y . Meng, C. Ropers, M. Setzler, S. Wang, I. Adebara, M. Auli, C. Balioglu, K. Chan, C. Cheng, J. Chuang, C. Droof, M. Duppenthaler, P.-A. Duquenne, A. Erben, C. Gao, G. M. Gonzalez, K. Lyu, S. Miglani, V . Pratap, K. R. Sadagopan, S. Saleem, A. Turkatenko, A. Ventayol-Boada, Z.-X. Yong, Y .-A. Chung, J. Maillard, R. ...
arXiv 2025
-
[32]
A. H. Liu, A. Ehrenberg, A. Lo, C. Denoix, C. Barreau, G. Lample, J.-M. Delignon, K. R. Chandu, P. von Platen, P. R. Muddireddy, S. Gandhi, S. Ghosh, S. Mishra, T. Foubert, A. Rastogi, A. Yang, A. Q. Jiang, A. Sablayrolles, A. H ´eliou, A. Martin, A. Agarwal, A. Roux, A. Darcet, A. Mensch, B. Bout, B. Rozi `ere, B. D. Monicault, C. Bamford, C. Wallenwein,...
arXiv 2025
-
[33]
Shunyalabs/pingala v1 universal,
Shunya Labs, “Shunyalabs/pingala v1 universal,” https: //huggingface.co/shunyalabs/pingala-v1-universal, 2025, hug- ging Face model card, Shunya Labs RAIL-M License; access: March 2, 2026
2025
-
[34]
Gemini 3 flash,
Google DeepMind, “Gemini 3 flash,” https://genai.google/api/ models/gemini-3-flash, 2025
2025
-
[35]
Chirp speech model,
Google Cloud, “Chirp speech model,” https://cloud.google.com/ speech-to-text, 2025, universal multilingual ASR model used in Speech-to-Text API; accessed 2026-02-05
2025
-
[36]
Azure speech service,
Microsoft, “Azure speech service,” https://learn.microsoft.com/ azure/ai-services/speech-service/overview, 2025, cloud speech service for ASR and TTS; accessed 2026-02-05
2025
-
[37]
Saarika-v2.5 speech recognition model,
S. AI, “Saarika-v2.5 speech recognition model,” https://docs. sarvam.ai/api-reference-docs/asr/models/saarika, 2025, speech- to-text model supporting multiple Indian languages; accessed 2026-02-05
2025
-
[38]
Gpt-4o transcribe model documentation,
OpenAI, “Gpt-4o transcribe model documentation,” https:// developers.openai.com/api/docs/models/gpt-4o-transcribe, 2024, accessed: 2026
2024
-
[39]
Introducing saaras v3: Built for the way india speaks,
Sarvam AI, “Introducing saaras v3: Built for the way india speaks,” https://www.sarvam.ai/blogs/asr/, February 2026, ac- cessed: 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.