A Benchmark of (MRI-) Foundation Models to Predict IDH Mutational Status in Glioma
Pith reviewed 2026-06-26 06:28 UTC · model grok-4.3
The pith
Tabular foundation models on radiomic features match or exceed image foundation models for IDH prediction from glioma MRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
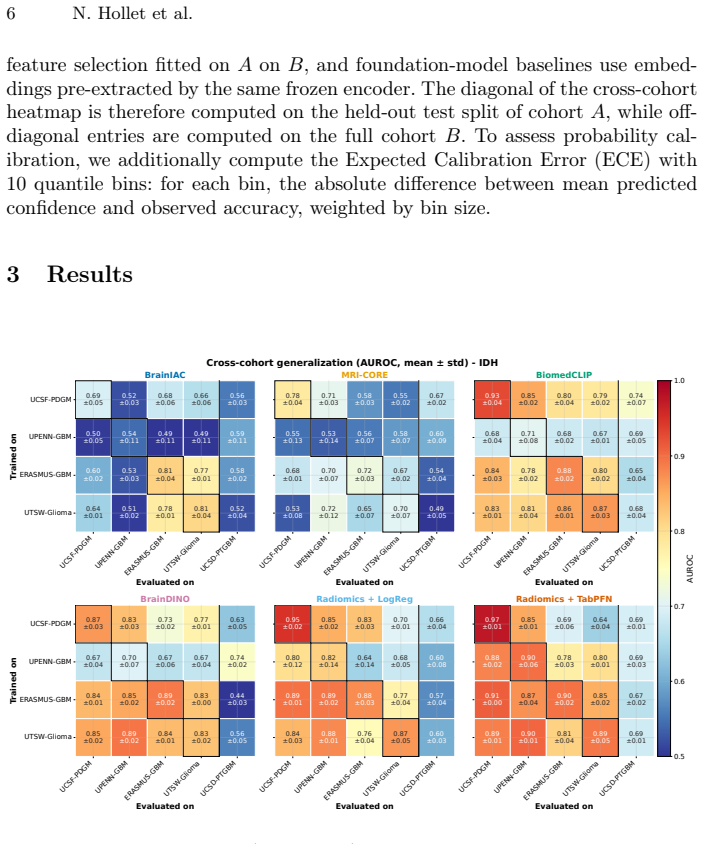
Representation modality and evaluation context critically influence foundation-model performance in MRI-based molecular prediction. Tabular foundation models on radiomic features provide a strong, well-calibrated baseline, while image foundation models may offer complementary value under clinically distinct distribution shifts.
What carries the argument
Benchmark of image foundation models (BrainIAC, MRI-CORE, BiomedCLIP, BrainDINO) versus radiomics TabPFN and logistic regression for IDH mutation prediction across four public glioma cohorts plus one external post-treatment cohort, measuring AUROC, AUPRC, and calibration error.
If this is right
- TabPFN on radiomics delivers 0.92 mean AUROC and 0.07 ECE within cohorts, establishing it as the strongest baseline.
- BiomedCLIP reaches the highest external-cohort AUROC of 0.74, suggesting image encoders can retain utility when prevalence or treatment status changes.
- AUPRC degrades more than AUROC under cross-cohort prevalence shifts, indicating prevalence-aware evaluation is required.
- MRI-specific pre-trained encoders consistently underperform general vision-language models like BiomedCLIP on this task.
- Calibration remains superior for the tabular model even when AUROC is comparable, affecting downstream clinical probability use.
Where Pith is reading between the lines
- Hybrid models that fuse radiomic tabular features with image embeddings could capture both the calibration strength and shift robustness observed here.
- The observed underperformance of MRI-specific encoders may indicate that current pre-training objectives or data scales are insufficient for molecular-status tasks and warrant targeted re-examination.
- Because calibration differs markedly by modality, clinical deployment pipelines may need modality-specific uncertainty thresholds rather than a single model selection rule.
- Extending the benchmark to include longitudinal or multi-sequence inputs could test whether the current modality ranking persists when more imaging context is available.
Load-bearing premise
The public glioma cohorts and external post-treatment cohort are representative enough of clinical distributions to support conclusions about generalization and the relative value of different model types.
What would settle it
On a new large multi-center prospective clinical dataset, if image foundation models show no AUROC advantage or complementary value over TabPFN under any measured distribution shift, the claim that they can offer value in distinct clinical contexts would be refuted.
Figures

read the original abstract
Non-invasive prediction of glioma molecular status from routine magnetic resonance imaging (MRI) has shown promising performance, but model generalization remains challenging given small-scale matched imaging-genomic datasets. Foundation models may address this bottleneck, but a comprehensive benchmark is needed to establish the impact of diverse architectures, pre-training domains, and objectives. Given the use case of isocitrate dehydrogenase (IDH) mutation prediction from FLAIR and post-contrast T1 MRIs, we compared four image-based foundation models, BrainIAC, MRI-CORE, BiomedCLIP, and BrainDINO, against radiomics-based TabPFN and logistic regression baselines. Prediction performance and calibration were assessed across four public adult glioma cohorts and an external post-treatment cohort. Within-cohort, TabPFN matched or outperformed all visual encoders, achieving 0.92 (0.03) AUROC and 0.74 (0.17) AUPRC (mean (SD) across all datasets). Among visual encoders, BiomedCLIP performed best (0.85 (0.08) AUROC), with BrainDINO competitive (0.82 (0.09) AUROC), while MRI-specific encoders (BrainIAC, MRI-CORE) consistently underperformed. Cross-cohort transfer showed moderate AUROC degradation but stronger AUPRC sensitivity to prevalence shifts. On the external cohort, BiomedCLIP achieved the highest AUROC (0.74 (0.07)), whereas TabPFN provided superior calibration (Expected Calibration Error 0.07 (0.01)). These results indicate that representation modality and evaluation context critically influence foundation-model performance in MRI-based molecular prediction. Tabular foundation models on radiomic features provide a strong, well-calibrated baseline, while image foundation models may offer complementary value under clinically distinct distribution shifts. Code available at https://github.com/nathanhollet/idh-status-prediction
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks four image foundation models (BrainIAC, MRI-CORE, BiomedCLIP, BrainDINO) against radiomics-based TabPFN and logistic regression baselines for predicting IDH mutational status from FLAIR and post-contrast T1 MRI. It reports within-cohort performance (TabPFN AUROC 0.92, BiomedCLIP 0.85), cross-cohort transfer degradation, and external post-treatment cohort results (BiomedCLIP AUROC 0.74, TabPFN better calibration), concluding that tabular models provide a strong baseline while image models may complement under distribution shifts. Code is released.
Significance. If the tabulated results and calibration metrics hold after verification of methods, the benchmark supplies concrete empirical comparisons of modality-specific foundation models on a clinically relevant molecular prediction task. The public code release and focus on both AUROC/AUPRC and calibration are strengths that allow direct reuse and extension by the community.
major comments (1)
- [Abstract] Abstract: the claim that image foundation models 'may offer complementary value under clinically distinct distribution shifts' is not supported by any quantitative characterization of how the external post-treatment cohort differs from the four public cohorts or from routine clinical distributions (scanner vendor, field strength, slice thickness, treatment timing, or demographics). Without this, the reversal in ranking (BiomedCLIP AUROC advantage vs. TabPFN calibration) cannot be interpreted as evidence of complementary value under shifts.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the opportunity to strengthen the manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that image foundation models 'may offer complementary value under clinically distinct distribution shifts' is not supported by any quantitative characterization of how the external post-treatment cohort differs from the four public cohorts or from routine clinical distributions (scanner vendor, field strength, slice thickness, treatment timing, or demographics). Without this, the reversal in ranking (BiomedCLIP AUROC advantage vs. TabPFN calibration) cannot be interpreted as evidence of complementary value under shifts.
Authors: We agree that the abstract claim would be more robust with explicit cohort characterization. The external cohort is explicitly described as post-treatment (distinct in treatment timing from the primarily pre-treatment public cohorts), and the observed reversal (BiomedCLIP AUROC 0.74 vs. TabPFN superior calibration) is presented as suggestive rather than definitive evidence. However, we did not include a consolidated table of scanner, field strength, slice thickness, or demographic metadata across cohorts. In revision we will (1) add a table or paragraph in Methods summarizing all available cohort metadata and (2) revise the abstract sentence to read: 'On the external post-treatment cohort, image encoders showed an AUROC advantage while the tabular baseline remained better calibrated, indicating that representation modality and evaluation context influence performance under distribution shift.' This directly incorporates the referee's point without overstating the evidence. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential predictions.
full rationale
This paper is a data-driven benchmark study that trains and evaluates multiple models (image foundation models, TabPFN, logistic regression) on public glioma cohorts and one external set, reporting AUROC, AUPRC, and calibration metrics. No equations, derivations, or fitted parameters are presented that reduce any reported performance number to an input by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The central claims rest on direct empirical comparisons rather than any closed logical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying AUROC, AUPRC, and expected calibration error calculations hold for the evaluated datasets and models.
Reference graph
Works this paper leans on
-
[1]
PLOS ONE16(8), e0256152 (Aug 2021)
An, C., Park, Y.W., Ahn, S.S., Han, K., Kim, H., Lee, S.K.: Radiomics ma- chine learning study with a small sample size: Single random training-test set split may lead to unreliable results. PLOS ONE16(8), e0256152 (Aug 2021). https://doi.org/10.1371/journal.pone.0256152
-
[2]
Bakas, S., et al.: The University of Pennsylvania glioblastoma (UPenn-GBM) co- hort: advanced MRI, clinical, genomics, & radiomics. Scientific Data9(1), 453 (Jul 2022). https://doi.org/10.1038/s41597-022-01560-7
-
[3]
On the Opportunities and Risks of Foundation Models
Bommasani, R., et al.: On the Opportunities and Risks of Foundation Models (Jul 2022). https://doi.org/10.48550/arXiv.2108.07258
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07258 2022
-
[4]
Neuro-oncology Advances4(1), vdac060 (Apr 2022)
Calabrese, E., Rudie, J.D., Rauschecker, A.M., Villanueva-Meyer, J.E., Clarke, J.L., Solomon, D.A., Cha, S.: Combining radiomics and deep convolutional neural network features from preoperative MRI for predicting clinically relevant genetic biomarkers in glioblastoma. Neuro-oncology Advances4(1), vdac060 (Apr 2022). https://doi.org/10.1093/noajnl/vdac060
-
[5]
Calabrese, E., et al.: The University of California San Francisco Preoperative Dif- fuse Glioma MRI (UCSF-PDGM) Dataset. Radiology: Artificial Intelligence4(6), e220058 (Nov 2022). https://doi.org/10.1148/ryai.220058
-
[6]
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple frame- work for contrastive learning of visual representations (2020), https://arxiv.org/abs/2002.05709
Pith/arXiv arXiv 2020
-
[7]
Neuro-Oncology23(2), 304–313 (Jul 2020)
Choi, Y.S., et al.: Fully automated hybrid approach to predict the IDH mutation status of gliomas via deep learning and radiomics. Neuro-Oncology23(2), 304–313 (Jul 2020). https://doi.org/10.1093/neuonc/noaa177 10 N. Hollet et al
-
[8]
Mri- core: a foundation model for magnetic resonance imaging
Dong, H., Chen, Y., Gu, H., Konz, N., Chen, Y., Li, Q., Mazurowski, M.A.: MRI-CORE: A Foundation Model for Magnetic Resonance Imaging (Jul 2025). https://doi.org/10.48550/arXiv.2506.12186
-
[9]
Eu- ropean Radiology36(2), 1562–1591 (Feb 2026)
Farahani, S., Hejazi, M., Tabassum, M., Di Ieva, A., Mahdavifar, N., Liu, S.: Di- agnostic performance of deep learning for predicting glioma isocitrate dehydroge- nase and 1p/19q co-deletion in MRI: a systematic review and meta-analysis. Eu- ropean Radiology36(2), 1562–1591 (Feb 2026). https://doi.org/10.1007/s00330- 025-11898-2
-
[10]
https://doi.org/10.7937/FWV2-DT74, version 3
Gagnon, L., et al.: The University of California San Diego annotated post- treatment high-grade glioma multimodal MRI dataset (UCSD-PTGBM) (2025). https://doi.org/10.7937/FWV2-DT74, version 3
-
[11]
He, W., Huang, W., Zhang, L., Wu, X., Zhang, S., Zhang, B.: Radiogenomics: bridging the gap between imaging and genomics for precision oncology. MedComm 5(9), e722 (2024). https://doi.org/10.1002/mco2.722
-
[12]
Clinical and Translational Radi- ation Oncology18, 74–79 (Apr 2019)
van der Heide, U.A., Frantzen-Steneker, M., Astreinidou, E., Nowee, M.E., van Houdt, P.J.: MRI basics for radiation oncologists. Clinical and Translational Radi- ation Oncology18, 74–79 (Apr 2019). https://doi.org/10.1016/j.ctro.2019.04.008
-
[13]
In: International Confer- ence on Learning Representations 2023 (2023)
Hollmann, N., Müller, S., Eggensperger, K., Hutter, F.: Tabpfn: A transformer that solves small tabular classification problems in a second. In: International Confer- ence on Learning Representations 2023 (2023)
2023
-
[14]
Automated brain extracƟon of mulƟsequence MRI using arƟficial neural networks
Isensee, F., et al.: Automated brain extraction of multisequence MRI using ar- tificial neural networks. Human Brain Mapping40(17), 4952–4964 (Aug 2019). https://doi.org/10.1002/hbm.24750
-
[15]
Kumar, A., Raghunathan, A., Jones, R., Ma, T., Liang, P.: Fine-tuning can distort pretrained features and underperform out-of-distribution (2022), https://arxiv.org/abs/2202.10054
arXiv 2022
-
[16]
Neuro-Oncology23(8), 1231–1251 (Jun 2021)
Louis, D.N., et al.: The 2021 WHO Classification of Tumors of the Central Nervous System: a summary. Neuro-Oncology23(8), 1231–1251 (Jun 2021). https://doi.org/10.1093/neuonc/noab106
-
[17]
Magnetic Resonance Imaging104, 72–79 (Dec 2023)
Lu, J., Xu, W., Chen, X., Wang, T., Li, H.: Noninvasive prediction of IDH muta- tion status in gliomas using preoperative multiparametric MRI radiomics nomo- gram: A mutlicenter study. Magnetic Resonance Imaging104, 72–79 (Dec 2023). https://doi.org/10.1016/j.mri.2023.09.001
-
[18]
npj Precision Oncology9(1), 187 (Jun 2025)
Nakase, T., et al.: Integration of MRI radiomics and germline genetics to predict the IDH mutation status of gliomas. npj Precision Oncology9(1), 187 (Jun 2025). https://doi.org/10.1038/s41698-025-00980-z
-
[19]
Oquab, M., et al.: Dinov2: Learning robust visual features without supervision (2024), https://arxiv.org/abs/2304.07193
Pith/arXiv arXiv 2024
-
[20]
Paszke, A., et al.: Pytorch: An imperative style, high-performance deep learning library (2019), https://arxiv.org/abs/1912.01703
Pith/arXiv arXiv 2019
-
[21]
In: 2019 53rd Asilo- mar Conference on Signals, Systems, and Computers
Qin, J., Lou, Y.: L1-2 Regularized Logistic Regression. In: 2019 53rd Asilo- mar Conference on Signals, Systems, and Computers. pp. 779–783 (Nov 2019). https://doi.org/10.1109/IEEECONF44664.2019.9048830, iSSN: 2576-2303
-
[22]
Learning Transferable Visual Models From Natural Language Supervision
Radford, A., et al.: Learning Transferable Visual Models From Natural Language Supervision (Feb 2021). https://doi.org/10.48550/arXiv.2103.00020
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020 2021
-
[23]
https://doi.org/10.7937/DFAE-1B86, version 1
Reddy, D., et al.: The University of Texas Southwestern Glioma MRI dataset with molecular marker characterization and segmentations (UTSW-Glioma) (2026). https://doi.org/10.7937/DFAE-1B86, version 1
-
[24]
Siméoni, O., et al.: Dinov3 (2025), https://arxiv.org/abs/2508.10104 Title Suppressed Due to Excessive Length 11
Pith/arXiv arXiv 2025
-
[25]
Sottoriva, A., et al.: Intratumor heterogeneity in human glioblastoma re- flects cancer evolutionary dynamics. Proceedings of the National Academy of Sciences of the United States of America110(10), 4009–4014 (Mar 2013). https://doi.org/10.1073/pnas.1219747110
-
[26]
Task representations in neural networks trained to perform many cognitive tasks
Tak, D., et al.: A generalizable foundation model for analysis of human brain MRI. Nature Neuroscience29(4), 945–956 (Apr 2026). https://doi.org/10.1038/s41593- 026-02202-6
-
[27]
Data in Brief37, 107191 (Jun 2021)
van der Voort, S.R., et al.: The Erasmus Glioma Database (EGD): Structural MRI scans, WHO 2016 subtypes, and segmentations of 774 patients with glioma. Data in Brief37, 107191 (Jun 2021). https://doi.org/10.1016/j.dib.2021.107191
-
[28]
Wu, Y., Wang, S., Li, Y., Safari, M., Hu, M., Chang, C.W., Veeraraghavan, H., Yang, X.: Braindino: A brain mri foundation model for generalizable clinical rep- resentation learning (2026), https://arxiv.org/abs/2604.27277
Pith/arXiv arXiv 2026
-
[29]
The New England journal of medicine360(8), 765–773 (Feb 2009)
Yan, H., et al.: IDH1 and IDH2 Mutations in Gliomas. The New England journal of medicine360(8), 765–773 (Feb 2009). https://doi.org/10.1056/NEJMoa0808710
-
[30]
Health Care Science4(2), 110–143 (Apr 2025)
Yuan, H., Zhu, M., Yang, R., Liu, H., Li, I., Hong, C.: Rethinking domain- specific pretraining by supervised or self-supervised learning for chest radio- graph classification: A comparative study against imagenet counterparts in cold-start active learning. Health Care Science4(2), 110–143 (Apr 2025). https://doi.org/10.1002/hcs2.70009
-
[31]
Zhang, S., et al.: BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs (Jan 2025). https://doi.org/10.48550/arXiv.2303.00915
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.00915 2025
-
[32]
Cancer journal (Sudbury, Mass.)22(6), 418–422 (2016)
Ziv, E., Durack, J.C., Solomon, S.B.: The Importance of Biopsy in the Era of Molecular Medicine. Cancer journal (Sudbury, Mass.)22(6), 418–422 (2016). https://doi.org/10.1097/PPO.0000000000000228
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.