4DVLT: Dynamic Scene Understanding with Worldline-Centered Vision-Language Tracking
Pith reviewed 2026-06-26 10:49 UTC · model grok-4.3
The pith
Worldline-centered modeling improves target grounding accuracy by 19.62 points on Instruct-4D
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
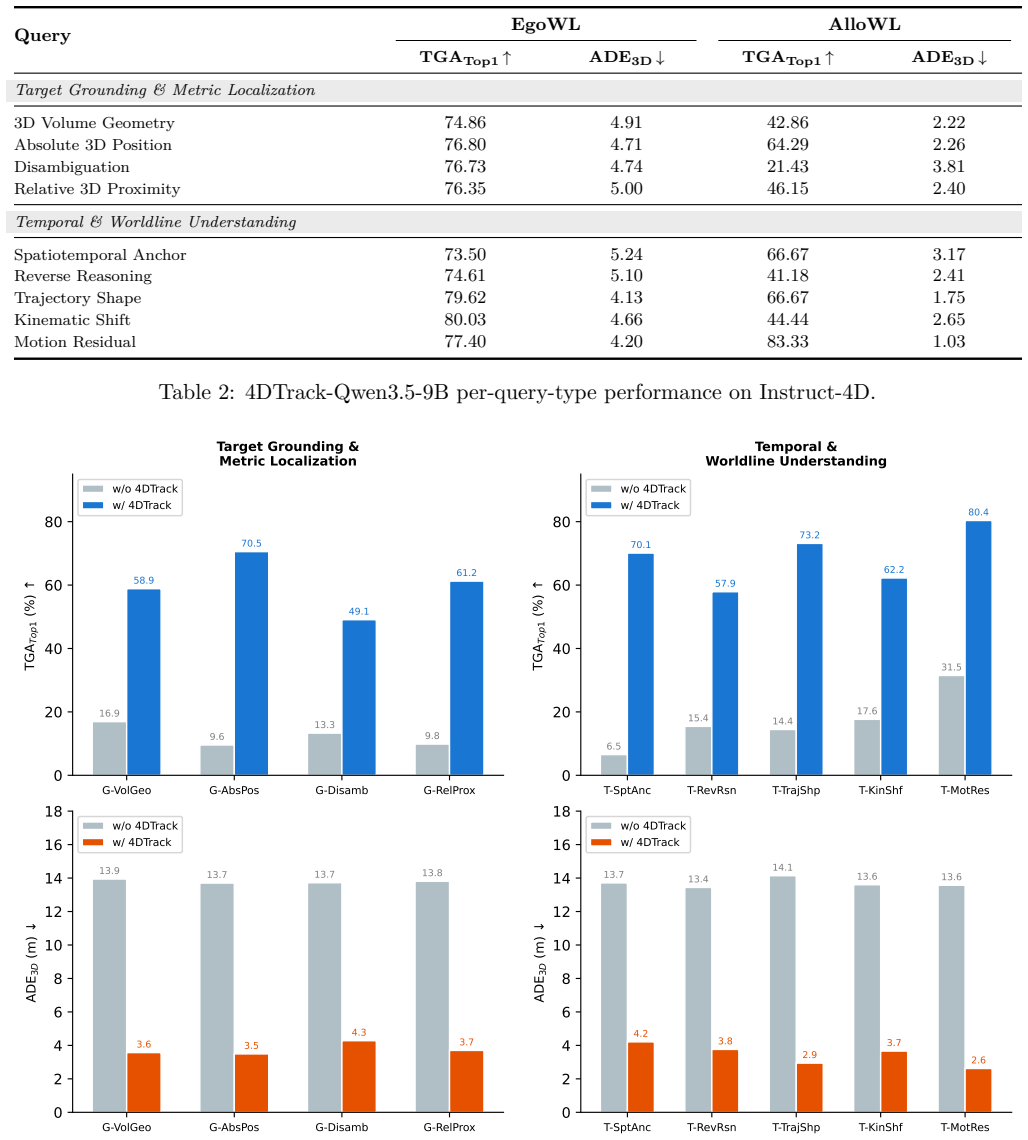
By centering vision-language tracking on worldlines that persist across time in fully observed multi-view video, the approach allows instruction-conditioned 4D dynamic scene understanding that preserves metric topology and identity continuity, unlike prior methods limited to fragmented 2D or 3D outputs. The 4DTrack implementation demonstrates this by reaching 62.68 TGA Top1 and outperforming baselines by 19.62 points on the Instruct-4D benchmark.
What carries the argument
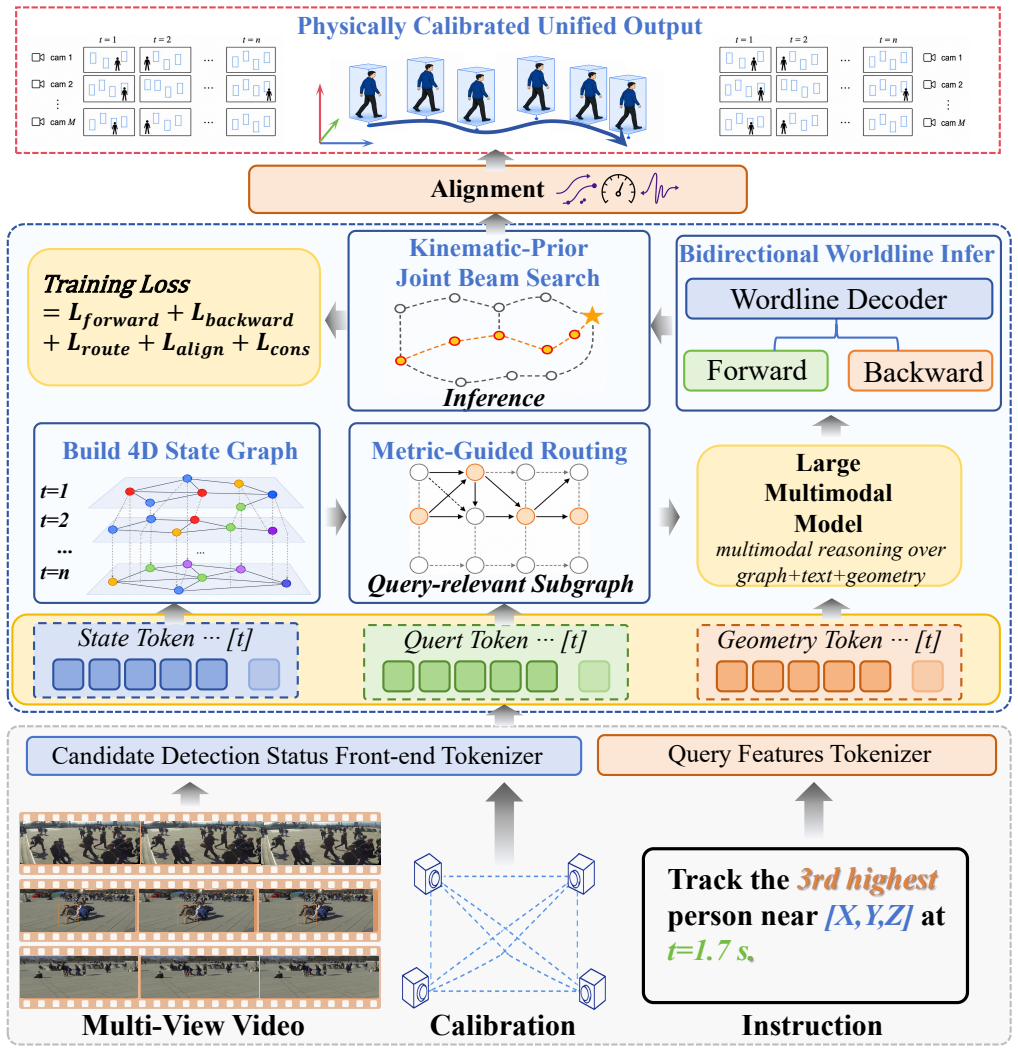
Graph-conditioned worldline inference through an object-centric 4D state graph, metric-guided routing, bidirectional decoding, and kinematic calibration.
If this is right
- Improved target grounding accuracy for language instructions in dynamic 4D scenes.
- Better quality of recovered worldlines that align with actual 3D motion.
- Effective handling of reasoning-oriented queries involving temporal and spatial relations.
- Applicability to both synthetic and captured scenes in the benchmark.
Where Pith is reading between the lines
- Similar worldline structures could help in extending 4D understanding to settings with fewer camera views.
- Combining this with larger multimodal models may enhance reasoning while keeping metric accuracy.
- Worldline inference might support downstream tasks like 4D scene editing or future prediction.
Load-bearing premise
The Instruct-4D benchmark provides a faithful test of instruction-conditioned 4D dynamic scene understanding that generalizes beyond its 851 scenes.
What would settle it
Evaluating the method on additional real-world multi-view video datasets with language queries outside the current benchmark distribution.
Figures









read the original abstract
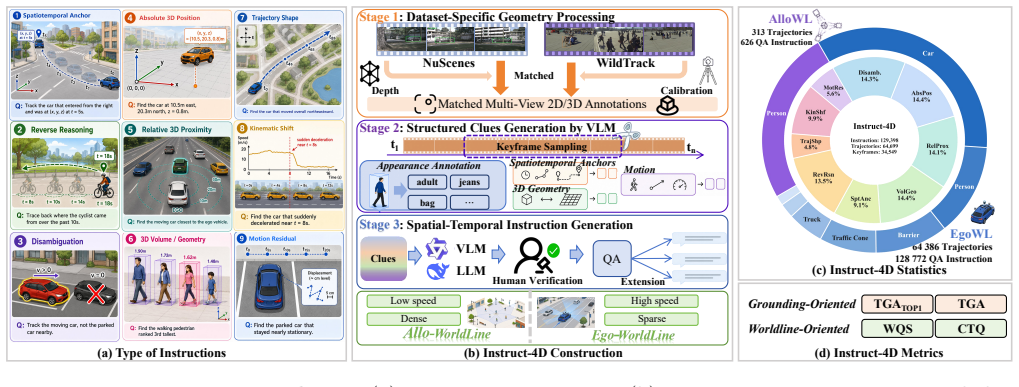
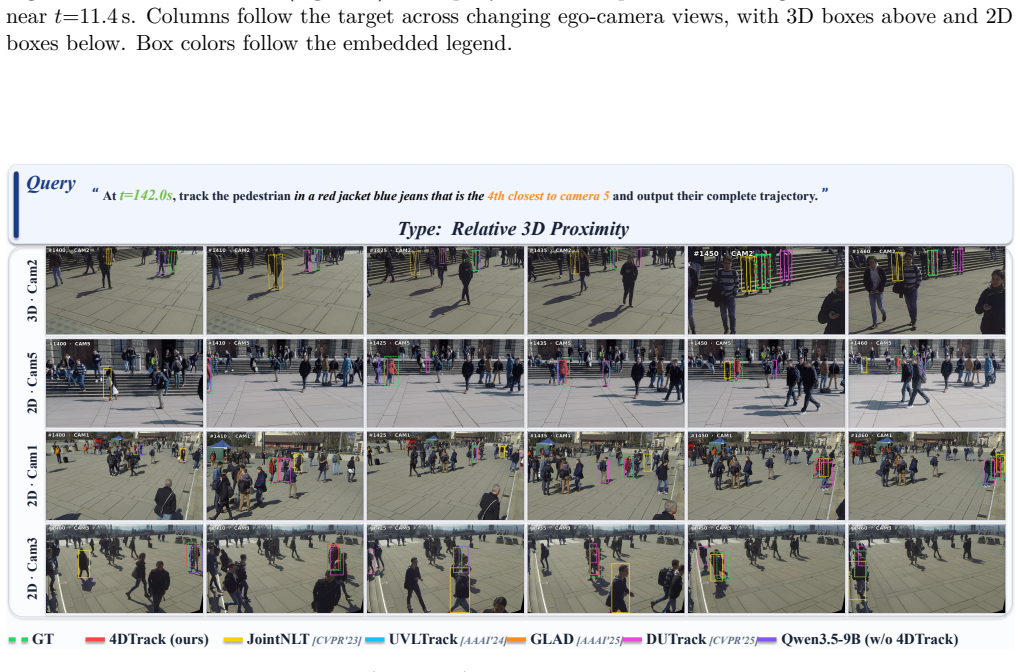
4D dynamic scene understanding requires grounding language to a persistent worldline that binds identity, metric 3D motion, and synchronized multi-view 2D projections. Existing paradigms capture only part of this structure: large multimodal models reason over rich visual evidence but rarely preserve metric topology, while vision-language tracking remains tied to fragmented 2D or 3D outputs and local continuation. We therefore introduce \textbf{4DVLT}, a worldline-centered task for instruction-conditioned 4D dynamic scene understanding in fully observed multi-view video, and \textbf{Instruct-4D}, a benchmark with 129.4K question-answer pairs, 64.7K target entities, 851 scenes, and 9 reasoning-oriented query types. To address this setting, we present \textbf{4DTrack}, which casts instruction-conditioned tracking as graph-conditioned worldline inference through an object-centric 4D state graph, metric-guided routing, bidirectional decoding, and kinematic calibration. On Instruct-4D, 4DTrack-Qwen3.5-9B reaches 62.68 $\mathrm{TGA}_{\mathrm{Top1}}$ and surpasses the best adapted VLT baseline by 19.62 points. These results show that worldline-centered modeling improves both target grounding and recovered worldline quality. The project page is available at https://github.com/mikubaka88/4DVLT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the 4DVLT task for instruction-conditioned 4D dynamic scene understanding that grounds language to persistent worldlines binding identity, metric 3D motion, and multi-view projections. It presents the Instruct-4D benchmark (129.4K QA pairs, 64.7K entities, 851 scenes, 9 query types) and the 4DTrack method, which performs graph-conditioned worldline inference via an object-centric 4D state graph, metric-guided routing, bidirectional decoding, and kinematic calibration. On Instruct-4D, 4DTrack-Qwen3.5-9B achieves 62.68 TGA_Top1 and exceeds the best adapted VLT baseline by 19.62 points, with the central claim that worldline-centered modeling improves target grounding and recovered worldline quality.
Significance. If the evaluation details are clarified, the work offers a new task formulation and benchmark that explicitly couples language instructions with metric 4D worldlines, addressing a gap between multimodal reasoning models and fragmented tracking outputs. The reported numerical gain and the open project page (https://github.com/mikubaka88/4DVLT) provide a concrete starting point for reproducible research on persistent 4D scene representations. The contribution is primarily empirical and benchmark-driven rather than theoretical.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: The central claim that worldline-centered modeling yields a 19.62-point TGA_Top1 gain rests on comparison to 'best adapted VLT baseline,' yet no description is given of the adaptation procedure (e.g., how 2D/3D VLT methods are extended to multi-view 4D queries or the 9 reasoning types). This detail is load-bearing for attributing the margin to the proposed 4D state graph rather than implementation differences.
- [Experiments] Experiments section: The reported 62.68 TGA_Top1 and 19.62-point improvement are presented without error bars, standard deviations across runs, or statistical significance tests. Given that the benchmark is newly introduced and the claim concerns improved worldline quality, these statistics are required to establish that the observed margin is robust.
- [Benchmark / Evaluation] Benchmark and Evaluation sections: No cross-dataset results or external validation on existing 4D or tracking benchmarks are reported. The claim that Instruct-4D constitutes a faithful test of instruction-conditioned 4D understanding therefore depends entirely on the internal diversity of the 851 scenes and 129.4K QA pairs, which is not externally corroborated.
minor comments (2)
- [Abstract] The acronym TGA_Top1 is used in the abstract without an explicit definition; a brief expansion or reference to its definition in the main text would improve readability.
- Figure and table captions could more explicitly link visual results to the nine query types to help readers connect qualitative examples to the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments and the recommendation for major revision. We address each of the major comments below, providing clarifications and indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The central claim that worldline-centered modeling yields a 19.62-point TGA_Top1 gain rests on comparison to 'best adapted VLT baseline,' yet no description is given of the adaptation procedure (e.g., how 2D/3D VLT methods are extended to multi-view 4D queries or the 9 reasoning types). This detail is load-bearing for attributing the margin to the proposed 4D state graph rather than implementation differences.
Authors: We agree that more detail on the baseline adaptation is necessary to support the central claim. The original manuscript provided a high-level overview, but we will revise the Experiments section to include a comprehensive description of the adaptation procedure for the VLT baselines, specifying the extensions to multi-view 4D queries and the 9 reasoning types. This revision will help attribute the performance improvements to the worldline-centered modeling. revision: yes
-
Referee: [Experiments] Experiments section: The reported 62.68 TGA_Top1 and 19.62-point improvement are presented without error bars, standard deviations across runs, or statistical significance tests. Given that the benchmark is newly introduced and the claim concerns improved worldline quality, these statistics are required to establish that the observed margin is robust.
Authors: We recognize the value of error bars and statistical tests for establishing robustness, particularly for a new benchmark. Due to the significant computational resources required for training and inference on the large Instruct-4D benchmark, we conducted single-run experiments. In the revised manuscript, we will add error bars where possible by reporting results from multiple random seeds for the inference components and include a discussion of the observed margin's robustness. We will also note this as a limitation. revision: partial
-
Referee: [Benchmark / Evaluation] Benchmark and Evaluation sections: No cross-dataset results or external validation on existing 4D or tracking benchmarks are reported. The claim that Instruct-4D constitutes a faithful test of instruction-conditioned 4D understanding therefore depends entirely on the internal diversity of the 851 scenes and 129.4K QA pairs, which is not externally corroborated.
Authors: We appreciate the suggestion for external validation. However, to the best of our knowledge, there are no existing benchmarks that provide instruction-conditioned queries aligned with persistent 4D worldlines in multi-view settings. Creating such alignments for external datasets would require substantial new annotation efforts outside the scope of this paper. We will revise the Benchmark section to more explicitly justify the design of Instruct-4D based on its scale and diversity (851 scenes, 64.7K entities, 9 query types) and release the full benchmark to facilitate future external validations by the community. revision: no
Circularity Check
No circularity; empirical results on newly introduced benchmark are independent of internal definitions.
full rationale
The manuscript introduces the 4DVLT task, Instruct-4D benchmark (129.4K QA pairs, 851 scenes, 9 query types), and 4DTrack method, then reports empirical TGA_Top1 scores and a 19.62-point gain over baselines. No equations, parameter-fitting steps, or self-citation chains are described that would reduce the performance claims to the inputs by construction. The central claim rests on direct benchmark evaluation rather than any self-definitional or fitted-input reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 4D dynamic scene understanding requires grounding language to a persistent worldline that binds identity, metric 3D motion, and synchronized multi-view 2D projections.
invented entities (2)
-
worldline
no independent evidence
-
4D state graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023
Pith/arXiv arXiv 2023
-
[2]
Flamingo: A visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, ...
-
[3]
Henriques, Andrea Vedaldi, and Philip H
Luca Bertinetto, Jack Valmadre, João F. Henriques, Andrea Vedaldi, and Philip H. S. Torr. Fully- convolutional siamese networks for object tracking. In Gang Hua and Hervé Jégou, editors, Computer Vision ECCV 2016 Workshops , volume 9914, pages 850–865. Springer International Publishing, 2016. ISBN 978-3-319-48880-6 978-3-319-48881-3. doi: 10.1007/978-3-31...
-
[4]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11618–11628. IEEE, 2020. ISBN 978-1-7281-7168-5. doi: 10.1109/CVPR426...
-
[5]
WILDTRACK: A multi-camera HD dataset for dense unscripted pedestrian detection
Tatjana Chavdarova, Pierre Baque, Stephane Bouquet, Andrii Maksai, Cijo Jose, Timur Bagautdinov, Louis Lettry, Pascal Fua, Luc Van Gool, and Francois Fleuret. WILDTRACK: A multi-camera HD dataset for dense unscripted pedestrian detection. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5030–5039. IEEE, 2018. ISBN 978-1-5386-6...
arXiv 2018
-
[6]
Dave Zhenyu Chen, Angel X. Chang, and Matthias NieSSner. ScanRefer: 3D object localization in RGB-D scans using natural language. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan- Michael Frahm, editors, Computer Vision ECCV 2020 , volume 12365, pages 202–221. Springer Inter- national Publishing, 2020. ISBN 978-3-030-58564-8 978-3-030-58565-5. doi: ...
-
[7]
Transformer tracking
Xin Chen, Bin Yan, Jiawen Zhu, Dong Wang, Xiaoyun Yang, and Huchuan Lu. Transformer tracking. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 8122–
2021
-
[8]
Contrastive learning for compact single image dehazing,
IEEE, 2021. ISBN 978-1-6654-4509-2. doi: 10.1109/CVPR46437.2021.00803
-
[9]
Self-Supervised Learning from Images with a Joint- Embedding Predictive Architecture
Xin Chen, Houwen Peng, Dong Wang, Huchuan Lu, and Han Hu. SeqTrack: Sequence to se- quence learning for visual object tracking. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 14572–14581. IEEE, 2023. ISBN 979-8-3503-0129-8. doi: 10.1109/CVPR52729.2023.01400
-
[10]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems , 36:10088–10115, 2023
2023
-
[11]
Contrastive learning for compact single image dehazing,
Qi Feng, Vitaly Ablavsky, Qinxun Bai, and Stan Sclaroff. Siamese natural language tracker: Tracking by natural language descriptions with siamese trackers. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 5847–5856. IEEE, 2021. ISBN 978-1-6654-4509-2. doi: 10.1109/CVPR46437.2021.00579. 14
-
[12]
MemVLT: Vision-language tracking with adaptive memory-based prompts
Xiaokun Feng, Xuchen Li, Shiyu Hu, Dailing Zhang, Meiqi Wu, Jing Zhang, Xiaotang Chen, and Kaiqi Huang. MemVLT: Vision-language tracking with adaptive memory-based prompts. In Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , 2024. doi: 10.52202/079017-0476
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 , 2024
Pith/arXiv arXiv 2024
-
[14]
Xin Gu, Heng Fan, Yan Huang, Tiejian Luo, and Libo Zhang. Context-guided spatio-temporal video grounding. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 1–13, 2024. doi: 10.1109/CVPR52733.2024.01735
-
[15]
Divert more attention to vision-language object tracking
Mingzhe Guo, Zhipeng Zhang, Liping Jing, Haibin Ling, and Heng Fan. Divert more attention to vision-language object tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence , 46 (12):8600–8618, 2024. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2024.3409078
-
[16]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022
2022
-
[17]
GOT-10k: A large high-diversity benchmark for generic object tracking in the wild
Lianghua Huang, Xin Zhao, and Kaiqi Huang. GOT-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Transactions on Pattern Analysis and Machine Intelligence , 43(5): 1562–1577, 2021. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2019.2957464
-
[18]
Yuzhi Huang, Kairun Wen, Rongxin Gao, Dongxuan Liu, Yibin Lou, Jie Wu, Jing Xu, Jian Zhang, Zheng Yang, Yunlong Lin, et al. Thinking in dynamics: How multimodal large language models perceive, track, and reason dynamics in physical 4d world. arXiv preprint arXiv:2603.12746 , 2026
arXiv 2026
-
[19]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Guillaume Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825 , 2023
Pith/arXiv arXiv 2023
-
[20]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. Proceedings of the International Conference on Machine Learning , pages 1–13, 2023
2023
-
[21]
Time3d: End-to-end joint monocular 3d object detection and tracking for autonomous driving
Peixuan Li and Jieyu Jin. Time3d: End-to-end joint monocular 3d object detection and tracking for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3885–3894, 2022
2022
-
[22]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiaohai Li, Bineng Zhong, Qihua Liang, Zhiyi Mo, Jian Nong, and Shuxiang Song. Dynamic updates for language adaptation in visual-language tracking. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 1–10, 2025. doi: 10.1109/CVPR52734.2025.01785
-
[23]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp
Xuchen Li, Xiaokun Feng, Shiyu Hu, Meiqi Wu, Dailing Zhang, Jing Zhang, and Kaiqi Huang. DTLLM-VLT: Diverse text generation for visual language tracking based on LLM. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR W) , pages 7283–7292. IEEE, 2024. ISBN 979-8-3503-6547-4. doi: 10.1109/CVPR W63382.2024.00724
-
[24]
Tracking by natural language specification
Zhenyang Li, Ran Tao, Efstratios Gavves, Cees G M Snoek, and Arnold W M Smeulders. Tracking by natural language specification. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2017. doi: 10.1109/CVPR.2017.777
-
[25]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xinqi Liu, Li Zhou, Zikun Zhou, Jianqiu Chen, and Zhenyu He. MambaVLT: Time-evolving multi- modal state space model for vision-language tracking. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 1–15, 2025. doi: 10.1109/CVPR52734.2025.00816. 15
-
[26]
Unifying visual and vision-language tracking via contrastive learning
Yinchao Ma, Yuyang Tang, Wenfei Yang, Tianzhu Zhang, Jinpeng Zhang, and Mengxue Kang. Unifying visual and vision-language tracking via contrastive learning. Proceedings of the AAAI Conference on Artificial Intelligence , 38(5):4107–4116, 2024. ISSN 2374-3468, 2159-5399. doi: 10.1609/aaai.v38i5.28205
-
[27]
TrackingNet: A large-scale dataset and benchmark for object tracking in the wild
Matthias Müller, Adel Bibi, Silvio Giancola, Salman Alsubaihi, and Bernard Ghanem. TrackingNet: A large-scale dataset and benchmark for object tracking in the wild. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors, Computer Vision ECCV 2018 , volume 11205, pages 310–327. Springer International Publishing, 2018. ISBN 978-...
-
[28]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[29]
Yanyan Shao, Shuting He, Qi Ye, Yuchao Feng, Wenhan Luo, and Jiming Chen. Context-aware integration of language and visual references for natural language tracking. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 19208–19217. IEEE, 2024. ISBN 979-8-3503-5300-6. doi: 10.1109/CVPR52733.2024.01817
-
[30]
Qwen2.5-vl, January 2025
Qwen Team. Qwen2.5-vl, January 2025. URL https://qwenlm.github.io/blog/qwen2.5-vl/
2025
-
[31]
Vptracker: Global vision-language tracking via visual prompt and mllm
Jingchao Wang, Kaiwen Zhou, Zhijian Wu, Kunhua Ji, Dingjiang Huang, and Yefeng Zheng. Vptracker: Global vision-language tracking via visual prompt and mllm. arXiv preprint arXiv:2512.22799 , 2025
Pith/arXiv arXiv 2025
-
[32]
Xiao Wang, Chenglong Li, Rui Yang, Tianzhu Zhang, Jin Tang, and Bin Luo. Describe and attend to track: Learning natural language guided structural representation and visual attention for object tracking. arXiv preprint arXiv:1811.10014 , 2018
Pith/arXiv arXiv 2018
-
[33]
Towards more flexible and accurate object tracking with natural language: Algorithms and benchmark
Xiao Wang, Xiujun Shu, Zhipeng Zhang, Bo Jiang, Yaowei Wang, Yonghong Tian, and Feng Wu. Towards more flexible and accurate object tracking with natural language: Algorithms and benchmark. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 13763– 13773, 2021
2021
-
[34]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hongkai Wei, Yang Yang, Shijie Sun, Mingtao Feng, Xiangyu Song, Qi Lei, Hongli Hu, Rong Wang, Huansheng Song, Naveed Akhtar, and Ajmal Saeed Mian. Mono3DVLT: Monocular-video-based 3D visual language tracking. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1–11, 2025. doi: 10.1109/CVPR52734.2025.01296
-
[35]
Changli Wu, Haodong Wang, Jiayi Ji, Yutian Yao, Chunsai Du, Jihua Kang, Yanwei Fu, and Liujuan Cao. Mvggt: Multimodal visual geometry grounded transformer for multiview 3d referring expression segmentation. arXiv preprint arXiv:2601.06874 , 2026
arXiv 2026
-
[36]
URL https://doi.org/10.1109/ ICCV51070.2023.00008
Dongming Wu, Tiancai Wang, Yuang Zhang, Xiangyu Zhang, and Jianbing Shen. OnlineRefer: A simple online baseline for referring video object segmentation. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , pages 2749–2758. IEEE, 2023. ISBN 979-8-3503-0718-4. doi: 10.1109/ICCV51070.2023.00259
-
[37]
Jiannan Wu, Yi Jiang, Peize Sun, Zehuan Yuan, and Ping Luo. Language as queries for referring video object segmentation. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4964–4974. IEEE, 2022. ISBN 978-1-6654-6946-3. doi: 10.1109/CVPR52688.2022. 00492
-
[38]
Joint feature learning and relation modeling for tracking: A one-stream framework
Botao Ye, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. Joint feature learning and relation modeling for tracking: A one-stream framework. In Shai A vidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors, Computer Vision ECCV 2022 , volume 16 13682, pages 341–357. Springer Nature Switzerland, 2022. ISBN 978-3...
-
[39]
Mllm-4d: To- wards visual-based spatial-temporal intelligence
Xingyilang Yin, Chengzhengxu Li, Jiahao Chang, Chi-Man Pun, and Xiaodong Cun. Mllm-4d: To- wards visual-based spatial-temporal intelligence. arXiv preprint arXiv:2603.00515 , 2026
arXiv 2026
-
[40]
All in one: Exploring unified vision-language tracking with multi-modal alignment
Chunhui Zhang, Xin Sun, Yiqian Yang, Li Liu, Qiong Liu, Xi Zhou, and Yanfeng Wang. All in one: Exploring unified vision-language tracking with multi-modal alignment. In Proceedings of the 31st ACM International Conference on Multimedia , pages 5552–5561. ACM, 2023. ISBN 979-8-4007-0108-
2023
-
[41]
doi: 10.1145/3581783.3611803
-
[42]
One-stream stepwise decreasing for vision-language tracking
Guangtong Zhang, Bineng Zhong, Qihua Liang, Zhiyi Mo, Ning Li, and Shuxiang Song. One-stream stepwise decreasing for vision-language tracking. IEEE Transactions on Circuits and Systems for Video Technology, 34(10):9053–9063, 2024. ISSN 1051-8215, 1558-2205. doi: 10.1109/TCSVT.2024.3395352
-
[43]
Aware distillation for robust vision-language tracking under linguistic sparsity
Guangtong Zhang, Bineng Zhong, Shirui Yang, Yang Wang, and Tian Bai. Aware distillation for robust vision-language tracking under linguistic sparsity. Proceedings of the AAAI Conference on Artificial Intelligence , pages 1–9, 2026. doi: 10.1609/aaai.v40i15.38237
-
[44]
One-stream vision-language memory network for object tracking
Huanlong Zhang, Jingchao Wang, Jianwei Zhang, Tianzhu Zhang, and Bineng Zhong. One-stream vision-language memory network for object tracking. IEEE Transactions on Multimedia, 26:1720–1730,
-
[45]
ISSN 1520-9210, 1941-0077. doi: 10.1109/TMM.2023.3285441
-
[46]
From flatland to space: Teaching vision-language models to perceive and reason in 3d
Jiahui Zhang, Yurui Chen, Yueming Xu, Ze Huang, Jilin Mei, Chunhui Chen, Yanpeng Zhou, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d. Advances in Neural Information Processing Systems , 38, 2026
2026
-
[47]
Uav-track vla: Embodied aerial tracking via vision-language-action models
Qiyao Zhang, Shuhua Zheng, Jianli Sun, Chengxiang Li, Xianke Wu, Zihan Song, Zhiyong Cui, Yisheng Lv, and Yonglin Tian. Uav-track vla: Embodied aerial tracking via vision-language-action models. arXiv preprint arXiv:2604.02241 , 2026
Pith/arXiv arXiv 2026
-
[48]
Mutr3d: A multi-camera tracking framework via 3d-to-2d queries
Tianyuan Zhang, Xuanyao Chen, Yue Wang, Yilun Wang, and Hang Zhao. Mutr3d: A multi-camera tracking framework via 3d-to-2d queries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 4537–4546, 2022
2022
-
[49]
Yu Zhang, Yiming Sun, Mi Zhang, Fan Yu, Shaoxiang Chen, Yang Li, Changbo Wang, Jianke Zhu, and Steven C.H. Hoi. ChatTracker: Enhancing visual tracking via LLM-driven iterative description refinement. IEEE Transactions on Pattern Analysis and Machine Intelligence , pages 1–18, 2026. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2026.3674357
-
[50]
Llava-video: Video instruction tuning with synthetic data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava-video: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 , 2024
Pith/arXiv arXiv 2024
-
[51]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao. Where does it ex- ist: Spatio-temporal video grounding for multi-form sentences. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 10665–10674. IEEE, 2020. ISBN 978-1- 7281-7168-5. doi: 10.1109/CVPR42600.2020.01068
-
[52]
Transformer vision-language tracking via proxy token guided cross-modal fusion
Haojie Zhao, Xiao Wang, Dong Wang, Huchuan Lu, and Xiang Ruan. Transformer vision-language tracking via proxy token guided cross-modal fusion. Pattern Recognition Letters , 168:10–16, 2023. ISSN 01678655. doi: 10.1016/j.patrec.2023.02.023
-
[53]
Effective local and global search for fast long-term tracking
Haojie Zhao, Bin Yan, Dong Wang, Xuesheng Qian, Xiaoyun Yang, and Huchuan Lu. Effective local and global search for fast long-term tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):460–474, 2023. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2022. 3153645. 17
-
[54]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3D LLM: Learning position-aware video represen- tation for 3D scene understanding. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 1–14, 2025. doi: 10.1109/CVPR52734.2025.00841
-
[55]
Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors
Duo Zheng, Yanyang Li, Liwei Wang, et al. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors. Advances in neural information processing systems , 38:20560–20586, 2026
2026
-
[56]
Towards unified token learning for vision-language tracking
Yaozong Zheng, Bineng Zhong, Qihua Liang, Guorong Li, Rongrong Ji, and Xianxian Li. Towards unified token learning for vision-language tracking. IEEE Transactions on Circuits and Systems for Video Technology, pages 1–11, 2024. doi: 10.1109/TCSVT.2023.3301933
-
[57]
Llava-4d: Embedding spatiotemporal prompt into lmms for 4d scene understanding
Hanyu Zhou and Gim Hee Lee. Llava-4d: Embedding spatiotemporal prompt into lmms for 4d scene understanding. In The Fourteenth International Conference on Learning Representations , 2025
2025
-
[58]
Self-Supervised Learning from Images with a Joint- Embedding Predictive Architecture
Li Zhou, Zikun Zhou, Kaige Mao, and Zhenyu He. Joint visual grounding and tracking with natural language specification. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23151–23160. IEEE, 2023. ISBN 979-8-3503-0129-8. doi: 10.1109/CVPR52729.2023. 02217
-
[59]
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. LLaV A-3D: A simple yet effective pathway to empowering LMMs with 3D capabilities. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 1–18, 2025. doi: 10.1109/ICCV51701.2025.00409
-
[60]
Bidir.=off
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. Proceedings of the International Conference on Learning Representations , pages 1–15, 2024. 18 Appendix In the appendix, we provide additional method details including graph-conditioned prompt constru...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.