On the Sparsity-Storage-Accuracy Tradeoff in Parsimoniously Activated Dictionary Learning
Pith reviewed 2026-06-26 11:11 UTC · model grok-4.3
The pith
PADL admits an equivalent MAP formulation under a generative model with auxiliary latents, yielding an analytical sparsity-storage-accuracy tradeoff.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing auxiliary latent variables that govern global activation patterns, PADL becomes equivalent to MAP estimation under a structured generative model; this equivalence produces both generalization bounds and an explicit analytical characterization of the sparsity-storage-accuracy tradeoff that enables automatic hyperparameter estimation.
What carries the argument
The structured generative model with auxiliary latent variables that enforce the global constraint on activated dictionary atoms, rendering the MAP objective identical to the original PADL objective.
If this is right
- Generalization guarantees become available for PADL.
- Hyperparameters can be chosen directly from data without manual tuning.
- Reconstruction accuracy improves at the same sparsity level on visual benchmarks.
- The method accelerates inference inside vision-language models.
Where Pith is reading between the lines
- The same auxiliary-variable construction may apply to other dictionary-learning variants that use global rather than element-wise sparsity.
- The closed-form tradeoff could guide compression decisions when storing sparse codes for large-scale vision models.
- Data-driven hyperparameter selection might reduce reliance on cross-validation in related sparse coding algorithms.
Load-bearing premise
The global constraint on the number of activated dictionary atoms can be exactly represented by auxiliary latent variables such that the MAP objective is mathematically equivalent to the PADL regularization and produces a tractable analytical tradeoff expression.
What would settle it
If the hyperparameters chosen by minimizing the analytical tradeoff expression fail to match the empirically optimal values on held-out reconstruction error, or if the predicted accuracy curve deviates systematically from measured performance across sparsity levels.
Figures
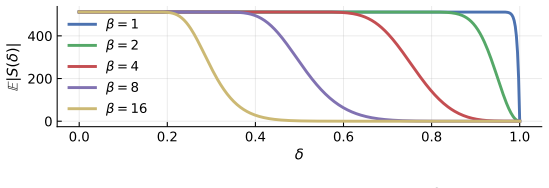
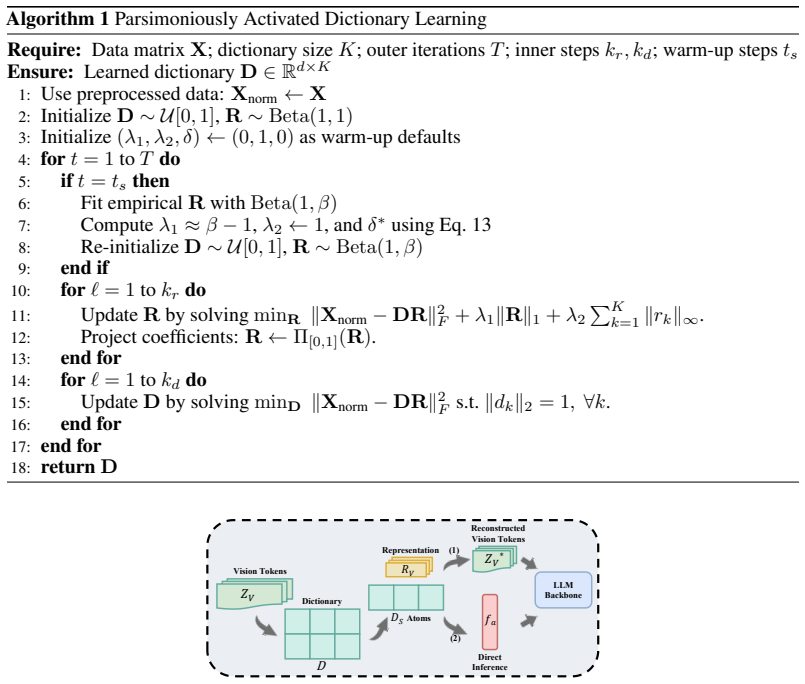
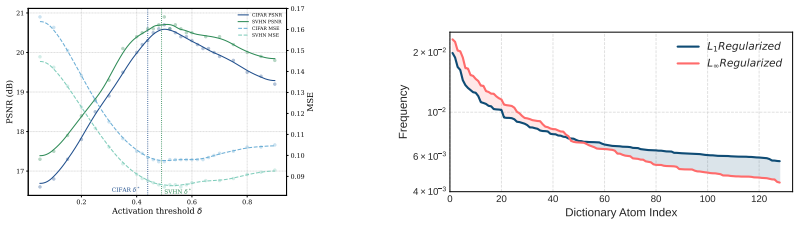
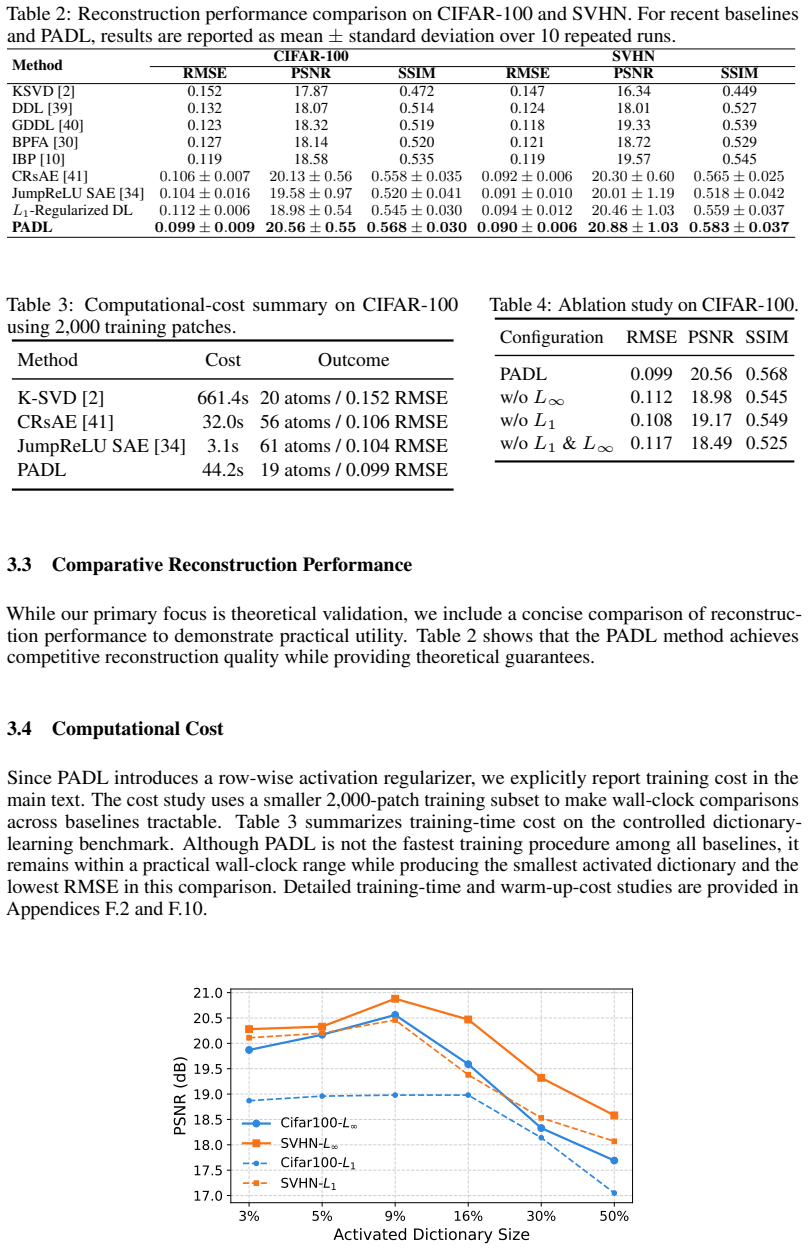
read the original abstract
Dictionary learning has long been studied from both optimization and probabilistic perspectives. While formulations with element-wise sparsity regularization (e.g., L1-based sparse coding) admit well-established probabilistic interpretations, many structured variants that impose global constraints lack a clear and tractable generative view. In this paper, we revisit a class of practically effective yet theoretically under-explored dictionary learning methods that impose a simple global regularization on the number of activated dictionary atoms, which we term parsimoniously activated dictionary learning (PADL). We show that PADL admits an equivalent formulation as maximum a posteriori estimation under a structured generative model, with auxiliary latent variables that govern global activation patterns. This formulation allows us to derive generalization guarantees that are difficult to obtain under the original formulation. More importantly, it yields an analytical characterization of the tradeoff between sparsity, storage cost, and reconstruction accuracy, enabling data-driven estimation of optimal hyperparameters. Based on this connection, we develop an efficient and interpretable PADL algorithm that eliminates manual hyperparameter tuning, achieving improved reconstruction performance under comparable sparsity levels on visual benchmarks. We further demonstrate its practical utility in accelerating inference for vision-language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces parsimoniously activated dictionary learning (PADL), which applies a global constraint on the number of activated dictionary atoms rather than element-wise sparsity. It claims that PADL is equivalent to maximum a posteriori estimation in a structured generative model using auxiliary latent variables for global activation patterns. This equivalence is used to derive generalization guarantees and an analytical expression for the sparsity-storage-accuracy tradeoff, which enables data-driven hyperparameter selection. An efficient algorithm is developed from this view and evaluated on visual benchmarks for reconstruction and on accelerating inference in vision-language models.
Significance. If the claimed equivalence is exact and the analytical tradeoff is derived without circularity or approximation, the work would supply a principled probabilistic foundation for a practically useful but theoretically under-explored form of structured sparsity, together with a mechanism for automatic hyperparameter choice and reproducible performance gains. The provision of generalization bounds and a closed-form tradeoff would be notable strengths.
major comments (2)
- [Section 3 (Equivalence to MAP Estimation)] The central claim of mathematical equivalence between the original PADL objective (with its global cardinality constraint) and the MAP objective under the auxiliary-latent generative model is load-bearing for both the generalization guarantees and the analytical tradeoff. The manuscript must exhibit the explicit construction (including the precise prior or counting process on the auxiliary variables) that makes the two objectives identical rather than approximately related after marginalization.
- [Section 4 (Analytical Tradeoff)] The analytical characterization of the sparsity-storage-accuracy tradeoff is asserted to be closed-form and to support data-driven hyperparameter estimation. The derivation must be shown to be independent of quantities fitted from the same data used for evaluation; otherwise the reported performance improvements on visual benchmarks cannot be interpreted as evidence that the tradeoff expression is predictive rather than descriptive.
minor comments (2)
- Notation for the auxiliary latent variables and the global activation indicator should be introduced with an explicit table or diagram to avoid ambiguity when the same symbols appear in both the original PADL formulation and the generative model.
- The experimental section should include an ablation that isolates the effect of the data-driven hyperparameter procedure from other implementation choices (e.g., initialization or optimization schedule).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Section 3 (Equivalence to MAP Estimation)] The central claim of mathematical equivalence between the original PADL objective (with its global cardinality constraint) and the MAP objective under the auxiliary-latent generative model is load-bearing for both the generalization guarantees and the analytical tradeoff. The manuscript must exhibit the explicit construction (including the precise prior or counting process on the auxiliary variables) that makes the two objectives identical rather than approximately related after marginalization.
Authors: We agree that the explicit construction is required for rigor. The current manuscript sketches the auxiliary-variable model but does not fully specify the prior. In the revision we will insert the precise prior: the auxiliary activation pattern Z is drawn uniformly from the set of all binary vectors with exactly k ones, i.e., p(Z) = binom(m,k)^{-1} whenever ||Z||_0 = k (and zero otherwise), where m is the dictionary size. The negative log-prior term then becomes exactly the global cardinality penalty, making the MAP objective identical to the original PADL objective. The revised Section 3 will contain this derivation together with the resulting equivalence proof. revision: yes
-
Referee: [Section 4 (Analytical Tradeoff)] The analytical characterization of the sparsity-storage-accuracy tradeoff is asserted to be closed-form and to support data-driven hyperparameter estimation. The derivation must be shown to be independent of quantities fitted from the same data used for evaluation; otherwise the reported performance improvements on visual benchmarks cannot be interpreted as evidence that the tradeoff expression is predictive rather than descriptive.
Authors: We accept the referee's point on independence. The closed-form tradeoff expression itself is derived solely from the generative model and does not depend on fitted quantities from the evaluation set. Hyperparameter selection proceeds by estimating the model parameters on a held-out validation split that is disjoint from the test data used to report reconstruction and acceleration results. In the revision we will add an explicit paragraph in Section 4 describing this data-partitioning protocol and confirming that no test-set information enters the tradeoff-based hyperparameter choice. This clarification will allow the benchmark numbers to be read as out-of-sample validation of the tradeoff's predictive utility. revision: yes
Circularity Check
No significant circularity; equivalence reformulation enables independent derivations
full rationale
The paper's central step is showing that the PADL objective admits an equivalent MAP formulation under a generative model with auxiliary latents that exactly encode the global activation constraint. This is presented as a mathematical equivalence that then permits deriving generalization bounds and an analytical sparsity-storage-accuracy tradeoff expression. No quoted equations or self-citations in the provided text demonstrate that the tradeoff reduces to a fitted quantity by construction, that the equivalence is smuggled via prior self-work, or that any prediction is statistically forced from a subset of the same data. The data-driven hyperparameter estimation is a downstream application of the derived expression rather than a circular input. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dna sequence compression using the burrows-wheeler transform
Don Adjeroh, Yong Zhang, Amar Mukherjee, Matt Powell, and Tim Bell. Dna sequence compression using the burrows-wheeler transform. InProceedings. IEEE computer society bioinformatics conference, pages 303–313. IEEE, 2002
2002
-
[2]
K-svd: An algorithm for designing overcomplete dictionaries for sparse representation.IEEE Transactions on signal processing, 54(11):4311–4322, 2006
Michal Aharon, Michael Elad, and Alfred Bruckstein. K-svd: An algorithm for designing overcomplete dictionaries for sparse representation.IEEE Transactions on signal processing, 54(11):4311–4322, 2006
2006
-
[3]
Hedy Attouch, Jérôme Bolte, and Benar Fux Svaiter. Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward–backward splitting, and regularized gauss–seidel methods.Mathematical programming, 137(1):91–129, 2013
2013
-
[4]
Bayesian group-sparse modeling and variational inference.IEEE transactions on signal processing, 62(11):2906–2921, 2014
S Derin Babacan, Shinichi Nakajima, and Minh N Do. Bayesian group-sparse modeling and variational inference.IEEE transactions on signal processing, 62(11):2906–2921, 2014
2014
-
[5]
Alberto Bocchinfuso, Daniela Calvetti, and Erkki Somersalo. Bayesian sparsity and class sparsity priors for dictionary learning and coding.arXiv preprint arXiv:2309.00999, 2023
arXiv 2023
-
[6]
Proximal alternating linearized minimization for nonconvex and nonsmooth problems.Mathematical Programming, 146(1):459–494, 2014
Jérôme Bolte, Shoham Sabach, and Marc Teboulle. Proximal alternating linearized minimization for nonconvex and nonsmooth problems.Mathematical Programming, 146(1):459–494, 2014
2014
-
[7]
Sparse variational inference: Bayesian coresets from scratch.Advances in Neural Information Processing Systems, 32, 2019
Trevor Campbell and Boyan Beronov. Sparse variational inference: Bayesian coresets from scratch.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[8]
Feilong Chen, Minglun Han, Haozhi Zhao, Qingyang Zhang, Jing Shi, Shuang Xu, and Bo Xu. X-llm: Bootstrapping advanced large language models by treating multi-modalities as foreign languages.arXiv preprint arXiv:2305.04160, 2023
arXiv 2023
-
[9]
Atomic decomposition by basis pursuit.SIAM review, 43(1):129–159, 2001
Scott Shaobing Chen, David L Donoho, and Michael A Saunders. Atomic decomposition by basis pursuit.SIAM review, 43(1):129–159, 2001
2001
-
[10]
Indian buffet process dictionary learning: algorithms and applications to image processing.International Journal of Approximate Reasoning, 83: 1–20, 2017
Hong-Phuong Dang and Pierre Chainais. Indian buffet process dictionary learning: algorithms and applications to image processing.International Journal of Approximate Reasoning, 83: 1–20, 2017
2017
-
[11]
Towards dictionaries of optimal size: A bayesian non parametric approach.Journal of Signal Processing Systems, 90(2):221–232, 2018
Hong Phuong Dang and Pierre Chainais. Towards dictionaries of optimal size: A bayesian non parametric approach.Journal of Signal Processing Systems, 90(2):221–232, 2018
2018
-
[12]
Adaptive-size dictionary learning using information theoretic criteria.Algorithms, 12(9):178, 2019
Bogdan Dumitrescu and Ciprian Doru Giurc˘aneanu. Adaptive-size dictionary learning using information theoretic criteria.Algorithms, 12(9):178, 2019
2019
-
[13]
Springer Science & Business Media, 2010
Michael Elad.Sparse and redundant representations: from theory to applications in signal and image processing. Springer Science & Business Media, 2010
2010
-
[14]
Discrete sparse coding.Neural computation, 29(11): 2979–3013, 2017
Georgios Exarchakis and Jorg Lucke. Discrete sparse coding.Neural computation, 29(11): 2979–3013, 2017
2017
-
[15]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
Pith/arXiv arXiv 2023
-
[16]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017. 10
2017
-
[17]
Binary sparse coding
Marc Henniges, Gervasio Puertas, Jörg Bornschein, Julian Eggert, and Jörg Lücke. Binary sparse coding. InInternational Conference on Latent Variable Analysis and Signal Separation, pages 450–457. Springer, 2010
2010
-
[18]
Tgif-qa: Toward spatio-temporal reasoning in visual question answering
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio-temporal reasoning in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2758–2766, 2017
2017
-
[19]
Submodular dictionary selection for sparse representation
Andreas Krause and V olkan Cevher. Submodular dictionary selection for sparse representation. InInternational Conference on Machine Learning (ICML), 2010
2010
-
[20]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[21]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models.arXiv preprint arXiv:2305.10355, 2023
Pith/arXiv arXiv 2023
-
[22]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 5971–5984, 2024
2024
-
[23]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[24]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[25]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35: 2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35: 2507–2521, 2022
2022
-
[26]
Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Da Li, Pengcheng Lu, Tao Wang, Linmei Hu, Minghui Qiu, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability.arXiv preprint arXiv:2306.07207, 2023
arXiv 2023
-
[27]
Online dictionary learning for sparse coding
Julien Mairal, Francis Bach, Jean Ponce, and Guillermo Sapiro. Online dictionary learning for sparse coding. InProceedings of the 26th annual international conference on machine learning, pages 689–696, 2009
2009
-
[28]
Reading digits in natural images with unsupervised feature learning
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Baolin Wu, Andrew Y Ng, et al. Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learning, volume 2011, page 7. Granada, 2011
2011
-
[29]
Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997
Bruno A Olshausen and David J Field. Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997
1997
-
[30]
Nonparametric factor analysis with beta process priors
John Paisley and Lawrence Carin. Nonparametric factor analysis with beta process priors. In Proceedings of the 26th annual international conference on machine learning, pages 777–784, 2009
2009
-
[31]
Working locally thinking globally: Theoret- ical guarantees for convolutional sparse coding.IEEE Transactions on Signal Processing, 65 (21):5687–5701, 2017
Vardan Papyan, Jeremias Sulam, and Michael Elad. Working locally thinking globally: Theoret- ical guarantees for convolutional sparse coding.IEEE Transactions on Signal Processing, 65 (21):5687–5701, 2017
2017
-
[32]
Vardan Papyan, Yaniv Romano, Jeremias Sulam, and Michael Elad. Theoretical foundations of deep learning via sparse representations: A multilayer sparse model and its connection to convolutional neural networks.IEEE Signal Processing Magazine, 35(4):72–89, 2018
2018
-
[33]
Sangha Park, Seungryong Yoo, Jisoo Mok, and Sungroh Yoon. Save: Sparse autoencoder- driven visual information enhancement for mitigating object hallucination.arXiv preprint arXiv:2512.07730, 2025. 11
arXiv 2025
-
[34]
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders.arXiv preprint arXiv:2407.14435, 2024
Pith/arXiv arXiv 2024
-
[35]
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumrge: Adaptive token reduction for efficient large multimodal models.arXiv preprint arXiv:2403.15388, 2024
arXiv 2024
-
[36]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
2019
-
[37]
Data-efficient and robust trajectory generation through pathlet dictionary learning
Yan Tang, Zihui Zhao, Zixuan Zhang, Yang Li, et al. Data-efficient and robust trajectory generation through pathlet dictionary learning. InThe Third Conference on Parsimony and Learning (Proceedings Track)
-
[38]
Explainable trajectory representation through dictionary learning
Yuanbo Tang, Zhiyuan Peng, and Yang Li. Explainable trajectory representation through dictionary learning. InProceedings of the 31st ACM International Conference on Advances in Geographic Information Systems, pages 1–4, 2023
2023
-
[39]
Deep dictionary learning
Snigdha Tariyal, Angshul Majumdar, Richa Singh, and Mayank Vatsa. Deep dictionary learning. IEEE Access, 4:10096–10109, 2016
2016
-
[40]
Greedy deep dictionary learning.arXiv preprint arXiv:1602.00203, 2016
Snigdha Tariyal, Angshul Majumdar, Richa Singh, and Mayank Vatsa. Greedy deep dictionary learning.arXiv preprint arXiv:1602.00203, 2016
Pith/arXiv arXiv 2016
-
[41]
Deep residual autoencoders for expectation maximization-inspired dictionary learning.IEEE Transactions on neural networks and learning systems, 32(6):2415–2429, 2020
Bahareh Tolooshams, Sourav Dey, and Demba Ba. Deep residual autoencoders for expectation maximization-inspired dictionary learning.IEEE Transactions on neural networks and learning systems, 32(6):2415–2429, 2020
2020
-
[42]
Algorithms for simultaneous sparse approximation
Joel A Tropp, Anna C Gilbert, and Martin J Strauss. Algorithms for simultaneous sparse approximation. part i: Greedy pursuit.Signal processing, 86(3):572–588, 2006
2006
-
[43]
Convergence of a block coordinate descent method for nondifferentiable minimiza- tion.Journal of optimization theory and applications, 109(3):475–494, 2001
Paul Tseng. Convergence of a block coordinate descent method for nondifferentiable minimiza- tion.Journal of optimization theory and applications, 109(3):475–494, 2001
2001
-
[44]
Bingxin Xu, Yuzhang Shang, Yunhao Ge, Qian Lou, and Yan Yan. freepruner: A training-free approach for large multimodal model acceleration.arXiv preprint arXiv:2411.15446, 2024
arXiv 2024
-
[45]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016
2016
-
[46]
Activitynet-qa: A dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 9127–9134, 2019
2019
-
[47]
Model selection and estimation in regression with grouped variables
Ming Yuan and Yi Lin. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society Series B: Statistical Methodology, 68(1):49–67, 2006
2006
-
[48]
Hybridtoken-vlm: Hybrid token compression for vision-language models
Jusheng Zhang, Xiaoyang Guo, Kaitong Cai, Qinhan Lv, Yijia Fan, Wenhao Chai, Jian Wang, and Keze Wang. Hybridtoken-vlm: Hybrid token compression for vision-language models. arXiv preprint arXiv:2512.08240, 2025
arXiv 2025
-
[49]
Unicode: Learning a unified codebook for multimodal large language models
Sipeng Zheng, Bohan Zhou, Yicheng Feng, Ye Wang, and Zongqing Lu. Unicode: Learning a unified codebook for multimodal large language models. InEuropean Conference on Computer Vision, pages 426–443. Springer, 2024
2024
-
[50]
Limitations
Mingyuan Zhou, Haojun Chen, Lu Ren, Guillermo Sapiro, Lawrence Carin, and John Paisley. Non-parametric bayesian dictionary learning for sparse image representations.Advances in neural information processing systems, 22, 2009. 12 A Related Works A.1 Dictionary Learning and Sparse Representation Traditional dictionary learning aims to represent data using a...
2009
-
[51]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects 34 Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.