FetSelect: Task-Specific Architectures and Self-Supervised Learning for Automated Fetal Ultrasound Frame Selection
Pith reviewed 2026-06-26 10:43 UTC · model grok-4.3
The pith
FetSelect uses a frozen vision backbone with BYOL pretraining and a hybrid multi-head design to select quality fetal ultrasound frames for biometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
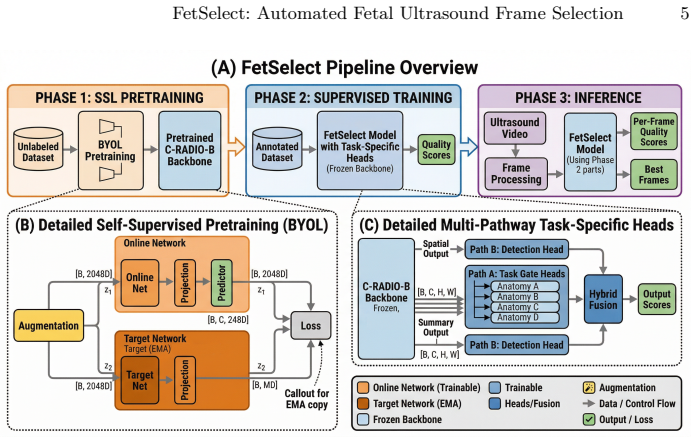
FetSelect shows that pairing a frozen vision backbone pretrained with BYOL on unlabeled fetal ultrasound images with a hybrid architecture of task-gated classification and detection-derived quality scoring fused by learned weights produces frame selections that align closely with expert quality judgments across four distinct biometry targets.
What carries the argument
Hybrid multi-head design of a Task-Gated classification head and a Detection-derived quality head combined via learned fusion, applied after BYOL adaptation of a frozen vision backbone.
If this is right
- Downstream fetal biometry pipelines can receive frames directly from video without manual curation.
- Self-supervision on unlabeled scans improves discrimination without extra expert annotations.
- Task-specific heads allow quality criteria to differ across targets such as CRL versus NT.
- Performance observed on external clinical videos and additional CRL images suggests the method can transfer beyond the original training distribution.
Where Pith is reading between the lines
- The same hybrid-head pattern could be tested on frame selection for other ultrasound examinations such as cardiac or abdominal scans.
- Adding explicit temporal modeling across consecutive video frames might further raise agreement with experts.
- The reliance on a frozen backbone implies that larger foundation models pretrained on broader medical data could raise the ceiling without retraining the entire network.
Load-bearing premise
Expert-labeled frames supply a reliable and unbiased ground truth for quality, and the held-out test set together with external evaluations are enough to show generalization across sites and equipment.
What would settle it
A prospective study that feeds FetSelect-selected frames into actual clinical biometry software and measures whether the resulting length or thickness values differ systematically from those obtained by expert-selected frames on the same patients and machines.
Figures

read the original abstract
Automated frame selection for fetal biometry remains under addressed, with most prior work targeting generic quality assessment or downstream measurement pipelines that assume suitable frames are available. We introduce FetSelect, a task-specific framework that pairs a frozen vision foundation backbone with a hybrid multi-head design: a Task-Gated classification head and a Detection-derived quality head combined via learned fusion. We curate 6,486 expert-labeled frames across four targets: Crown-Rump Length (CRL), Nuchal Translucency (NT), Nasal Bone (NB), and Scalebar, and adapt the backbone with BYOL pretraining on 19,019 unlabeled images. On a held-out test set (974 frames), FetSelect achieves mean AUROC 0.956 and mean correlation 0.818 with expert quality annotations. Ablations confirm that hybrid fusion surpasses single-head variants, and ultrasound-specific self-supervision yields consistent gains. Evaluation on external clinical videos and 509 external CRL images demonstrates task-specific discrimination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FetSelect, a task-specific framework for automated fetal ultrasound frame selection. It pairs a frozen vision foundation backbone (adapted via BYOL self-supervision on 19,019 unlabeled images) with a hybrid multi-head architecture consisting of a Task-Gated classification head and a Detection-derived quality head, fused via learned weights. The authors curate 6,486 expert-labeled frames across four targets (CRL, NT, NB, Scalebar) and report mean AUROC 0.956 and mean correlation 0.818 with expert annotations on a 974-frame held-out test set. Ablations are presented to support the hybrid design and self-supervision benefits, with additional results on external clinical videos and 509 external CRL images.
Significance. If the central results hold after addressing label reliability, the work provides a concrete empirical demonstration that hybrid task-specific heads plus ultrasound-adapted self-supervision can yield strong discrimination for frame quality in fetal biometry, an area with limited prior task-specific methods. The external evaluations offer modest support for generalization claims beyond the primary dataset.
major comments (1)
- [Abstract] Abstract (performance claims) and data curation description: All reported metrics (mean AUROC 0.956 and mean correlation 0.818 on the 974-frame held-out set, plus external results) are computed exclusively against expert quality annotations as ground truth. No inter-rater agreement statistics (kappa, ICC, or multi-rater overlap) are supplied for the 6,486 labeled frames. This is load-bearing for the central claim of reliable task-specific selection, because without evidence that the labels reflect a stable quality signal rather than rater-specific noise, the ablation gains and external-video discrimination cannot be interpreted as evidence of clinical utility.
minor comments (2)
- [Abstract] Abstract: clarify whether the reported 'mean AUROC' and 'mean correlation' are macro-averages across the four targets or computed differently; this affects interpretation of the aggregate numbers.
- The manuscript would benefit from an explicit limitations paragraph addressing potential site/equipment biases in the external sets and the dependence on single-rater labels.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of label reliability. We address the single major comment below and note that our response is limited by the data collection protocol used in the study.
read point-by-point responses
-
Referee: [Abstract] Abstract (performance claims) and data curation description: All reported metrics (mean AUROC 0.956 and mean correlation 0.818 on the 974-frame held-out set, plus external results) are computed exclusively against expert quality annotations as ground truth. No inter-rater agreement statistics (kappa, ICC, or multi-rater overlap) are supplied for the 6,486 labeled frames. This is load-bearing for the central claim of reliable task-specific selection, because without evidence that the labels reflect a stable quality signal rather than rater-specific noise, the ablation gains and external-video discrimination cannot be interpreted as evidence of clinical utility.
Authors: We agree that the absence of inter-rater agreement metrics is a substantive limitation. Each of the 6,486 frames was annotated by a single expert following standard clinical protocols for the four targets, and no multi-rater overlap was collected. Consequently we cannot compute kappa, ICC, or similar statistics. We will revise the manuscript to (i) state this limitation explicitly in a new Limitations paragraph, (ii) qualify all performance claims as being relative to the available single-expert annotations rather than a proven stable ground truth, and (iii) moderate language concerning immediate clinical utility. The external-video and external-CRL results remain informative as consistency checks but cannot substitute for multi-rater reliability data. revision: partial
- Provision of inter-rater agreement statistics (kappa, ICC, or multi-rater overlap) for the 6,486 labeled frames, as multiple independent annotations per frame were never collected.
Circularity Check
No circularity: purely empirical reporting with no derivations or self-referential predictions
full rationale
The manuscript contains no equations, derivations, or first-principles claims. All reported results are direct empirical measurements (AUROC 0.956, correlation 0.818) computed on a held-out test set against external expert labels. Self-supervision (BYOL) and hybrid-head ablations are standard training procedures whose outputs are evaluated on independent data; none reduce to the inputs by construction. No self-citation chains, uniqueness theorems, or fitted-parameter-as-prediction patterns appear. The work is therefore self-contained as standard ML experimentation.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned fusion weights
axioms (1)
- domain assumption Expert annotations serve as reliable ground truth for ultrasound frame quality.
Reference graph
Works this paper leans on
-
[1]
Akumu, T., Elbatel, M., Campello, V.M., Osuala, R., Martin-Isla, C., Valenzuela, I., Li, X., Khanal, B., Lekadir, K.: Adaptive frame selection for gestational age es- timation from blind sweep fetal ultrasound videos. In: MICCAI. pp. 3–13. Springer (2025). https://doi.org/10.1007/978-3-032-05185-1_1
-
[2]
https://doi.org/https://doi.org/10.1016/j.dib.2023.109708
Alzubaidi, M., Agus, M., Makhlouf, M., Anver, F., Alyafei, K., Househ, M.: Large- scaleannotationdatasetforfetalheadbiometryinultrasoundimages.DatainBrief 51, 109708 (2023). https://doi.org/https://doi.org/10.1016/j.dib.2023.109708
-
[3]
Bardes, A., Ponce, J., LeCun, Y.: Vicreg: Variance-invariance-covariance regular- ization for self-supervised learning (2022), https://arxiv.org/abs/2105.04906
Pith/arXiv arXiv 2022
-
[4]
IEEE Transactions on Medical Imaging36(11), 2204–2215 (2017)
Baumgartner, C.F., Kamnitsas, K., Matthew, J., Smith, S., Kainz, B., Rueckert, D.: Sononet: Real-time detection and localisation of fetal standard scan planes in freehand ultrasound. IEEE Transactions on Medical Imaging36(11), 2204–2215 (2017). https://doi.org/10.1109/TMI.2017.2712367
-
[5]
Nature Scientific Reports10, 10200 (2020)
Burgos-Artizzu, X., Coronado-Gutiérrez, D., Valenzuela-Alcaraz, B., Bonet-Carne, E., Eixarch, E., Crispi, F., Gratacós, E.: Evaluation of deep convolutional neu- ral networks for automatic classification of common maternal fetal ultrasound planes. Nature Scientific Reports10, 10200 (2020). https://doi.org/10.1038/ s41598-020-67076-5
2020
-
[6]
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers (2021), https://arxiv. org/abs/2104.14294
Pith/arXiv arXiv 2021
-
[7]
Scientific Data11(1), 436 (2024)
Chen, G., Bai, J., Ou, Z., Lu, Y., Wang, H.: Psfhs: Intrapartum ultrasound image dataset for ai-based segmentation of pubic symphysis and fetal head. Scientific Data11(1), 436 (2024). https://doi.org/10.1038/s41597-024-03266-4
-
[8]
https://doi.org/10.17632/4gcpm9dsc3.1, https://data.mendeley.com/datasets/4gcpm9dsc3/1
Correggio, K.S.D., Galluzzo, R.N., Santos, L.O., Barroso, F.S.M., Chaves, T.Z.L., Onofre, A.S.C., von Wangenheim, A.: Fetal abdominal structures segmentation dataset using ultrasonic images (2023). https://doi.org/10.17632/4gcpm9dsc3.1, https://data.mendeley.com/datasets/4gcpm9dsc3/1
-
[9]
https://doi.org/10.6084/m9.figshare.16570518.v1, https://figshare.com/articles/dataset/CRL/16570518
Ghelichoghli, M.: CRL (9 2021). https://doi.org/10.6084/m9.figshare.16570518.v1, https://figshare.com/articles/dataset/CRL/16570518
-
[10]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Do- ersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., Piot, B., Kavukcuoglu, K., Munos, FetSelect: Automated Fetal Ultrasound Frame Selection 13 R., Valko, M.: Bootstrap your own latent a new approach to self-supervised learn- ing. In: Proceedings of the 34th International Conf...
2020
-
[11]
Guo, X., Men, Q., Noble, J.A.: Mmsummary: Multimodal summary generation for fetal ultrasound video. In: MICCAI. pp. 678–688. Springer (2024). https://doi. org/10.1007/978-3-031-72083-3_63
-
[12]
He, D., Wang, H., Yaqub, M.: Advancing fetal ultrasound image quality assessment in low-resource settings (2025), https://arxiv.org/abs/2507.22802
arXiv 2025
-
[13]
Local deep im- plicit functions for 3d shape
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020). https://doi.org/ 10.1109/CVPR42600.2020.00975
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Heinrich, G., Ranzinger, M., Yin, H., Lu, Y., Kautz, J., Tao, A., Catanzaro, B., Molchanov, P.: Radiov2.5: Improved baselines for agglomerative vision foundation models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22487–22497 (June 2025)
2025
-
[15]
Herath, H.M.S.S., Herath, H.M.K.K.M.B., Madusanka, N., Lee, B.I.: A systematic reviewofmedicalimagequalityassessment.JournalofImaging11(4)(2025).https: //doi.org/10.3390/jimaging11040100
-
[16]
Synaptic Partner Assignment Using Attentional V oxel Association Networks
Jiao, J., Droste, R., Drukker, L., Papageorghiou, A.T., Noble, J.A.: Self-supervised representation learning for ultrasound video. In: IEEE 17th International Sympo- sium on Biomedical Imaging (ISBI). pp. 1125–1129. IEEE (2020). https://doi.org/ 10.1109/ISBI45749.2020.9098666
-
[17]
Medical image analysis 96, 103202 (2024)
Jiao,J.,Zhou,J.,Li,X.,Xia,M.,Huang,Y.,Huang,L.,Wang,N.,Zhang,X.,Zhou, S., Wang, Y., et al.: Usfm: A universal ultrasound foundation model generalized to tasks and organs towards label efficient image analysis. Medical image analysis 96, 103202 (2024)
2024
-
[18]
Computer Methods and Programs in Biomedicine226, 107170 (2022)
Lin, Q., Zhou, Y., Shi, S., Zhang, Y., Yin, S., Liu, X., Peng, Q., Huang, S., Jiang, Y., Cui, C., She, R., Xu, J., Dong, F.: How much can ai see in early pregnancy: A multi-center study of fetus head characterization in week 10–14 in ultrasound using deep learning. Computer Methods and Programs in Biomedicine226, 107170 (2022). https://doi.org/https://doi...
-
[19]
Maani,F.,Saeed,N.,Saleem,T.,Farooq,Z.,Alasmawi,H.,Diehl,W.,Mohammad, A., Waring, G., Valappi, S., Bricker, L., Yaqub, M.: Fetalclip: A visual-language foundation model for fetal ultrasound image analysis (2025), https://arxiv.org/ abs/2502.14807
arXiv 2025
-
[20]
Biomedical Signal Processing and Control122, 110313 (2026)
Megahed, Y., Ducharme, R., Erman, A., Walker, M.C., Hawken, S., Chan, A.D.: Usf-mae: Ultrasound self-supervised foundation model with masked autoencoding. Biomedical Signal Processing and Control122, 110313 (2026). https://doi.org/ https://doi.org/10.1016/j.bspc.2026.110313
-
[21]
Medical Image Analysis 103, 103611 (2025)
Mishra, D., Saha, P., Zhao, H., Hernandez-Cruz, N., Patey, O., Papageorghiou, A.T., Noble, J.A.: Tier-loc: Visual query-based video clip localization in fe- tal ultrasound videos with a multi-tier transformer. Medical Image Analysis 103, 103611 (2025). https://doi.org/https://doi.org/10.1016/j.media.2025.103611, https://www.sciencedirect.com/science/artic...
-
[22]
Imbalanced data problem in machine learning: A review,
Nehary, E.A., Rajan, S., Rossa, C.: Metric-based frame selection and deep learning model with multi-head self attention for classification of ultrasound lung video images. IEEE Access12, 79297–79310 (2024). https://doi.org/10.1109/ACCESS. 2024.10547274 14 M. Alzubaidi et al
-
[23]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W.,Howes,R.,Huang,P.Y.,Li,S.W.,Misra,I.,Rabbat,M.,Sharma,V.,Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without su...
Pith/arXiv arXiv 2024
-
[24]
Prenatal diagnosis32(3), 240–244 (2012)
Persico, N., Molina, F., Azumendi, G., Fedele, L., Nicolaides, K.H.: Nasal bone assessment in fetuses with trisomy 21 at 16–24 weeks of gestation by three- dimensional ultrasound. Prenatal diagnosis32(3), 240–244 (2012)
2012
-
[25]
American Journal of Obstetrics & Gyne- cology MFM7(4) (2025)
Płotka, S., Pustelnik, K., Szenejko, P., Żebrowska, K., Rzucidło-Szymańska, I., Szymecka-Samaha, N., Łęgowik, T., Kosińska-Kaczyńska, K., Korzeniowski, P., Biliński, P., Khalil, A., Brawura-Biskupski-Samaha, R., Išgum, I., Sánchez, C.I., Sitek, A.: Direct estimation of fetal biometry measurements from ultrasound video scans through deep learning. American...
-
[26]
American Jour- nal of Obstetrics & Gynecology MFM5(12), 101182 (2023)
Płotka, S.S., Grzeszczyk, M.K., Szenejko, P.I., Żebrowska, K., Szymecka-Samaha, N.A., Łęgowik, T., Lipa, M.A., Kosińska-Kaczyńska, K., Brawura-Biskupski- Samaha, R., Išgum, I., Sánchez, C.I., Sitek, A.: Deep learning for estimation of fetal weight throughout the pregnancy from fetal abdominal ultrasound. American Jour- nal of Obstetrics & Gynecology MFM5(...
-
[27]
Ramesh, J., Bacher, V., Eid, M.C., Kalabizadeh, H., Rupprecht, C., Namburete, A.I.L., Yeung, P.H., Wyburd, M.K., Dinsdale, N.K.: Automated fetal biometry assessment with deep ensembles using sparse-sampling of 2d intrapartum ultra- sound images. In: Intrapartum Ultrasound. pp. 46–60. Springer Nature Switzerland (2025). https://doi.org/10.1007/978-3-031-96318-6_5
-
[28]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ranzinger, M., Heinrich, G., Kautz, J., Molchanov, P.: Am-radio: Agglomerative vision foundation model reduce all domains into one. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12490–12500 (June 2024)
2024
-
[29]
Stebler, Y., Sutter, T.M., Ozkan, E., Vogt, J.E.: Temporal representation learning for real-time ultrasound analysis (2025), https://arxiv.org/abs/2509.01433
arXiv 2025
-
[30]
npj Digital Medicine8(1), 22 (2025)
Venturini, L., Budd, S., Farruggia, A., Wright, R., Matthew, J., Day, T.G., Kainz, B., Razavi, R., Hajnal, J.V.: Whole-examination ai estimation of fetal biometrics from 20-week ultrasound scans. npj Digital Medicine8(1), 22 (2025). https://doi. org/10.1038/s41746-024-01406-z
-
[31]
Yasrab, R., Fu, Z., Drukker, L., Lee, L.H., Zhao, H., Papageorghiou, A.T., Noble, J.A.: End-to-end first trimester fetal ultrasound video automated crl and nt seg- mentation. In: 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI). pp. 1–5 (2022). https://doi.org/10.1109/ISBI52829.2022.9761400
-
[32]
Medicine100(4) (2021)
Zhang, B., Liu, H., Luo, H., Li, K.: Automatic quality assessment for 2d fetal sonographic standard plane based on multitask learning. Medicine100(4) (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.