Open AI in the Wild: Adoption and Adaptation of Open Models on r/LocalLLaMA
Pith reviewed 2026-06-26 11:24 UTC · model grok-4.3
The pith
Users in r/LocalLLaMA conceptualize openness in AI models through practical concerns like local control, privacy, and adaptation under hardware and licensing limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through thematic analysis of community discussions, the authors establish that members conceptualize openness pragmatically in relation to reliability, local control, privacy, and the ability to adapt models under constraints such as compute resources, licensing, and usability. Motivations include autonomy, experimentation, and resistance to platform instability, while deterrents include steep learning curves and performance gaps. Shared community resources such as datasets, evaluation frameworks, and inference tools sustain interdependent development beyond single model releases.
What carries the argument
Thematic analysis of r/LocalLLaMA discussions, which surfaces a utility-oriented view of openness tied to practical constraints and community resources.
If this is right
- Open model producers can better support sustained use by improving downstream usability and infrastructure.
- A utility-oriented view of openness shifts focus from release practices alone to how models perform under real constraints.
- Community projects such as shared datasets and tools form an interdependent layer that extends beyond individual model releases.
- Adoption grows when models align with needs for autonomy and resistance to platform changes.
Where Pith is reading between the lines
- The same pragmatic framing may appear in other open-source software communities facing similar resource limits.
- Designers of new open AI platforms could test features that directly address local control and privacy to increase adoption.
- Policy discussions on AI openness might incorporate user-reported constraints rather than relying only on technical checklists.
Load-bearing premise
Thematic analysis of discussions on r/LocalLLaMA accurately captures how the community conceptualizes openness without major effects from sampling bias or researcher interpretation.
What would settle it
A direct survey of r/LocalLLaMA members or comparable open-model communities that finds primary emphasis on technical release criteria instead of pragmatic factors like local control and privacy.
Figures

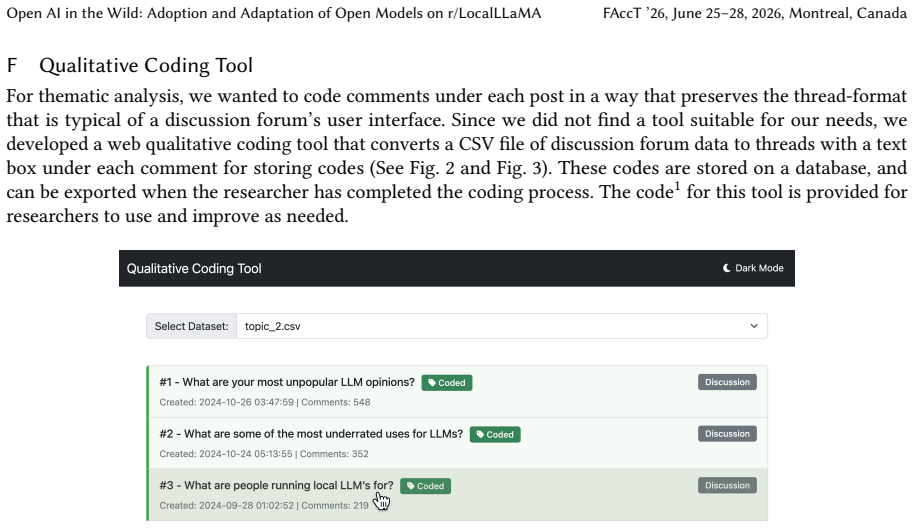
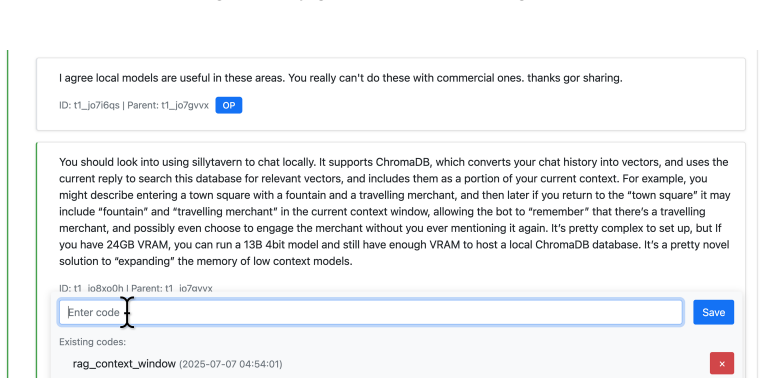
read the original abstract
Existing work on AI openness has focused on defining what technical components or release practices qualify a system as "open". However, less is known about how openness is understood and put into practice by people who adopt and adapt these models under real-world constraints. In this paper, we present an empirical study of r/LocalLLaMA, a large online community centered on running and customizing open foundation models locally. Through thematic analysis of community discussions, we find that members conceptualize openness pragmatically - in relation to reliability, local control, privacy, and the ability to adapt models under constraints such as compute resources, licensing, and usability. We identify key motivations for adopting open models, including autonomy, experimentation, and resistance to platform instability, as well as deterrents such as steep learning curves and performance gaps compared to closed systems. We further describe how shared resources and projects, including datasets, evaluation frameworks, and inference tools, sustain interdependent development in the broader open AI ecosystem beyond individual model releases. We then discuss the implications of a utility-oriented view of openness, and how producer support for downstream usability and infrastructure could better enable sustained innovation in open model ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a qualitative empirical study of the r/LocalLLaMA subreddit, using thematic analysis of community discussions to examine how users adopt and adapt open foundation models under real-world constraints. It claims that community members conceptualize openness pragmatically in terms of reliability, local control, privacy, and adaptability under limits of compute, licensing, and usability; identifies motivations such as autonomy, experimentation, and resistance to platform instability along with deterrents like learning curves and performance gaps; and describes the role of shared datasets, evaluation frameworks, and inference tools in sustaining interdependent development. The paper concludes with implications for how producers might better support downstream usability to enable sustained open-model innovation.
Significance. If the thematic analysis holds, the work supplies grounded, user-centered evidence on openness that moves beyond purely technical definitions of model release practices. Its strength lies in drawing directly from an active online community rather than abstract theorizing, yielding concrete observations about pragmatic trade-offs and ecosystem interdependencies that could inform HCI and AI governance research on sustainable open ecosystems.
major comments (1)
- [Abstract] Abstract (and presumed Methods section): the description of the thematic analysis provides no information on the sampling frame, number of threads or posts examined, coding procedure, or inter-rater reliability checks. Because the central claim—that members conceptualize openness in terms of reliability, local control, privacy, and adaptation under constraints—rests entirely on the validity of this analysis, the absence of these details leaves open the possibility that reported themes reflect thread selection, self-selection among posters, or researcher framing rather than community views.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the paper's contribution and for the detailed feedback on methodological transparency. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and presumed Methods section): the description of the thematic analysis provides no information on the sampling frame, number of threads or posts examined, coding procedure, or inter-rater reliability checks. Because the central claim—that members conceptualize openness in terms of reliability, local control, privacy, and adaptation under constraints—rests entirely on the validity of this analysis, the absence of these details leaves open the possibility that reported themes reflect thread selection, self-selection among posters, or researcher framing rather than community views.
Authors: We agree that the manuscript requires additional detail on data collection and analysis to support the validity of the thematic findings. The current version describes the overall approach at a high level but does not include the specific elements noted. In the revised manuscript we will expand the Methods section to report: the sampling frame and selection criteria for threads from r/LocalLLaMA, the total number of threads and posts examined, a step-by-step account of the coding procedure (including initial code generation, theme development, and iteration), and the measures taken to ensure analytical rigor. Regarding inter-rater reliability, we will explicitly state that the analysis followed a reflexive thematic analysis orientation (Braun & Clarke) conducted by a single researcher with reflexive practices; we will describe how trustworthiness was addressed through iterative memoing, peer discussion of emerging themes, and an audit trail rather than multi-coder reliability statistics. These additions will be placed in a dedicated subsection and will directly mitigate concerns about selection effects or researcher framing. revision: yes
Circularity Check
No significant circularity: purely empirical qualitative study with no derivations or fitted inputs.
full rationale
This paper presents a thematic analysis of external Reddit community discussions on r/LocalLLaMA. It contains no equations, parameters, predictions, or derivations that could reduce claims to inputs by construction. The central findings emerge from coding of observed discussions rather than any self-referential fitting, self-citation chain, or ansatz. No load-bearing steps match the enumerated circularity patterns, and the study is self-contained against external data sources.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Andrej Karpathy [@karpathy]. 2023. @AlphaSignalAI @ClementDelangue I Pretty Much Only Trust Two LLM Evals Right Now: Chatbot Arena and r/LocalLlama Comments Section. https://x.com/karpathy/status/1737544497016578453
arXiv 2023
-
[2]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. Refusal in Language Models Is Mediated by a Single Direction. arXiv:2406.11717 [cs] doi:10.48550/arXiv.2406.11717
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11717 2024
-
[3]
Kelsey Beninger. 2017. Social media users’ views on the ethics of social media research.The SAGE handbook of social media research methods57 (2017)
2017
-
[4]
Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul Röttger, Dan Jurafsky, Tatsunori Hashimoto, and James Zou. 2024. Safety- Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models That Follow Instructions. arXiv:2309.07875 [cs] doi:10.48550/arXiv.2309.07875
-
[5]
Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, et al. 2022. Gpt-neox-20b: An open-source autoregressive language model.arXiv preprint arXiv:2204.06745(2022)
Pith/arXiv arXiv 2022
-
[6]
Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, and Samuel Weinbach
-
[7]
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
GPT-NeoX-20B: An Open-Source Autoregressive Language Model. arXiv:2204.06745 [cs] doi:10.48550/arXiv.2204.06745
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.06745
-
[8]
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man Is to Computer Programmer as Woman Is to Homemaker? Debiasing Word Embeddings. InAdvances in Neural Information Processing Systems, Vol. 29. Curran Associates, Inc
2016
-
[9]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri Chatterji, Annie 3https://goodsystems.utexas.edu Open AI in the Wild: Adoption and Adaptation of Open Models on r/LocalLLaM...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07258 2026
-
[10]
Nick Bostrom. 2018. Strategic implications of openness in AI development. InArtificial intelligence safety and security. Chapman and Hall/CRC, 145–164
2018
-
[11]
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Ben Bucknall, Andreas A. Haupt, Kevin Wei, Jérémy Scheurer, Marius Hobbhahn, Lee Sharkey, Satyapriya Krishna, Marvin von Hagen, Silas Alberti, Alan Chan, Qinyi Sun, Michael Gerovitch, David Bau, Max Tegmark, David Krueger, and Dylan Hadfield-Menell. 2024. Black-Box Access is ...
2024
-
[12]
Joel Castaño, Silverio Martínez-Fernández, Xavier Franch, and Justus Bogner. 2024. Analyzing the Evolution and Maintenance of ML Models on Hugging Face. InProceedings of the 21st International Conference on Mining Software Repositories(New York, NY, USA, 2024-07-02)(MSR ’24). Association for Computing Machinery, 607–618. doi:10.1145/3643991.3644898
-
[13]
Madiha Zahrah Choksi, Ilan Mandel, and Sebastian Benthall. 2025. The Brief and Wondrous Life of Open Models. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 3224–3240. doi:10.1145/3715275.3732206
-
[14]
Nolazco-Flores, Lori Landay, Matthew Jackson, Paul Röttger, Philip H
Francisco Eiras, Aleksandar Petrov, Bertie Vidgen, Christian Schroeder de Witt, Fabio Pizzati, Katherine Elkins, Supratik Mukhopadhyay, Adel Bibi, Botos Csaba, Fabro Steibel, Fazl Barez, Genevieve Smith, Gianluca Guadagni, Jon Chun, Jordi Cabot, Joseph Marvin Imperial, Juan A. Nolazco-Flores, Lori Landay, Matthew Jackson, Paul Röttger, Philip H. S. Torr, ...
-
[15]
arXiv:2404.17047 [cs] doi:10.48550/arXiv.2404.17047
Near to Mid-term Risks and Opportunities of Open-Source Generative AI. arXiv:2404.17047 [cs] doi:10.48550/arXiv.2404.17047
-
[16]
Free Software Foundation. [n. d.]. What Is Free Software? - GNU Project - Free Software Foundation. https://www.gnu.org/philosophy/ free-sw.en.html
-
[17]
Devin Gaffney and J. Nathan Matias. 2018. Caveat Emptor, Computational Social Science: Large-scale Missing Data in a Widely-Published Reddit Corpus.PLOS ONE13, 7 (July 2018), e0200162. doi:10.1371/journal.pone.0200162
-
[18]
Whiting, and K
Dilrukshi Gamage, Piyush Ghasiya, Vamshi Bonagiri, Mark E. Whiting, and K. Sasahara. 2022. Are Deepfakes Concerning? Analyzing Conversations of Deepfakes on Reddit and Exploring Societal Implications.Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems(2022). https://api.semanticscholar.org/CorpusId:247779344
2022
-
[19]
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. 2020. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv:2101.00027 [cs] doi:10.48550/arXiv.2101.00027
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2101.00027 2020
-
[20]
I Will Not Drink With You Today
Robert P Gauthier, Mary Jean Costello, and James R Wallace. 2022. “I Will Not Drink With You Today”: A Topic-Guided Thematic Analysis of Addiction Recovery on Reddit. InCHI Conference on Human Factors in Computing Systems. ACM, New Orleans LA USA, 1–17. doi:10.1145/3491102.3502076
-
[21]
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. 2024. Olmo: Accelerating the science of language models.arXiv preprint arXiv:2402.00838(2024)
Pith/arXiv arXiv 2024
-
[22]
Maarten Grootendorst. 2022. BERTopic: Neural topic modeling with a class-based TF-IDF procedure.arXiv preprint arXiv:2203.05794 (2022)
Pith/arXiv arXiv 2022
-
[23]
James Howison and Kevin Crowston. 2014. Collaboration through Open Superposition: A Theory of the Open Source Way.MIS Quarterly38, 1 (2014), 29–50. jstor:26554867 https://www.jstor.org/stable/26554867
arXiv 2014
-
[24]
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. 2025. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290(2025)
Pith/arXiv arXiv 2025
-
[25]
Siming Huang, Tianhao Cheng, Jason Klein Liu, Jiaran Hao, Liuyihan Song, Yang Xu, J Yang, Jiaheng Liu, Chenchen Zhang, Linzheng Chai, et al. 2024. Opencoder: The open cookbook for top-tier code large language models.arXiv preprint arXiv:2411.04905(2024)
arXiv 2024
-
[26]
Open Source Initiative. 2023. Meta’s LLaMa License Is Not Open Source. https://opensource.org/blog/metas-llama-2-license-is-not- open-source FAccT ’26, June 25–28, 2026, Montreal, Canada Lee et al
2023
-
[27]
Ho, Percy Liang, and Arvind Narayanan
Sayash Kapoor, Rishi Bommasani, Kevin Klyman, Shayne Longpre, Ashwin Ramaswami, Peter Cihon, Aspen Hopkins, Kevin Bankston, Stella Biderman, Miranda Bogen, Rumman Chowdhury, Alex Engler, Peter Henderson, Yacine Jernite, Seth Lazar, Stefano Maffulli, Alondra Nelson, Joelle Pineau, Aviya Skowron, Dawn Song, Victor Storchan, Daniel Zhang, Daniel E. Ho, Percy...
-
[28]
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuh- mann, Huu Nguyen, and Alexander Mattick. 2023. OpenAssistant Conversations – Democratizing Large Lang...
-
[29]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(New York, NY, USA, 2023-10-23)(SOSP ’23). Association for Computing Machinery...
-
[30]
Nathan Lambert. [n. d.]. Stanford CS25: V4 I Aligning Open Language Models - YouTube. https://www.youtube.com/
-
[31]
Max Langenkamp and Daniel N. Yue. 2022. How Open Source Machine Learning Software Shapes AI. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. ACM, Oxford United Kingdom, 385–395. doi:10.1145/3514094.3534167
-
[32]
Andreas Liesenfeld and Mark Dingemanse. 2024. Rethinking Open Source Generative AI: Open Washing and the EU AI Act. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency. ACM, Rio de Janeiro Brazil, 1774–1787. doi:10.1145/3630106.3659005
-
[33]
Andreas Liesenfeld, Alianda Lopez, and Mark Dingemanse. 2023. Opening up ChatGPT: Tracking Openness, Transparency, and Accountability in Instruction-Tuned Text Generators. InProceedings of the 5th International Conference on Conversational User Interfaces (Eindhoven Netherlands, 2023-07-19). ACM, 1–6. doi:10.1145/3571884.3604316
-
[34]
Johan Linåker, Cailean Osborne, Jennifer Ding, and Ben Burtenshaw. 2025.A Cartography of Open Collaboration in Open Source AI: Mapping Practices, Motivations, and Governance in 14 Open Large Language Model Projects. arXiv:2509.25397 [cs] doi:10.48550/arXiv.2509. 25397
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509 2025
-
[35]
2025.Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem
Shayne Longpre, Christopher Akiki, Campbell Lund, Atharva Kulkarni, Emily Chen, Irene Solaiman, Avijit Ghosh, Yacine Jernite, and Lucie-Aimée Kaffee. 2025.Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem. arXiv:2512.03073 [cs] doi:10.48550/arXiv.2512.03073
-
[36]
2025.Meta’s LLaMa License Is Still Not Open Source
Jordan Maris. 2025.Meta’s LLaMa License Is Still Not Open Source. Open Source Initiative. https://opensource.org/blog/metas-llama- license-is-still-not-open-source/
2025
-
[37]
Leland McInnes, John Healy, Steve Astels, et al. 2017. hdbscan: Hierarchical density based clustering.J. Open Source Softw.2, 11 (2017), 205
2017
-
[38]
Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426(2018)
Pith/arXiv arXiv 2018
-
[39]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2024. 2 OLMo 2 Furious.arXiv preprint arXiv:2501.00656(2024)
Pith/arXiv arXiv 2024
-
[40]
Cailean Osborne, Jennifer Ding, and Hannah Rose Kirk. 2024. The AI Community Building the Future? A Quantitative Analysis of Development Activity on Hugging Face Hub.Journal of Computational Social Science7, 2 (Oct. 2024), 2067–2105. doi:10.1007/s42001- 024-00300-8
-
[41]
Tamara Paris, AJung Moon, and Jin L.C. Guo. 2025. Opening the Scope of Openness in AI. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 1293–1311. doi:10.1145/3715275.3732087
-
[42]
Nicholas Proferes, Naiyan Jones, Sarah Gilbert, Casey Fiesler, and Michael Zimmer. 2021. Studying Reddit: A Systematic Overview of Disciplines, Approaches, Methods, and Ethics.Social Media + Society7, 2 (April 2021), 20563051211019004. doi:10.1177/20563051211019004
-
[43]
Weihong Qi, Jinsheng Pan, Hanjia Lyu, and Jiebo Luo. 2023. Excitements and Concerns in the Post-ChatGPT Era: Deciphering Public Perception of AI through Social Media Analysis.Telematics Informatics92 (2023), 102158. https://api.semanticscholar.org/CorpusId: 259837235
2023
-
[44]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. Direct Preference Optimization: Your Language Model Is Secretly a Reward Model. arXiv:2305.18290 [cs] doi:10.48550/arXiv.2305.18290
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.18290 2024
-
[45]
Reddit. 2021. Advertising—Audience—Reddit. Discover what makes Reddit ads unique. Red- dit.com. (2021, January 17). Advertising—Audience—Reddit. Discover what makes Reddit ads unique. https://web.archive.org/web/20210117184818/https://www.redditinc.com/advertising/audience
arXiv 2021
-
[46]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[47]
Elizabeth Seger, Noemi Dreksler, Richard Moulange, Emily Dardaman, Jonas Schuett, K. Wei, Christoph Winter, Mackenzie Arnold, Seán Ó hEigeartaigh, Anton Korinek, Markus Anderljung, Ben Bucknall, Alan Chan, Eoghan Stafford, Leonie Koessler, Aviv Ovadya, Ben Open AI in the Wild: Adoption and Adaptation of Open Models on r/LocalLLaMA FAccT ’26, June 25–28, 2...
-
[48]
Elizabeth Seger, Aviv Ovadya, Divya Siddarth, Ben Garfinkel, and Allan Dafoe. 2023. Democratising AI: Multiple Meanings, Goals, and Methods. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’23). Association for Computing Machinery, New York, NY, USA, 715–722. doi:10.1145/3600211.3604693
-
[49]
2023.The Mirage of Open-Source AI: Analyzing Meta’s Llama 2 Release Strategy
Alex Tarkowski. 2023.The Mirage of Open-Source AI: Analyzing Meta’s Llama 2 Release Strategy. Open Future. https://openfuture.eu/ blog/the-mirage-of-open-source-ai-analyzing-metas-llama-2-release-strategy
2023
-
[50]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971 (2023)
Pith/arXiv arXiv 2023
-
[51]
Eric Von Hippel. 2005. Open Source Software Projects as "User Innovation Networks". InPerspectives on Free and Open Source Software, Joseph Feller, Brian Fitzgerald, Scott A. Hissam, and Karim R. Lakhani (Eds.). The MIT Press, 267–278. doi:10.7551/mitpress/5326.003.0021
-
[52]
Matt White, Ibrahim Haddad, Cailean Osborne, Xiao-Yang Yanglet Liu, Ahmed Abdelmonsef, Sachin Varghese, and Arnaud Le Hors
-
[53]
arXiv preprint arXiv:2403.13784 (2024) https://doi.org/10.48550/arXiv.2403.13784
The Model Openness Framework: Promoting Completeness and Openness for Reproducibility, Transparency, and Usability in Artificial Intelligence. arXiv:2403.13784 [cs] doi:10.48550/arXiv.2403.13784
-
[54]
David Gray Widder, Sarah West, and Meredith Whittaker. 2023. Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI. social science research network:4543807 doi:10.2139/ssrn.4543807
-
[55]
BigScience Workshop, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, et al. 2022. Bloom: A 176b-parameter open-access multilingual language model.arXiv preprint arXiv:2211.05100(2022). FAccT ’26, June 25–28, 2026, Montreal, Canada Lee et al. A Posts with res...
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.