Assistron: Bayesian Shared Autonomy with Off-the-shelf Vision-Language-Action Models
Pith reviewed 2026-06-26 08:34 UTC · model grok-4.3
The pith
Assistron uses off-the-shelf VLA models for macro movements and calls for human input only at contact-rich failure points, raising success rates without any model fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
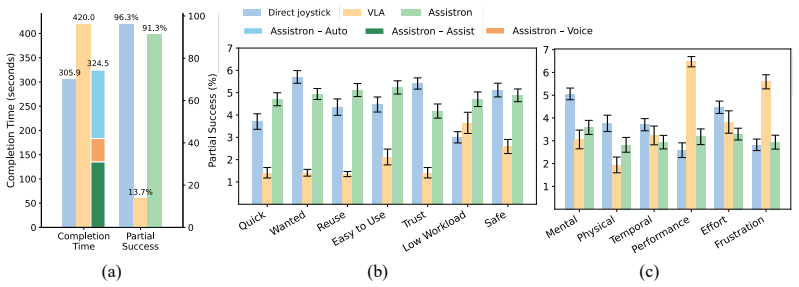
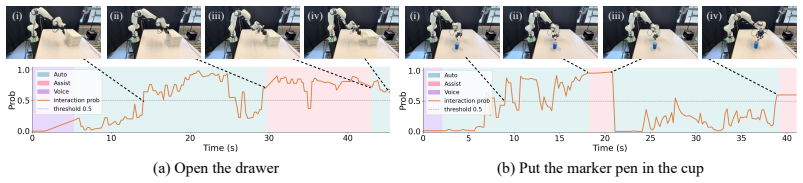
Assistron improves task success rates over pure autonomous VLA baselines and reduces human cognitive and physical workload relative to traditional teleoperation by deploying phase-aware interaction detection to identify VLA failure points in contact-rich phases and applying flow matching guidance to incorporate user interventions, all while avoiding any fine-tuning of the VLA model.
What carries the argument
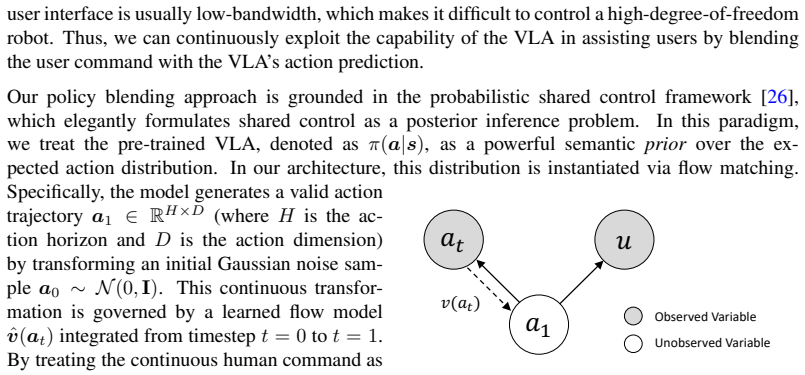
Phase-aware interaction detection mechanism that identifies likely VLA failure moments in contact-rich phases, paired with flow matching guidance to adjust the model's generated actions from user input.
If this is right
- Task success rates increase over pure VLA autonomy on diverse daily manipulation skills.
- Human cognitive and physical workload decreases compared with full teleoperation.
- The VLA retains its broad behavioral priors because no fine-tuning occurs.
- The method scales across multiple tasks in a scene recovery benchmark without task-specific retraining.
Where Pith is reading between the lines
- The detection-plus-flow-matching pattern could be reused to limit human input in other VLA applications such as navigation or assembly.
- Flow matching supplies a lightweight route for injecting human corrections into pretrained models while protecting their existing knowledge.
- Similar phase-aware triggers might generalize to any setting where large models handle routine segments and humans supply input only at uncertainty peaks.
Load-bearing premise
The phase-aware detection reliably flags the exact moments when VLA models fail in contact-rich interactions and flow matching can steer actions effectively without fine-tuning or eroding the model's original behavioral priors.
What would settle it
A controlled run on contact-rich daily manipulation tasks in which the detection either misses VLA errors or the flow matching adjustments cause measurable loss of the VLA's general capabilities on unseen tasks.
Figures






read the original abstract
We propose Assistron, a shared autonomy model that leverages Vision-Language-Action (VLA) models to assist the user in daily activities. Our approach is grounded in two core principles: (1)~minimizing human cognitive and physical effort by leveraging VLA-driven autonomy for macro-movements, and (2)~prioritizing human intervention specifically at critical failure points. Driven by the user's verbal language commands, Assistron utilizes the VLA to autonomously execute macro-reaching trajectories, saving users' effort. In contact-rich interactions where VLAs tend to fail, Assistron employs a phase-aware interaction detection mechanism and solicits the user to intervene, in turn adjusting the VLA's action generation via flow matching guidance. Critically, our formulation eliminates the need for VLA fine-tuning, protecting its broad behavioral priors from catastrophic forgetting and ensuring the model does not become a narrow specialist. We validate our approach on a comprehensive multi-task scene recovery benchmark encompassing diverse daily manipulation skills. Empirical results demonstrate that Assistron significantly improves task success rates over pure autonomous baselines while significantly reducing human cognitive and physical workload compared to traditional teleoperation, offering a scalable, smooth, and effortless paradigm for assistive manipulation. The code is available in https://github.com/mousecpn/Assistron.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Assistron, a shared autonomy system for assistive manipulation that integrates off-the-shelf Vision-Language-Action (VLA) models. It uses verbal commands to drive VLA-based autonomous execution of macro-reaching trajectories while employing a phase-aware interaction detection mechanism to identify contact-rich failure points and solicit human intervention, with flow-matching guidance used to adjust actions. The formulation avoids VLA fine-tuning to preserve behavioral priors. Validation is reported on a multi-task scene recovery benchmark, with claims of significantly higher task success rates versus pure autonomous baselines and lower human cognitive/physical workload versus teleoperation.
Significance. If the empirical claims hold under rigorous validation, the work demonstrates a practical route to deploying large pre-trained VLAs in shared autonomy without catastrophic forgetting, which could improve scalability for daily assistive tasks. The explicit focus on intervening only at critical phases while minimizing overall human effort addresses a key usability barrier in human-robot interaction.
major comments (2)
- [Abstract / Results] Abstract and experimental validation sections: the central empirical claim of significant improvements in task success rates and workload reduction rests on a multi-task benchmark, yet no details are supplied on task definitions, number of trials per condition, baseline implementations (including how pure autonomous VLA and teleoperation conditions were realized), statistical tests, or error bars; this information is load-bearing for assessing whether the reported gains are reliable or reproducible.
- [Method / Experiments] §3 (method) and §4 (experiments): the phase-aware interaction detection and flow-matching guidance are presented as reliably identifying VLA failure moments in contact-rich settings without fine-tuning, but no ablation, sensitivity analysis, or quantitative characterization of detection accuracy or guidance effectiveness is provided to substantiate that the mechanism preserves the VLA's behavioral priors while still enabling effective corrections.
minor comments (1)
- [Abstract] The GitHub link is provided but the manuscript does not indicate whether the released code includes the exact benchmark environments, random seeds, or evaluation scripts needed to reproduce the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where additional detail would strengthen the empirical claims. We address each major comment below and have revised the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and experimental validation sections: the central empirical claim of significant improvements in task success rates and workload reduction rests on a multi-task benchmark, yet no details are supplied on task definitions, number of trials per condition, baseline implementations (including how pure autonomous VLA and teleoperation conditions were realized), statistical tests, or error bars; this information is load-bearing for assessing whether the reported gains are reliable or reproducible.
Authors: We agree that these experimental details are necessary for reproducibility and rigorous assessment. In the revised manuscript we have expanded §4 to define each task in the multi-task scene recovery benchmark, specify that 30 independent trials were run per condition, describe the pure autonomous VLA baseline (off-the-shelf model with no human input) and teleoperation baseline (direct end-effector velocity control via joystick), report the use of paired t-tests with p < 0.01 for significance, and add standard-error bars to all bar plots. These additions directly address the load-bearing concerns. revision: yes
-
Referee: [Method / Experiments] §3 (method) and §4 (experiments): the phase-aware interaction detection and flow-matching guidance are presented as reliably identifying VLA failure moments in contact-rich settings without fine-tuning, but no ablation, sensitivity analysis, or quantitative characterization of detection accuracy or guidance effectiveness is provided to substantiate that the mechanism preserves the VLA's behavioral priors while still enabling effective corrections.
Authors: We acknowledge the value of explicit ablations for these components. The revised §4 now includes an ablation study that isolates the contribution of phase-aware detection and flow-matching guidance. We report detection precision and recall on annotated failure points, a sensitivity sweep over the contact-detection threshold, and KL-divergence between the original VLA action distribution and the flow-guided distribution to quantify preservation of behavioral priors. These quantitative results support the claim that corrections remain effective without eroding the VLA priors. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents Assistron as a method combining VLA models with phase-aware detection and flow-matching guidance for shared autonomy. No equations, derivations, or first-principles predictions appear in the provided text that reduce any claimed result to fitted parameters, self-definitions, or self-citation chains. Central claims rest on empirical task-success and workload measurements across a multi-task benchmark, which constitute independent evidence rather than tautological outputs. The explicit avoidance of fine-tuning is a stated design principle, not a circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLA models possess broad behavioral priors that must be protected from catastrophic forgetting by avoiding fine-tuning
- domain assumption A phase-aware interaction detection mechanism can accurately flag critical failure points in contact-rich tasks
Reference graph
Works this paper leans on
-
[1]
Chang, R
P. Chang, R. Luo, M. Dorostian, and T. Padır. A shared control method for collaborative human-robot plug task.IEEE Robotics and Automation Letters, 6(4):7429–7436, 2021
2021
-
[2]
Baksic, H
P. Baksic, H. Courtecuisse, and B. Bayle. Shared control strategy for needle insertion into deformable tissue using inverse finite element simulation. In2021 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 12442–12448. IEEE, 2021
2021
-
[3]
P. Song, P. Li, E. Aertbeli ¨en, and R. Detry. Robot trajectron: Trajectory prediction-based shared control for robot manipulation. InProceedings Of IEEE International Conference on Robotics and Automation, 2024
2024
-
[4]
Y . Xu, H. Zhang, L. Cao, X. Shu, and D. Zhang. A shared control strategy for reach and grasp of multiple objects using robot vision and noninvasive brain–computer interface.IEEE Transactions on Automation Science and Engineering, 19(1):360–372, 2020
2020
-
[5]
A. D. Dragan and S. S. Srinivasa. A policy-blending formalism for shared control.The Inter- national Journal of Robotics Research, 32(7):790–805, 2013
2013
-
[6]
Quere, A
G. Quere, A. Hagengruber, M. Iskandar, S. Bustamante, D. Leidner, F. Stulp, and J. V ogel. Shared control templates for assistive robotics. In2020 IEEE international conference on robotics and automation (ICRA), pages 1956–1962. IEEE, 2020
1956
-
[7]
M. S. Marambe, B. S. Duerstock, and J. P. Wachs. Optimization approach for multisensory feedback in robot-assisted pouring task. InActuators, volume 13, page 152. MDPI, 2024
2024
-
[8]
Padalkar, G
A. Padalkar, G. Quere, F. Steinmetz, A. Raffin, M. Nieuwenhuisen, J. Silv ´erio, and F. Stulp. Guiding reinforcement learning with shared control templates. In2023 IEEE International Conference on Robotics and Automation, ICRA 2023. IEEE, 2023
2023
-
[9]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: a VLA That Learns From Experience. arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[10]
Bjorck, F
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t nl: An open foundation model for generalist humanoid robots, 2025
2025
-
[11]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation, 2024
2024
-
[12]
Y . Hu, J.-N. Zaech, N. Nikolov, Y . Yao, S. Dey, G. Albanese, R. Detry, L. Van Gool, and D. Paudel. Ar-vla: True autoregressive action expert for vision-language-action models.arXiv preprint arXiv:2603.10126, 2026
Pith/arXiv arXiv 2026
-
[13]
H. Song, D. Qu, Y . Yao, Q. Chen, Q. Lv, Y . Tang, M. Shi, G. Ren, M. Yao, B. Zhao, et al. Hume: Introducing system-2 thinking in visual-language-action model, 2025
2025
-
[14]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a Vision-Language-Action Model with Open-World Generaliza- tion.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[15]
Y . Ma, H. He, S. Song, W. Wu, and B. Zhou. Aura: Multimodal shared autonomy for real- world urban navigation.arXiv preprint arXiv:2604.01659, 2026
arXiv 2026
-
[16]
T. Tang, X. Ji, W. Xing, C. Hao, W. Xu, L. Shao, C. Lu, Q. Yu, J. Pang, and K. Zhang. To- wards human-like manipulation through rl-augmented teleoperation and mixture-of-dexterous- experts vla.arXiv preprint arXiv:2603.08122, 2026
arXiv 2026
-
[17]
Y . Cui, Y . Zhang, L. Tao, Y . Li, X. Yi, and Z. Li. End-to-end dexterous arm-hand vla policies via shared autonomy: Vr teleoperation augmented by autonomous hand vla policy for efficient data collection.arXiv preprint arXiv:2511.00139, 2025
arXiv 2025
-
[18]
Y . Liu, Y . Yin, T. Huang, F. Yan, Y . Xu, W. Hong, W. Han, Y . Cao, X. Chen, Z. Fan, et al. Adaptor: Advancing assistive teleoperation with few-shot learning and cross-operator general- ization.arXiv preprint arXiv:2604.09462, 2026
Pith/arXiv arXiv 2026
- [19]
- [20]
-
[21]
J. Song, A. Vahdat, M. Mardani, and J. Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational conference on learning representations, 2023
2023
-
[22]
R. Feng, C. Yu, W. Deng, P. Hu, and T. Wu. On the guidance of flow matching.arXiv preprint arXiv:2502.02150, 2025
arXiv 2025
-
[23]
Radford, J
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[24]
Z. Xue, S. Deng, Z. Chen, Y . Wang, Z. Yuan, and H. Xu. Demogen: Synthetic demonstration generation for data-efficient visuomotor policy learning.arXiv preprint arXiv:2502.16932, 2025
arXiv 2025
-
[25]
K. Dreczkowski, P. Vitiello, V . V osylius, and E. Johns. Learning a thousand tasks in a day. Science Robotics, 10(108):eadv7594, 2025. doi:10.1126/scirobotics.adv7594. URLhttps: //www.science.org/doi/abs/10.1126/scirobotics.adv7594
-
[26]
P. Song, Y . Du, O. Saussus, S. De Schrijver, I. Caprara, P. Janssen, and R. Detry. Robot trajectron v2: A probabilistic shared control framework for navigation.arXiv preprint arXiv:2509.19954, 2025
arXiv 2025
-
[27]
S. Hart. Development of nasa-tlx (task load index): Results of empirical and theoretical re- search.Human mental workload/Elsevier, 1988
1988
-
[28]
H. E. Robbins. An empirical bayes approach to statistics. InBreakthroughs in Statistics: F oundations and basic theory, pages 388–394. Springer, 1992
1992
-
[29]
S. Luo, Q. Peng, J. Lv, K. Hong, K. R. Driggs-Campbell, C. Lu, and Y .-L. Li. Human-agent joint learning for efficient robot manipulation skill acquisition. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 1370–1377. IEEE, 2025
2025
-
[30]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. 2016 ieee conf. InComput. Vis. Pattern Recognit, pages 770–778, 2015
2016
- [31]
-
[32]
A. Wang, X. Yan, B. McMahan, M. Zhou, Y . Yuan, J. Y . Lee, A. Shreif, M. Li, Z. Peng, B. Zhou, et al. Disco: Diffusion sequence copilots for shared autonomy. InProceedings of the 21st ACM/IEEE International Conference on Human-Robot Interaction, pages 982–990, 2026
2026
-
[33]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.