Generative Relightable Avatars
Pith reviewed 2026-06-26 10:23 UTC · model grok-4.3
The pith
A hybrid pipeline of physics-based rendering and generative refinement produces higher-quality relightable full-body human avatars than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
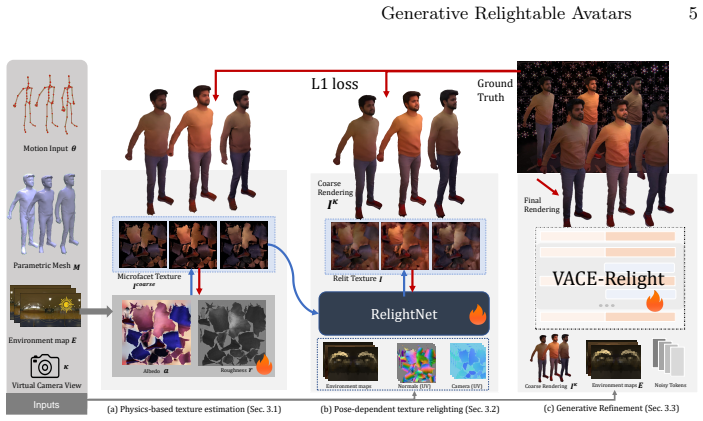
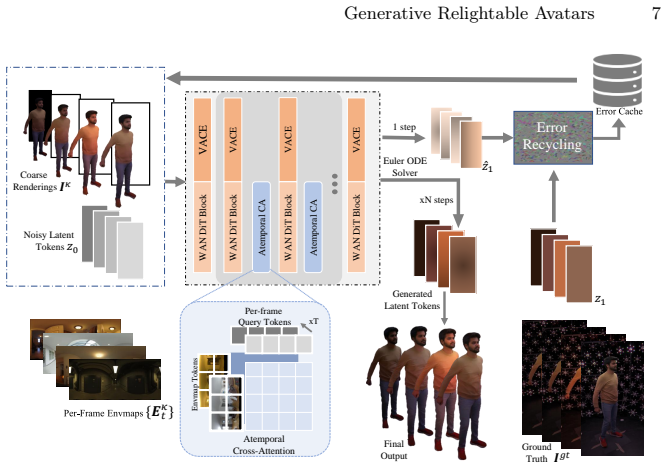
GRA follows a hybrid approach that combines controllable, physics-grounded relighting with probabilistic refinement. Starting from a tracked animated mesh, material parameters are optimized in UV-space and rendered as a coarse relit appearance under a target HDR environment map; a feed-forward model then captures pose-dependent texture dynamics and illumination effects beyond simplified reflectance; finally a fine-tuned video-to-video diffusion model transforms the renderings into temporally coherent high-detail videos while preserving 3D control, using an error-recycling strategy for long sequences.
What carries the argument
Three-stage hybrid pipeline of UV-space material optimization with physics rendering, feed-forward texture refinement, and error-recycling video-to-video diffusion.
Load-bearing premise
The tracked animated mesh is accurate enough and the coarse physics render stable enough that later neural stages can add detail without breaking 3D consistency or lighting control.
What would settle it
Apply the full pipeline to input meshes with known tracking inaccuracies and measure whether output videos lose multi-view consistency or fail to match new environment maps under controlled relighting tests.
Figures











read the original abstract
We present Generative Relightable Avatars (GRA), a person-specific method for photorealistic free-view rendering and environment-map relighting of full-body humans. We postulate that modeling fine-grained appearance details is inherently a one-to-many problem that can benefit from a generative formulation. In contrast to fully regressive relightable avatar methods, GRA follows a hybrid approach that combines controllable, physics-grounded relighting with probabilistic refinement. Starting from a tracked animated mesh, we optimize material parameters in UV-space and render a coarse relit appearance under a target HDR environment map. Next, we refine the textures with a feed-forward model to capture pose-dependent texture dynamics and illumination effects beyond simplified reflectance assumptions. Finally, a fine-tuned video-to-video diffusion model transforms the physically grounded renderings into temporally coherent, high-detail videos while preserving 3D control, with an error-recycling strategy for generating long videos. Experimental evaluations demonstrate our method's improved perceptual quality over prior relightable avatar baselines. Project Page: https://vcai.mpi-inf.mpg.de/projects/GRA/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Generative Relightable Avatars (GRA), a person-specific hybrid method for photorealistic free-view rendering and environment-map relighting of full-body humans. Starting from a tracked animated mesh, it optimizes UV-space material parameters to produce a coarse physics-based render under a target HDR environment map, refines the result with a feed-forward model to capture pose-dependent texture dynamics, and applies a fine-tuned video-to-video diffusion model with an error-recycling strategy to generate temporally coherent high-detail output while preserving 3D control and lighting fidelity. The central claim is improved perceptual quality relative to prior relightable avatar baselines.
Significance. If the hybrid pipeline maintains 3D consistency and lighting control while adding generative detail, the work would offer a practical advance over purely regressive relightable avatar methods by explicitly addressing the one-to-many character of fine appearance. The error-recycling mechanism for long-video generation is a concrete engineering contribution that could see adoption in animation pipelines if shown to scale without drift.
major comments (2)
- [Abstract] Abstract: the assertion of 'improved perceptual quality' is presented without any quantitative metrics, user-study results, ablation tables, or dataset statistics; because this is the central empirical claim, the experiments section must supply these (including error bars and baseline comparisons) for the claim to be evaluable.
- [Method description (implied in abstract)] The weakest assumption identified in the method description—that the input tracked mesh and coarse physics render remain sufficiently stable for the feed-forward and diffusion stages to add detail without introducing 3D-inconsistent artifacts or breaking lighting control—is load-bearing; the manuscript must demonstrate this stability (e.g., via controlled ablation on mesh noise or render fidelity) in §4 or §5.
minor comments (1)
- [Abstract] The manuscript should clarify the exact architecture and training objective of the feed-forward refinement network and the conditioning signals used for the video diffusion model.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and commit to revisions that strengthen the empirical support and validation of key assumptions in the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'improved perceptual quality' is presented without any quantitative metrics, user-study results, ablation tables, or dataset statistics; because this is the central empirical claim, the experiments section must supply these (including error bars and baseline comparisons) for the claim to be evaluable.
Authors: We agree that the central claim of improved perceptual quality requires explicit quantitative and statistical support to be fully evaluable. While the current experiments section provides qualitative comparisons and perceptual evaluations against baselines, we will revise it to include quantitative metrics (LPIPS, FID) with error bars, a user study with statistical analysis, ablation tables, and dataset statistics. These additions will directly support the abstract claim. revision: yes
-
Referee: [Method description (implied in abstract)] The weakest assumption identified in the method description—that the input tracked mesh and coarse physics render remain sufficiently stable for the feed-forward and diffusion stages to add detail without introducing 3D-inconsistent artifacts or breaking lighting control—is load-bearing; the manuscript must demonstrate this stability (e.g., via controlled ablation on mesh noise or render fidelity) in §4 or §5.
Authors: We concur that explicit validation of the stability assumption is necessary. In the revised manuscript we will add a controlled ablation study (in §4 or §5) that introduces controlled mesh noise and render-fidelity variations, then measures resulting 3D consistency and lighting fidelity in the final output. This will quantify the robustness of the hybrid pipeline. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes a hybrid pipeline of UV-space material optimization, coarse physics-based rendering under HDR maps, feed-forward texture refinement for pose-dependent effects, and a fine-tuned video diffusion model with error recycling. No equations, derivations, or self-referential definitions appear in the provided text that reduce any claimed output (e.g., relit appearance or perceptual quality) to fitted inputs by construction. The method assembles standard rendering and generative components without load-bearing self-citations, uniqueness theorems imported from prior author work, or renaming of known results as novel derivations. The central claims rest on the independent engineering integration of these stages rather than tautological reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A tracked animated mesh of the subject is available as input
- domain assumption Standard physically based rendering equations are sufficient for the coarse stage
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Chaturvedi, S., Ren, M., Hold-Geoffroy, Y., Liu, J., Dorsey, J., Shu, Z.: Synthlight: Portrait relighting with diffusion model by learning to re-render synthetic faces. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[2]
arXiv preprint arXiv:2407.08414 (2024)
Chen, Y., Zheng, Z., Li, Z., Xu, C., Liu, Y.: Meshavatar: Learning high-quality triangular human avatars from multi-view videos. arXiv preprint arXiv:2407.08414 (2024)
arXiv 2024
-
[3]
In: Euro- pean Conference on Computer Vision
Chen, Z., Liu, Z.: Relighting4d: Neural relightable human from videos. In: Euro- pean Conference on Computer Vision. pp. 606–623. Springer (2022)
2022
-
[4]
Cook, R.L., Torrance, K.E.: A reflectance model for computer graphics. ACM Trans. Graph.1(1), 7–24 (Jan 1982).https://doi.org/10.1145/357290.357293, https://doi.org/10.1145/357290.357293
-
[5]
Bermano, A., Theobalt, C.: Practilight: Practical light control using foundational diffusion models
Erel, Y., Dabral, R., Golyanik, V., H. Bermano, A., Theobalt, C.: Practilight: Practical light control using foundational diffusion models. ACM Transactions on Graphics (TOG)44(6), 1–11 (2025)
2025
-
[6]
arXiv preprint arXiv:1704.00090 (2017)
Gardner, M.A., Sunkavalli, K., Yumer, E., Shen, X., Gambaretto, E., Gagné, C., Lalonde, J.F.: Learning to predict indoor illumination from a single image. arXiv preprint arXiv:1704.00090 (2017)
Pith/arXiv arXiv 2017
-
[7]
ACM Transactions on Graphics (ToG)40(4), 1–16 (2021)
Habermann, M., Liu, L., Xu, W., Zollhoefer, M., Pons-Moll, G., Theobalt, C.: Real-time deep dynamic characters. ACM Transactions on Graphics (ToG)40(4), 1–16 (2021)
2021
-
[8]
In: European Conference on Computer Vision (ECCV) (2010)
He, K., Sun, J., Tang, X.: Guided image filtering. In: European Conference on Computer Vision (ECCV) (2010)
2010
-
[9]
In: SIGGRAPH Asia 2024 Conference Papers
He, M., Clausen, P., Taşel, A.L., Ma, L., Pilarski, O., Xian, W., Rikker, L., Yu, X., Burgert,R.,Yu,N.,etal.:Diffrelight:Diffusion-basedfacialperformancerelighting. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–12 (2024)
2024
-
[10]
arXiv preprint arXiv:1503.02531 (2015)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
Pith/arXiv arXiv 2015
-
[11]
Hu, E., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Chen, W.: Lora: Low-rank adaptation of large language models (2021)
2021
-
[12]
In: ICCV (2023)
Iqbal, U., Caliskan, A., Nagano, K., Khamis, S., Molchanov, P., Kautz, J.: Rana: Relightable articulated neural avatars. In: ICCV (2023)
2023
-
[13]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Jiang, Z., Wang, S., Tang, S.: Dnf-avatar: Distilling neural fields for real-time an- imatable avatar relighting. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 6383–6394 (2025)
2025
-
[14]
arXiv preprint arXiv:2503.07598 (2025)
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. arXiv preprint arXiv:2503.07598 (2025)
Pith/arXiv arXiv 2025
-
[15]
arXiv preprint arXiv:2406.07520 (2024)
Jin, H., Li, Y., Luan, F., Xiangli, Y., Bi, S., Zhang, K., Xu, Z., Sun, J., Snavely, N.: Neural gaffer: Relighting any object via diffusion. arXiv preprint arXiv:2406.07520 (2024)
arXiv 2024
-
[16]
Kajiya,J.T.:Therenderingequation.In:Proceedingsofthe13thannualconference on Computer graphics and interactive techniques. pp. 143–150 (1986)
1986
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, H., Jang, M., Yoon, W., Lee, J., Na, D., Woo, S.: Switchlight: Co-design of physics-driven architecture and pre-training framework for human portrait re- lighting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25096–25106 (2024)
2024
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lei, C., Ren, X., Zhang, Z., Chen, Q.: Blind video deflickering by neural filtering with a flawed atlas. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10439–10448 (2023) 16 K.M. Singh et al
2023
-
[19]
arXiv preprint arXiv:2510.09212 (2025)
Li, W., Pan, W., Luan, P.C., Gao, Y., Alahi, A.: Stable video infinity: Infinite- length video generation with error recycling. arXiv preprint arXiv:2510.09212 (2025)
arXiv 2025
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Liang, R., Gojcic, Z., Ling, H., Munkberg, J., Hasselgren, J., Lin, C.H., Gao, J., Keller, A., Vijaykumar, N., Fidler, S., Wang, Z.: Diffusionrenderer: Neural in- verse and forward rendering with video diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[21]
arXiv preprint arXiv:2210.02747 (2022)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
Pith/arXiv arXiv 2022
-
[22]
arXiv preprint arXiv:2407.16124 (2024)
Liu, J., Qu, Y., Yan, Q., Zeng, X., Wang, L., Liao, R.: Fr\’echet video motion distance: A metric for evaluating motion consistency in videos. arXiv preprint arXiv:2407.16124 (2024)
arXiv 2024
-
[23]
In: European Conference on Computer Vision (ECCV) (2024)
Luvizon, D., Golyanik, V., Kortylewski, A., Habermann, M., Theobalt, C.: Re- lightable neural actor with intrinsic decomposition and pose control. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Mei, Y., He, M., Ma, L., Philip, J., Xian, W., George, D.M., Yu, X., Dedic, G., Taşel, A.L., Yu, N., et al.: Lux post facto: Learning portrait performance relight- ing with conditional video diffusion and a hybrid dataset. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5510–5522 (2025)
2025
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mei, Y., Zeng, Y., Zhang, H., Shu, Z., Zhang, X., Bi, S., Zhang, J., Jung, H., Patel, V.M.: Holo-relighting: Controllable volumetric portrait relighting from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4263–4273 (2024)
2024
-
[26]
ACM Trans
Pandey, R., Orts-Escolano, S., Legendre, C., Haene, C., Bouaziz, S., Rhemann, C., Debevec, P.E., Fanello, S.R.: Total relighting: learning to relight portraits for background replacement. ACM Trans. Graph.40(4), 43–1 (2021)
2021
-
[27]
Acm transactions on graphics (tog)29(4), 1–13 (2010)
Parker, S.G., Bigler, J., Dietrich, A., Friedrich, H., Hoberock, J., Luebke, D., McAl- lister, D., McGuire, M., Morley, K., Robison, A., et al.: Optix: a general purpose ray tracing engine. Acm transactions on graphics (tog)29(4), 1–13 (2010)
2010
-
[28]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (2024)
Ren, M., Xiong, W., Yoon, J.S., Shu, Z., Zhang, J., Jung, H., Gerig, G., Zhang, H.: Relightful harmonization: Lighting-aware portrait background replacement. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (2024)
2024
-
[29]
arXiv preprint arXiv:2201.02610 (2022)
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. arXiv preprint arXiv:2201.02610 (2022)
arXiv 2022
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sanyal, S., Bolkart, T., Feng, H., Black, M.J.: Learning to regress 3d face shape and expression from an image without 3d supervision. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7763–7772 (2019)
2019
-
[31]
arXiv preprint arXiv:2512.00255 (2025)
Singh, K.M., Chen, J., Golyanik, V., Garbin, S.J., Beeler, T., Dabral, R., Habermann, M., Theobalt, C.: Relightable holoported characters: Capturing and relighting dynamic human performance from sparse views. arXiv preprint arXiv:2512.00255 (2025)
arXiv 2025
-
[32]
(2025),https://github.com/soravux/skylibs
Skylibs: Tools used for ldr/hdr environment map (ibl) handling, conversion and i/o. (2025),https://github.com/soravux/skylibs
2025
-
[33]
Team, T.H.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation (2025)
2025
-
[34]
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Generative Relightable Avatars 17 Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin,...
Pith/arXiv arXiv 2025
-
[35]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR) (2025)
Wang, J., Liu, J., Sun, X., Singh, K.K., Shu, Z., Zhang, H., Yang, J., Zhao, N., Wang, T.Y., Chen, S.S., Neumann, U., Yoon, J.S.: Comprehensive relighting: Gen- eralizable and consistent monocular human relighting and harmonization. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR) (2025)
2025
-
[36]
arXiv preprint arXiv:2509.23769 (2025)
Wang, L., Jin, S., Cui, R., Dahl, A.B., Frisvad, J.R., Bigdeli, S.: Relumix: Ex- tending image relighting to video via video diffusion models. arXiv preprint arXiv:2509.23769 (2025)
arXiv 2025
-
[37]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Wang, S., Antic, B., Geiger, A., Tang, S.: Intrinsicavatar: Physically based inverse rendering of dynamic humans from monocular videos via explicit ray tracing. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 1877–1888 (2024)
2024
-
[38]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Wang, S., Simon, T., Santesteban, I., Bagautdinov, T., Li, J., Agrawal, V., Prada, F., Yu, S.I., Nalbone, P., Gramlich, M., et al.: Relightable full-body gaussian codec avatars. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–12 (2025)
2025
-
[39]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Wang, Y., Han, Q., Habermann, M., Daniilidis, K., Theobalt, C., Liu, L.: Neus2: Fast learning of neural implicit surfaces for multi-view reconstruction. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 3295– 3306 (2023)
2023
-
[40]
IEEE transactions on image processing13(4), 600–612 (2004)
Wang, Z.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing13(4), 600–612 (2004)
2004
-
[41]
Tech report (2025)
Xiang, J., Chen, X., Xu, S., Wang, R., Lv, Z., Deng, Y., Zhu, H., Dong, Y., Zhao, H., Yuan, N.J., Yang, J.: Native and compact structured latents for 3d generation. Tech report (2025)
2025
-
[42]
arXiv preprint arXiv:2412.01506 (2024)
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024)
Pith/arXiv arXiv 2024
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiao, J., Zhang, Q., Xu, Z., Zheng, W.S.: Neca: Neural customizable human avatar. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20091–20101 (2024)
2024
-
[44]
ACM Transactions on Graphics43(5), 1–22 (2024)
Xie, R., Huang, K., Cho, I.Y., Yang, S., Chen, W., Bao, H., Zheng, W., Li, R., Huo, Y.: Ren human: Learning relightable neural implicit surfaces for animatable human rendering. ACM Transactions on Graphics43(5), 1–22 (2024)
2024
-
[45]
In: CVPR (2024)
Xu, Z., Peng, S., Geng, C., Mou, L., Yan, Z., Sun, J., Bao, H., Zhou, X.: Relightable and animatable neural avatar from sparse-view video. In: CVPR (2024)
2024
-
[46]
In: CVPR (2026)
Yang, P., Zhou, S., Hao, K., Tao, Q.: MatAnyone 2: Scaling video matting via a learned quality evaluator. In: CVPR (2026)
2026
-
[47]
ACM Transactions on Graphics (TOG) 43(6), 1–13 (2024)
Yoon, J.S., Shu, Z., Ren, M., Zhang, C., Hold-Geoffroy, Y., Singh, K.k., Zhang, H.: Generative portrait shadow removal. ACM Transactions on Graphics (TOG) 43(6), 1–13 (2024)
2024
-
[48]
Singh et al
Zeng, Z., Deschaintre, V., Georgiev, I., Hold-Geoffroy, Y., Hu, Y., Luan, F., Yan, L.Q., Hašan, M.: Rgb-x: Image decomposition and synthesis using material- and 18 K.M. Singh et al. lighting-aware diffusion models. In: ACM SIGGRAPH 2024 Conference Papers (2024)
2024
-
[49]
In: International Conference on Learning Representations (ICLR) (2025)
Zhang, L., Rao, A., Agrawala, M.: Scaling in-the-wild training for diffusion-based illumination harmonization and editing by imposing consistent light transport. In: International Conference on Learning Representations (ICLR) (2025)
2025
-
[50]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[51]
Zhao, Y., Wu, C., Huang, B., Zhi, Y., Zhao, C., Wang, J., Gao, S.: Surfel-based gaussian inverse rendering for fast and relightable dynamic human reconstruction from monocular video. arXiv preprint arXiv:2407.15212 (2024) Generative Relightable Avatars 19 A Overview This supplementary document provides additional details and analyses to com- plement the m...
arXiv 2024
-
[52]
C" denotes convolution layer,
Table 3 illustrates the concrete architecture ofRelightNet. Table 3:Illustration of theRelightNetarchitecture. In the operation column, "C" denotes convolution layer, "SA" denotes self-attention layer, "CA" denotes cross- attention layer, "DS" and "US" denotes down-sampling and up-sampling layer with scale factors equal to 2. Number of Feature Channels Op...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.