TEXEDO : Test Time Scaling for Controller-aware Language-conditioned Humanoid Motion Generation
Pith reviewed 2026-06-26 08:49 UTC · model grok-4.3
The pith
Test-time selection using a feasibility verifier and semantic scorer produces more executable text-to-humanoid motions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
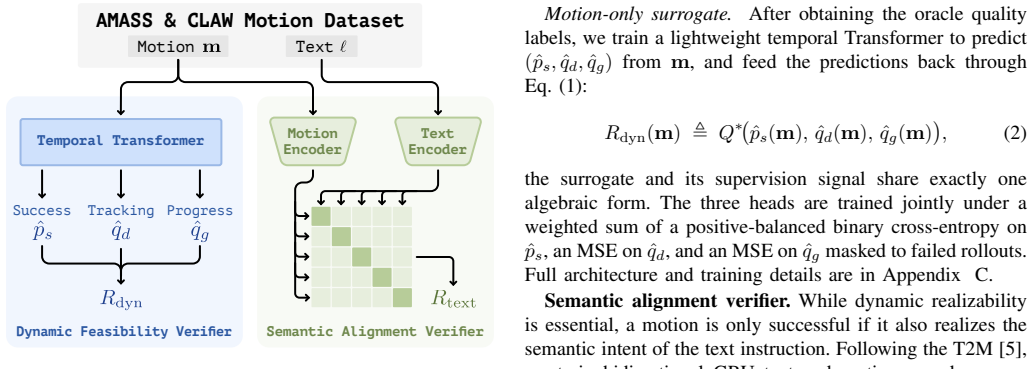
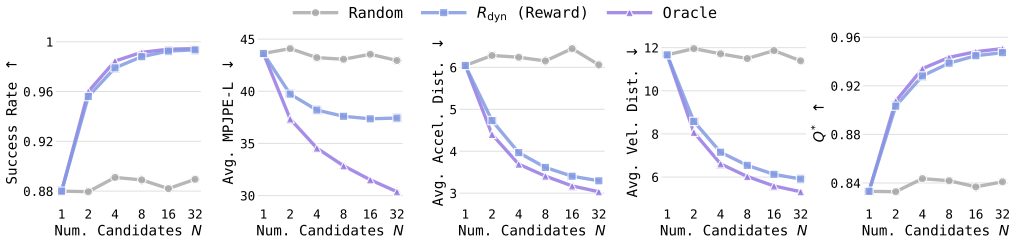
TEXEDO samples multiple motions from a fixed pretrained text-conditioned generator, applies a dynamic feasibility verifier distilled from whole-body tracking rollouts as a hard filter, and then selects the motion with highest semantic alignment inside the feasible set. Large-scale simulation and real-world tests on a Unitree G1 show consistent gains in both tracking fidelity and prompt adherence.
What carries the argument
TEXEDO test-time scaling pipeline that treats dynamic feasibility as a hard constraint and semantic alignment as the selection objective.
If this is right
- Motions that pass the verifier are more likely to succeed under the actual whole-body controller without violating balance or actuation limits.
- Semantic alignment can be optimized only among motions already known to be feasible, avoiding the trade-off between meaning and executability.
- The same selection procedure works for any pretrained generator, so gains accrue without collecting new robot-specific training data.
- Real-robot experiments confirm that the simulated verifier transfers to hardware, closing the sim-to-real gap for language-conditioned tasks.
Where Pith is reading between the lines
- The framework could be applied to other robot morphologies by retraining only the feasibility verifier on that platform's tracking data.
- If the verifier is cheap to evaluate, further scaling the number of candidates at test time may yield additional gains similar to test-time compute in language models.
- Combining the verifier with online adaptation of the generator weights could produce a hybrid system that improves both at inference and through continued learning.
Load-bearing premise
The dynamic feasibility verifier distilled from whole-body tracking rollouts accurately predicts whether a generated motion will be physically executable by the robot's controller.
What would settle it
Deploy the motions selected by TEXEDO on the physical Unitree G1 and measure whether tracking error and success rate remain statistically indistinguishable from motions chosen by random sampling or by the original generator alone.
Figures




read the original abstract
Text-conditioned motion generation is a promising interface for programming humanoid robots, yet current generators are often trained on human motion datasets retargeted to robot morphologies. Although such data provides rich semantic and kinematic priors, it fails to capture the nuances of whole-body tracking controllers, including balance, contact dynamics, actuation limits, and controller-specific failure modes. As a result, generated motions can be semantically plausible but difficult or impossible for the robot to execute. We introduce TEXEDO, a test-time scaling framework for humanoid motion generation that improves motion quality without requiring a stronger underlying generator. Given a text prompt, TEXEDO samples multiple candidate motions from a pretrained text-conditioned generator and selects the best motion that is both executable and task-aligned. The reward model combines a dynamic feasibility verifier, distilled from whole-body tracking rollouts to predict physical executability, with a semantic alignment verifier that measures text-motion alignment in a learned co-embedding space. Our pipeline treats dynamic feasibility as a hard constraint and semantic alignment as the selection objective within the feasible set. Through large-scale simulation studies and real-world deployment on a Unitree G1 humanoid robot, we show that TEXEDO consistently improves both tracking fidelity and text alignment. These results demonstrate that grounded verification is an effective path toward deployable language-guided humanoid motion generation. Project website: https://jianuocao.github.io/TEXEDO/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TEXEDO, a test-time scaling framework for text-conditioned humanoid motion generation. It samples multiple candidate motions from a pretrained generator and selects the best one by treating dynamic feasibility (via a verifier distilled from whole-body tracking rollouts) as a hard constraint and semantic alignment (in a learned co-embedding space) as the selection objective within the feasible set. The method is claimed to improve tracking fidelity and text alignment, with supporting evidence from large-scale simulation studies and real-world deployment on a Unitree G1 robot.
Significance. If the central assumption holds, the approach provides a practical, training-free way to adapt existing motion generators to robot-specific controller constraints such as balance and contact dynamics. The real-robot evaluation on the Unitree G1 is a positive aspect for deployability claims. However, the absence of any quantitative metrics, baselines, or experimental details in the abstract prevents assessment of effect sizes or whether the gains are meaningful relative to prior work.
major comments (2)
- [Abstract] Abstract: the central claim of consistent improvements in tracking fidelity and text alignment rests on the dynamic feasibility verifier (distilled only from whole-body tracking rollouts) correctly classifying executability for motions sampled from the text-conditioned generator. No evidence is provided that generator outputs lie inside the rollout distribution; systematic misclassification would directly invalidate the selection step and the reported gains.
- [Abstract] Abstract: the manuscript states that 'large-scale simulation studies and real-world deployment' demonstrate the improvements, yet supplies no metrics, baselines, success rates, or statistical details. This omission makes the soundness of the empirical claims impossible to evaluate from the provided text.
minor comments (1)
- [Abstract] The abstract refers to a 'reward model' combining the two verifiers, but the selection procedure is described only at a high level; a precise statement of how the hard constraint is enforced (e.g., filtering before ranking or joint optimization) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the abstract requires strengthening to better support the claims with quantitative details and will revise it accordingly. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent improvements in tracking fidelity and text alignment rests on the dynamic feasibility verifier (distilled only from whole-body tracking rollouts) correctly classifying executability for motions sampled from the text-conditioned generator. No evidence is provided that generator outputs lie inside the rollout distribution; systematic misclassification would directly invalidate the selection step and the reported gains.
Authors: We acknowledge this is a substantive concern: the abstract does not explicitly demonstrate that motions from the text-conditioned generator lie within the distribution of whole-body tracking rollouts used to distill the verifier. The full manuscript reports that TEXEDO yields measurable gains in tracking fidelity and text alignment across simulation and real-robot experiments, which provides indirect support for the verifier's utility on generator outputs. However, we agree that direct evidence of distribution overlap or out-of-distribution robustness would strengthen the argument. In revision we will update the abstract to reference the empirical validation and add a short discussion or ablation on verifier generalization. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states that 'large-scale simulation studies and real-world deployment' demonstrate the improvements, yet supplies no metrics, baselines, success rates, or statistical details. This omission makes the soundness of the empirical claims impossible to evaluate from the provided text.
Authors: The referee is correct that the current abstract is too high-level and lacks the quantitative details needed to assess effect sizes. The full paper contains these results in the experiments section, including simulation metrics on tracking error and success rates as well as real-world deployment outcomes on the Unitree G1. We will revise the abstract to incorporate key numbers, baseline comparisons, and statistical details so that the claims can be evaluated directly from the abstract text. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a test-time selection pipeline that samples from a pretrained generator and filters using a verifier distilled from separate whole-body tracking rollouts. No equations, self-definitional relations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The verifier training distribution and generator sampling are treated as distinct inputs with an explicit (if unverified) assumption of coverage; this does not reduce the claimed improvement to a tautology or self-referential fit by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BONES-SEED: Skeletal everyday em- bodiment dataset, 2026
Bones Studio. BONES-SEED: Skeletal everyday em- bodiment dataset, 2026. URL https://huggingface.co/ datasets/bones-studio/seed
2026
-
[2]
Jianuo Cao, Yuxin Chen, and Masayoshi Tomizuka. Claw: Composable language-annotated whole-body mo- tion generation.arXiv preprint arXiv:2604.11251, 2026
Pith/arXiv arXiv 2026
-
[3]
Yuxin Chen, Jianglan Wei, Chenfeng Xu, Boyi Li, Masayoshi Tomizuka, Andrea Bajcsy, and Ran Tian. Reimagination with test-time observation interven- tions: Distractor-robust world model predictions for visual model predictive control.arXiv preprint arXiv:2506.16565, 2025
arXiv 2025
-
[4]
Scaling instruction-finetuned language models.Journal of Ma- chine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Ma- chine Learning Research, 25(70):1–53, 2024
2024
-
[5]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5152–5161, 2022
2022
-
[6]
Momask: Generative masked modeling of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked modeling of 3d human motions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2024
1900
-
[7]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[8]
Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
2023
-
[9]
Jacky Kwok, Christopher Agia, Rohan Sinha, Matt Fout- ter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models.arXiv preprint arXiv:2506.17811, 2025
arXiv 2025
-
[10]
Qiayuan Liao, Takara E Truong, Xiaoyu Huang, Yu- man Gao, Guy Tevet, Koushil Sreenath, and C Karen Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[11]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational Conference on Learn- ing Representations, volume 2024, pages 39578–39601, 2024
2024
-
[12]
Perpetual humanoid control for real-time simulated avatars
Zhengyi Luo, Jinkun Cao, Kris Kitani, Weipeng Xu, et al. Perpetual humanoid control for real-time simulated avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10895–10904, 2023
2023
-
[13]
Zhengyi Luo, Ye Yuan, Tingwu Wang, Chenran Li, Sirui Chen, Fernando Castaneda, Zi-Ang Cao, Jiefeng Li, David Minor, Qingwei Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body con- trol.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[14]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
2019
-
[15]
Finite scalar quantization: Vq-vae made simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple. InInternational Conference on Learn- ing Representations, volume 2024, pages 51772–51783, 2024
2024
-
[16]
Learning to reason with LLMs
OpenAI. Learning to reason with LLMs. OpenAI Blog, 2024. https://openai.com/index/ learning-to-reason-with-llms/
2024
-
[17]
Amp: Adversarial motion priors for stylized physics-based character control.ACM Transac- tions on Graphics (ToG), 40(4):1–20, 2021
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transac- tions on Graphics (ToG), 40(4):1–20, 2021
2021
-
[18]
Kimodo: Scaling controllable human motion generation.arXiv preprint arXiv:2603.15546, 2026
Davis Rempe, Mathis Petrovich, Ye Yuan, Haotian Zhang, Xue Bin Peng, Yifeng Jiang, Tingwu Wang, Umar Iqbal, David Minor, Michael de Ruyter, et al. Kimodo: Scaling controllable human motion generation.arXiv preprint arXiv:2603.15546, 2026
arXiv 2026
-
[19]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Ku- mar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[20]
Zelin Tao, Zeran Su, Peiran Liu, Jingkai Sun, Wenqiang Que, Jiahao Ma, Jialin Yu, Jiahang Cao, Pihai Sun, Hao Liang, et al. Heracles: Bridging precise tracking and generative synthesis for general humanoid control.arXiv preprint arXiv:2603.27756, 2026
arXiv 2026
-
[21]
Human motion diffusion model.arXiv preprint arXiv:2209.14916, 2022
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model.arXiv preprint arXiv:2209.14916, 2022
Pith/arXiv arXiv 2022
-
[22]
Realign: text-to- motion generation via step-aware reward-guided align- ment
Wanjiang Weng, Xiaofeng Tan, Junbo Wang, Guo-Sen Xie, Pan Zhou, and Hongsong Wang. Realign: text-to- motion generation via step-aware reward-guided align- ment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 10621–10629, 2026
2026
-
[23]
Yilin Wu, Ran Tian, Gokul Swamy, and Andrea Ba- jcsy. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment.arXiv preprint arXiv:2502.01828, 2025
arXiv 2025
-
[24]
Generating human motion from textual descrip- tions with discrete representations
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Yong Zhang, Hongwei Zhao, Hongtao Lu, Xi Shen, and Ying Shan. Generating human motion from textual descrip- tions with discrete representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14730–14740, 2023
2023
-
[25]
Mo- tiondiffuse: Text-driven human motion generation with diffusion model.IEEE transactions on pattern analysis and machine intelligence, 46(6):4115–4128, 2024
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Mo- tiondiffuse: Text-driven human motion generation with diffusion model.IEEE transactions on pattern analysis and machine intelligence, 46(6):4115–4128, 2024
2024
-
[26]
Zewei Zhang, Kehan Wen, Michael Xu, Junzhe He, Chenhao Li, Takahiro Miki, Clemens Schwarke, Chong Zhang, Xue Bin Peng, and Marco Hutter. Learning whole-body humanoid locomotion via motion generation and motion tracking.arXiv preprint arXiv:2604.17335, 2026. APPENDIXA RELATEDWORK Language-conditioned motion generation.A prominent line of work represents co...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.