From Recognition to Understanding: Unlocking Cognitive Time Series Reasoning with LLMs
Pith reviewed 2026-06-26 11:47 UTC · model grok-4.3
The pith
TSAlign encodes time series as patches and aligns them to LLM semantic directions to support cognitive reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
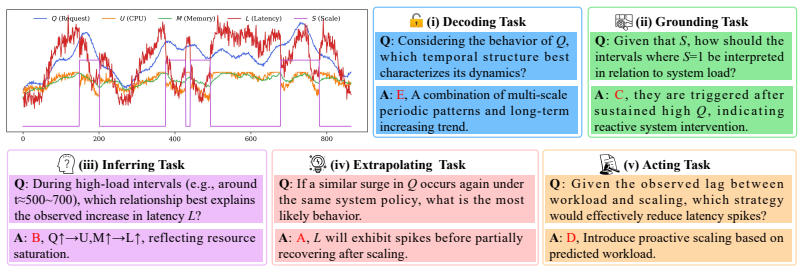
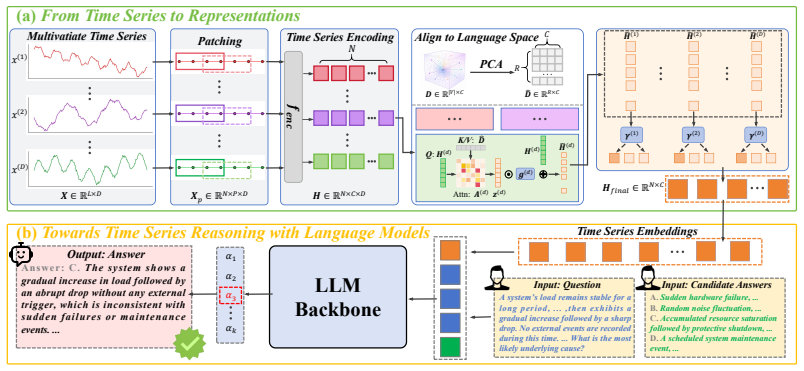
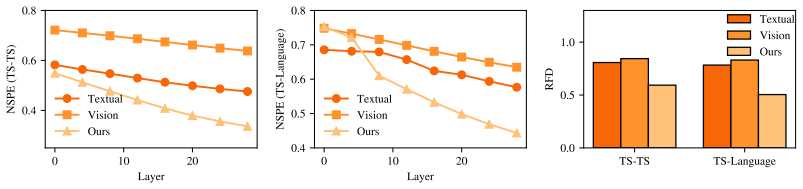
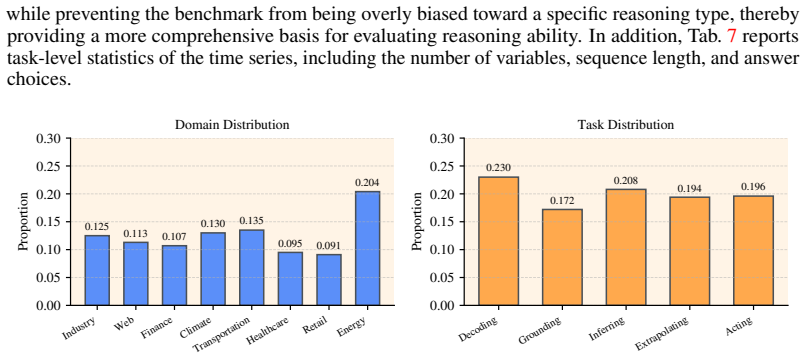
Existing task formulations reduce time series understanding to curve-fitting systems focused on low-level prediction. TSCognition supplies a multimodal benchmark of roughly 41K QA samples across Decoding, Grounding, Inferring, Extrapolating, and Acting tasks collected from fifteen public sources. TSAlign encodes the series into compact patch-level representations and aligns them with semantic directions in the LLM embedding space via gated residual injection and multivariate fusion, yielding higher accuracy than prior LLM, VLM, and time-series QA methods on TSCognition and TimerBed at substantially lower computational cost.
What carries the argument
TSAlign framework that encodes time series into compact patch-level representations and aligns them with semantic directions in the LLM embedding space via gated residual injection and multivariate fusion.
If this is right
- LLMs become usable for tasks that combine time series with textual context such as inferring causes or selecting actions.
- Patch-level encoding plus gated alignment reduces the compute needed for multimodal time-series reasoning compared with vision-language models.
- Performance gains on TimerBed indicate the alignment approach transfers beyond the newly constructed benchmark.
- The five-task structure supplies a concrete testbed for measuring progress from recognition to understanding in temporal data.
Where Pith is reading between the lines
- The same patch-alignment recipe could be tested on other sequential modalities such as audio or video event streams.
- If the alignment holds, downstream systems could generate natural-language explanations of time-series anomalies without separate post-hoc modules.
- The benchmark construction method suggests a template for turning existing public datasets into reasoning QA collections in other scientific domains.
Load-bearing premise
The five cognitive tasks and 41K QA samples drawn from fifteen public sources accurately represent the semantic, contextual, and reasoning demands of real-world temporal decision-making.
What would settle it
A new collection of real-world time-series decision scenarios whose ground-truth answers require contextual inference or action planning, on which TSAlign shows no accuracy gain over standard curve-fitting or direct LLM prompting baselines.
Figures











read the original abstract
Time series analysis has recently been coupled with Large Language Models (LLMs) to leverage their reasoning and world knowledge capabilities, yet gains remain limited. We attribute this to a fundamental mismatch between existing task formulations and LLM strengths: most settings reduce time series understanding to curve-fitting systems, focusing on low-level prediction while ignoring the semantic, contextual, and reasoning-intensive nature of real-world temporal decision-making.To address these limitations, we introduce TSCognition, a multimodal benchmark for multi-dimensional time series reasoning. It collects real-world time series and textual information from 15 public sources and constructs approximately 41K QA samples around five cognitive reasoning tasks: Decoding, Grounding, Inferring, Extrapolating, and Acting. Building on this, we further propose TSAlign, a unified framework that encodes time series into compact patch-level representations and aligns them with semantic directions in the LLM embedding space via gated residual injection and multivariate fusion.Experiments show that TSAlign outperforms existing LLM, VLM, and time series QA baselines on TSCognition and the publicly available TimerBed benchmark while substantially reducing computational cost.Code is available at: [https://github.com/EIT-NLP/CognitiveTSR](https://github.com/EIT-NLP/CognitiveTSR)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TSCognition, a multimodal benchmark for cognitive time series reasoning constructed from 15 public sources yielding ~41K QA samples across five tasks (Decoding, Grounding, Inferring, Extrapolating, Acting). It proposes TSAlign, a framework that encodes time series into compact patch-level representations and aligns them to LLM embedding space via gated residual injection and multivariate fusion. The central claim is that TSAlign outperforms existing LLM, VLM, and time series QA baselines on TSCognition and TimerBed while reducing computational cost.
Significance. If the empirical claims hold with proper controls and the benchmark tasks genuinely capture semantic/contextual reasoning demands beyond curve-fitting, the work could meaningfully redirect LLM-based time series research toward higher-level temporal decision-making. The reuse of public data sources and provision of code support reproducibility and are positive features.
major comments (2)
- [Abstract] Abstract: The statement that TSAlign 'outperforms existing LLM, VLM, and time series QA baselines on TSCognition and the publicly available TimerBed benchmark while substantially reducing computational cost' supplies no numerical metrics, baseline specifications, ablation results, or statistical tests. This absence is load-bearing for the central empirical claim and prevents assessment of effect sizes or reliability.
- [Abstract] Abstract: The five cognitive reasoning tasks and 41K QA samples are motivated as addressing a mismatch with real-world temporal decision-making, yet no details are given on task construction, inter-annotator validation, or explicit differentiation from standard time series QA formulations. This leaves the benchmark's fidelity to the stated motivation unverified and central to interpreting any performance gains.
minor comments (1)
- The GitHub repository link is provided, which is helpful for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and will make corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that TSAlign 'outperforms existing LLM, VLM, and time series QA baselines on TSCognition and the publicly available TimerBed benchmark while substantially reducing computational cost' supplies no numerical metrics, baseline specifications, ablation results, or statistical tests. This absence is load-bearing for the central empirical claim and prevents assessment of effect sizes or reliability.
Authors: We agree that the abstract would be strengthened by including concrete metrics. In the revised version we will add specific performance numbers (accuracy/F1 gains on TSCognition and TimerBed), name the primary baselines, and reference the ablation studies plus statistical tests reported in Sections 4–5. revision: yes
-
Referee: [Abstract] Abstract: The five cognitive reasoning tasks and 41K QA samples are motivated as addressing a mismatch with real-world temporal decision-making, yet no details are given on task construction, inter-annotator validation, or explicit differentiation from standard time series QA formulations. This leaves the benchmark's fidelity to the stated motivation unverified and central to interpreting any performance gains.
Authors: The abstract is intentionally concise; the full construction details, data sources, and differentiation from standard QA appear in Section 3. We will expand the abstract with a brief description of the five tasks, the 15 public sources, and the cognitive focus. Inter-annotator validation is not applicable to our largely automated construction pipeline, but we can add a sentence clarifying this approach. revision: partial
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on constructing TSCognition (41K QA samples across five tasks from 15 public sources) and the TSAlign framework (patch-level encoding with gated residual injection and multivariate fusion), followed by empirical comparisons against LLM/VLM/time-series baselines on TSCognition and TimerBed. No equations, derivations, or self-citations are shown that reduce any prediction or result to a quantity defined by the authors' own prior work or fitted inputs by construction. The contribution is self-contained via new benchmark creation and standard benchmarking, with no load-bearing steps that collapse to self-definition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing time-series-plus-LLM tasks reduce understanding to curve-fitting and therefore fail to engage LLM reasoning strengths.
Reference graph
Works this paper leans on
-
[1]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[2]
J. Chen, A. Feng, Z. Zhao, J. Garza, G. Nurbek, C. Qin, A. Maatouk, L. Tassiulas, Y . Gao, and R. Ying. Mtbench: A multimodal time series benchmark for temporal reasoning and question answering.arXiv preprint arXiv:2503.16858, 2025
arXiv 2025
-
[3]
Cheng, J
M. Cheng, J. Wang, D. Wang, X. Tao, Q. Liu, and E. Chen. Can slow-thinking llms reason over time? empirical studies in time series forecasting. InProceedings of the Nineteenth ACM International Conference on Web Search and Data Mining, pages 99–110, 2026
2026
-
[4]
D. C. Dowson and B. Landau. The fréchet distance between multivariate normal distributions. Journal of multivariate analysis, 12(3):450–455, 1982
1982
-
[5]
Ethayarajh
K. Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 55–65, 2019
2019
-
[6]
T. Guan, Z. Meng, D. Li, S. Wang, C.-H. H. Yang, Q. Wen, Z. Liu, S. M. Siniscalchi, M. Jin, and S. Pan. Timeomni-1: Incentivizing complex reasoning with time series in large language models. arXiv preprint arXiv:2509.24803, 2025
Pith/arXiv arXiv 2025
-
[7]
T. Guan, S. Pan, J. Barthelemy, Z. Li, Y . Cai, C. Alippi, M. Jin, and S. Pan. Timeomni-vl: Unified models for time series understanding and generation.arXiv preprint arXiv:2602.17149, 2026
Pith/arXiv arXiv 2026
-
[8]
Z. He, S. Alnegheimish, and M. Reimherr. Harnessing vision-language models for time series anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 21690–21698, 2026
2026
-
[9]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[10]
S. Jia, B. Song, C. Ye, and C. Yuan. M3time: Llm-enhanced multi-modal, multi-scale, and multi-frequency multivariate time series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 22265–22273, 2026
2026
-
[11]
Jiang, Y
Y . Jiang, Y . Chen, X. Li, Q. Chao, S. Liu, and G. Cong. Fstllm: Spatio-temporal llm for few shot time series forecasting. InForty-second International Conference on Machine Learning, 2025
2025
-
[12]
Jiang, K
Y . Jiang, K. Ning, Z. Pan, X. Shen, J. Ni, W. Yu, A. Schneider, H. Chen, Y . Nevmyvaka, and D. Song. Multi-modal time series analysis: A tutorial and survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 6043–6053, 2025
2025
-
[13]
M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Pan, and Q. Wen. Time-llm: Time series forecasting by reprogramming large language models. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 23857–23880, 2024
2024
-
[14]
B. Jing, S. Chen, L. Zheng, B. Liu, Z. Li, J. Zou, T. Wei, Z. Liu, Z. Zeng, R. Qiu, et al. Tsaqa: Time series analysis question and answering benchmark.arXiv preprint arXiv:2601.23204, 2026
Pith/arXiv arXiv 2026
-
[15]
Y . Kong, Y . Yang, Y . Hwang, W. Du, S. Zohren, Z. Wang, M. Jin, and Q. Wen. Time-mqa: Time series multi-task question answering with context enhancement. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29736–29753, 2025
2025
-
[16]
Z. Li, S. Li, and X. Yan. Time series as images: Vision transformer for irregularly sampled time series.Advances in Neural Information Processing Systems, 36:49187–49204, 2023. 11
2023
-
[17]
C. Liu, Q. Xu, H. Miao, S. Yang, L. Zhang, C. Long, Z. Li, and R. Zhao. Timecma: Towards llm-empowered multivariate time series forecasting via cross-modality alignment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18780–18788, 2025
2025
-
[18]
H. Liu, C. Liu, and B. A. Prakash. A picture is worth a thousand numbers: Enabling llms reason about time series via visualization. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7486–7518, 2025
2025
-
[19]
H. Liu, S. Xu, Z. Zhao, L. Kong, H. Kamarthi, A. B. Sasanur, M. Sharma, J. Cui, Q. Wen, C. Zhang, et al. Time-mmd: Multi-domain multimodal dataset for time series analysis.Advances in Neural Information Processing Systems, 37:77888–77933, 2024
2024
-
[20]
P. Liu, H. Guo, T. Dai, N. Li, J. Bao, X. Ren, Y . Jiang, and S.-T. Xia. Calf: Aligning llms for time series forecasting via cross-modal fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18915–18923, 2025
2025
-
[21]
W. Liu, H. Wu, X. Qiu, Y . Fan, Y . Zhang, A. Zhao, Y . Ma, and X. Shen. Vica: Efficient multimodal llms with vision-only cross-attention.arXiv preprint arXiv:2602.07574, 2026
Pith/arXiv arXiv 2026
-
[22]
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625, 2023
Pith/arXiv arXiv 2023
-
[23]
Y . Luo, Y . Zhou, M. Cheng, J. Wang, D. Wang, T. Pan, and J. Zhang. Time series forecasting as reasoning: A slow-thinking approach with reinforced llms.arXiv preprint arXiv:2506.10630, 2025
Pith/arXiv arXiv 2025
-
[24]
Meunier, F
R. Meunier, F. Benamara, V . Moriceau, Z. Qiao, and S. Ramasamy. Crisists: Coupling social media textual data and meteorological time series for urgency classification. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16082–16099, 2025
2025
-
[25]
Mu and P
J. Mu and P. Viswanath. All-but-the-top: Simple and effective postprocessing for word repre- sentations. InInternational Conference on Learning Representations, 2018
2018
-
[26]
S. Nagrath and S. K. Panigrahy. Patch-level tokenization with cnn encoders and attention for improved transformer time-series forecasting.arXiv preprint arXiv:2601.12467, 2026
arXiv 2026
-
[27]
J. Ni, Z. Zhao, C. Shen, H. Tong, D. Song, W. Cheng, D. Luo, and H. Chen. Harnessing vision models for time series analysis: a survey. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 10612–10620, 2025
2025
-
[28]
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730, 2022
Pith/arXiv arXiv 2022
-
[29]
Z. Pan, Y . Jiang, S. Garg, A. Schneider, Y . Nevmyvaka, and D. Song.S2ip-llm: Semantic space informed prompt learning with llm for time series forecasting. InForty-first International Conference on Machine Learning, 2024
2024
-
[30]
V . Prithyani, M. Mohammed, R. Gadgil, R. Buitrago, V . Jain, and A. Chadha. On the feasibility of vision-language models for time-series classification.arXiv preprint arXiv:2412.17304, 2024
arXiv 2024
-
[31]
Z. Qiao, S. Pan, A. Wang, V . Zhukova, Y . Liu, X. Jiang, Q. Wen, M. Long, M. Jin, and C. Liu. It’s time: Towards the next generation of time series forecasting benchmarks.arXiv preprint arXiv:2602.12147, 2026
Pith/arXiv arXiv 2026
-
[32]
X. Qiu, J. Tong, Y . Sun, Y . Ma, and X. Shen. The few govern the many: Unveiling few-layer dominance for time series models.arXiv preprint arXiv:2511.07237, 2025
arXiv 2025
-
[33]
X. Qiu, J. Tong, Y . Sun, Y . Ma, W. Zhang, and X. Shen. Rethinking the role of llms in time series forecasting.arXiv preprint arXiv:2602.14744, 2026. 12
arXiv 2026
-
[34]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, ...
2025
-
[35]
D. Schumacher, E. Nourbakhsh, R. Slavin, and A. Rios. Prompting underestimates llm capability for time series classification.arXiv preprint arXiv:2601.03464, 2026
arXiv 2026
-
[36]
M. Tan, M. A. Merrill, V . Gupta, T. Althoff, and T. Hartvigsen. Are language models actually useful for time series forecasting?Advances in Neural Information Processing Systems, 37:60162– 60191, 2024
2024
-
[37]
Tarasiou, E
M. Tarasiou, E. Chavez, and S. Zafeiriou. Vits for sits: Vision transformers for satellite image time series. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10418–10428, 2023
2023
-
[38]
J. Tong, L. Xie, S. Fang, W. Yang, and K. Zhang. Hourly solar irradiance forecasting based on encoder–decoder model using series decomposition and dynamic error compensation.Energy Conversion and Management, 270:116049, 2022
2022
-
[39]
Y . Wang, P. Lei, J. Song, Y . Hao, T. Chen, Y . Zhang, L. Jia, Y . Li, and Z. Wei. Itformer: Bridging time series and natural language for multi-modal qa with large-scale multitask dataset. In International Conference on Machine Learning, pages 63324–63344. PMLR, 2025
2025
-
[40]
H. Wu, T. Hu, Y . Liu, H. Zhou, J. Wang, and M. Long. Timesnet: Temporal 2d-variation modeling for general time series analysis. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[41]
W. Wu, Z. Zhang, L. Liu, X. Xu, J. Zhuang, K. Fan, Q. Lv, J. Liu, C. Zhang, Z. Yuan, et al. Scits: Scientific time series understanding and generation with llms.arXiv preprint arXiv:2510.03255, 2025
arXiv 2025
-
[42]
X. Wu, J. Lu, Z. Li, X. Qiu, J. Hu, C. Guo, C. S. Jensen, and B. Yang. Timeart: Towards agentic time series reasoning via tool-augmentation.arXiv preprint arXiv:2601.13653, 2026
arXiv 2026
-
[43]
Z. Xie, Z. Li, X. He, L. Xu, X. Wen, T. Zhang, J. Chen, R. Shi, and D. Pei. Chatts: Aligning time series with llms via synthetic data for enhanced understanding and reasoning.Proceedings of the VLDB Endowment, 18(8):2385–2398, 2025
2025
-
[44]
G. Xu, P. Jin, Z. Wu, H. Li, Y . Song, L. Sun, and L. Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025
2087
-
[45]
X. Xu, H. Wang, Y . Liang, P. S. Yu, Y . Zhao, and K. Shu. Can multimodal llms perform time series anomaly detection? InProceedings of the ACM Web Conference 2026, pages 5392–5403, 2026
2026
-
[46]
F. Yu, X. Guo, L. Yuan, H. Kang, H. Zhao, L. Qin, F. Huang, B. Hu, and T. Zhou. Tsrbench: A comprehensive multi-task multi-modal time series reasoning benchmark for generalist models.arXiv preprint arXiv:2601.18744, 2026
Pith/arXiv arXiv 2026
-
[47]
Z. Yue, Y . Wang, J. Duan, T. Yang, C. Huang, Y . Tong, and B. Xu. Ts2vec: Towards universal representation of time series. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 8980–8987, 2022
2022
-
[48]
Zhang, Q
S. Zhang, Q. Fang, Z. Yang, and Y . Feng. Llava-mini: Efficient image and video large multimodal models with one vision token. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[49]
L. N. Zheng, W. Liang, W. E. Zhang, M. Xu, O. Maennel, and W. Chen. Lifting manifolds to mitigate pseudo-alignment in llm4ts. InProceedings of the ACM Web Conference 2026, pages 3764–3775, 2026. 13
2026
-
[50]
Zhong, W
S. Zhong, W. Ruan, M. Jin, H. Li, Q. Wen, and Y . Liang. Time-vlm: Exploring multimodal vision-language models for augmented time series forecasting. InInternational Conference on Machine Learning, pages 78478–78497. PMLR, 2025
2025
-
[51]
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. InInternational conference on machine learning, pages 27268–27286. PMLR, 2022
2022
-
[52]
perceiving signals
T. Zhou, P. Niu, L. Sun, R. Jin, et al. One fits all: Power general time series analysis by pretrained lm.Advances in neural information processing systems, 36:43322–43355, 2023. A Ethics Statement Our study is limited to methodological and empirical investigation and does not involve human participants, animal subjects, or environmentally sensitive mater...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.