Improving Reasoning in Vision-Language Models via Perception Verified Self-Training
Pith reviewed 2026-07-01 06:27 UTC · model grok-4.3
The pith
Vision-language models improve reasoning up to 16% by verifying captions before generating thought chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
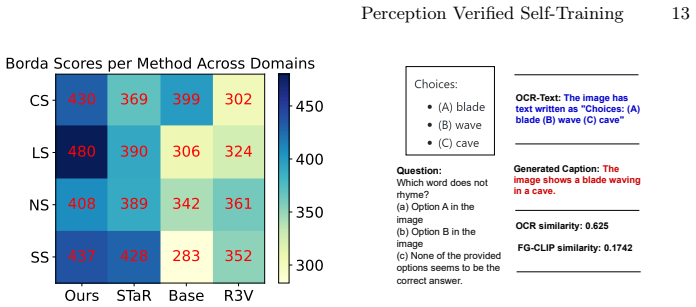
The central claim is that enforcing visual grounding through caption verification and a two-stage curriculum on partitioned data allows self-training to produce more accurate reasoning chains in VLMs, leading to gains of up to 16% over standard self-training methods that only check answer correctness.
What carries the argument
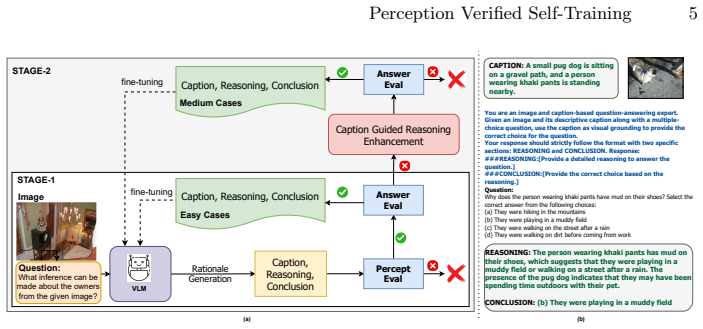
The perception-verified self-training framework, which uses a caption-reasoning-conclusion template and PerceptEval to filter for perceptually grounded samples before curriculum training.
Load-bearing premise
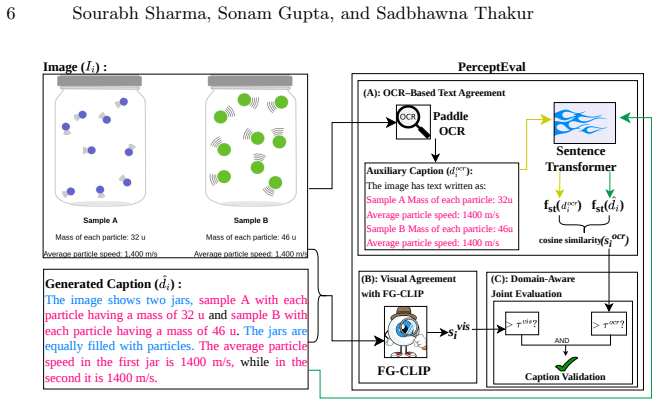
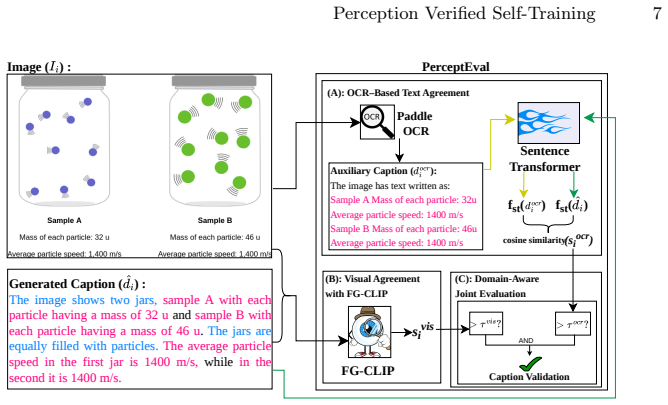
Unsupervised PerceptEval can accurately judge caption quality from image alignment without any ground-truth references.
What would settle it
A controlled experiment comparing training with and without the caption verification step on the same self-generated rationales would show whether the perception check is necessary for the reported gains.
Figures


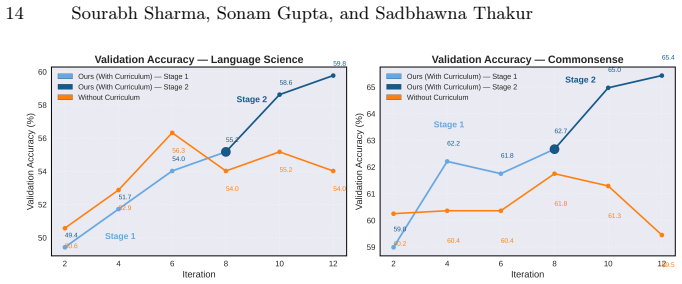



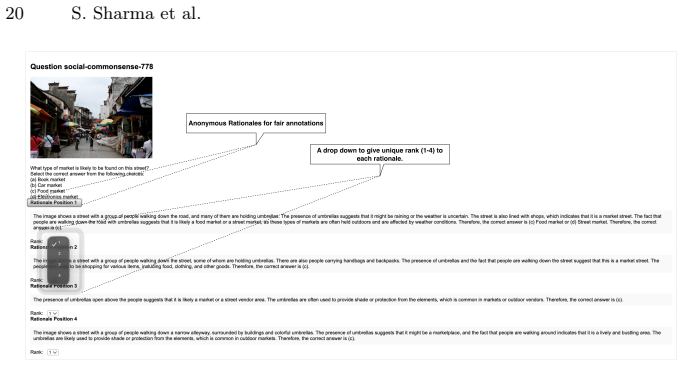
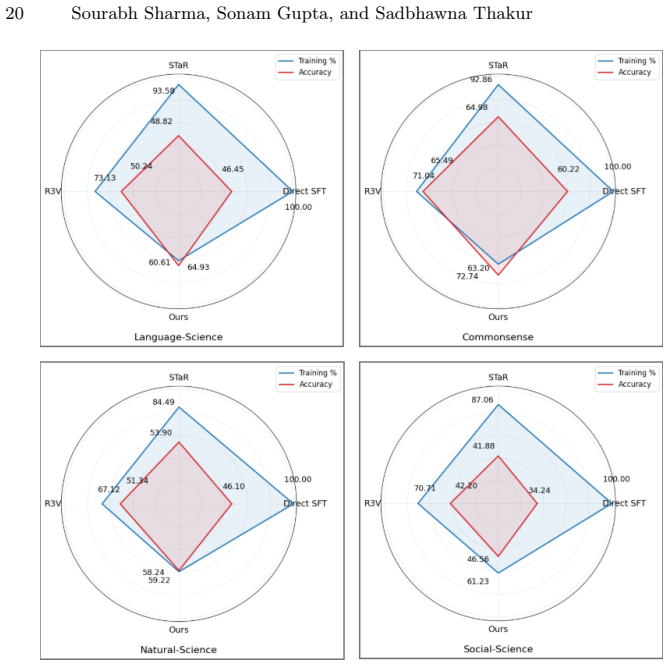






























read the original abstract
Achieving human-like reasoning in Vision-Language Models (VLMs) remains a long-standing challenge. Recent approaches leverage Chain-of-Thought (CoT) rationales generated by human annotators or proprietary models, which are costly and difficult to scale. Self-training offers a promising alternative but often suffers from visual hallucinations and language shortcuts because rationales are filtered only by answer correctness without verifying visual perception. We propose a perception-verified self-training framework that enforces visually grounded reasoning. Our method employs a CoT template (caption-reasoning-conclusion) that disentangles perception from reasoning, enabling independent verification of visual understanding. To compensate for the absence of ground-truth captions, we introduce PerceptEval, an unsupervised method that evaluates caption quality based on its alignment with visual and textual elements in the image. Using caption verification together with answer correctness, we partition the data into easy, medium, and hard subsets and design a two-stage curriculum learning strategy. Stage 1 trains on easy samples, while Stage 2 enhances medium samples by regenerating reasoning conditioned on verified captions and retaining only those with correct conclusions. This ensures training is performed exclusively on perceptually grounded reasoning, reducing hallucinations and language shortcuts. Extensive experiments across diverse domains and models demonstrate improvements of up to 16% over standard self-training baselines, showing that our framework provides a scalable and cost-effective solution for advancing multimodal reasoning without manually annotated CoT rationales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a perception-verified self-training framework for VLMs, built around a caption-reasoning-conclusion CoT template and an unsupervised PerceptEval method for caption quality assessment, enables data partitioning into easy/medium/hard subsets and a two-stage curriculum that produces perceptually grounded reasoning, yielding up to 16% gains over standard self-training baselines across domains and models without requiring manual CoT annotations.
Significance. If the empirical gains are robust and attributable to the perception-verification step rather than noisy reweighting, the work would supply a scalable route to reduce hallucinations and language shortcuts in multimodal self-training, a practically relevant advance given the cost of human or proprietary CoT data.
major comments (3)
- [Abstract] Abstract and method overview: PerceptEval is presented as the load-bearing component that 'evaluates caption quality based on its alignment with visual and textual elements' without ground truth, yet no validation (correlation with human judgments, ablation of its alignment metric, or comparison to random filtering) is described; this directly undermines attribution of the reported 16% lift to the proposed mechanism rather than data selection artifacts.
- [Abstract] Experimental claims: The abstract states 'extensive experiments across diverse domains and models' with 'improvements of up to 16%', but supplies no information on dataset sizes, baseline implementations, statistical tests, or error analysis; without these, the central empirical claim cannot be assessed for reproducibility or robustness.
- [§4] §4 (curriculum design): The two-stage strategy retains only medium samples whose regenerated reasoning yields correct conclusions after conditioning on verified captions; if PerceptEval scores correlate only weakly with actual visual fidelity, this filtering step reduces to answer-correctness filtering plus a noisy proxy, collapsing the distinction from standard self-training.
minor comments (2)
- [Abstract] The abstract repeatedly uses 'perceptually grounded' without a precise operational definition that distinguishes it from answer correctness alone.
- [Method] Notation for the CoT template (caption-reasoning-conclusion) is introduced but not formalized with an equation or pseudocode, which would aid clarity in the method section.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below. Where the comments identify gaps in validation or presentation, we will revise the manuscript accordingly. We believe the core contribution remains intact and can be strengthened through these changes.
read point-by-point responses
-
Referee: [Abstract] Abstract and method overview: PerceptEval is presented as the load-bearing component that 'evaluates caption quality based on its alignment with visual and textual elements' without ground truth, yet no validation (correlation with human judgments, ablation of its alignment metric, or comparison to random filtering) is described; this directly undermines attribution of the reported 16% lift to the proposed mechanism rather than data selection artifacts.
Authors: We agree that stronger validation of PerceptEval would improve attribution. The full manuscript contains ablations demonstrating that PerceptEval-based filtering outperforms both random selection and answer-correctness-only baselines. However, we did not include explicit human correlation or metric ablation in the submitted version. We will add a dedicated validation subsection reporting Spearman correlation with human judgments on a held-out set of 500 captions and an ablation of the alignment metric components. revision: yes
-
Referee: [Abstract] Experimental claims: The abstract states 'extensive experiments across diverse domains and models' with 'improvements of up to 16%', but supplies no information on dataset sizes, baseline implementations, statistical tests, or error analysis; without these, the central empirical claim cannot be assessed for reproducibility or robustness.
Authors: The experimental section (§5) specifies dataset sizes per domain, describes baseline implementations as standard self-training with answer filtering, and reports results with standard deviations over three random seeds. The abstract itself is intentionally concise. We will revise the abstract to include brief references to these elements and add paired statistical significance tests in the results tables during revision. revision: yes
-
Referee: [§4] §4 (curriculum design): The two-stage strategy retains only medium samples whose regenerated reasoning yields correct conclusions after conditioning on verified captions; if PerceptEval scores correlate only weakly with actual visual fidelity, this filtering step reduces to answer-correctness filtering plus a noisy proxy, collapsing the distinction from standard self-training.
Authors: The distinction is preserved because Stage 2 explicitly regenerates reasoning conditioned on PerceptEval-verified captions before applying the correctness filter; ablations removing the caption verification step show clear performance drops. We acknowledge that stronger evidence of PerceptEval's correlation would further separate the methods. We will add an analysis of PerceptEval precision on visually faithful vs. hallucinated captions in the revised §4. revision: partial
Circularity Check
No circularity; derivation relies on proposed unsupervised PerceptEval and external experimental validation
full rationale
The paper defines a perception-verified self-training pipeline that introduces PerceptEval (unsupervised alignment-based caption scoring) to partition data and applies a two-stage curriculum, with gains measured against standard self-training baselines in experiments. No quoted step reduces a prediction or result to a fitted input by construction, no self-citation chain bears the central claim, and no ansatz or uniqueness theorem is smuggled in. The framework is self-contained against external benchmarks (performance deltas up to 16%), satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
PerceptEval
no independent evidence
Reference graph
Works this paper leans on
-
[1]
al., R.: Direct preference optimization: your language model is secretly a reward model
et. al., R.: Direct preference optimization: your language model is secretly a reward model. In: NeurIPS (2023)
2023
-
[2]
In: Ku, L.W., Martins, A., Srikumar, V
Chen, Q., Qin, L., Zhang, J., Chen, Z., Xu, X., Che, W.: M3CoT: A novel bench- mark for multi-domain multi-step multi-modal chain-of-thought. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 8199–
-
[3]
https://doi.org/10.18653/v1/2024.acl- long.446,https://aclanthology
Association for Computational Linguistics, Bangkok, Thailand (Aug 2024). https://doi.org/10.18653/v1/2024.acl- long.446,https://aclanthology. org/2024.acl-long.446/
-
[4]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Muyan, Z., Zhang, Q., Zhu, X., Lu, L., Li, B., Luo, P., Lu, T., Qiao, Y., Dai, J.: Intern vl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 24185–24198 (2023),https://api.semanticsch...
2024
-
[5]
The North American Chapter of the Association for Computational Linguistics (2025)
Cheng, K., Li, Y., Xu, F., Zhang, J., Zhou, H., Liu, Y.: Vision-language mod- els can self-improve reasoning via reflection. The North American Chapter of the Association for Computational Linguistics (2025)
2025
-
[6]
Cui, C., Sun, T., Lin, M., Gao, T., Zhang, Y., Liu, J., Wang, X., Zhang, Z., Zhou, C., Liu, H., Zhang, Y., Lv, W., Huang, K., Zhang, Y., Zhang, J., Zhang, J., Liu, Y., Yu, D., Ma, Y.: Paddleocr 3.0 technical report (2025),https://arxiv.org/ abs/2507.05595
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems
Deng, Y., Lu, P., Yin, F., Hu, Z., Shen, S., Zou, J., Chang, K.W., Wang, W.: Enhancing large vision language models with self-training on image comprehen- sion. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. NIPS ’24, Curran Associates Inc., Red Hook, NY, USA (2024) 32 S. Sharma et al
2024
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., Manocha, D., Zhou, T.: Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1437...
2024
-
[9]
Huang, W., Jia, B., Zhai, Z., Cao, S., Ye, Z., Zhao, F., Xu, Z., Tang, X., Hu, Y., Lin, S.: Vision-r1: Incentivizing reasoning capability in multimodal large language models (2026),https://arxiv.org/abs/2503.06749
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
In: Proceedings of the 36th International Conference on Neural Information Processing Systems
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. NIPS ’22, Curran Associates Inc. (2022)
2022
-
[11]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Kojima,T.,Gu,S.S.,Reid,M.,Matsuo,Y.,Iwasawa,Y.:Largelanguagemodelsare zero-shot reasoners. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Information Processing Systems. vol. 35, pp. 22199–22213. Curran Associates, Inc. (2022),https://proceedings.neurips.cc/ paper _ files / paper / 2022 / file / 8bb0d291a...
2022
-
[12]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, J., Zhang, D., Wang, X., Hao, Z., Lei, J., Tan, Q., Zhou, C., Liu, W., Wang, W., Chen, Z., Wang, W., Li, W., Zhang, S., Su, M., Ouyang, W., Li, Y., Zhou, D.: Chemvlm: Exploring the power of multimodal large language models in chemistry area. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 415–423 (2025)
2025
-
[13]
In: Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers)
Li, Y., Lin, Z., Zhang, S., Fu, Q., Chen, B., Lou, J.G., Chen, W.: Making language models better reasoners with step-aware verifier. In: Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). pp. 5315–5333 (2023)
2023
-
[14]
In: Findings of the Association for Computational Linguistics: ACL 2025
Li, Z., Tang, B., Niu, Y., Jin, B., Shi, Q., Feng, Y., Li, Z., Hu, J., Yang, M., Xiong, F.: Care-star: Constraint-aware self-taught reasoner. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 21689–21703 (2025)
2025
-
[15]
Li, Z., Yu, W., Huang, C., Liang, Z., Liu, R., Liu, F., Che, J., Yu, D., Boyd- Graber, J., Mi, H., Yu, D.: Self-rewarding vision-language model via reasoning decomposition (2026),https://arxiv.org/abs/2508.19652
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning (2023)
2023
-
[17]
io/blog/2024-01-30-llava-next/
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024),https://llava-vl.github. io/blog/2024-01-30-llava-next/
2024
-
[18]
Lu, J., Dou, Z., Wang, H., Cao, Z., Dai, J., Feng, Y., Guo, Z.: Autopsv: Automated process-supervisedverifier.AdvancesinNeuralInformationProcessingSystems37, 79935–79962 (2024)
2024
-
[19]
arXiv preprint arXiv:2401.08967 (2024)
Luong, T.Q., Zhang, X., Jie, Z., Sun, P., Jin, X., Li, H.: Reft: Reasoning with reinforced fine-tuning. arXiv preprint arXiv:2401.08967 (2024)
-
[20]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Mitra, C., Huang, B., Darrell, T., Herzig, R.: Compositional chain-of-thought prompting for large multimodal models. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 14420–14431 (2024)
2024
-
[21]
Mitra, C., Huang, B., Darrell, T., Herzig, R.: Compositional chain-of-thought prompting for large multimodal models (2024),https://arxiv.org/abs/2311. 17076
2024
-
[22]
In: OpenAI (2023),https : / / api
OpenAI: GPT-4Vision system card. In: OpenAI (2023),https : / / api . semanticscholar.org/CorpusID:263218031 Perception Verified Self-Training 33
2023
-
[23]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum? id=4XIKfvNYvx
Pang, R.Y., Yuan, W., He, H., Cho, K., Sukhbaatar, S., Weston, J.E.: Iterative reasoning preference optimization. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum? id=4XIKfvNYvx
2024
-
[24]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[25]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics (11 2019),https: //arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
Advances in Neural Information Processing Systems37, 8612–8642 (2024)
Shao, H., Qian, S., Xiao, H., Song, G., Zong, Z., Wang, L., Liu, Y., Li, H.: Vi- sual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning. Advances in Neural Information Processing Systems37, 8612–8642 (2024)
2024
-
[27]
In: Conference on Empirical Methods in Natural Language Pro- cessing (2022),https://api.semanticscholar.org/CorpusID:253098851
Wang, B., Deng, X., Sun, H.: Iteratively prompt pre-trained language models for chain of thought. In: Conference on Empirical Methods in Natural Language Pro- cessing (2022),https://api.semanticscholar.org/CorpusID:253098851
2022
-
[28]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Machine In- telligence Research20, 447 – 482 (2023),https://api.semanticscholar.org/ CorpusID:257038341
Wang, X., Chen, G., Qian, G., Gao, P., Wei, X., Wang, Y., Tian, Y., Gao, W.: Large-scale multi-modal pre-trained models: A comprehensive survey. Machine In- telligence Research20, 447 – 482 (2023),https://api.semanticscholar.org/ CorpusID:257038341
2023
-
[30]
NIPS ’22, Curran Associates Inc
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models.In:Proceedingsofthe36thInternationalConferenceonNeuralInformation Processing Systems. NIPS ’22, Curran Associates Inc. (2022)
2022
- [31]
- [32]
-
[33]
arXiv preprint arXiv:2505.05071 (2025)
Xie, C., Wang, B., Kong, F., Li, J., Liang, D., Zhang, G., Leng, D., Yin, Y.: Fg-clip: Fine-grained visual and textual alignment. arXiv preprint arXiv:2505.05071 (2025)
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9556– 9567 (2024)
2024
-
[35]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Zelikman, E., Wu, Y., Mu, J., Goodman, N.: STar: Bootstrapping reasoning with reasoning. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022),https://openreview.net/forum? id=_3ELRdg2sgI
2022
-
[36]
Advances in Neural Information Processing Systems37, 64735–64772 (2024) 34 S
Zhang, D., Zhoubian, S., Hu, Z., Yue, Y., Dong, Y., Tang, J.: Rest-mcts*: Llm self-training via process reward guided tree search. Advances in Neural Information Processing Systems37, 64735–64772 (2024) 34 S. Sharma et al
2024
-
[37]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M., Shum, H.Y.: Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Zheng, G., Yang, B., Tang, J., Zhou, H.Y., Yang, S.: Ddcot: duty-distinct chain-of- thought prompting for multimodal reasoning in language models. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23, Curran Associates Inc. (2023)
2023
-
[39]
arXiv preprint arXiv:2407.06189 (2024)
Zohar, O., Wang, X., Bitton, Y., Szpektor, I., Yeung-Levy, S.: Video-star: Self- training enables video instruction tuning with any supervision. arXiv preprint arXiv:2407.06189 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.