Enlight: Fast Low-Light Image Enhancement via Multi-Objective Optimization and Shadow-Aware Refinement
Pith reviewed 2026-06-26 14:26 UTC · model grok-4.3
The pith
ENLIGHT enhances low-light images to competitive perceptual quality using direct multi-objective optimization without any training data or learned models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
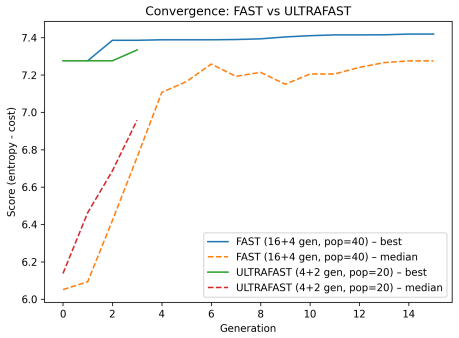
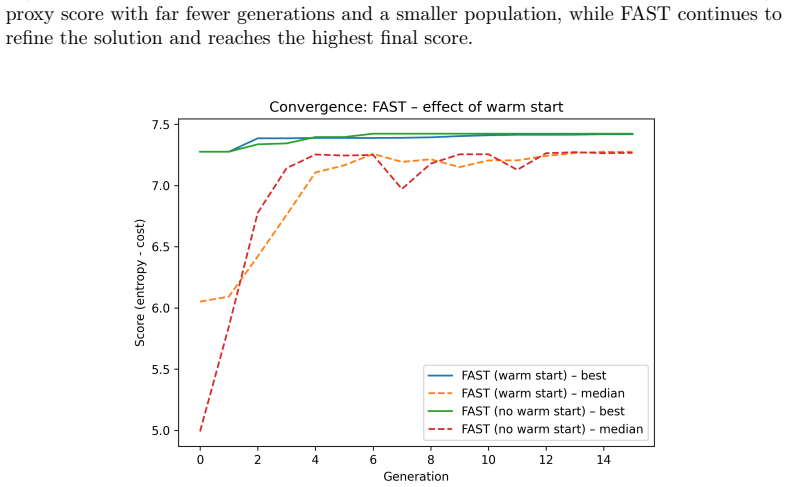
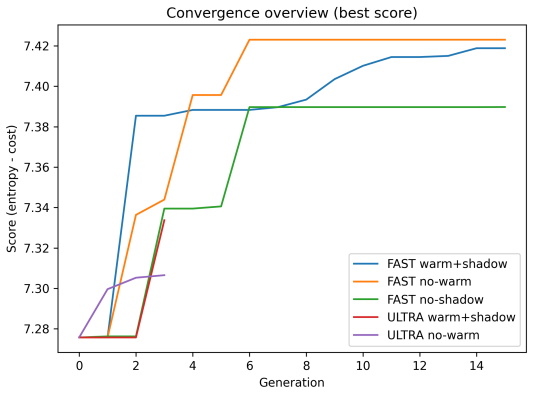
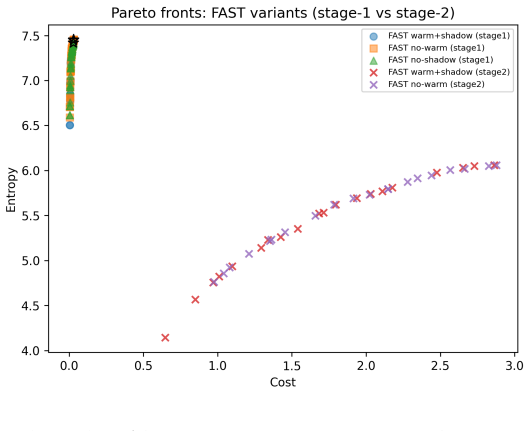
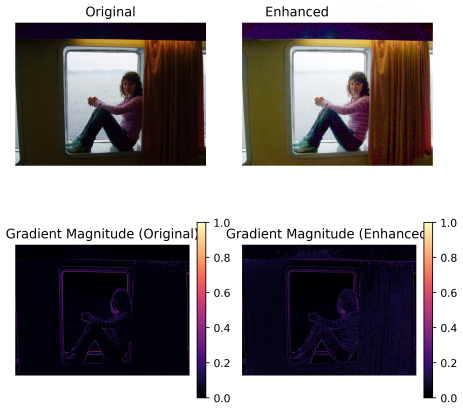
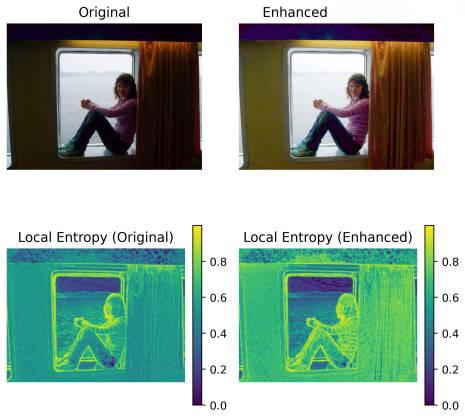
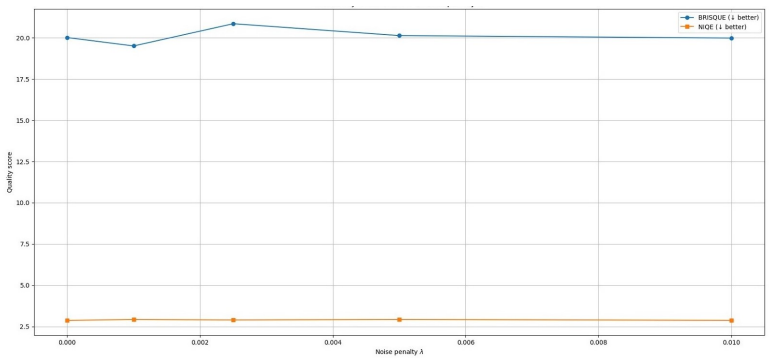
ENLIGHT performs global illumination adjustment to improve visibility while maintaining structural consistency and avoiding excessive noise enhancement, then applies a second stage of shadow-aware refinement that selectively improves low-intensity regions through masked local optimization, all without supervision, to reach competitive MUSIQ, NIQE, and BRISQUE scores at lower inference time across the BAID, Backlit300, LIME, MEF, NPE, and DICM datasets.
What carries the argument
Two-stage global-to-local optimization that combines entropy maximization, gradient preservation, and noise regularization inside a multi-objective function, together with shadow-aware masking for selective local refinement.
If this is right
- The method works on any new image without retraining or dataset collection.
- It supports both evolutionary algorithms and lightweight local search for flexibility in speed versus quality.
- Fast and ultrafast modes let users trade computation for quality on the same objective.
- Qualitative outputs show better contrast and detail preservation with controlled noise compared to baselines.
- The framework is optimizer-agnostic, allowing substitution of different search procedures.
Where Pith is reading between the lines
- The masking step could be adapted to other selective enhancement tasks such as medical or satellite imagery where only dark regions need adjustment.
- Frame-by-frame application with added temporal terms might extend the approach to video without retraining a network.
- Because no training occurs, deployment on edge devices becomes simpler since model weights and data transfer are unnecessary.
- The explicit objective terms make it easier to diagnose failures on specific image types than black-box networks.
Load-bearing premise
The multi-objective terms plus shadow masking will produce perceptually competitive results without any learned model or post-hoc tuning that alters the reported metrics.
What would settle it
Running ENLIGHT on a fresh low-light test set and finding its MUSIQ, NIQE, or BRISQUE scores fall substantially below those of leading supervised methods while its runtime advantage remains.
Figures





read the original abstract
We present ENLIGHT, a fast and training free framework for low-light image enhancement based on direct optimization of a perceptual objective. Unlike deep learning approaches that require large scale training data and supervision, ENLIGHT operates in a zero-shot manner by optimizing image quality at inference time. The method employs a two stage global to local optimization strategy. In the first stage, ENLIGHT performs global illumination adjustment to improve visibility while maintaining structural consistency and avoiding excessive noise enhancement. In the second stage, a shadow aware refinement selectively improves low-intensity regions through masked local optimization, enhancing visibility without overexposure. To balance quality and efficiency, we introduce two modes: Fast, which uses a multi-objective formulation combining entropy, gradient preservation, and noise regularization, and Ultrafast, which reduces computational cost via a lightweight approximation of the same objective. The framework is optimizer agnostic and supports both evolutionary and lightweight local search methods. Experiments on BAID, Backlit300, LIME, MEF, NPE, and DICM demonstrate that ENLIGHT achieves competitive perceptual quality (MUSIQ, NIQE, BRISQUE) with significantly lower inference time. Qualitative results further show improved contrast, preserved structural details, and controlled noise amplification, making ENLIGHT a practical and interpretable alternative to learning based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ENLIGHT, a training-free, zero-shot framework for low-light image enhancement. It uses a two-stage optimization: global illumination adjustment to improve visibility while preserving structure and controlling noise, followed by shadow-aware local refinement via masked optimization. The method optimizes a multi-objective function (entropy + gradient preservation + noise regularization) in Fast and Ultrafast modes, is optimizer-agnostic, and reports competitive perceptual quality (MUSIQ, NIQE, BRISQUE) with lower inference time than learning-based methods on BAID, Backlit300, LIME, MEF, NPE, and DICM datasets.
Significance. If the central claims hold with a single fixed hyperparameter set across all datasets and modes, the work would offer a practical, interpretable alternative to supervised deep-learning methods by demonstrating that direct inference-time optimization can achieve competitive perceptual results efficiently without training data. The two-stage global-to-local strategy and support for evolutionary/local search optimizers are potentially reusable ideas for other enhancement tasks.
major comments (2)
- [Abstract] Abstract: the claim that ENLIGHT 'operates in a zero-shot manner by optimizing image quality at inference time' with a 'fixed' multi-objective formulation is load-bearing for the training-free advantage, yet the abstract provides no explicit scalar weights on the entropy/gradient/noise terms or shadow-mask thresholds, nor states that one fixed vector was used for all six datasets and both modes.
- [Abstract] Abstract (and implied method): no derivation, sensitivity analysis, or verification is given that the chosen objective terms (entropy, gradient preservation, noise regularization) produce the reported perceptual scores without post-hoc adjustment; this leaves open whether the tabulated MUSIQ/NIQE/BRISQUE numbers reflect the stated objectives or implicit tuning.
minor comments (1)
- [Abstract] Abstract: the list of datasets is given but no reference to a comparison table or baseline methods appears in the summary paragraph, making the 'competitive' claim harder to contextualize at first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that ENLIGHT 'operates in a zero-shot manner by optimizing image quality at inference time' with a 'fixed' multi-objective formulation is load-bearing for the training-free advantage, yet the abstract provides no explicit scalar weights on the entropy/gradient/noise terms or shadow-mask thresholds, nor states that one fixed vector was used for all six datasets and both modes.
Authors: We agree that the abstract would benefit from greater explicitness on this point. In the revised version we will state the specific scalar weights for the entropy, gradient-preservation and noise-regularization terms, the shadow-mask threshold, and confirm that a single fixed hyperparameter vector was used for all six datasets and both Fast and Ultrafast modes. These values are already provided in the Methods section. revision: yes
-
Referee: [Abstract] Abstract (and implied method): no derivation, sensitivity analysis, or verification is given that the chosen objective terms (entropy, gradient preservation, noise regularization) produce the reported perceptual scores without post-hoc adjustment; this leaves open whether the tabulated MUSIQ/NIQE/BRISQUE numbers reflect the stated objectives or implicit tuning.
Authors: The three terms were chosen because entropy promotes contrast and information content, gradient preservation maintains structural fidelity, and noise regularization limits artifact amplification; these are standard perceptual criteria in the enhancement literature. All reported scores are obtained directly from the inference-time optimization with no training data and no post-hoc adjustment of the output images or metrics. We acknowledge that the original submission did not contain an explicit derivation or sensitivity study. We will add a concise discussion of the term selection and its link to the observed perceptual metrics in the revised manuscript, supported by the fixed-formulation results across the six datasets. revision: yes
Circularity Check
No circularity; method is direct per-image optimization of stated objectives
full rationale
The paper describes a zero-shot, training-free framework that performs direct optimization of a multi-objective function (entropy + gradient preservation + noise regularization) plus shadow-aware masking at inference time on each input image. No equations, parameters, or results are shown to be fitted to the reported MUSIQ/NIQE/BRISQUE scores on the evaluation datasets; the optimization targets the explicitly stated perceptual terms rather than the downstream metrics. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing premises. The derivation chain is therefore self-contained and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. Guo, Y. Li, H. Ling, Lime: Low-light image enhancement via illumi- nation map estimation, IEEE Transactions on image processing 26 (2) (2016) 982–993
2016
-
[2]
C. Guo, C. Li, J. Guo, C. C. Loy, J. Hou, S. Kwong, R. Cong, Zero- reference deep curve estimation for low-light image enhancement, in: 36 Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 1780–1789
2020
-
[3]
Zhang, J
Y. Zhang, J. Zhang, X. Guo, Kindling the darkness: A practical low- light image enhancer, in: Proceedings of the 27th ACM international conference on multimedia, 2019, pp. 1632–1640
2019
-
[4]
E. H. Land, J. J. McCann, Lightness and retinex theory, Journal of the Optical society of America 61 (1) (1971) 1–11
1971
-
[5]
X. Fu, D. Zeng, Y. Huang, X.-P. Zhang, X. Ding, A weighted varia- tional model for simultaneous reflectance and illumination estimation, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2782–2790
2016
-
[6]
K. Ma, Z. Wang, Multi-exposure image fusion: A patch-wise approach, in: 2015 IEEE International Conference on Image Processing (ICIP), IEEE, 2015, pp. 1717–1721
2015
-
[7]
H. Li, L. Zhang, Multi-exposure fusion with cnn features, in: 2018 25th IEEE International Conference on Image Processing (ICIP), IEEE, 2018, pp. 1723–1727
2018
-
[8]
C. Wei, W. Wang, W. Yang, J. Liu, Deep retinex decomposition for low-light enhancement, arXiv preprint arXiv:1808.04560 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
W. Wu, J. Weng, P. Zhang, X. Wang, W. Yang, J. Jiang, Uretinex-net: Retinex-based deep unfolding network for low-light image enhancement, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5901–5910
2022
-
[10]
Jiang, X
Y. Jiang, X. Gong, D. Liu, Y. Cheng, C. Fang, X. Shen, J. Yang, P. Zhou, Z. Wang, Enlightengan: Deep light enhancement without paired supervision, IEEE transactions on image processing 30 (2021) 2340–2349
2021
-
[11]
C. Li, C. Guo, C. C. Loy, Learning to enhance low-light image via zero- reference deep curve estimation, IEEE transactions on pattern analysis and machine intelligence 44 (8) (2021) 4225–4238. 37
2021
-
[12]
R. Liu, L. Ma, J. Zhang, X. Fan, Z. Luo, Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 10561–10570
2021
-
[13]
L. Ma, T. Ma, R. Liu, X. Fan, Z. Luo, Toward fast, flexible, and robust low-light image enhancement, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5637– 5646
2022
-
[14]
Mittal, A
A. Mittal, A. K. Moorthy, A. C. Bovik, No-reference image quality assessment in the spatial domain, IEEE Transactions on image processing 21 (12) (2012) 4695–4708
2012
-
[15]
A. Mittal, R. Soundararajan, A. C. Bovik, Making a “completely blind” image quality analyzer.", IEEE Signal Processing Letters 20 (3) (2013) 209–212.doi:10.1109/LSP.2012.2227726
-
[16]
Kimmel, M
R. Kimmel, M. Elad, D. Shaked, R. Keshet, I. Sobel, A variational framework for retinex, International Journal of computer vision 52 (1) (2003) 7–23
2003
-
[17]
M. K. Ng, W. Wang, A total variation model for retinex, SIAM Journal on Imaging Sciences 4 (1) (2011) 345–365
2011
-
[18]
M. Zhu, P. Pan, W. Chen, Y. Yang, Eemefn: Low-light image enhance- ment via edge-enhanced multi-exposure fusion network, in: Proceedings of the AAAI conference on artificial intelligence, Vol. 34, 2020, pp. 13106– 13113
2020
-
[19]
Z. Ying, G. Li, Y. Ren, R. Wang, W. Wang, A new image contrast en- hancement algorithm using exposure fusion framework, in: International conference on computer analysis of images and patterns, Springer, 2017, pp. 36–46
2017
-
[20]
X. Fu, Y. Liao, D. Zeng, Y. Huang, X.-P. Zhang, X. Ding, A probabilistic method for image enhancement with simultaneous illumination and reflectance estimation, IEEE Transactions on Image Processing 24 (12) (2015) 4965–4977. 38
2015
-
[21]
C. Lee, C. Lee, C.-S. Kim, Contrast enhancement based on layered difference representation of 2d histograms, IEEE transactions on image processing 22 (12) (2013) 5372–5384
2013
-
[22]
K. Ma, K. Zeng, Z. Wang, Perceptual quality assessment for multi- exposure image fusion, IEEE Transactions on Image Processing 24 (11) (2015) 3345–3356
2015
-
[23]
S. Wang, J. Zheng, H.-M. Hu, B. Li, Naturalness preserved enhancement algorithm for non-uniform illumination images, IEEE transactions on image processing 22 (9) (2013) 3538–3548
2013
-
[24]
Vonikakis, R
V. Vonikakis, R. Kouskouridas, A. Gasteratos, On the evaluation of illu- mination compensation algorithms, Multimedia Tools and Applications 77 (8) (2018) 9211–9231
2018
-
[25]
Liang, C
Z. Liang, C. Li, S. Zhou, R. Feng, C. C. Loy, Iterative prompt learning for unsupervised backlit image enhancement, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8094–8103
2023
-
[26]
Bychkovsky, S
V. Bychkovsky, S. Paris, E. Chan, F. Durand, Learning photographic global tonal adjustment with a database of input/output image pairs, in: CVPR 2011, IEEE, 2011, pp. 97–104
2011
-
[27]
Y. Wang, R. Wan, W. Yang, H. Li, L.-P. Chau, A. Kot, Low-light image enhancement with normalizing flow, in: Proceedings of the AAAI conference on artificial intelligence, Vol. 36, 2022, pp. 2604–2612
2022
-
[28]
X. Xu, R. Wang, C.-W. Fu, J. Jia, Snr-aware low-light image enhance- ment, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 17714–17724
2022
-
[29]
Z. Fu, Y. Yang, X. Tu, Y. Huang, X. Ding, K.-K. Ma, Learning a simple low-light image enhancer from paired low-light instances, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22252–22261
2023
- [30]
-
[31]
Afifi, K
M. Afifi, K. G. Derpanis, B. Ommer, M. S. Brown, Learning multi-scale photo exposure correction, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9157–9167
2021
-
[32]
Zhao, S.-P
L. Zhao, S.-P. Lu, T. Chen, Z. Yang, A. Shamir, Deep symmetric network for underexposed image enhancement with recurrent attentional learning, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12075–12084
2021
-
[33]
Zhang, L
L. Zhang, L. Zhang, X. Liu, Y. Shen, S. Zhang, S. Zhao, Zero-shot restorationofback-litimagesusingdeepinternallearning, in: Proceedings of the 27th ACM international conference on multimedia, 2019, pp. 1623– 1631. 40
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.