Energy-based Compositional Diffusion Planning
Pith reviewed 2026-06-26 14:10 UTC · model grok-4.3
The pith
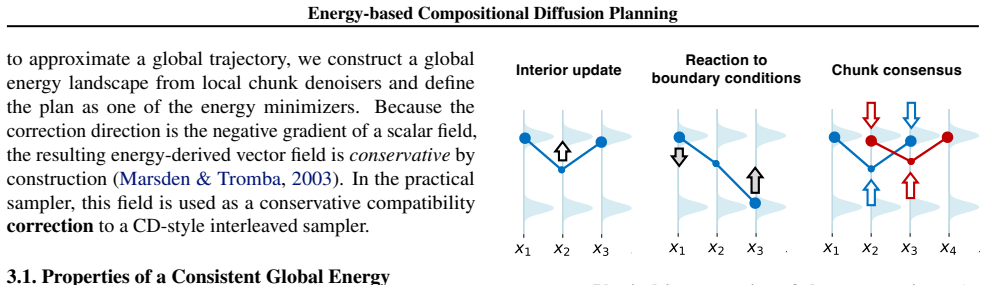
ECD recovers global trajectories by minimizing the sum of local bridge potentials, producing a conservative correction field that includes the omitted boundary reaction term.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
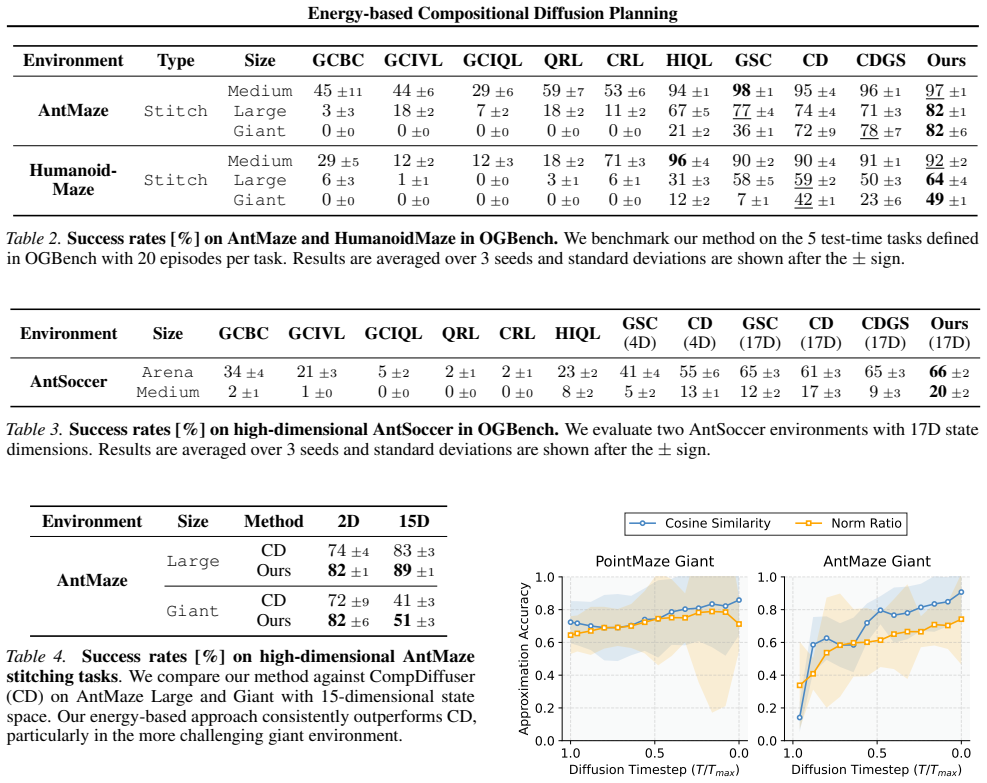
The global trajectory is recovered as the minimizer of the sum of local bridge potentials; this energy-based view defines a conservative correction field that contains the boundary reaction term omitted by heuristic stitching, and the reaction term is recovered efficiently by a Markov-based score approximation solved via a single block-tridiagonal linear system.
What carries the argument
Energy-based Compositional Diffuser (ECD), the formulation of the global trajectory as the minimizer of the sum of local bridge potentials.
If this is right
- The stitched update becomes a conservative field that corresponds to a valid global trajectory log-density.
- Inference cost remains linear in the planning horizon through the block-tridiagonal solve.
- Higher success rates are obtained on long-horizon robotic stitching tasks.
- The boundary reaction term is included without changing the asymptotic speed of heuristic methods.
Where Pith is reading between the lines
- The same energy-minimization view could be applied to other sequence-composition methods that currently rely on ad-hoc stitching.
- The reaction term recovered by the Markov approximation may correspond to measurable boundary effects in physical robot dynamics.
- Extending the block-tridiagonal structure to non-Markov score models could further reduce approximation error on very long horizons.
Load-bearing premise
The global trajectory log-density is exactly recovered by minimizing the sum of local bridge potentials and the Markov score approximation captures the reaction term without introducing bias that changes planning outcomes.
What would settle it
A direct comparison on a stitching task where the trajectory distribution recovered by ECD diverges measurably from the true global log-density or where success rates fall below heuristic stitching.
Figures


read the original abstract
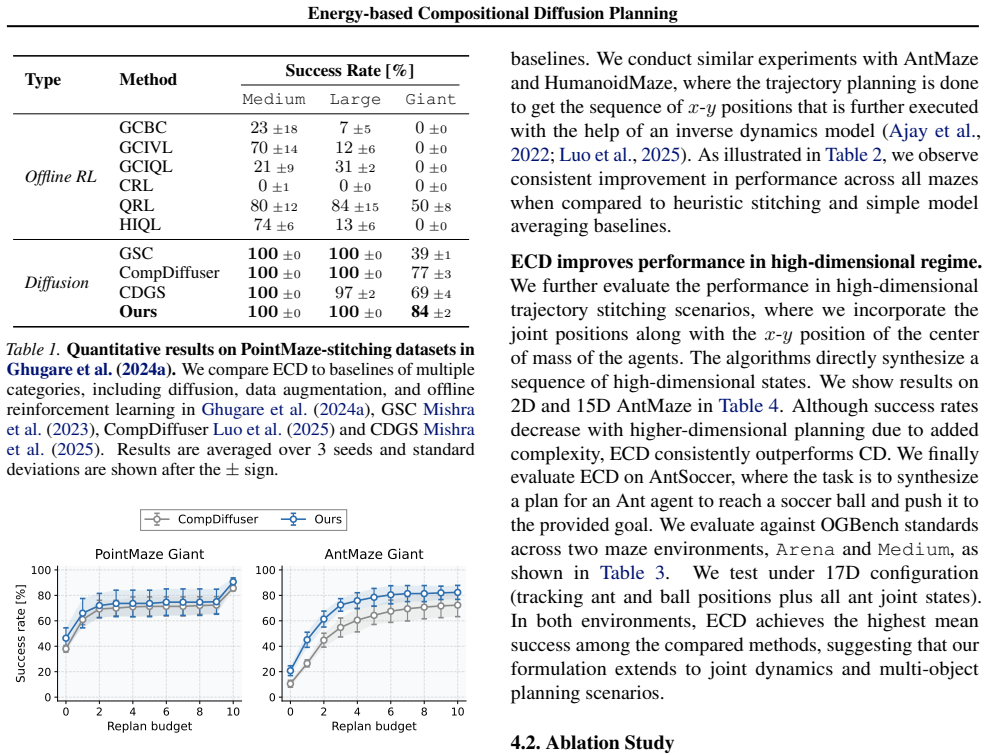
Compositional diffusion planners aim to solve long-horizon robotic tasks using short training trajectories. Yet, current approaches often rely on the heuristic stitching of local predictions. We show that the resulting stitched update is generally a non-conservative field} that does not mathematically correspond to any valid global trajectory log-density function. We propose Energy-based Compositional Diffuser (ECD), a framework that formulates the global trajectory as the minimizer of the sum of local bridge potentials. This energy-based perspective defines a conservative correction field and contains a boundary reaction term that heuristic stitching omits. To enable efficient inference, we further introduce a Markov-based score approximation that computes the reaction term via a single block-tridiagonal solve, maintaining time complexity linear in the planning horizon. Empirically, ECD achieves state-of-the-art success rates on a range of OGBench stitching tasks, while nearly matching the inference speed of heuristic stitching methods. Code is available at https://github.com/GradientSpaces/ECD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that heuristic stitching of local predictions in compositional diffusion planners produces a non-conservative vector field that does not correspond to any valid global trajectory log-density. It proposes the Energy-based Compositional Diffuser (ECD), which formulates the global trajectory as the minimizer of the sum of local bridge potentials; this yields a conservative correction field that includes an omitted boundary reaction term. A Markov-based score approximation recovers the reaction term via a single block-tridiagonal solve while preserving linear time complexity in the horizon. Experiments report state-of-the-art success rates on OGBench stitching tasks at near-heuristic inference speed, with code released.
Significance. If the energy minimization exactly recovers the global log-density and the Markov approximation introduces no material bias, the work supplies a principled, conservative alternative to heuristic stitching for long-horizon diffusion planning. The open-source implementation is a concrete strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract and the section introducing the non-conservative claim: the assertion that the stitched update 'does not mathematically correspond to any valid global trajectory log-density function' is stated without a derivation showing that the heuristic field cannot arise from any global density; this claim is load-bearing for the motivation of ECD.
- [Markov-based score approximation] The section on the Markov-based score approximation: the claim that the single block-tridiagonal solve 'accurately captures the omitted reaction term without introducing bias' lacks both an error bound (independent of horizon) and an ablation measuring the approximation's effect on trajectory validity or planning success; this directly affects whether the conservativeness guarantee survives the practical implementation.
minor comments (1)
- [Abstract] The abstract states 'nearly matching the inference speed'; a table or figure quantifying wall-clock times and success rates side-by-side with the heuristic baseline would strengthen the empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate the revisions that will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract and the section introducing the non-conservative claim: the assertion that the stitched update 'does not mathematically correspond to any valid global trajectory log-density function' is stated without a derivation showing that the heuristic field cannot arise from any global density; this claim is load-bearing for the motivation of ECD.
Authors: We agree that an explicit derivation strengthens the motivation. In the revision we will add a short proof in Section 3 showing that the heuristic stitched field has nonzero curl in general (hence cannot be the gradient of any scalar log-density) together with a two-segment counterexample demonstrating nonzero circulation. This derivation follows directly from the energy formulation already present in the manuscript. revision: yes
-
Referee: [Markov-based score approximation] The section on the Markov-based score approximation: the claim that the single block-tridiagonal solve 'accurately captures the omitted reaction term without introducing bias' lacks both an error bound (independent of horizon) and an ablation measuring the approximation's effect on trajectory validity or planning success; this directly affects whether the conservativeness guarantee survives the practical implementation.
Authors: We will add an ablation comparing the Markov approximation to exact block-tridiagonal solves on short-horizon instances where the latter is tractable, reporting effects on success rate and trajectory validity. A horizon-independent error bound is not currently derived and appears difficult without further assumptions on the underlying dynamics; we will instead clarify the approximation's bias properties and its effect on the conservativeness guarantee in the revised text. revision: partial
- Deriving a general error bound for the Markov score approximation that is independent of planning horizon
Circularity Check
No significant circularity; central construction is definitional proposal
full rationale
The paper defines ECD by formulating the global trajectory explicitly as the minimizer of summed local bridge potentials; this choice directly yields the conservative field and reaction term by the mathematical properties of energy minimization, without reducing a claimed derivation back to fitted data or prior self-citations. The Markov score approximation is presented solely as a computational device for linear-time inference, not as a result that is forced by or equivalent to the target quantities. No equations or steps in the provided text exhibit self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. The framework is therefore self-contained as a modeling choice rather than a circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local diffusion predictions can be treated as bridge potentials whose sum defines a global energy whose minimizer is a valid trajectory density.
- domain assumption The Markov score approximation computes the boundary reaction term without material bias for planning success.
Reference graph
Works this paper leans on
-
[1]
Stap: Sequencing task-agnostic policies.arXiv preprint arXiv:2210.12250,
Agia, C., Migimatsu, T., Wu, J., and Bohg, J. Stap: Sequencing task-agnostic policies.arXiv preprint arXiv:2210.12250,
-
[2]
Ajay, A., Du, Y ., Gupta, A., Tenenbaum, J. B., Jaakkola, T. S., and Agrawal, P. Is conditional generative modeling all you need for decision making? InInternational Conference on Learning Representations (ICLR), 2023a. Ajay, A., Han, S., Du, Y ., Li, S., Gupta, A., Jaakkola, T. S., Tenenbaum, J. B., Kaelbling, L. P., Srivastava, A., and Agrawal, P. Compo...
-
[3]
T., Baierl, M., Koert, D., and Peters, J
Carvalho, J., Le, A. T., Baierl, M., Koert, D., and Peters, J. Motion planning diffusion: Learning and planning of robot motions with diffusion models. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1916–1923. IEEE,
1916
-
[4]
Char, I., Mehta, V ., Villaflor, A., Dolan, J. M., and Schneider, J. Bats: Best action trajectory stitching.arXiv preprint arXiv:2204.12026,
-
[5]
Simple hierarchical planning with diffusion
Chen, C., Deng, F., Kawaguchi, K., Gulcehre, C., and Ahn, S. Simple hierarchical planning with diffusion. In International Conference on Learning Representations (ICLR), 2024a. Chen, C., Deng, F., Kawaguchi, K., Gulcehre, C., and Ahn, S. Simple hierarchical planning with diffusion.arXiv preprint arXiv:2401.02644, 2024b. Chen, C., Hamed, H., Baek, D., Kang...
-
[6]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Chi, C., Feng, S., Du, Y ., Xu, W., Wang, T., Cousineau, E., Burchfiel, B., and Song, S. Diffusion policy: Visuomotor policy learning via action diffusion.arXiv preprint arXiv:2303.04137,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URLhttps://arxiv.org/abs/2105.05233. Du, Y . and Kaelbling, L. Compositional generative modeling: A single model is not all you need.arXiv preprint arXiv:2402.01103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Compositional sculpting of iterative generative processes.arXiv preprint arXiv:2309.16115,
Garipov, T., De Peuter, S., Yang, G., Garg, V ., Kaski, S., and Jaakkola, T. Compositional sculpting of iterative generative processes.arXiv preprint arXiv:2309.16115,
-
[9]
Learning to reach goals via iterated supervised learning.arXiv preprint arXiv:1912.06088,
Ghosh, D., Gupta, A., Reddy, A., Fu, J., Devin, C., Eysenbach, B., and Levine, S. Learning to reach goals via iterated supervised learning.arXiv preprint arXiv:1912.06088,
-
[10]
Ghugare, R., Geist, M., Berseth, G., and Eysenbach, B. Closing the gap between td learning and supervised learning–a generalisation point of view.arXiv preprint arXiv:2401.11237, 2024a. Ghugare, R., Geist, M., Berseth, G., and Eysenbach, B. Closing the gap between td learning and supervised learning-a generalisation point of view. InThe Twelfth Internatio...
-
[11]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Drdt3: Diffusion- refined decision test-time training model.arXiv preprint arXiv:2501.06718,
Huang, X., Wu, D., and Boulet, B. Drdt3: Diffusion- refined decision test-time training model.arXiv preprint arXiv:2501.06718,
-
[13]
Offline Reinforcement Learning with Implicit Q-Learning
Kim, J., Lee, S., Kim, W., and Sung, Y . Adaptiveq-aid for conditional supervised learning in offline reinforcement learning.Advances in Neural Information Processing Systems, 37:87104–87135, 2024a. Kim, S., Choi, Y ., Matsunaga, D. E., and Kim, K.- E. Stitching sub-trajectories with conditional diffusion model for goal-conditioned offline rl. InProceedin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lee, K. and Choi, J. State-covering trajectory stitching for diffusion planners.arXiv preprint arXiv:2506.00895,
-
[15]
Lei, X., Zhang, X., and Wang, D. Mgda: Model-based goal data augmentation for offline goal-conditioned weighted supervised learning.arXiv preprint arXiv:2412.11410,
-
[16]
Li, S. and Zhang, X. Augmenting offline reinforcement learning with state-only interactions.arXiv preprint arXiv:2402.00807,
-
[17]
Liu, Z., Qian, L., Liu, Z., Wan, L., Chen, X., and Lan, X. Enhancing decision transformer with diffusion- based trajectory branch generation.arXiv preprint arXiv:2411.11327,
-
[18]
Luo, Y ., Mishra, U. A., Du, Y ., and Xu, D. Generative trajectory stitching through diffusion composition.arXiv preprint arXiv:2503.05153,
-
[19]
Compositional risk minimization.arXiv preprint arXiv:2410.06303,
Mahajan, D., Pezeshki, M., Mitliagkas, I., Ahuja, K., and Vincent, P. Compositional risk minimization.arXiv preprint arXiv:2410.06303,
-
[20]
A., He, D., Chen, Y ., and Xu, D
Mishra, U. A., He, D., Chen, Y ., and Xu, D. Compositional diffusion with guided search for long-horizon planning. arXiv preprint arXiv:2601.00126,
-
[21]
Composing diffusion policies for few-shot learning of movement trajectories
Patil, O., Sah, A., and Gopalan, N. Composing diffusion policies for few-shot learning of movement trajectories. arXiv preprint arXiv:2410.17479,
-
[22]
Composition and control with distilled energy diffusion models and sequential monte carlo
Thornton, J., Bethune, L., Zhang, R., Bradley, A., Nakkiran, P., and Zhai, S. Composition and control with distilled energy diffusion models and sequential monte carlo. arXiv preprint arXiv:2502.12786,
-
[23]
T., Dolan, J., Schneider, J., and Berseth, G
Venkatraman, S., Khaitan, S., Akella, R. T., Dolan, J., Schneider, J., and Berseth, G. Reasoning with latent diffusion in offline reinforcement learning.arXiv preprint arXiv:2309.06599,
-
[24]
Wang, L., Zhao, J., Du, Y ., Adelson, E. H., and Tedrake, R. Poco: Policy composition from and for heterogeneous robot learning.arXiv preprint arXiv:2402.02511, 2024a. Wang, T., Torralba, A., Isola, P., and Zhang, A. Optimal goal-reaching reinforcement learning via quasimetric learning. InInternational Conference on Machine Learning, pp. 36411–36430. PMLR,
-
[25]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Wang, Y ., Yang, C., Wen, Y ., Liu, Y ., and Qiao, Y . Critic- guided decision transformer for offline reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 15706–15714, 2024b. Wang, Z., Hunt, J. J., and Zhou, M. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Yang, C.-F., Xu, H., Wu, T.-L., Gao, X., Chang, K.-W., and Gao, F. Planning as in-painting: A diffusion-based embodied task planning framework for environments under uncertainty.arXiv preprint arXiv:2312.01097, 2023a. Yang, Z., Mao, J., Du, Y ., Wu, J., Tenenbaum, J. B., Lozano- P´erez, T., and Kaelbling, L. P. Compositional diffusion- based continuous co...
-
[27]
Context-former: Stitching via latent conditioned sequence modeling.arXiv preprint arXiv:2401.16452,
Zhang, Z., Xu, J., Liu, J., Zhuang, Z., Wang, D., Liu, M., and Zhang, S. Context-former: Stitching via latent conditioned sequence modeling.arXiv preprint arXiv:2401.16452,
-
[28]
training horizon
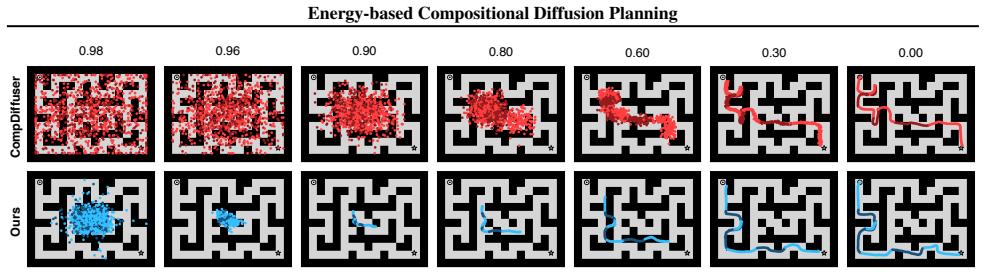
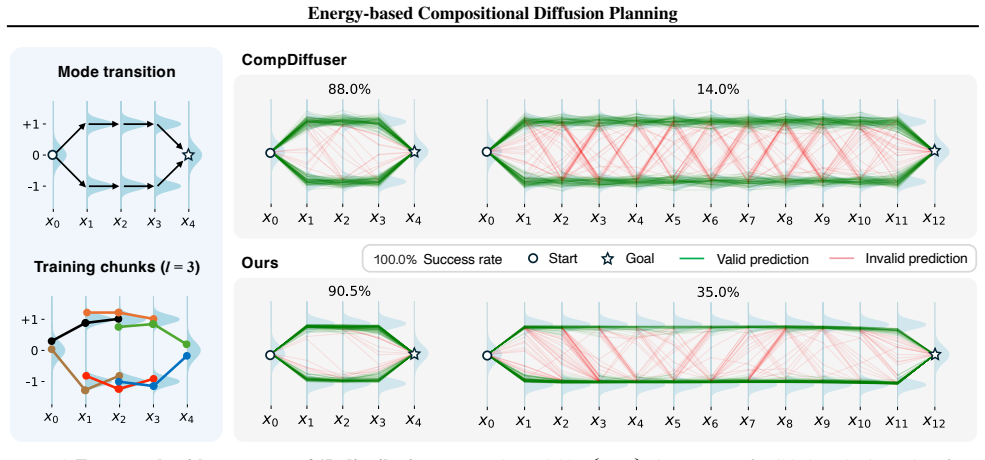
Hence the score field is generally non-conservative. Chunk-interleaved variant.CD’s chunk-interleaved variant used in practice is an ordered composition of local updates. It is therefore better viewed as a proposal operator than as a single simultaneous score field. Its non-conservative character can still be formalized. Let Tk denote the local update tha...
2000
-
[29]
We use the same planner checkpoints for CD and ECD
and CompDiffuser (Luo et al., 2025).We follow the official CompDiffuser implementation and hyperparameter conventions: https://github.com/devinluo27/comp_ diffuser_release. We use the same planner checkpoints for CD and ECD. PointMaze is executed with the PD controller. AntMaze, HumanoidMaze, AntSoccer, and AntMaze-o15d use inverse-dynamics models trained...
2025
-
[30]
Compositional Diffusion with Guided Search (Mishra et al., 2025).We use the official CDGS codebase: https: //github.com/UtkarshMishra04/CDGS_ogbench
For HumanoidMaze and AntSoccer, which are not fully covered by the released pretrained checkpoints, we train our own planner and inverse-dynamics models following the CD codebase. Compositional Diffusion with Guided Search (Mishra et al., 2025).We use the official CDGS codebase: https: //github.com/UtkarshMishra04/CDGS_ogbench. We use the same checkpoints...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.