Rethinking Burst Buffer Optimization: Enabling Layout Heterogeneity via Hybrid Analysis and LLM Guidance
Pith reviewed 2026-06-26 11:54 UTC · model grok-4.3
The pith
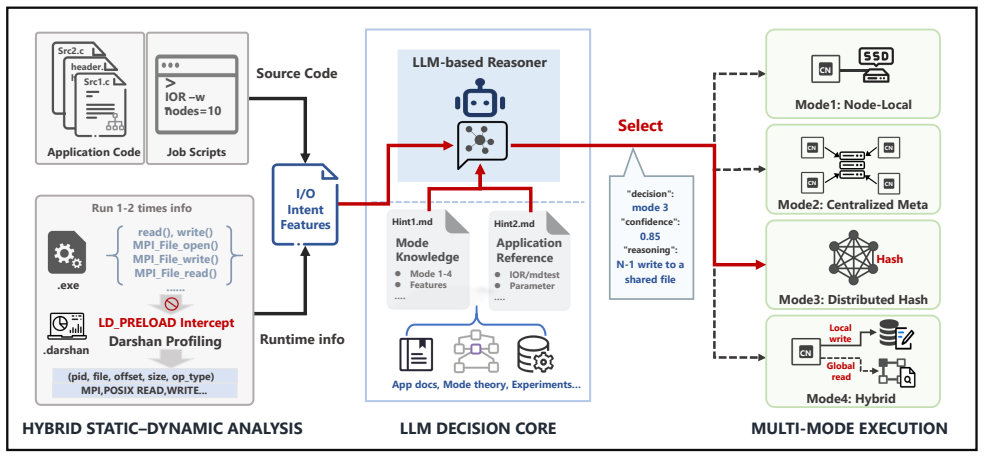
Proteus reconstructs I/O intent from static code and one runtime probe to select optimal burst buffer layouts without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
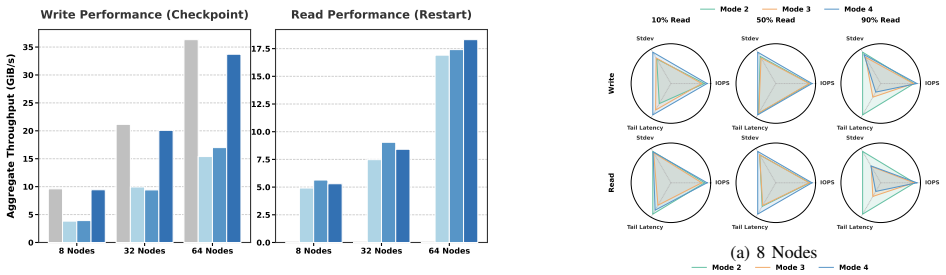
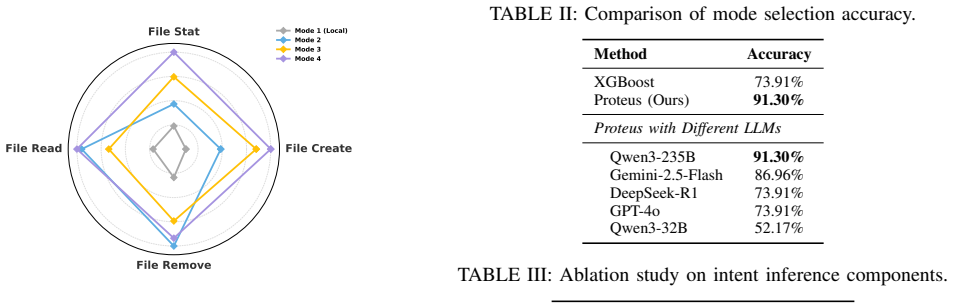
Proteus treats data layout as a first-class optimization dimension in burst buffer file systems. The central claim is that application I/O intent can be reconstructed by synergistically combining static code structures with lightweight runtime signals. Through a hybrid pipeline and a single execution probe, Proteus extracts latent semantic cues to determine the optimal layout prior to production runs, eliminating the need for prior training or exhaustive profiling. Evaluation with representative HPC workloads shows that Proteus achieves 91.30% decision accuracy, delivering up to 3.24× and 2.9× speedups for write-intensive and metadata-intensive workloads, respectively.
What carries the argument
Hybrid pipeline combining static code structures, a single execution probe, and LLM guidance to reconstruct I/O intent and select the optimal data layout.
If this is right
- Layout selection becomes possible before production runs without prior training or exhaustive profiling.
- Write-intensive workloads achieve up to 3.24× speedup when the selected layout is used.
- Metadata-intensive workloads achieve up to 2.9× speedup when the selected layout is used.
- 91.30% accuracy is reached in layout decisions across the evaluated representative HPC workloads.
- Data layout can be optimized as an independent dimension alongside storage parameter tuning.
Where Pith is reading between the lines
- The same hybrid reconstruction approach could be tested on other distributed storage systems where I/O intent is difficult to infer statically.
- Integration with existing parameter-tuning methods might compound gains by addressing both layout and stack settings at once.
- Replacing the LLM component with lighter rule-based or learned classifiers would clarify how much of the accuracy depends on language-model guidance.
- Applying the single-probe method to workloads with more variable or multi-phase I/O patterns would reveal the limits of the current cue extraction.
Load-bearing premise
A single execution probe plus static code structures and LLM guidance are sufficient to reconstruct application I/O intent accurately enough to choose a layout that delivers the reported speedups across diverse HPC workloads.
What would settle it
Running Proteus on an HPC workload where the single probe misses a key I/O pattern and checking whether the predicted layout still yields the claimed speedup would test the reconstruction claim.
Figures










read the original abstract
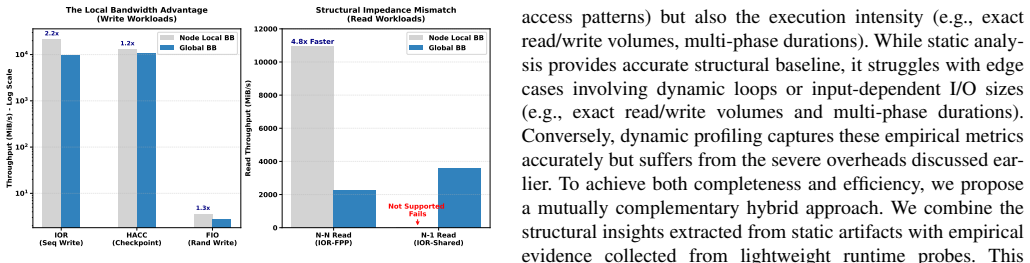
Burst buffers (BBs) are essential for mitigating I/O bottlenecks in modern HPC systems. However, existing BB file systems often suffer from structural performance degradation due to fixed data layouts that fail to align with diverse application behaviors. While current machine-learning-based optimizations focus primarily on tuning storage stack parameters for a given layout, they offer diminishing returns when a fundamental mismatch exists between I/O patterns and the underlying data organization. Furthermore, these approaches typically incur prohibitive costs due to extensive training or intrusive profiling. To bridge this gap, we present Proteus, a semantic-aware BB system that treats data layout as a first-class optimization dimension. The core insight of Proteus is that application I/O intent can be reconstructed by synergetically combining static code structures with lightweight runtime signals. Through a hybrid pipeline and a single execution probe, Proteus extracts latent semantic cues to determine the optimal layout prior to production runs-eliminating the need for prior training or exhaustive profiling. Evaluation with representative HPC workloads shows that Proteus achieves 91.30\% decision accuracy, delivering up to 3.24$\times$ and 2.9$\times$ speedups for write-intensive and metadata-intensive workloads, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Proteus, a semantic-aware burst buffer system for HPC that reconstructs application I/O intent via a hybrid pipeline of static code analysis, a single lightweight runtime execution probe, and LLM guidance. This determines the optimal data layout prior to production runs without prior training or exhaustive profiling. Evaluation on representative HPC workloads is claimed to yield 91.30% decision accuracy along with speedups of up to 3.24× (write-intensive) and 2.9× (metadata-intensive).
Significance. If the empirical claims hold after proper validation of the experimental methodology, the work would be significant for addressing structural mismatches in burst buffer file systems by elevating layout selection to a first-class, low-cost optimization. The hybrid static-plus-probe-plus-LLM approach offers a potential alternative to expensive ML-based parameter tuning, and the elimination of training/profiling overhead could improve practicality for diverse HPC I/O patterns.
major comments (2)
- [Abstract] Abstract: performance numbers (91.30% decision accuracy, 3.24× and 2.9× speedups) are stated with no description of experimental setup, baselines, workload selection criteria, accuracy measurement method, error bars, or per-workload breakdown. This is load-bearing for the central claim that the hybrid pipeline delivers the reported benefits.
- [Method and evaluation description] Method and evaluation description: the core assumption that one execution probe plus static structures and LLM guidance suffices to reconstruct I/O intent is not accompanied by any analysis or mechanism for detecting/compensating phase-varying or input-dependent I/O behavior (e.g., checkpoint size or process count changes). No evidence is supplied that the 91.30% accuracy holds under such conditions.
minor comments (1)
- [Abstract] Abstract: 'synergetically' appears to be a typo for 'synergistically'; missing space before 'eliminating'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance numbers (91.30% decision accuracy, 3.24× and 2.9× speedups) are stated with no description of experimental setup, baselines, workload selection criteria, accuracy measurement method, error bars, or per-workload breakdown. This is load-bearing for the central claim that the hybrid pipeline delivers the reported benefits.
Authors: We agree that the abstract would be strengthened by including brief context on the experimental methodology. In the revised manuscript we will expand the abstract to note the representative HPC workloads evaluated, the comparison baselines, the method used to compute decision accuracy (including per-workload breakdown), and the presence of error bars in the full evaluation section. revision: yes
-
Referee: [Method and evaluation description] Method and evaluation description: the core assumption that one execution probe plus static structures and LLM guidance suffices to reconstruct I/O intent is not accompanied by any analysis or mechanism for detecting/compensating phase-varying or input-dependent I/O behavior (e.g., checkpoint size or process count changes). No evidence is supplied that the 91.30% accuracy holds under such conditions.
Authors: The current evaluation focuses on representative HPC workloads whose I/O patterns are captured by the combination of static code analysis and a single lightweight probe; the LLM component then maps the extracted semantics to layout decisions. We acknowledge that the manuscript does not provide explicit analysis or mechanisms for phase-varying or input-dependent behaviors, nor does it report accuracy under altered checkpoint sizes or process counts. We will add a limitations subsection discussing these cases and potential mitigation strategies in the revised version. revision: partial
Circularity Check
No circularity; empirical claims with no derivation chain
full rationale
The paper describes a systems artifact (Proteus) whose core claims are empirical measurements of decision accuracy and speedups on HPC workloads. No equations, fitted parameters, or mathematical predictions appear in the provided text. The hybrid pipeline and LLM guidance are presented as engineering choices whose effectiveness is validated by runtime experiments rather than derived from self-referential definitions or self-citations. Because there is no load-bearing derivation that reduces to its own inputs, the circularity score is 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the role of burst buffers in leadership-class storage systems,
N. Liu, J. Cope, P. H. Carns, C. D. Carothers, R. B. Ross, G. Grider, A. Crume, and C. Maltzahn, “On the role of burst buffers in leadership-class storage systems,” inIEEE 28th Symposium on Mass Storage Systems and Technologies, MSST 2012, April 16-20, 2012, Asilomar Conference Grounds, Pacific Grove, CA, USA. IEEE Computer Society, 2012, pp. 1–11. [Onlin...
-
[2]
End-to-end I/O portfolio for the summit supercomputing ecosystem,
S. Oral, S. S. Vazhkudai, F. Wang, C. Zimmer, C. Brumgard, J. Hanley, G. Markomanolis, R. G. Miller, D. Leverman, S. Atchley, and V . G. V . Larrea, “End-to-end I/O portfolio for the summit supercomputing ecosystem,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2019, Denver, Colorado, U...
-
[3]
Characterizing output bottlenecks in a supercomputer,
B. Xie, J. S. Chase, D. Dillow, O. Drokin, S. Klasky, S. Oral, and N. Podhorszki, “Characterizing output bottlenecks in a supercomputer,” inSC Conference on High Performance Computing Networking, Storage and Analysis, SC ’12, Salt Lake City, UT, USA - November 11 - 15, 2012, J. K. Hollingsworth, Ed. IEEE/ACM, 2012, p. 8. [Online]. Available: https://doi.o...
-
[4]
Burstmem: A high-performance burst buffer system for scientific applications,
T. Wang, S. Oral, Y . Wang, B. W. Settlemyer, S. Atchley, and W. Yu, “Burstmem: A high-performance burst buffer system for scientific applications,” in2014 IEEE International Conference on Big Data (IEEE BigData 2014), Washington, DC, USA, October 27-30, 2014, J. Lin, J. Pei, X. Hu, W. Chang, R. Nambiar, C. C. Aggarwal, N. Cercone, V . G. Honavar, J. Huan...
-
[5]
Gekkofs - A temporary distributed file system for HPC applications,
M. Vef, N. Moti, T. S ¨uß, T. Tocci, R. Nou, A. Miranda, T. Cortes, and A. Brinkmann, “Gekkofs - A temporary distributed file system for HPC applications,” inIEEE International Conference on Cluster Computing, CLUSTER 2018, Belfast, UK, September 10-13, 2018. IEEE Computer Society, 2018, pp. 319–324. [Online]. Available: https://doi.org/10.1109/CLUSTER.2018.00049
-
[6]
Unifyfs: A user-level shared file system for unified access to distributed local storage,
M. J. Brim, A. T. Moody, S. Lim, R. G. Miller, S. Boehm, C. Stanavige, K. M. Mohror, and S. Oral, “Unifyfs: A user-level shared file system for unified access to distributed local storage,” inIEEE International Parallel and Distributed Processing Symposium, IPDPS 2023, St. Petersburg, FL, USA, May 15-19, 2023. IEEE, 2023, pp. 290–300. [Online]. Available:...
-
[7]
From islands to archipelago: Towards collaborative and adaptive burst buffer for HPC systems,
M. Shao, R. Wang, W. Zhang, K. Lu, Y . Dai, and H. Wu, “From islands to archipelago: Towards collaborative and adaptive burst buffer for HPC systems,” inICS. ACM, 2025, pp. 550–563
2025
-
[8]
Towards practical machine learning frameworks for performance diagnostics in supercomputers,
B. Aksar, E. Sencan, B. Schwaller, V . J. Leung, J. Brandt, B. Kulis, M. Egele, and A. K. Coskun, “Towards practical machine learning frameworks for performance diagnostics in supercomputers,” inPro- ceedings of the First Workshop on AI for Systems, 2023, pp. 1–6
2023
-
[9]
Machine learning assisted HPC workload trace generation for leadership scale storage systems,
A. K. Paul, J. Y . Choi, A. M. Karimi, and F. Wang, “Machine learning assisted HPC workload trace generation for leadership scale storage systems,” inHPDC ’22: The 31st International Symposium on High-Performance Parallel and Distributed Computing, Minneapolis, MN, USA, 27 June 2022 - 1 July 2022, J. B. Weissman, A. Chandra, A. Gavrilovska, and D. Tiwari,...
-
[10]
A survey on machine learning-based hpc i/o analysis and optimization,
J. Peng, L. Yang, H. Wu, W. Zhang, Z. Wu, W. Zhang, J. Li, Y . Dai, and Y . Dong, “A survey on machine learning-based hpc i/o analysis and optimization,”IEEE Transactions on Parallel and Distributed Systems, 2025
2025
-
[11]
I/o behind the scenes: Bandwidth requirements of hpc applications with asynchronous i/o,
R. Macedoet al., “I/o behind the scenes: Bandwidth requirements of hpc applications with asynchronous i/o,” in2024 IEEE International Conference on Cluster Computing (CLUSTER), 2024, pp. 426–439
2024
-
[12]
Scheduling the i/o of hpc applications under congestion,
A. Gainaru, G. Aupy, A. Benoit, F. Cappello, Y . Robert, and M. Snir, “Scheduling the i/o of hpc applications under congestion,” in2015 IEEE International Parallel and Distributed Processing Symposium, 2015
2015
-
[13]
Scalable deep learning via i/o analysis and optimization,
S. Pumma, M. Si, W.-C. Feng, and P. Balaji, “Scalable deep learning via i/o analysis and optimization,”ACM Transactions on Parallel Computing (TOPC), vol. 6, no. 2, pp. 1–34, 2019
2019
-
[14]
Tiered data management system: Accelerating data processing on HPC systems,
P. Cheng, Y . Lu, Y . Du, and Z. Chen, “Tiered data management system: Accelerating data processing on HPC systems,”Future Gener. Comput. Syst., vol. 101, pp. 894–908, 2019
2019
-
[15]
Performance characterization of scientific workflows for the optimal use of burst buffers,
C. S. Daley, D. Ghoshal, G. K. Lockwood, S. S. Dosanjh, L. Ramakrishnan, and N. J. Wright, “Performance characterization of scientific workflows for the optimal use of burst buffers,”Future Gener. Comput. Syst., vol. 110, pp. 468–480, 2020. [Online]. Available: https://doi.org/10.1016/j.future.2017.12.022
-
[16]
Development of a burst buffer system for data-intensive applications,
T. Wang, S. Oral, M. Pritchard, K. Vasko, and W. Yu, “Development of a burst buffer system for data-intensive applications,”CoRR, vol. abs/1505.01765, 2015. [Online]. Available: http://arxiv.org/abs/1505.01765
Pith/arXiv arXiv 2015
-
[17]
The role of storage target allocation in applications’ I/O performance with beegfs,
H. Devarajan and K. M. Mohror, “Extracting and characterizing I/O behavior of HPC workloads,” inIEEE International Conference on Cluster Computing, CLUSTER 2022, Heidelberg, Germany, September 5-8, 2022. IEEE, 2022, pp. 243–255. [Online]. Available: https://doi.org/10.1109/CLUSTER51413.2022.00037
-
[18]
Evaluating burst buffer placement in HPC systems,
H. Khetawat, C. Zimmer, F. Mueller, S. Atchley, S. S. Vazhkudai, and M. Mubarak, “Evaluating burst buffer placement in HPC systems,” in2019 IEEE International Conference on Cluster Computing, CLUSTER 2019, Albuquerque, NM, USA, September 23-26, 2019. IEEE, 2019, pp. 1–11. [Online]. Available: https://doi.org/10.1109/CLUSTER.2019.8891051
-
[19]
Hadafs: A file system bridging the local and shared burst buffer for exascale supercomputers,
X. He, B. Yang, J. Gao, W. Xiao, Q. Chen, S. Shi, D. Chen, W. Liu, W. Xue, and Z. Chen, “Hadafs: A file system bridging the local and shared burst buffer for exascale supercomputers,” in21st USENIX Conference on File and Storage Technologies, FAST 2023, Santa Clara, CA, USA, February 21-23, 2023, A. Goel and D. Naor, Eds. USENIX Association, 2023, pp. 215...
2023
-
[20]
Challenges and considerations for utilizing burst buffers in high-performance computing,
M. Romanus, R. B. Ross, and M. Parashar, “Challenges and considerations for utilizing burst buffers in high-performance computing,”CoRR, vol. abs/1509.05492, 2015. [Online]. Available: http://arxiv.org/abs/1509.05492
Pith/arXiv arXiv 2015
-
[21]
Optimizing HPC I/O performance with regression analysis and ensemble learning,
Z. Liu, C. Zhang, H. Wu, J. Fang, L. Peng, G. Ye, and Z. Tang, “Optimizing HPC I/O performance with regression analysis and ensemble learning,” inIEEE International Conference on Cluster Computing, CLUSTER 2023, Santa Fe, NM, USA, October 31 - Nov. 3, 2023. IEEE, 2023, pp. 234–246. [Online]. Available: https://doi.org/10.1109/CLUSTER52292.2023.00027
-
[22]
Design and implementation of I/O performance prediction scheme on HPC systems through large-scale log analysis,
S. Kim, A. Sim, K. Wu, S. Byna, and Y . Son, “Design and implementation of I/O performance prediction scheme on HPC systems through large-scale log analysis,”J. Big Data, vol. 10, no. 1, p. 65,
-
[23]
Available: https://doi.org/10.1186/s40537-023-00741-4
[Online]. Available: https://doi.org/10.1186/s40537-023-00741-4
-
[24]
Artificial neural networks based predictions towards the auto-tuning and optimization of parallel IO bandwidth in HPC system,
A. J. S. Tipu, P. ´O. Conbhu´ı, and E. Howley, “Artificial neural networks based predictions towards the auto-tuning and optimization of parallel IO bandwidth in HPC system,”Clust. Comput., vol. 27, no. 1, pp. 71–90,
-
[25]
Available: https://doi.org/10.1007/s10586-022-03814-w
[Online]. Available: https://doi.org/10.1007/s10586-022-03814-w
-
[26]
Mira: A framework for static performance analysis,
K. Meng and B. Norris, “Mira: A framework for static performance analysis,” in2017 IEEE International Conference on Cluster Computing, CLUSTER 2017, Honolulu, HI, USA, September 5-8, 2017. IEEE Computer Society, 2017, pp. 103–113. [Online]. Available: https://doi.org/10.1109/CLUSTER.2017.43
-
[27]
W. Zheng, D. Wang, and F. Song, “FQL: an extensible feature query language and toolkit on searching software characteristics for HPC applications,” inTools and Techniques for High Performance Computing - Selected Workshops, HUST, SE-HER and WIHPC, Held in Conjunction with SC 2019, Denver, CO, USA, November 17-18, 2019, Revised Selected Papers, ser. Commun...
-
[28]
Vidya: Performing code-block I/O characterization for data access optimization,
H. Devarajan, A. Kougkas, P. Challa, and X. Sun, “Vidya: Performing code-block I/O characterization for data access optimization,” in25th IEEE International Conference on High Performance Computing, HiPC 2018, Bengaluru, India, December 17-20, 2018. IEEE, 2018, pp. 255–264. [Online]. Available: https://doi.org/10.1109/HiPC.2018.00036
-
[29]
CWM: an open-weights LLM for research on code generation with world models,
F. C. team, J. Copet, Q. Carbonneaux, G. Cohen, J. Gehring, J. Kahn, J. Kossen, F. Kreuk, E. McMilin, M. Meyer, Y . Wei, D. Zhang, K. Zheng, J. Armengol-Estap ´e, P. Bashiri, M. Beck, P. Chambon, A. Charnalia, C. Cummins, J. Decugis, Z. V . Fisches, F. Fleuret, F. Gloeckle, A. Gu, M. Hassid, D. Haziza, B. Y . Idrissi, C. Keller, R. Kindi, H. Leather, G. M...
arXiv 2025
-
[30]
Codei/o: Condens- ing reasoning patterns via code input-output prediction,
J. Li, D. Guo, D. Yang, R. Xu, Y . Wu, and J. He, “Codei/o: Condens- ing reasoning patterns via code input-output prediction,”CoRR, vol. abs/2502.07316, 2025
arXiv 2025
-
[32]
Available: http://arxiv.org/abs/1911.12162
[Online]. Available: http://arxiv.org/abs/1911.12162
arXiv 1911
-
[33]
The role of storage target allocation in applications’ I/O performance with beegfs,
F. Boito, G. Pallez, and L. Teylo, “The role of storage target allocation in applications’ I/O performance with beegfs,” inIEEE International Conference on Cluster Computing, CLUSTER 2022, Heidelberg, Germany, September 5-8, 2022. IEEE, 2022, pp. 267–277. [Online]. Available: https://doi.org/10.1109/CLUSTER51413.2022.00039
-
[34]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[35]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[36]
Brief introduction of tianhe exascale prototype system,
R. Wang, K. Lu, C. Juan, W. zhe Zhang, J. wen Li, Y . Yuan, P. jing Lu, L. Huang, S. Li, and X. Fan, “Brief introduction of tianhe exascale prototype system,”Tsinghua Science and Technology, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:228997868
2021
-
[37]
Using ior to analyze the i/o performance for hpc platforms,
H. Shan and J. Shalf, “Using ior to analyze the i/o performance for hpc platforms,” 2007
2007
-
[38]
Fio: Flexible i/o tester and benchmark,
J. Axboe, “Fio: Flexible i/o tester and benchmark,” https://github.com/axboe/fio, 2008, accessed: 2025-11-02
2008
-
[39]
mdtest: Hpc metadata benchmark,
Los Alamos National Laboratory and HPC I/O Benchmark Repository, “mdtest: Hpc metadata benchmark,” https://github.com/hpc/ior, 2024
2024
-
[40]
Hacc i/o benchmark,
G. K. Lockwood, “Hacc i/o benchmark,” https://github.com/glennklockwood/hacc-io/, 2012, accessed: 2025- 11-02
2012
-
[41]
Direct numerical simulations of turbulent lean premixed combustion,
R. Sankaran, E. R. Hawkes, J. H. Chen, T. Lu, and C. K. Law, “Direct numerical simulations of turbulent lean premixed combustion,” inJournal of Physics: conference series, vol. 46, no. 1. IOP Publishing, 2006, p. 38
2006
-
[42]
Performance characteristics of a cosmology package on leading hpc architectures,
J. Carter, J. Borrill, and L. Oliker, “Performance characteristics of a cosmology package on leading hpc architectures,” inInternational Conference on High-Performance Computing. Springer, 2004, pp. 176– 188
2004
-
[43]
Optimizing hpc i/o performance with regression analysis and ensemble learning,
Z. Liu, C. Zhang, H. Wu, J. Fang, L. Peng, G. Ye, and Z. Tang, “Optimizing hpc i/o performance with regression analysis and ensemble learning,” in2023 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 2023, pp. 234–246
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.