PHOEBI: An Open-World Benchmark for Bacterial Identification in Phase-Contrast Microscopy
Pith reviewed 2026-06-26 09:09 UTC · model grok-4.3
The pith
Gradient-trained per-image aggregators for bacterial identification drop 0.39-0.57 F1 on unseen species combinations while anchor-based decoders do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the leave-combinations-out split, every gradient-trained per-image aggregator drops between 0.39 and 0.57 F1 relative to its in-distribution performance. This drop is attributed to the aggregator architecture itself rather than the visual representation, because linear probes of thirteen different encoders over the same features vary by only about six percentage points of F1. Three anchor-based decoders are proposed that capture per-species presence geometrically over a shared frozen tile-feature pool; these decoders score higher on held-out combinations than on in-distribution validation.
What carries the argument
Anchor-based decoders that capture per-species presence geometrically over a shared frozen tile-feature pool
If this is right
- The performance gap between in-distribution and held-out mixtures is driven primarily by decoder design rather than by the choice of visual encoder.
- A single frozen feature pool extracted from any of several standard encoders can support effective multi-label prediction for bacterial mixtures.
- Models can be trained on catalogued mixtures and still identify species in practical samples that contain previously unseen combinations.
- Geometric modeling of species presence allows higher accuracy on novel polymicrobial samples than on the mixtures seen during training.
Where Pith is reading between the lines
- The same LCO-style protocol could be applied to other multi-label microscopy tasks where the set of possible co-occurring objects is open.
- Clinical or environmental pipelines could adopt the frozen-pool plus anchor-decoder pattern to reduce retraining costs when new species appear.
- The six-point spread across encoders suggests that further gains are more likely to come from decoder innovation than from larger pretraining corpora.
- If the geometric anchoring mechanism generalizes, it may reduce the need for end-to-end fine-tuning in other open-set recognition settings.
Load-bearing premise
The observed F1 drop on held-out combinations is caused by the aggregator architecture rather than by unmeasured differences in data distribution, label noise, or species visual similarity.
What would settle it
An experiment in which the anchor-based decoders also exhibit a comparable F1 drop on the LCO split, or in which the six-point linear-probe spread widens substantially when distribution shifts are controlled.
Figures









read the original abstract
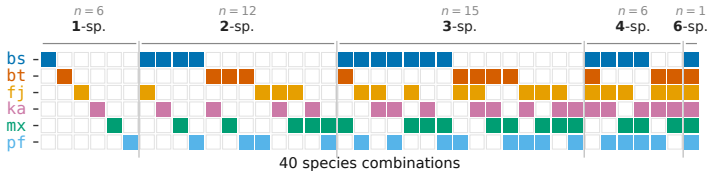
Optical microscopy enables rapid, label-free imaging of live bacteria and is the standard instrument for species identification across clinical, environmental, and industrial microbiology. Yet field samples are routinely polymicrobial and may contain organisms that were never seen during system training, and no computer-vision benchmark tests multi-label species identification from phase-contrast microscopy (PCM) of such mixtures. We introduce Phase-contrast Optical bEnchmark for Bacterial Identification ($\textbf{PHOEBI}$), a wet-lab-prepared dataset of $120{,}000$ PCM images covering $40$ combinations of six rod-shaped species, paired with a leave-combinations-out (LCO) evaluation protocol that holds out entire species combinations to mirror the practical scenario of a model trained on catalogued mixtures that must generalise to unseen ones. On LCO, every gradient-trained per-image aggregator we test drops $0.39$ to $0.57$ F1 from the in-distribution to the held-out split, a systematic open-world recognition failure in the aggregator, not the visual representation. A linear probe of thirteen different encoders over the same features spreads only about six percentage points of F1 across general-purpose and biomedical pretraining objectives, confirming the representation is sound. We propose three lightweight $\textit{anchor-based}$ decoders that capture per-species presence geometrically over a shared frozen tile-feature pool, scoring $\textit{higher}$ on held-out combinations than on in-distribution validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PHOEBI, a dataset of 120,000 phase-contrast microscopy images spanning 40 combinations of six rod-shaped bacterial species, together with a leave-combinations-out (LCO) protocol that holds out entire species mixtures. It reports that every tested gradient-trained per-image aggregator drops 0.39–0.57 F1 on LCO splits relative to in-distribution performance, attributes the failure to aggregator architecture rather than the visual representation on the basis of a linear-probe spread of ~6 F1 points across 13 encoders, and proposes three lightweight anchor-based decoders that achieve higher F1 on held-out combinations than on in-distribution validation.
Significance. If the attribution of the performance drop to aggregator choice is secured, the work supplies a reproducible open-world benchmark and evaluation protocol for multi-label bacterial identification in PCM that directly mirrors clinical and environmental use cases. The empirical demonstration of systematic aggregator failure, the small linear-probe variation, and the proposed geometric decoders that improve on LCO constitute concrete, falsifiable contributions that could become a reference point for testing generalization in microbiology computer vision.
major comments (1)
- [Abstract] Abstract: the claim that the representation is sound because 'a linear probe of thirteen different encoders over the same features spreads only about six percentage points of F1' does not specify whether these probes were run on the LCO held-out splits. If the probes are reported only on in-distribution data, the 6-point spread demonstrates only that the encoders are comparable on seen combinations and does not test whether the frozen tile features remain discriminative for unseen species mixtures, leaving the isolation of failure to the aggregator unsupported.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying an ambiguity in the abstract. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the representation is sound because 'a linear probe of thirteen different encoders over the same features spreads only about six percentage points of F1' does not specify whether these probes were run on the LCO held-out splits. If the probes are reported only on in-distribution data, the 6-point spread demonstrates only that the encoders are comparable on seen combinations and does not test whether the frozen tile features remain discriminative for unseen species mixtures, leaving the isolation of failure to the aggregator unsupported.
Authors: We agree that the abstract does not specify the evaluation split. The linear probes were performed on the in-distribution validation set. This supports encoder comparability on seen combinations but does not directly demonstrate that the frozen tile features remain discriminative under the LCO protocol. To strengthen the attribution of failure to the aggregator, we will revise the abstract to qualify the claim and will add linear-probe results computed on the LCO held-out splits (both in the main text and supplementary material) in the revised manuscript. revision: yes
Circularity Check
No circularity; empirical benchmark comparisons are self-contained
full rationale
The paper introduces a new dataset and LCO protocol, then reports direct performance numbers for gradient-trained aggregators versus linear probes and anchor-based decoders on the same held-out splits. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation of the central claim. The isolation of failure to aggregator architecture rests on observed F1 differences rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.3389/frai.2025.1632344. José M. Bioucas-Dias, Antonio Plaza, Nicolas Dobigeon, Mario Parente, Qian Du, Paul Gader, and Jocelyn Chanussot. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 5(2):354–379,
-
[2]
doi: 10.1038/nmeth.4397. Richard J. Chen, Tong Ding, Ming Y . Lu, Drew F. K. Williamson, Guillaume Jaume, Andrew H. Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, et al. Towards a general-purpose foundation model for computational pathology.Nature Medicine,
-
[3]
Overview of PlantCLEF 2024: Multi-species plant identification in vegetation plot images
Hervé Goëau, Vincent Espitalier, Pierre Bonnet, and Alexis Joly. Overview of PlantCLEF 2024: Multi-species plant identification in vegetation plot images. InWorking Notes of CLEF 2024 – Conference and Labs of the Evaluation Forum,
2024
-
[4]
Overview of LifeCLEF 2024: Challenges on species distribution prediction and identification
Alexis Joly, Lukáš Picek, Stefan Kahl, Hervé Goëau, Vincent Espitalier, Christophe Botella, et al. Overview of LifeCLEF 2024: Challenges on species distribution prediction and identification. InExperimental IR Meets Multilinguality, Multimodality, and Interaction (CLEF 2024), Lecture Notes in Computer Science. Springer,
2024
-
[5]
Query2label: A simple transformer way to multi-label classification.arXiv preprint arXiv:2107.10834,
Shilong Liu, Tianhe Ren, Jiemin Chen, Zhaoyang Zeng, Hao Zhang, Feng Li, Hongyang Li, Jun Huang, Hang Su, Jun Zhu, and Lei Zhang. Query2label: A simple transformer way to multi-label classification.arXiv preprint arXiv:2107.10834,
-
[6]
Overview of FungiCLEF 2024: Revisiting fungi species recognition beyond 0–1 cost
Lukáš Picek, Milan Šulc, and Jiˇrí Matas. Overview of FungiCLEF 2024: Revisiting fungi species recognition beyond 0–1 cost. InWorking Notes of CLEF 2024 – Conference and Labs of the Evaluation Forum,
2024
-
[7]
Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisserman
doi: 10.1109/ITC-CSCC.2019.8793320. Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisserman. Generalized category discovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7492–7501,
-
[8]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, Cliff Wong, Matthew P. Lungren, Tristan Naumann, and Hoifung Poon. BiomedCLIP: A multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
12 A Front-End and Decoder Implementation Details A.1 Tile pipeline For an image I: Ω→R 3 we estimate a per-channel backgroundBc =G σ ∗I c via a large-σ Gaussian and form ˜Ic =I c/(Bc/ ¯B), picking σ= 64 px so cellular structure (5 to 20 px) is preserved while the lamp gradient (hundreds of px) is captured. We sample T= 16 tiles of side s= 224 per image (...
2016
-
[10]
Cache reuse across folds keeps the cost of a full sweep at one feature-extraction pass; the per-fold inner loop is sub-second on a single GPU. Algorithm 1PHOEBI leave-one-out cross-validation (LOOCV) open-set + discovery sweep Require:Train/val/test splits; tile config;Kspecies 1:Extract tile features on train/val/test once (cache-reuse across folds) 2:fo...
-
[11]
0.0 0.5 1.0Precision bs base=0.42 A (0.56) B (0.50) bt base=0.33 A (0.32) B (0.35) fj base=0.47 A (0.47) B (0.60) 0.0 0.2 0.4 0.6 0.8 1.0 Recall 0.0 0.5 1.0Precision ka base=0.47 A (0.82) B (0.91) 0.0 0.2 0.4 0.6 0.8 1.0 Recall mx base=0.47 A (0.55) B (0.41) 0.0 0.2 0.4 0.6 0.8 1.0 Recall pf base=0.45 A (0.49) B (0.47) A — simplex unmix B — proto match cl...
2022
-
[12]
0.4 0.5 0.6 0.7 mean tile residual ‖r(x)‖ 0.0 2.5 5.0density held-out bs 0.4 0.5 0.6 0.7 mean tile residual ‖r(x)‖ 0.0 2.5 5.0 held-out bt 0.4 0.5 0.6 0.7 mean tile residual ‖r(x)‖ 0.0 2.5 5.0 held-out fj 0.55 0.60 0.65 0.70 mean tile residual ‖r(x)‖ 0 10density held-out ka 0.4 0.5 0.6 0.7 mean tile residual ‖r(x)‖ 0.0 2.5 5.0 held-out mx 0.4 0.5 0.6 0.7 ...
-
[13]
The decoder-level evidence directly mirrors the cross-method LCO evidence and rules out an alternative explanation in which the gap-closing is a feature of frozen-backbone training in general; only the geometrically-anchored decoders close the gap. Boundary-tile robustness check for H.A direct probe of whether H breaks at the field-of-view boundary: re-ru...
2021
-
[14]
makes this ordering a property of inter-species geometry on phase-contrast bacteria rather than of DINOV2. Exact-match accuracy collapses to <0.10 on quadruples and above for all decoders, a structural artifact of independent per-class thresholding (at F1 = 0.80 per class, six-class exact match is bounded by 0.806 ≈0.26 ); exact match is therefore a side ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.