The Pitfall of Scaling Up: Uncovering and Mitigating Popularity Bias Amplification in Scaling Transformer-based Recommenders
Pith reviewed 2026-06-26 11:34 UTC · model grok-4.3
The pith
Scaling transformer recommenders amplifies popularity bias because deeper attention and feed-forward layers cause spectral collapse in predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
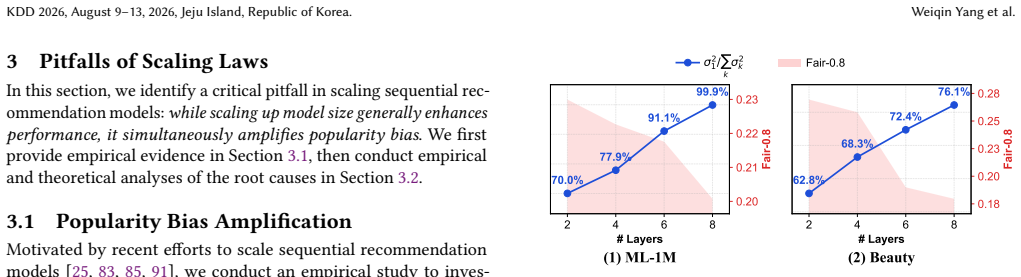
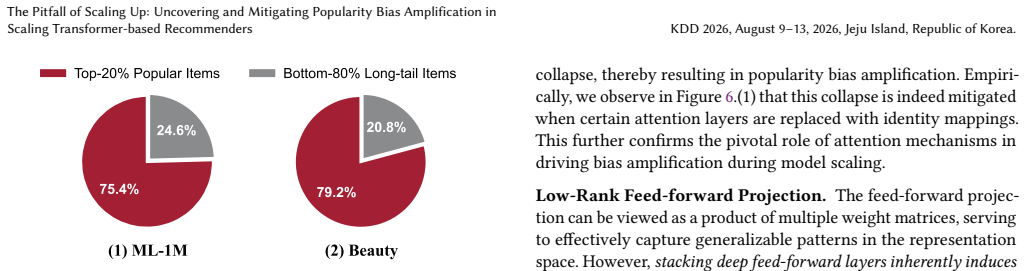
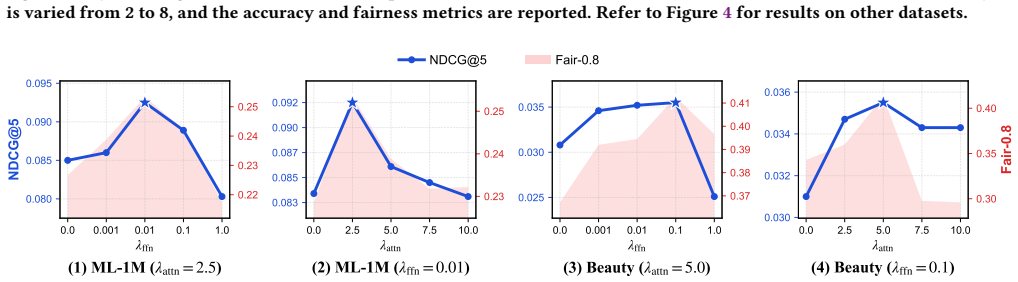
As model depth increases, the two core components of the transformer architecture, attention aggregation and feed-forward projections, synergistically induce severe spectral collapse in model predictions, which directly translates to the amplification of popularity bias. SPRINT mitigates spectral collapse during scaling by constraining the maximum column-sums of the attention score matrices and the spectral norms of the feed-forward parameters, resulting in better accuracy and long-tail fairness.
What carries the argument
SPRINT regularization, which constrains maximum column-sums of attention score matrices and spectral norms of feed-forward parameters to block spectral collapse.
If this is right
- Larger transformer recommenders can be trained without proportional increases in popularity bias.
- Long-tail items receive more balanced exposure as model capacity grows.
- Recommendation ecosystems experience reduced reinforcement of the Matthew effect.
- Both accuracy and fairness metrics improve together when the constraints are applied during scaling.
Where Pith is reading between the lines
- The same spectral-collapse mechanism could be checked in non-sequential or non-transformer recommenders to test generality.
- Monitoring the column sums of attention matrices during training may serve as an early warning for emerging bias.
- If spectral collapse proves causal, similar norm-based constraints might stabilize scaling in other attention-heavy models such as language models used for ranking.
Load-bearing premise
Spectral collapse induced specifically by attention and feed-forward components is the root cause of bias amplification rather than other factors like data distribution or training dynamics.
What would settle it
Training a series of deeper transformers while measuring prediction spectral properties and bias metrics, then checking whether bias still rises when the proposed column-sum and spectral-norm constraints are enforced.
Figures






read the original abstract
We identify a critical pitfall in scaling transformer-based sequential recommenders: while increasing model size improves recommendation accuracy, it simultaneously amplifies popularity bias. This bias drives systems to over-recommend popular items at the expense of niche ones, which not only undermines fairness but also degrades the broader ecosystem by reinforcing the Matthew effect and filter bubbles. Consequently, this bias amplification emerges as a fundamental obstacle to sustainable model scaling. Through comprehensive theoretical and empirical analyses, we uncover the root cause of this amplification. Our findings reveal that as model depth increases, the two core components of the transformer architecture, i.e., attention aggregation and feed-forward projections, synergistically induce severe spectral collapse in model predictions, which directly translates to the amplification of popularity bias. To address this challenge, we propose SPRINT (Scalable Popularity Regularization IN Transformers), which mitigates spectral collapse during scaling by constraining (i) the maximum column-sums of the attention score matrices and (ii) the spectral norms of the feed-forward parameters. Extensive experiments demonstrate that SPRINT significantly improves both accuracy and long-tail fairness. Crucially, it yields more favorable scaling behaviors when expanding model sizes from 0.05M to 0.34B parameters. The code is available at https://github.com/Tiny-Snow/GenRec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that scaling transformer-based sequential recommenders improves accuracy but amplifies popularity bias, with the root cause being synergistic spectral collapse induced by attention aggregation and feed-forward projections as model depth increases. It proposes SPRINT to mitigate this via constraints on the maximum column-sums of attention score matrices and the spectral norms of feed-forward parameters, reporting improved accuracy, long-tail fairness, and more favorable scaling behavior from 0.05M to 0.34B parameters, with code released.
Significance. If the causal mechanism is rigorously established, the work would be significant for recommender systems by identifying a depth-dependent scaling obstacle and providing targeted regularization that jointly benefits accuracy and fairness at large scales. The open-sourced code supports reproducibility and is a clear strength.
major comments (2)
- [Theoretical analysis] Theoretical analysis section: the assertion that spectral collapse 'directly translates' to popularity bias amplification is load-bearing for the central claim, yet the argument links depth-induced spectral properties to bias metrics via observed correlation rather than a closed-form derivation showing necessity (e.g., no explicit mapping from collapsed eigenvalues of the prediction operator to the popularity skew metric). This leaves open the possibility that other factors (optimization dynamics, embedding geometry) drive the bias.
- [SPRINT method] SPRINT method description: the proposed constraints on max column-sums of attention matrices and spectral norms of FFN weights are presented as addressing the synergistic root cause, but without a derivation showing how these bounds specifically prevent the collapse that produces the popularity metric (as opposed to generic regularization), the targeting of the mechanism remains under-supported.
minor comments (2)
- [Abstract] Abstract: states 'comprehensive theoretical and empirical analyses' but supplies no equations, dataset names, or quantitative results; adding one or two key equations or headline metrics would improve clarity.
- [Experiments] Experiments section: while scaling from 0.05M to 0.34B parameters is highlighted, specific dataset statistics, exact long-tail fairness metrics, and baseline implementations should be detailed to allow direct replication of the scaling curves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work identifying spectral collapse as a scaling obstacle in transformer recommenders and proposing SPRINT. We address the two major comments below, providing clarifications on the theoretical linkage and method motivation while noting where the manuscript can be strengthened for clarity.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the assertion that spectral collapse 'directly translates' to popularity bias amplification is load-bearing for the central claim, yet the argument links depth-induced spectral properties to bias metrics via observed correlation rather than a closed-form derivation showing necessity (e.g., no explicit mapping from collapsed eigenvalues of the prediction operator to the popularity skew metric). This leaves open the possibility that other factors (optimization dynamics, embedding geometry) drive the bias.
Authors: We appreciate this observation. Section 3 derives the synergistic effect of attention column aggregation and FFN projections on the eigenvalues of the effective prediction operator, showing progressive rank collapse with depth. This is then linked to popularity bias because the resulting low-rank operator disproportionately weights high-norm popular items under the recommendation softmax. While a fully closed-form necessity mapping from specific eigenvalues to the exact popularity skew metric is not derived (as it would require strong distributional assumptions on item popularities that do not generalize), we isolate the spectral mechanism via controlled ablations that hold optimization and embeddings fixed. We will revise the manuscript to expand the logical chain from operator spectrum to bias metric and add explicit discussion ruling out confounding factors. revision: partial
-
Referee: [SPRINT method] SPRINT method description: the proposed constraints on max column-sums of attention matrices and spectral norms of FFN weights are presented as addressing the synergistic root cause, but without a derivation showing how these bounds specifically prevent the collapse that produces the popularity metric (as opposed to generic regularization), the targeting of the mechanism remains under-supported.
Authors: The constraints in SPRINT are derived from the spectral analysis: the max column-sum bound on attention scores limits the aggregation operator's ability to concentrate mass and induce collapse, while the FFN spectral-norm bound directly caps the amplification of low-rank components in the projection. This is not generic regularization; ablations in the paper show that alternative regularizers (e.g., weight decay alone) fail to preserve spectrum or fairness at scale, whereas SPRINT maintains both. We will add a short derivation sketch in Section 4 explicitly connecting each bound to the eigenvalues of the composite operator to make the targeting clearer. revision: partial
Circularity Check
No circularity; theoretical link and new regularizers are independent of fitted outputs
full rationale
The paper's central claim rests on a theoretical analysis showing that depth-induced spectral collapse in attention and FFN components translates to popularity bias amplification, followed by introduction of SPRINT constraints on column-sums and spectral norms. These constraints are newly proposed regularizers, not quantities defined from or fitted to the target popularity metric. No self-citation is invoked as a load-bearing uniqueness theorem, no parameter is fitted to a data subset and then relabeled a prediction, and no ansatz is smuggled via prior work. The derivation chain is self-contained against external benchmarks and does not reduce by construction to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- constraint strengths for attention column-sums and FFN spectral norms
axioms (1)
- domain assumption Spectral collapse in predictions can be directly measured via attention and FFN properties and is causally linked to popularity bias
Reference graph
Works this paper leans on
-
[1]
Sanjeev Arora, Nadav Cohen, and Elad Hazan. 2018. On the optimization of deep networks: Implicit acceleration by overparameterization. InInternational conference on machine learning. PMLR, 244–253
2018
-
[2]
Sanjeev Arora, Nadav Cohen, Wei Hu, and Yuping Luo. 2019. Implicit regular- ization in deep matrix factorization.Advances in neural information processing systems32 (2019)
2019
-
[3]
Arlen Brown, Paul R Halmos, and Allen L Shields. 1965. Cesaro operators.Acta Sci. Math.(Szeged)26, 125-137 (1965), 81–82
1965
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
-
[6]
Jianxin Chang, Chen Gao, Yu Zheng, Yiqun Hui, Yanan Niu, Yang Song, Depeng Jin, and Yong Li. 2021. Sequential recommendation with graph neural networks. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 378–387
2021
-
[7]
Jiawei Chen, Hande Dong, Yang Qiu, Xiangnan He, Xin Xin, Liang Chen, Guli Lin, and Keping Yang. 2021. AutoDebias: Learning to debias for recommendation. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 21–30
2021
-
[8]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems41, 3 (2023), 1–39
2023
-
[9]
Ruijun Chen, Chongming Gao, Jiawei Chen, Weiqin Yang, and Xiangnan He
-
[10]
Beyond Static Best-of-N: Bayesian List-wise Alignment for LLM-based Recommendation.arXiv preprint arXiv:2605.04559(2026)
Pith/arXiv arXiv 2026
-
[11]
Sirui Chen, Jiawei Chen, Sheng Zhou, Bohao Wang, Shen Han, Chanfei Su, Yuqing Yuan, and Can Wang. 2024. SIGformer: Sign-aware graph transformer for recommendation. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. 1274–1284
2024
-
[12]
Sirui Chen, Shen Han, Jiawei Chen, Binbin Hu, Sheng Zhou, Gang Wang, Yan Feng, Chun Chen, and Can Wang. 2025. Rankformer: A graph transformer for recommendation based on ranking objective. InProceedings of the ACM on Web Conference 2025. 3037–3048
2025
-
[13]
Sirui Chen, Changxin Tian, Binbin Hu, Kunlong Chen, Ziqi Liu, Zhiqiang Zhang, and Jun Zhou. 2025. Arrows of math reasoning data synthesis for large language models: Diversity, complexity and correctness. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 4665–4669
2025
-
[14]
Xu Chen, Hongteng Xu, Yongfeng Zhang, Jiaxi Tang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2018. Sequential recommendation with user memory networks. InProceedings of the eleventh ACM international conference on web search and data mining. 108–116
2018
-
[15]
Erica Coppolillo, Marco Minici, Ettore Ritacco, Luciano Caroprese, Francesco Pisani, and Giuseppe Manco. 2024. Balanced Quality Score: Measuring Popularity Debiasing in Recommendation.ACM Transactions on Intelligent Systems and Technology15, 4 (2024), 1–27
2024
-
[16]
Yu Cui, Feng Liu, Jiawei Chen, Canghong Jin, Xingyu Lou, Changwang Zhang, Jun Wang, Yuegang Sun, and Can Wang. 2025. HatLLM: Hierarchical Attention Masking for Enhanced Collaborative Modeling in LLM-based Recommendation. arXiv preprint arXiv:2510.10955(2025)
arXiv 2025
-
[17]
Yu Cui, Feng Liu, Jiawei Chen, Xingyu Lou, Changwang Zhang, Jun Wang, Yue- gang Sun, Xiaohu Yang, and Can Wang. 2026. Field matters: A lightweight LLM-enhanced method for CTR prediction. InProceedings of the ACM Web Con- ference 2026. 6365–6376
2026
-
[18]
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, and Jiawei Chen. 2024. Distillation matters: empowering sequential recommenders to match the performance of large language models. InProceedings of the 18th ACM Conference on Recommender Systems. 507–517
2024
-
[19]
Yu Cui, Feng Liu, Zhaoxiang Wang, Changwang Zhang, Jun Wang, Can Wang, and Jiawei Chen. 2026. SpecTran: Spectral-Aware Transformer-based Adapter for LLM-Enhanced Sequential Recommendation.arXiv preprint arXiv:2601.21986 (2026)
Pith/arXiv arXiv 2026
-
[20]
Tri Dao. 2024. Flashattention-2: Faster attention with better parallelism and work partitioning. InInternational Conference on Learning Representations, Vol. 2024. 35549–35562
2024
-
[21]
Sihao Ding, Peng Wu, Fuli Feng, Yitong Wang, Xiangnan He, Yong Liao, and Yongdong Zhang. 2022. Addressing unmeasured confounder for recommendation with sensitivity analysis. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 305–315
2022
-
[22]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[23]
Gene H Golub and Henk A Van der Vorst. 2000. Eigenvalue computation in the 20th century.J. Comput. Appl. Math.123, 1-2 (2000), 35–65
2000
-
[24]
2013.Matrix computations
Gene H Golub and Charles F Van Loan. 2013.Matrix computations. JHU press
2013
-
[25]
Alois Gruson, Praveen Chandar, Christophe Charbuillet, James McInerney, Samantha Hansen, Damien Tardieu, and Ben Carterette. 2019. Offline evalu- ation to make decisions about playlistrecommendation algorithms. InProceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 420–428
2019
-
[26]
Wei Guo, Hao Wang, Luankang Zhang, Jin Yao Chin, Zhongzhou Liu, Kai Cheng, Qiushi Pan, Yi Quan Lee, Wanqi Xue, Tingjia Shen, et al. 2024. Scaling new fron- tiers: Insights into large recommendation models.arXiv preprint arXiv:2412.00714 (2024)
arXiv 2024
-
[27]
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, and Mingsheng Long. 2023. On the embedding collapse when scaling up recommendation models. arXiv preprint arXiv:2310.04400(2023)
arXiv 2023
-
[28]
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen. 2025. Rethinking entropy interventions in rlvr: An entropy change perspective.arXiv preprint arXiv:2510.10150(2025)
Pith/arXiv arXiv 2025
-
[29]
Zhezheng Hao, Hong Wang, Jian Luo, Jianqing Zhang, Yuyan Zhou, Qiang Lin, Can Wang, Hande Dong, and Jiawei Chen. 2026. ReCreate: Reasoning and Creating Domain Agents Driven by Experience.arXiv preprint arXiv:2601.11100 (2026)
Pith/arXiv arXiv 2026
-
[30]
Zhezheng Hao, Tianfu Wang, Huanshuo Dong, Ziyan Liu, Hong Wang, Xi- ankun Lin, Qiang Lin, Can Wang, Hande Dong, and Jiawei Chen. 2026. Evolve as a Team: Collaborative Self-Evolution for LLM-based Multi-Agent Systems. arXiv:2605.29790 [cs.MA] https://arxiv.org/abs/2605.29790
Pith/arXiv arXiv 2026
-
[31]
F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis)5, 4 (2015), 1–19
2015
-
[32]
Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web. 507–517
2016
-
[33]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[34]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
Pith/arXiv arXiv 2015
-
[35]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556(2022)
Pith/arXiv arXiv 2022
-
[36]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. 2021. Understanding dimensional collapse in contrastive self-supervised learning.arXiv preprint arXiv:2110.09348(2021)
arXiv 2021
-
[37]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[38]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
Pith/arXiv arXiv 2020
-
[39]
Anastasiia Klimashevskaia, Dietmar Jannach, Mehdi Elahi, and Christoph Trat- tner. 2024. A survey on popularity bias in recommender systems.User Modeling and User-Adapted Interaction34, 5 (2024), 1777–1834
2024
-
[40]
Haoxuan Li, Yanghao Xiao, Chunyuan Zheng, and Peng Wu. 2023. Balancing un- observed confounding with a few unbiased ratings in debiased recommendations. InProceedings of the ACM web conference 2023. 1305–1313
2023
-
[41]
Zihao Li, Yakun Chen, Tong Zhang, and Xianzhi Wang. 2025. Reembedding and Reweighting are Needed for Tail Item Sequential Recommendation. InProceedings of the ACM on Web Conference 2025. 4925–4936
2025
-
[42]
Siyi Lin, Chongming Gao, Jiawei Chen, Sheng Zhou, Binbin Hu, Yan Feng, Chun Chen, and Can Wang. 2025. How do recommendation models amplify popularity bias? An analysis from the spectral perspective. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 659–668
2025
-
[43]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
Pith/arXiv arXiv 2024
-
[44]
Kanglin Liu, Wenming Tang, Fei Zhou, and Guoping Qiu. 2019. Spectral regu- larization for combating mode collapse in gans. InProceedings of the IEEE/CVF international conference on computer vision. 6382–6390
2019
-
[45]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
Pith/arXiv arXiv 2017
-
[46]
Sijin Lu, Zhibo Man, Fangyuan Luo, and Jun Wu. 2025. Dual Debiasing in LLM-based Recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2685–2689
2025
-
[47]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[48]
InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[49]
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. 2018. Spectral normalization for generative adversarial networks.arXiv preprint The Pitfall of Scaling Up: Uncovering and Mitigating Popularity Bias Amplification in Scaling Transformer-based Recommenders KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. arXiv:1802.05957(2018)
Pith/arXiv arXiv 2018
-
[50]
Wentao Ning, Reynold Cheng, Xiao Yan, Ben Kao, Nan Huo, Nur Al Hasan Haldar, and Bo Tang. 2024. Debiasing recommendation with personal popularity. In Proceedings of the ACM Web Conference 2024. 3400–3409
2024
-
[51]
Naoto Ohsaka and Riku Togashi. 2023. Curse of" low" dimensionality in recom- mender systems. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 537–547
2023
-
[52]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
2020
-
[53]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[54]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[55]
William T Ross. 2022. The Cesaro operator.arXiv preprint arXiv:2210.08091 (2022)
arXiv 2022
-
[56]
Tingjia Shen, Hao Wang, Chuhan Wu, Jin Yao Chin, Wei Guo, Yong Liu, Huifeng Guo, Defu Lian, Ruiming Tang, and Enhong Chen. 2024. Optimizing sequential recommendation models with scaling laws and approximate entropy.arXiv preprint arXiv:2412.00430(2024)
arXiv 2024
-
[57]
Wentao Shi, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, and Fuli Feng. 2024. Large language models are learnable planners for long-term recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1893–1903
2024
-
[58]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568 (2024), 127063
2024
-
[59]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[60]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[61]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
2018
-
[62]
Viet Anh Tran, Guillaume Salha-Galvan, Bruno Sguerra, and Romain Hennequin
-
[63]
InProceed- ings of the 46th international ACM SIGIR conference on research and development in information retrieval
Attention mixtures for time-aware sequential recommendation. InProceed- ings of the 46th international ACM SIGIR conference on research and development in information retrieval. 1821–1826
-
[64]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[65]
Bohao Wang, Jiawei Chen, Changdong Li, Sheng Zhou, Qihao Shi, Yang Gao, Yan Feng, Chun Chen, and Can Wang. 2024. Distributionally robust graph- based recommendation system. InProceedings of the ACM web conference 2024. 3777–3788
2024
-
[66]
Bohao Wang, Jiawei Chen, Feng Liu, Changwang Zhang, Jun Wang, Canghong Jin, Chun Chen, and Can Wang. 2026. Does LLM Focus on the Right Words? Mitigating Context Bias in LLM-based Recommenders. InProceedings of the ACM Web Conference 2026. 6688–6699
2026
-
[67]
Bohao Wang, Yu Cui, Zhenxiang Xu, Jujia Zhao, Chenxiao Fan, Jizhi Zhang, Weiqin Yang, Shengjia Zhang, Sirui Chen, Yang Zhang, Xiaoyan Zhao, Wenjie Wang, Chongming Gao, Fuli Feng, Xiangnan He, and Jiawei Chen. 2026. Trust- worthy Recommendation in the Era of Large Language Models: Opportunities and Challenges. (2026)
2026
-
[68]
Bohao Wang, Feng Liu, Jiawei Chen, Xingyu Lou, Changwang Zhang, Jun Wang, Yuegang Sun, Yan Feng, Chun Chen, and Can Wang. 2025. Msl: Not all tokens are what you need for tuning llm as a recommender. InProceedings of the 48th international ACM SIGIR conference on research and development in information retrieval. 1912–1922
2025
-
[69]
Bohao Wang, Feng Liu, Changwang Zhang, Jiawei Chen, Yudi Wu, Sheng Zhou, Xingyu Lou, Jun Wang, Yan Feng, Chun Chen, et al. 2025. Llm4dsr: Leveraging large language model for denoising sequential recommendation.ACM Transac- tions on Information Systems44, 1 (2025), 1–32
2025
-
[70]
Hong Wang, Zhezheng Hao, Jian Luo, Chenxing Wei, Yao Shu, Lei Liu, Qiang Lin, Hande Dong, and Jiawei Chen. 2025. Scheduling Your LLM Reinforcement Learning with Reasoning Trees.arXiv preprint arXiv:2510.24832(2025)
Pith/arXiv arXiv 2025
-
[71]
Lei Wang, Chen Ma, Xian Wu, Zhaopeng Qiu, Yefeng Zheng, and Xu Chen. 2024. Causally debiased time-aware recommendation. InProceedings of the ACM Web Conference 2024. 3331–3342
2024
-
[72]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2400–2409
2024
-
[73]
Wenjie Wang, Fuli Feng, Xiangnan He, Xiang Wang, and Tat-Seng Chua. 2021. Deconfounded recommendation for alleviating bias amplification. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 1717– 1725
2021
-
[74]
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al
-
[75]
Emergent abilities of large language models.arXiv preprint arXiv:2206.07682 (2022)
Pith/arXiv arXiv 2022
-
[76]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[77]
Tianxin Wei, Fuli Feng, Jiawei Chen, Ziwei Wu, Jinfeng Yi, and Xiangnan He
-
[78]
InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining
Model-agnostic counterfactual reasoning for eliminating popularity bias in recommender system. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 1791–1800
-
[79]
Songpei Xu, Shijia Wang, Da Guo, Xianwen Guo, Qiang Xiao, Bin Huang, Guanlin Wu, and Chuanjiang Luo. 2025. Climber: Toward efficient scaling laws for large recommendation models. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6193–6200
2025
-
[80]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.