Local Causal Attribution of Chain-of-Thought Reasoning
Pith reviewed 2026-06-26 12:40 UTC · model grok-4.3
The pith
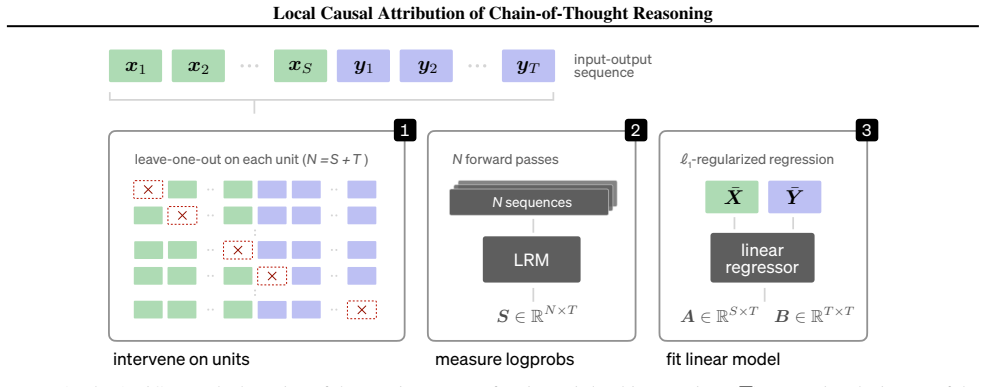
AttriCoT attributes causal importance to each unit in a chain-of-thought trace using a structural causal model estimated with O(U) forward passes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
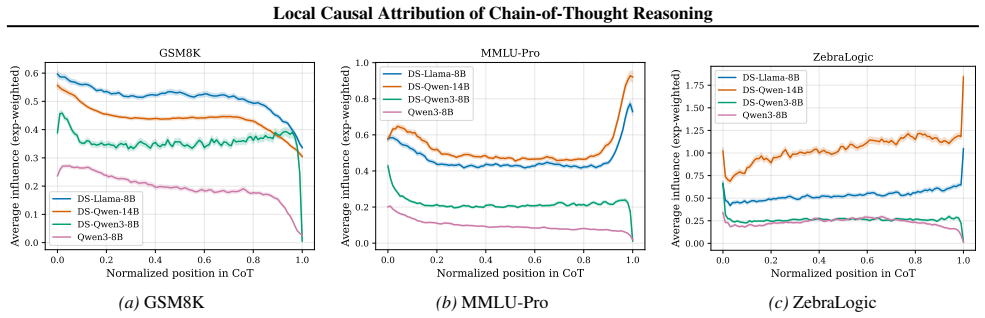
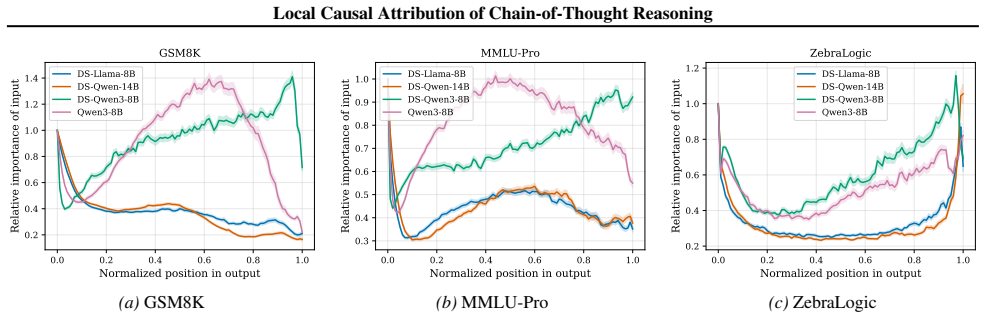
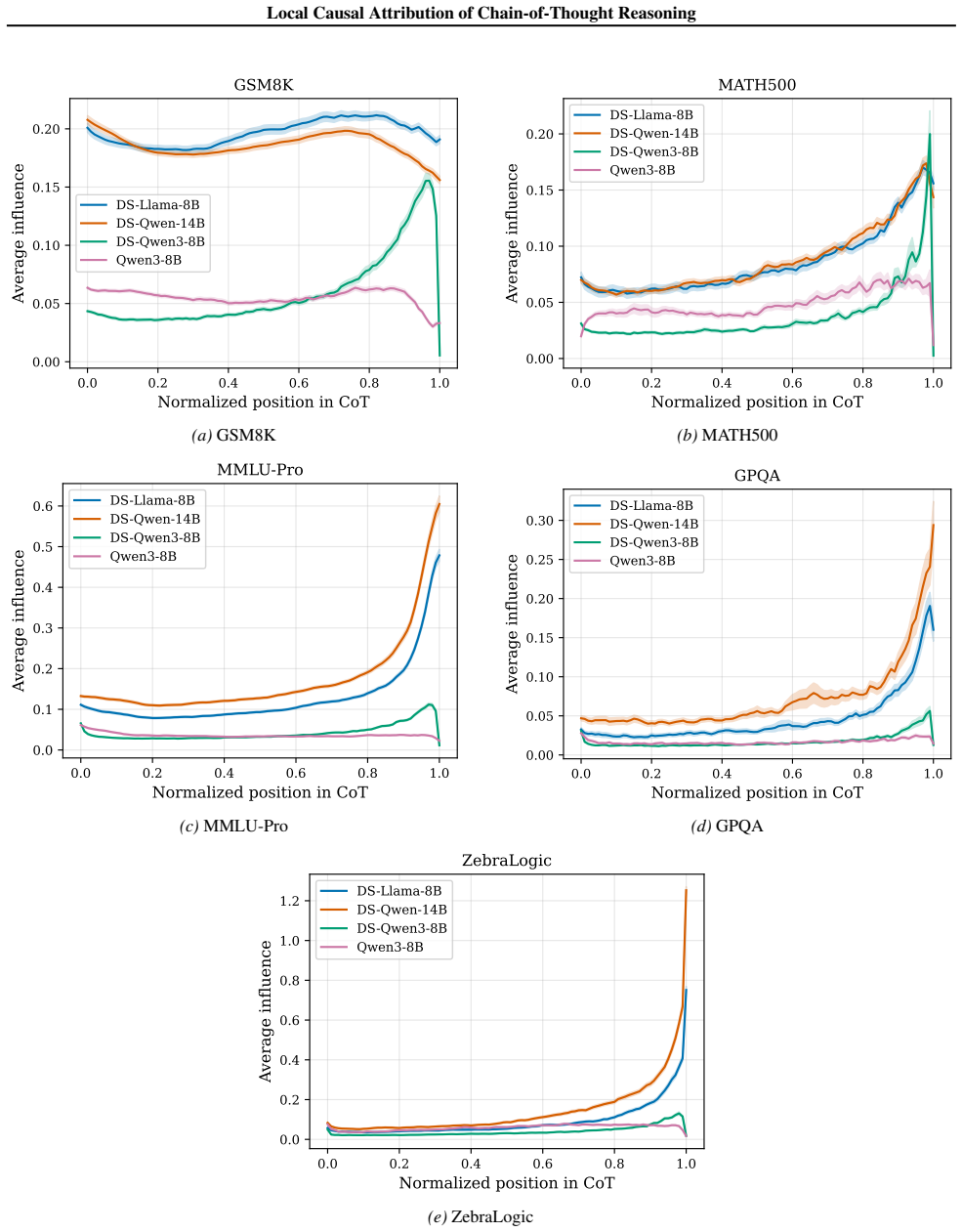
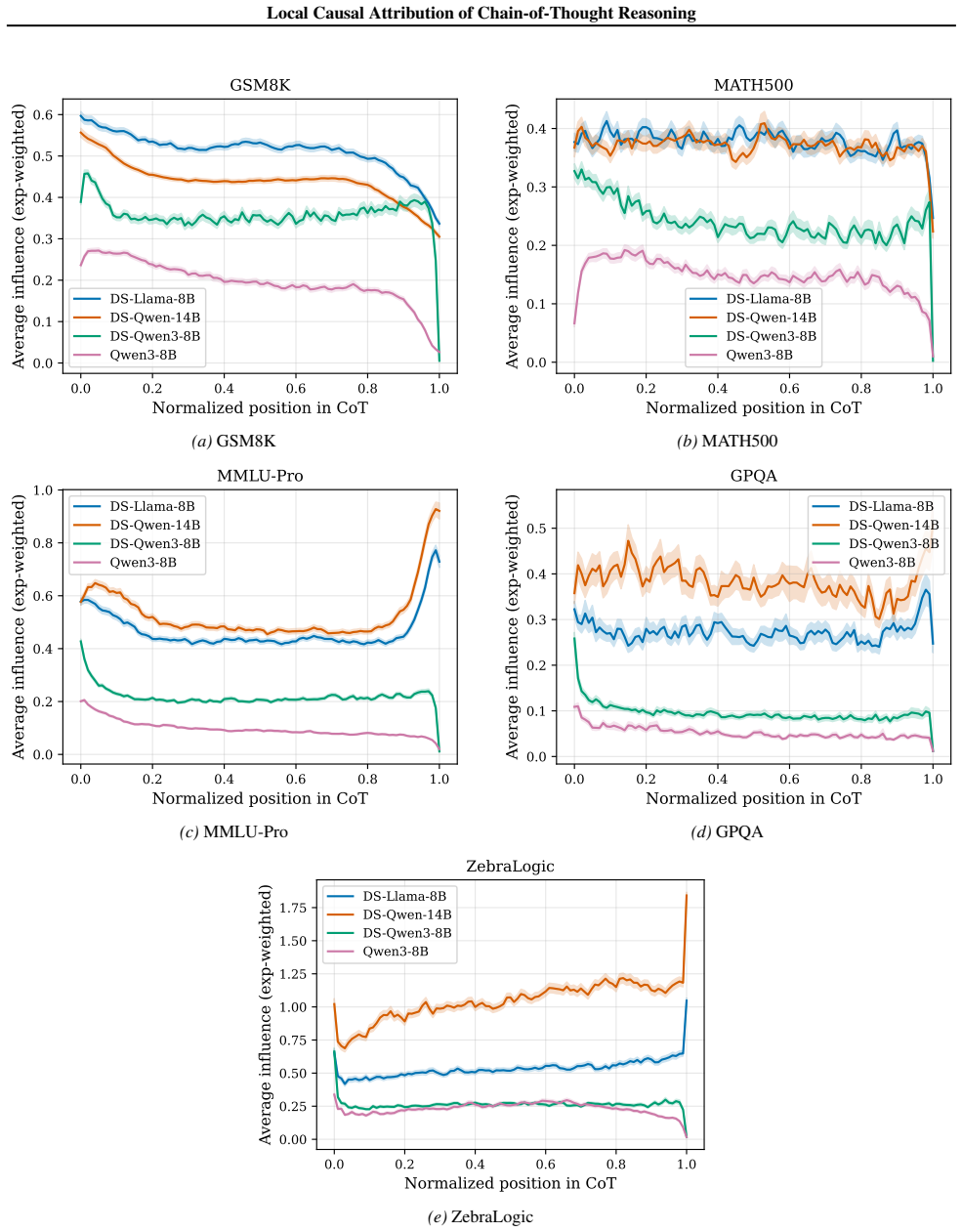
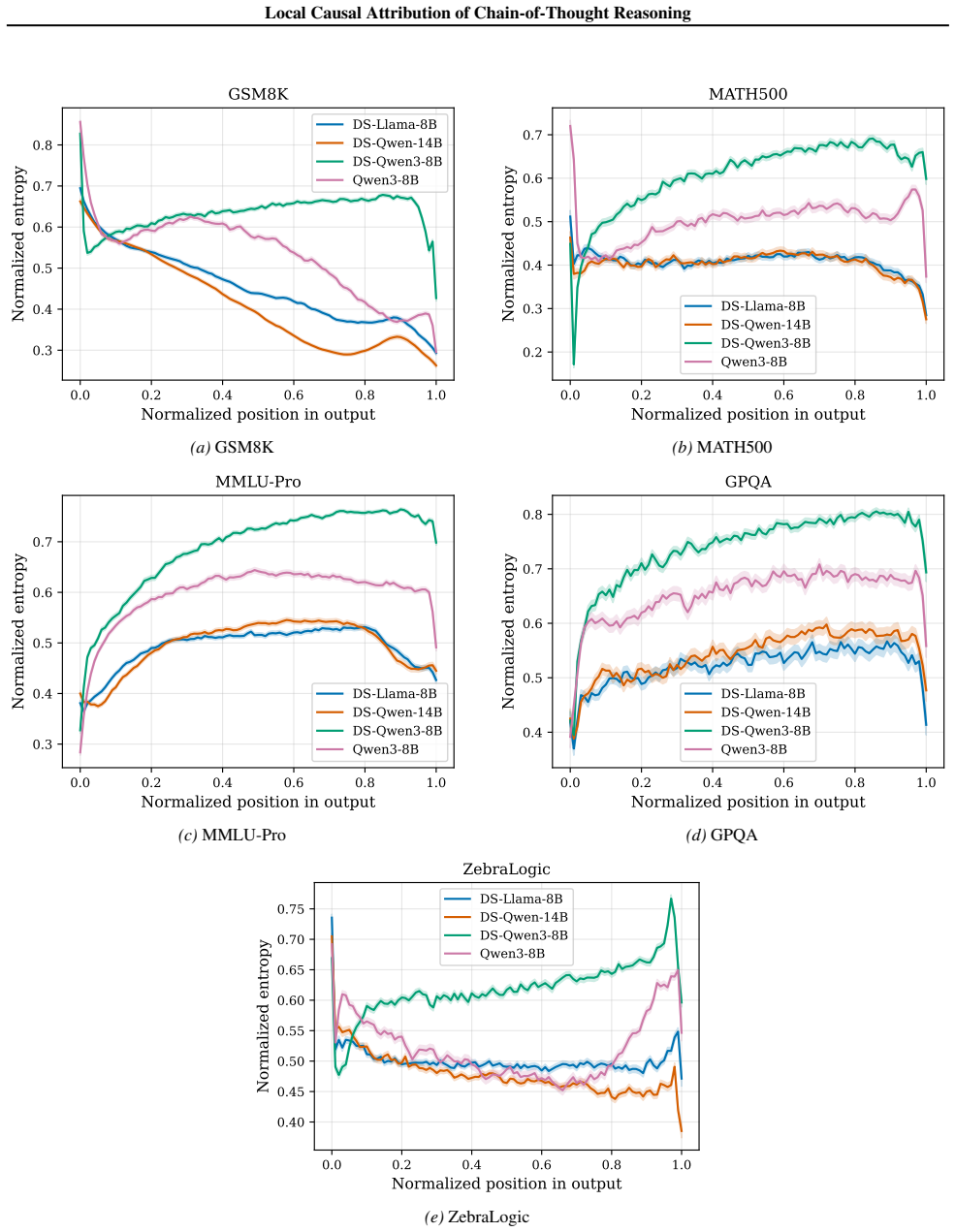
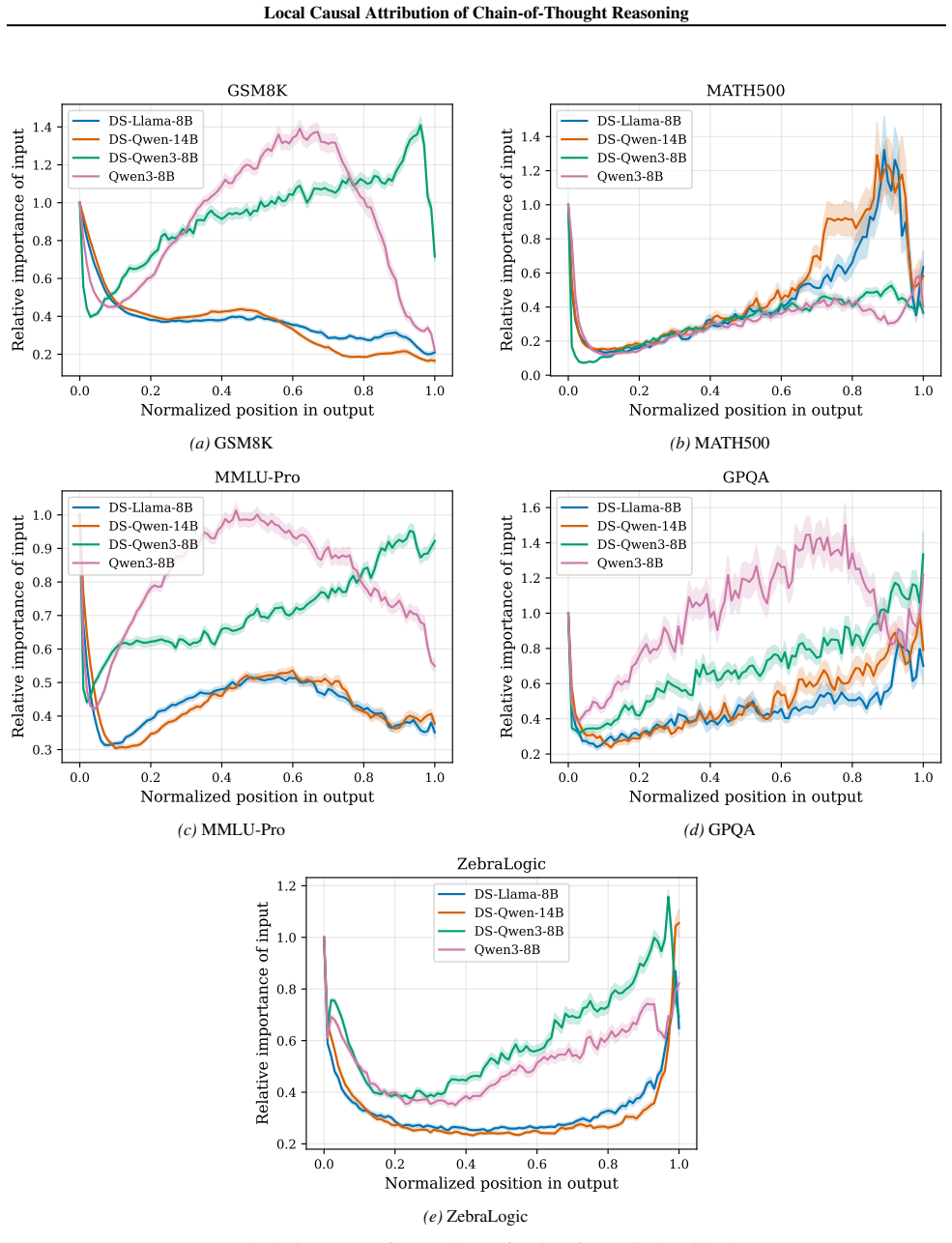
The central discovery is that constructing a structural causal model on the units of a chain-of-thought trace and estimating importance parameters via O(U) forward passes yields attributions that are more faithful to the model's behavior, as validated by perturbation curve evaluations on multiple datasets and models. This also uncovers variations in reasoning structures across different models and problem domains.
What carries the argument
AttriCoT, the black-box algorithm that estimates importance parameters in a structural causal model built on CoT units using O(U) forward passes.
Load-bearing premise
The structural causal model constructed on the units of a given CoT trace accurately captures the true causal dependencies among those units and their effect on output log-probabilities.
What would settle it
A direct comparison where perturbation curves for AttriCoT do not outperform alternatives on additional datasets or models would falsify the claim of superior faithfulness.
Figures

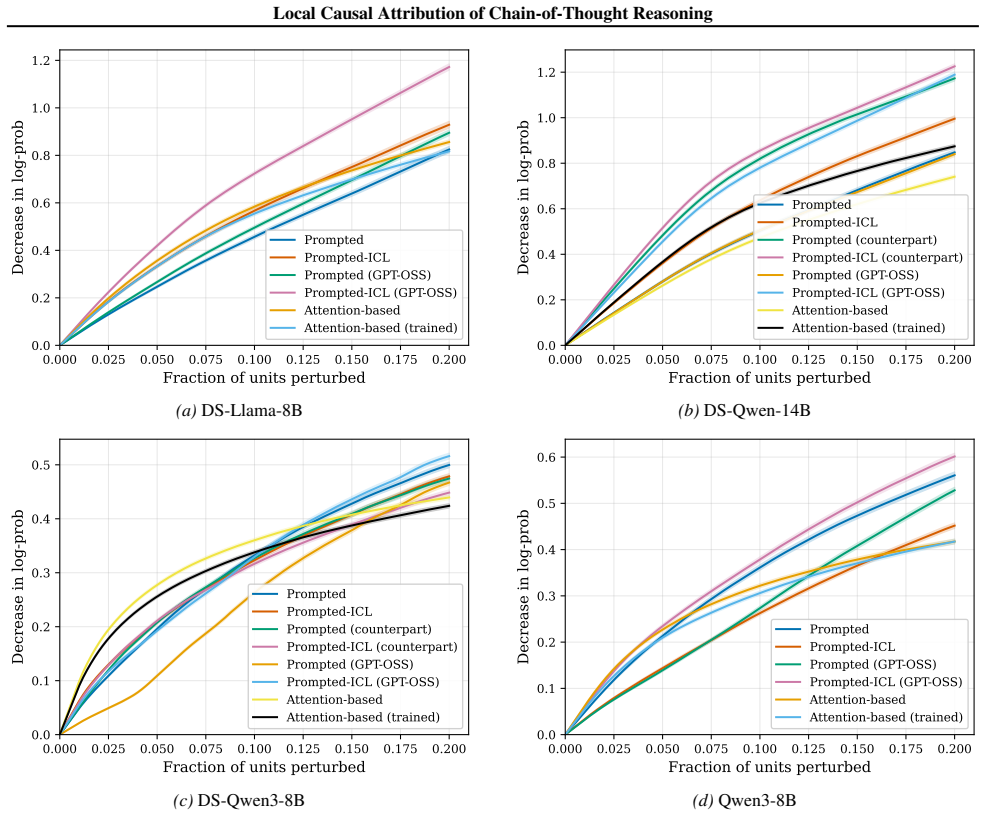
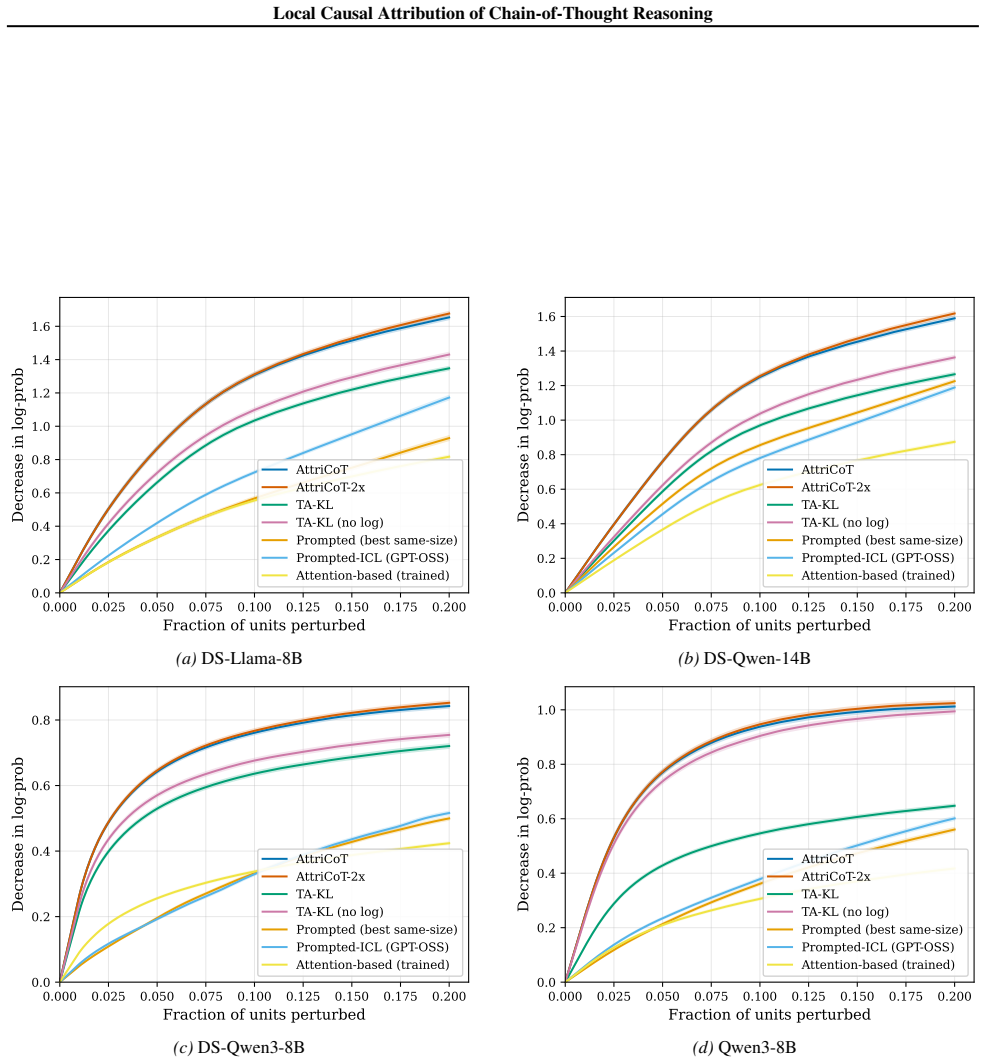
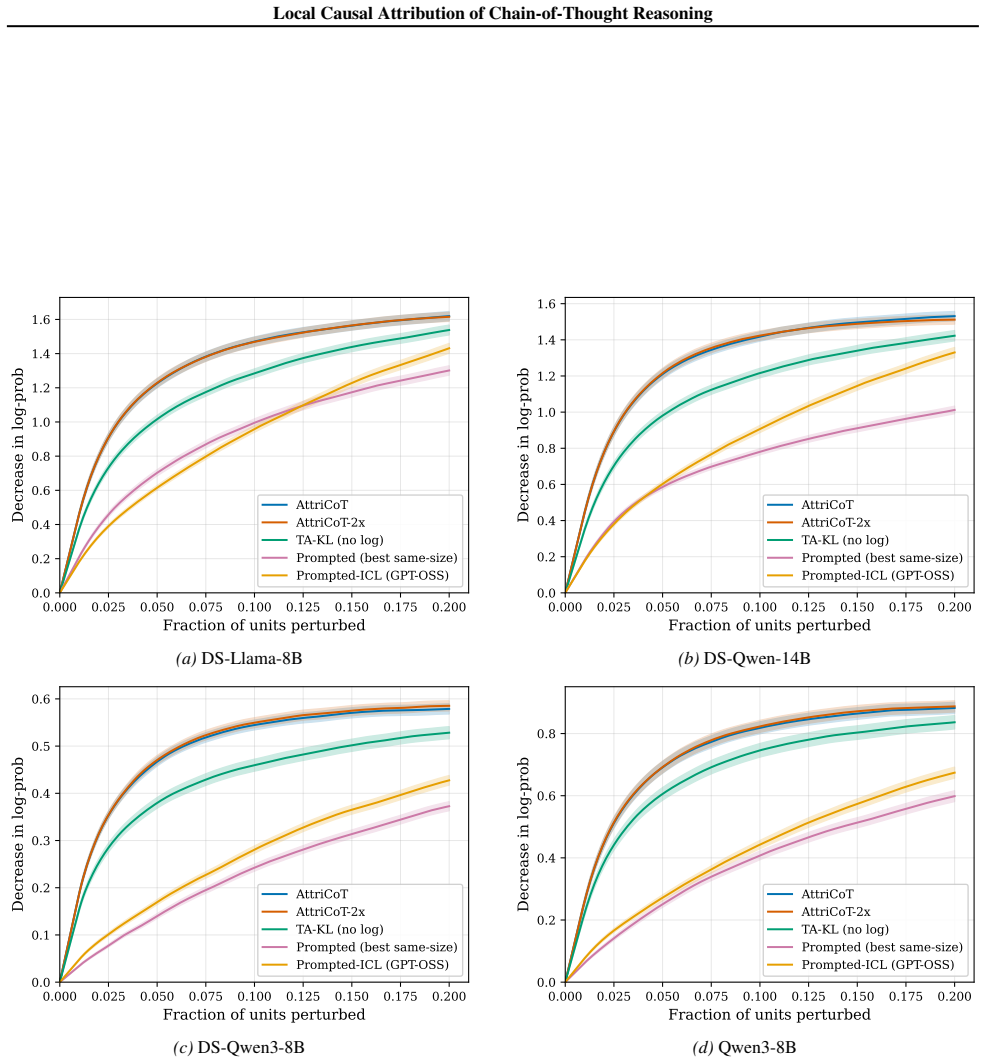
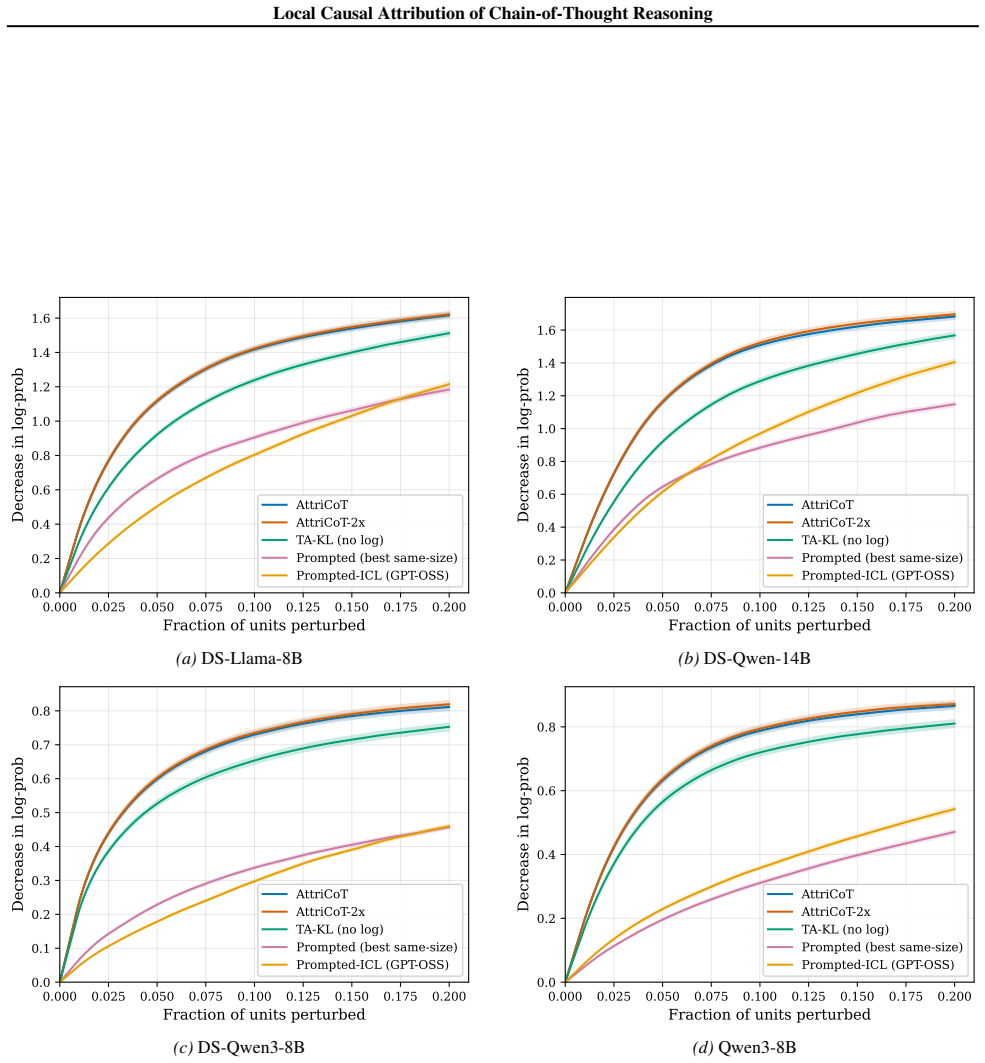
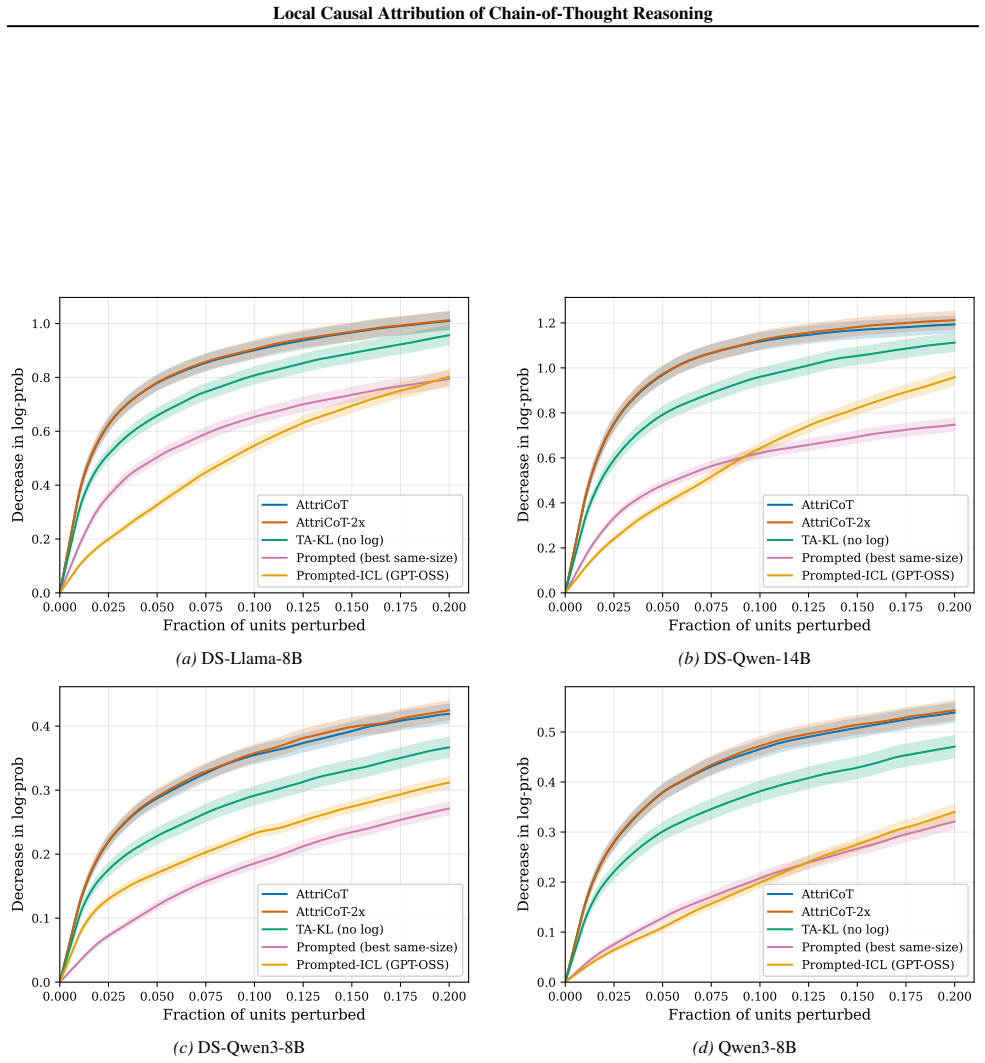
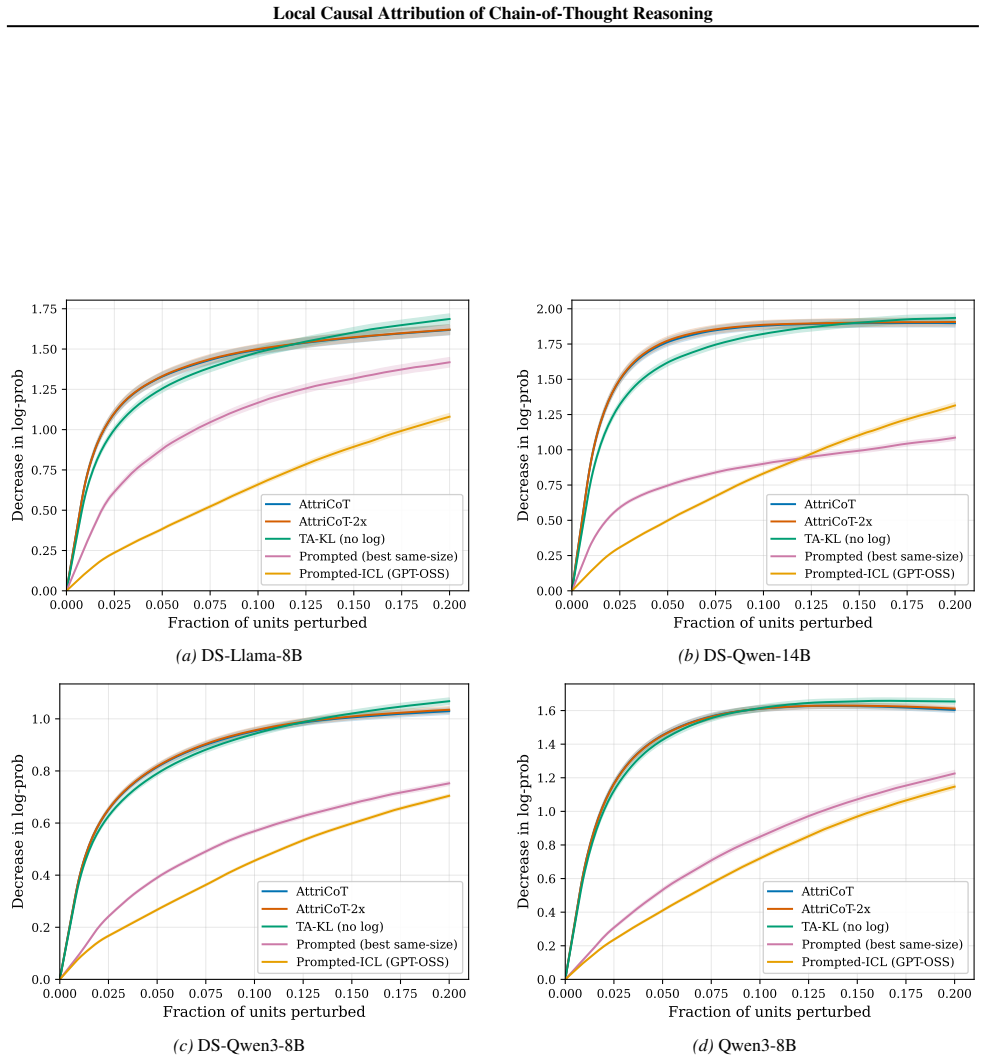
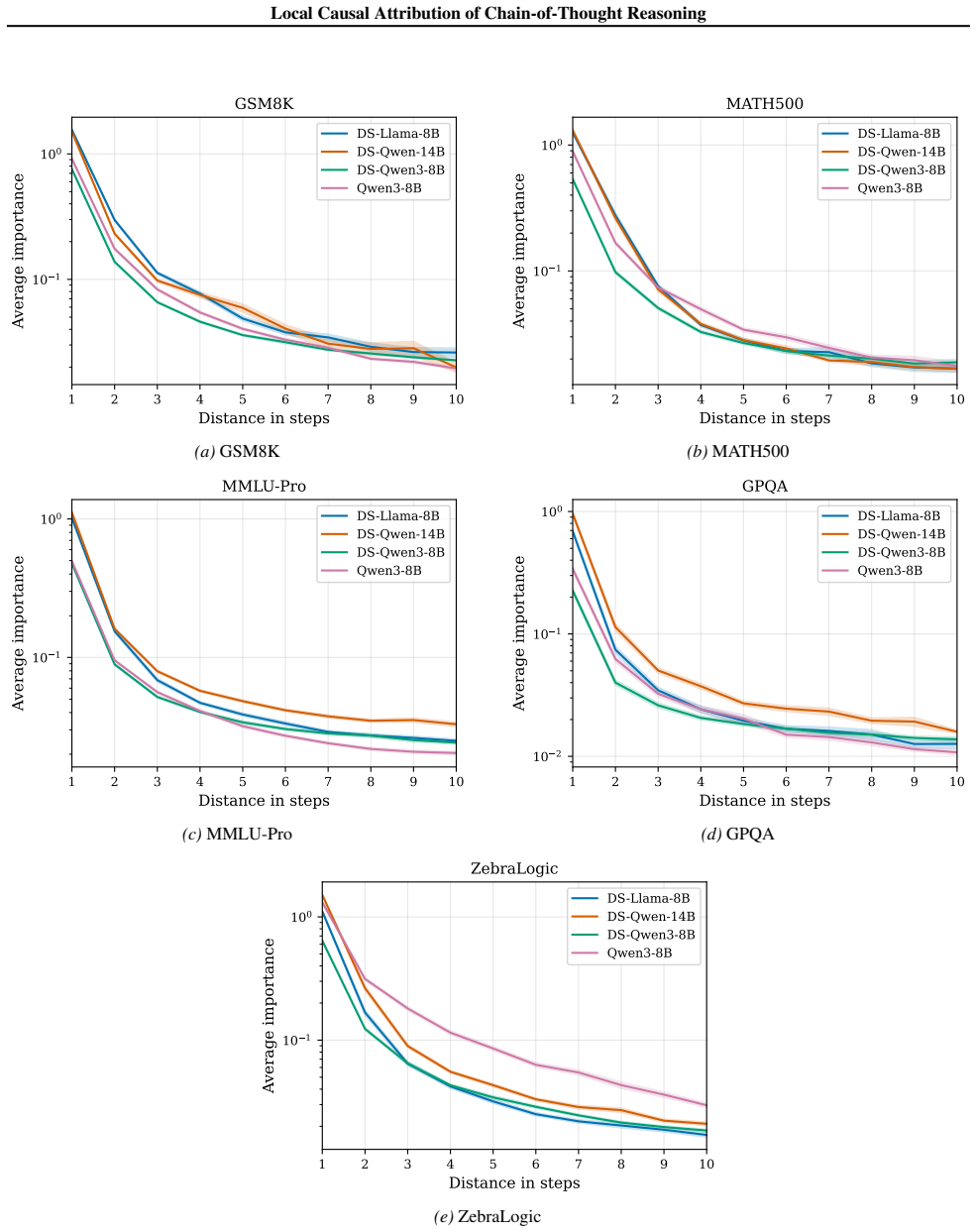
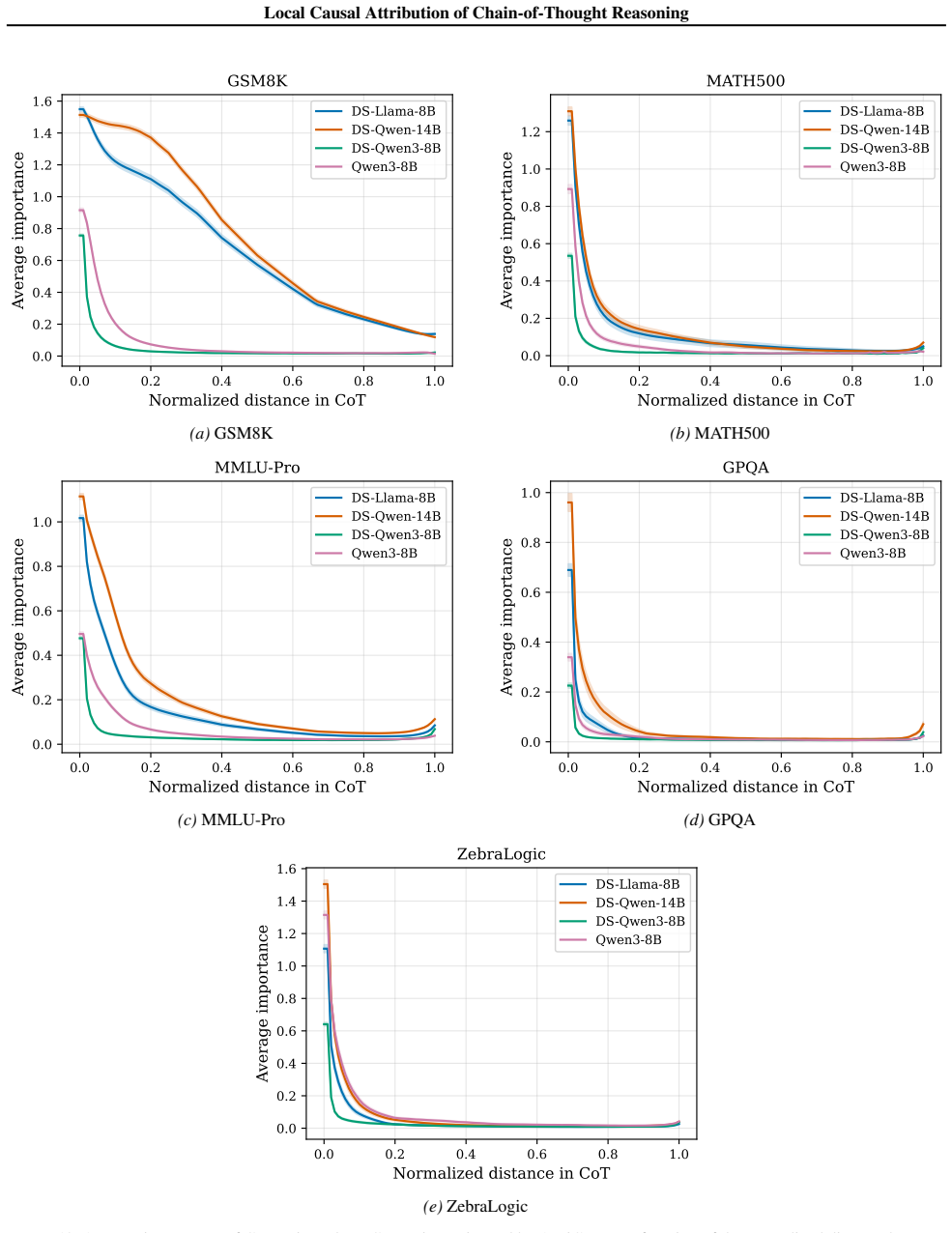
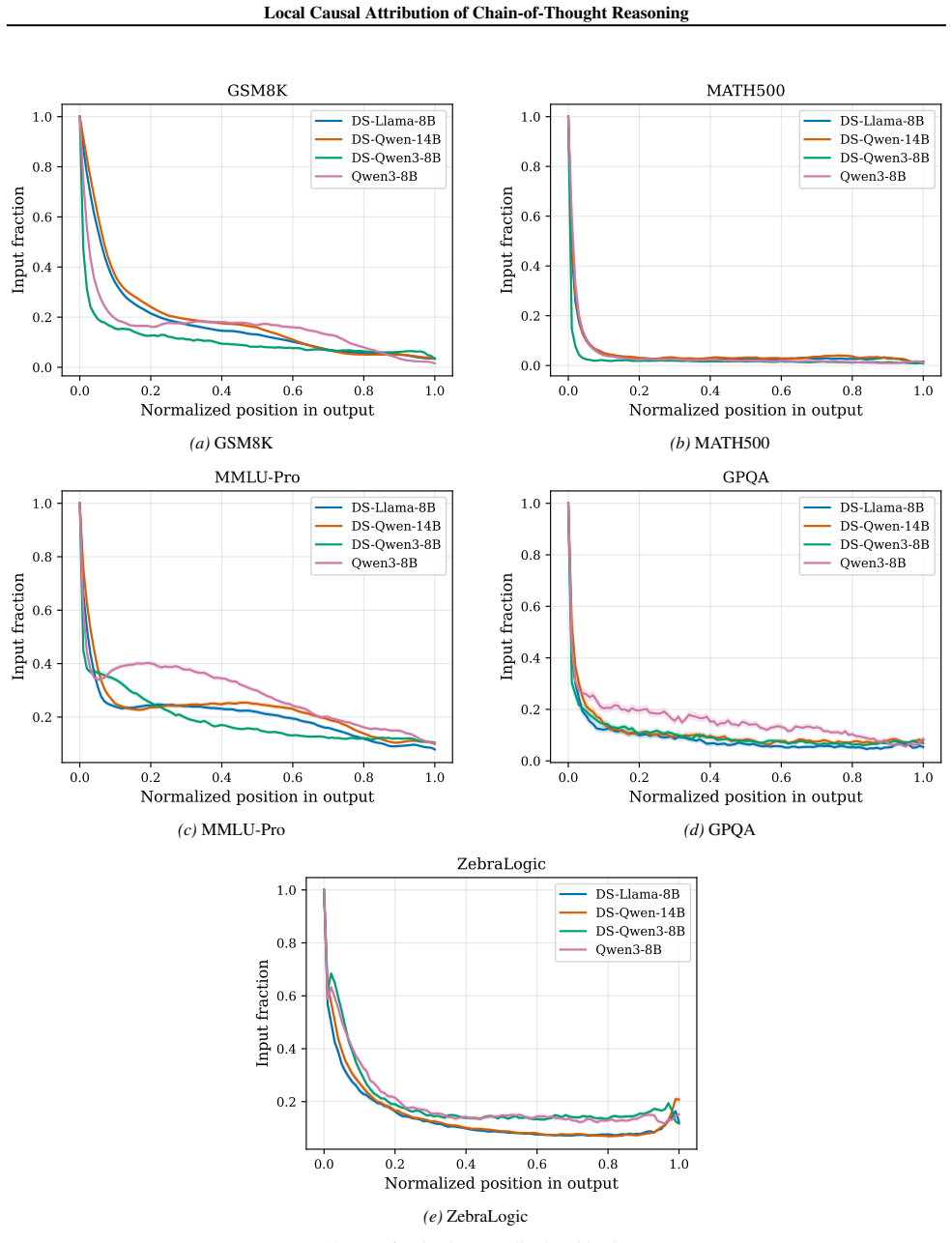
read the original abstract
Understanding the causal structure of a language model's thought process is a problem of significant importance for both transparency and safety. In this work, we take a local approach toward this goal by analyzing the causal relationships among individual components, termed units, of a given, specific chain-of-thought trace. We construct a structural causal model on these units and relate each unit to the log probability of generating (subsequent) output units. Our algorithm, termed AttriCoT, is a black-box method that performs attribution by estimating importance parameters in the structural causal model using $O(U)$ forward passes through the model, where $U$ is the number of units. Evaluation of perturbation curves across 5 datasets and 4 reasoning models shows that AttriCoT produces attributions that are more faithful to the model's behavior than alternative methods. The attribution results also reveal notable differences in thought structure between models and domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AttriCoT, a black-box algorithm for local causal attribution of chain-of-thought (CoT) reasoning. It constructs a structural causal model (SCM) over individual units of a given CoT trace, relates each unit to the log-probability of subsequent output units, and estimates importance parameters via O(U) forward passes. Faithfulness is assessed via perturbation-curve evaluation on 5 datasets and 4 reasoning models, with the claim that AttriCoT attributions are more faithful than those from alternative methods; the work also reports differences in thought structure across models and domains.
Significance. If the SCM is correctly specified and the perturbation evaluation is robust, the method offers an efficient, scalable way to obtain local causal attributions for LLM reasoning traces. This could support interpretability and safety analyses. The O(U) query complexity and multi-dataset/multi-model evaluation are positive features if the faithfulness metric is shown to be non-circular and the SCM assumptions are validated.
major comments (2)
- [Abstract, §4] Abstract and §4 (Evaluation): The central claim that AttriCoT attributions are more faithful rests on perturbation-curve results, yet no details are supplied on unit segmentation, the precise form of the SCM structural equations, the definition of interventions, the choice of baselines, or the presence of error bars/statistical tests. Without these, the comparison cannot be reproduced or assessed for validity.
- [§3] §3 (Method): The SCM is described as relating units to subsequent log-probabilities, but the paper does not specify how the graph structure is determined or whether the structural equations are linear, additive, or otherwise; misspecification here would render the estimated importance parameters non-causal and the downstream faithfulness comparison uninformative.
minor comments (2)
- [Abstract] The abstract states the method uses O(U) forward passes; clarify whether this count includes any overhead for graph construction or baseline comparisons.
- [§3] Provide explicit definitions or pseudocode for how units are extracted from a CoT trace and how the SCM is instantiated for a concrete example.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the two major comments point by point below. Where the manuscript lacks sufficient detail for reproducibility, we will expand the relevant sections in the revision.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Evaluation): The central claim that AttriCoT attributions are more faithful rests on perturbation-curve results, yet no details are supplied on unit segmentation, the precise form of the SCM structural equations, the definition of interventions, the choice of baselines, or the presence of error bars/statistical tests. Without these, the comparison cannot be reproduced or assessed for validity.
Authors: We agree that the current version does not provide enough implementation-level detail for independent reproduction of the perturbation-curve experiments. In the revised manuscript we will add, in §4 and the appendix, (i) the exact unit segmentation rule used for each model and dataset, (ii) the explicit linear additive form of the structural equations, (iii) the precise do-intervention operator applied to each unit, (iv) the baseline value chosen for each intervention, and (v) error bars together with the statistical test used to compare curves. These additions will be placed before the faithfulness results are presented. revision: yes
-
Referee: [§3] §3 (Method): The SCM is described as relating units to subsequent log-probabilities, but the paper does not specify how the graph structure is determined or whether the structural equations are linear, additive, or otherwise; misspecification here would render the estimated importance parameters non-causal and the downstream faithfulness comparison uninformative.
Authors: The graph is the temporal DAG induced by the order of units in the given CoT trace (earlier units may affect later ones). The structural equations are linear and additive, with each unit’s contribution entering as a scalar multiplier on the log-probability of subsequent tokens; the O(U) forward-pass procedure estimates these multipliers under the linear assumption. We acknowledge that the current text leaves these modeling choices implicit. In the revision we will state the graph-construction rule and the linear-additive form explicitly in §3, add a short discussion of the linearity assumption and its potential misspecification, and note that the faithfulness metric is intended to be evaluated under the same modeling assumptions used for attribution. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents AttriCoT as a method that constructs an SCM on CoT units, estimates importance parameters via O(U) forward passes, and then evaluates faithfulness via separate perturbation-curve experiments on held-out interventions. No equation or step reduces a reported result to a fitted parameter by construction, nor does any load-bearing claim rest on a self-citation chain. The faithfulness metric compares external perturbation behavior against the estimated attributions rather than re-using the same fitted values, satisfying the default expectation of an independent derivation. The central premise (SCM fidelity) is an explicit modeling assumption, not a hidden definitional loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A structural causal model on the units of a given CoT trace can be constructed and its parameters estimated from O(U) forward passes.
- domain assumption Perturbation curves provide a faithful measure of attribution quality.
Reference graph
Works this paper leans on
-
[1]
Atanasova, P., Camburu, O.-M., Lioma, C., Lukasiewicz, T., Simonsen, J
URL https://openreview.net/forum? id=L8094Whth0. Atanasova, P., Camburu, O.-M., Lioma, C., Lukasiewicz, T., Simonsen, J. G., and Augenstein, I. Faithfulness tests for natural language explanations. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.),Proceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (Volume 2: Sho...
-
[2]
acl-short.25/
URL https://aclanthology.org/2023. acl-short.25/. Barez, F., Wu, T.-Y ., Arcuschin, I., Lan, M., Wang, V ., Siegel, N., Collignon, N., Neo, C., Lee, I., Paren, A., et al. Chain-of-thought is not explainability.Preprint, alphaXiv, pp. v1, 2025. Bogdan, P. C., Macar, U., Nanda, N., and Conmy, A. Thought anchors: Which LLM reasoning steps matter? In Mechanis...
2023
-
[3]
Cao, L., Zou, Y ., Peng, C., Chen, R., Ning, W., and Li, Y
URL https://openreview.net/forum? id=VnSlfeRCaU. Cao, L., Zou, Y ., Peng, C., Chen, R., Ning, W., and Li, Y . Step guided reasoning: Improving mathematical rea- soning using guidance generation and step reasoning. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Confer- ence on Empirical Methods in Natural...
2025
-
[4]
11 Mitigating Multimodal Hallucinations via In-Context Visual Contrastive Optimization Manevich, A
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[5]
URL https://aclanthology.org/2025. emnlp-main.1068/. Chen, H., Zheng, G., and Ji, Y . Generating hierarchical explanations on text classification via feature interaction detection. In Jurafsky, D., Chai, J., Schluter, N., and Tetreault, J. (eds.),Proceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pp. 9 Local Causal ...
-
[6]
Reasoning Models Don't Always Say What They Think
URL https://aclanthology.org/2020. acl-main.494/. Chen, Y ., Benton, J., Radhakrishnan, A., Uesato, J., Deni- son, C., Schulman, J., Somani, A., Hase, P., Wagner, M., Roger, F., et al. Reasoning models don’t always say what they think.arXiv preprint arXiv:2505.05410, 2025. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-3035 2020
-
[7]
URL https://aclanthology.org/2024. findings-acl.832/. et al., A. G. The Llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783. Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Proce...
Pith/arXiv arXiv 2024
-
[8]
Ju, Y ., Zhang, Y ., Liu, K., and Zhao, J
URL https://openreview.net/forum? id=7Bywt2mQsCe. Ju, Y ., Zhang, Y ., Liu, K., and Zhao, J. A hierarchical explanation generation method based on feature inter- action detection. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.),Findings of the Association for Com- putational Linguistics: ACL 2023, pp. 12600–12611, Toronto, Canada, July 2023. Associ...
-
[9]
Measuring Faithfulness in Chain-of-Thought Reasoning
URL https://aclanthology.org/2023. findings-acl.798/. Lanham, T., Chen, A., Radhakrishnan, A., Steiner, B., Deni- son, C., Hernandez, D., Li, D., Durmus, E., Hubinger, E., Kernion, J., et al. Measuring faithfulness in chain- of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023. Lee, J. and Hockenmaier, J. Evaluating step-by-step rea- soning traces: ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.findings-emnlp 2023
-
[10]
findings-emnlp.94/
URL https://aclanthology.org/2025. findings-emnlp.94/. Lin, B. Y ., Bras, R. L., Richardson, K., Sabharwal, A., Poovendran, R., Clark, P., and Choi, Y . ZebraLogic: On the scaling limits of LLMs for logical reasoning. InForty- second International Conference on Machine Learning,
2025
-
[11]
Lundberg, S
URL https://openreview.net/forum? id=sTAJ9QyA6l. Lundberg, S. M. and Lee, S.-I. A unified approach to interpreting model predictions. In Guyon, I., Luxburg, U. V ., Bengio, S., Wallach, H., Fer- gus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Sys- tems 30, pp. 4765–4774. Curran Associates, Inc.,
-
[12]
URL http://papers.nips.cc/paper/ 7062-a-unified-approach-to-interpreting-model-predictions. pdf. Macar, U., Bogdan, P. C., Rajamanoharan, S., and Nanda, N. Thought branches: Interpreting LLM reasoning requires resampling. InThe Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=bVsAuIOvJ5. Miglani, ...
2026
-
[13]
URL https: //aclanthology.org/2023.nlposs-1.19
doi: 10.18653/v1/2023.nlposs-1.19. URL https: //aclanthology.org/2023.nlposs-1.19. Minegishi, G., Furuta, H., Kojima, T., Iwasawa, Y ., and Matsuo, Y . Topology of reasoning: Understanding large reasoning models through reasoning graph properties. 10 Local Causal Attribution of Chain-of-Thought Reasoning InThe Thirty-ninth Annual Conference on Neural In- ...
-
[14]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[15]
URL https://aclanthology.org/2025. acl-long.1553/. nostalgebraist. Interpreting GPT: the logit lens. Less- Wrong, 2020. URL https://www.lesswrong. com/posts/AcKRB8wDpdaN6v6ru/ interpreting-gpt-the-logit-lens. Parcalabescu, L. and Frank, A. On measuring faithful- ness or self-consistency of natural language explana- tions. In Ku, L.-W., Martins, A., and Sr...
-
[16]
URL https://aclanthology.org/2024. findings-emnlp.882/. Pearl, J.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2nd edition, 2009. Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. GPQA: A graduate-level Google-proof Q&A benchmark. InFirst Conference on Language Modeling, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023 2024
-
[17]
unfaith- fulness
URL https://aclanthology.org/2025. emnlp-main.504/. V on Arx, S. and Deng, A. CoT may be highly informative despite “unfaith- fulness”. https://metr.org/blog/ 2025-08-08-cot-may-be-highly-informative-despite-unfaithfulness/ , 8 2025. Wang, Y ., Ma, X., Zhang, G., Ni, Y ., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., Li, T., Ku, M., Wang,...
2025
-
[18]
URL https://openreview.net/forum? id=wVj7dB7waI. Zaman, K. and Srivastava, S. Is chain-of-thought really not explainability? Chain-of-thought can be faithful with- out hint verbalization, 2025. URL https://arxiv. org/abs/2512.23032. Zhang, A., Chen, Y ., Pan, J., Zhao, C., Panda, A., Li, J., and He, H. Reasoning models know when they’re right: Probing hid...
Pith/arXiv arXiv 2025
-
[19]
repre- sentational
URL https://openreview.net/forum? id=CxiNICq0Rr. 12 Local Causal Attribution of Chain-of-Thought Reasoning A. Related Work This section highlights the existing methods in the literature, what they aim to do, and how they work. Table 3 presents an overview of existing CoT attribution methods (Zaman & Srivastava, 2025). Method Ref. Type Intervention Causal ...
2025
-
[20]
attention scores
corrupts individual reasoning steps and mesuare how the confidence of the model though its hidden state is affected. Black-box step-level causal methods.Recent work suggested black-box methods, evaluating the causality of a CoT at a step-level. These methods perturb individual reasoning steps and evaluate the impact of such edits on the output or on the f...
2024
-
[21]
\n\n", since models often produce a summary of their reasoning in their final answer and continue to use the
When there is a choice between ⌊TCoT/100⌋ or ⌈TCoT/100⌉, the one that keeps the cumulative length in characters closer to that of a uniform distribution is chosen. Segmentation of the final answer.We also segment the final answer by splitting on "\n\n", since models often produce a summary of their reasoning in their final answer and continue to use the "...
2025
-
[22]
This enables a fairer comparison using the same unit segmentation for both AttriCoT and Thought Anchors
More general units:We generalized Thought Anchors-KL to operate on the same more general units used by AttriCoT (prompt, CoT, and final answer units) rather than the original’s restriction to CoT sentences only. This enables a fairer comparison using the same unit segmentation for both AttriCoT and Thought Anchors
-
[23]
Batch forward passes:Like AttriCoT-LOO, Thought Anchors-KL performs leave-one-out perturbations on the unit sequence and then runs forward passes through the LLM. In the case of Thought Anchors-KL, each forward pass computes token distributions at all token positions, rather than just the log probability of the originally generated token in AttriCoT’s cas...
-
[24]
This requires matching token positions in the original sequence with their corresponding token positions in a perturbed sequence
Token position matching:Thought Anchors-KL quantifies the causal effect of a perturbation on a target unit by computing KL divergences between token distributions at every token position in the target unit, and then taking the mean of these KL divergences over the unit. This requires matching token positions in the original sequence with their correspondi...
-
[25]
The authors’ code however does not apply a log transform
Log transform:The Thought Anchors paper (Bogdan et al., 2025) proposed first applying a log transform to KL divergences before taking the mean over a target unit. The authors’ code however does not apply a log transform. We evaluated both versions on the GSM8K dataset, as reported in Table 1, to see which is better for our purpose. 17 Local Causal Attribu...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.