Attention mechanism for scalable mesh-based neural surrogates of free-surface fluids
Pith reviewed 2026-06-26 06:08 UTC · model grok-4.3
The pith
Self-attention neural surrogates predict free-surface fluid flows on evolving meshes with improved scalability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The self-attention-based neural surrogate accurately predicts transient dynamics and final configurations of free-surface flows with significantly improved scalability while preserving the PFEM mesh discretization and enabling reconstruction of derived mechanical quantities.
What carries the argument
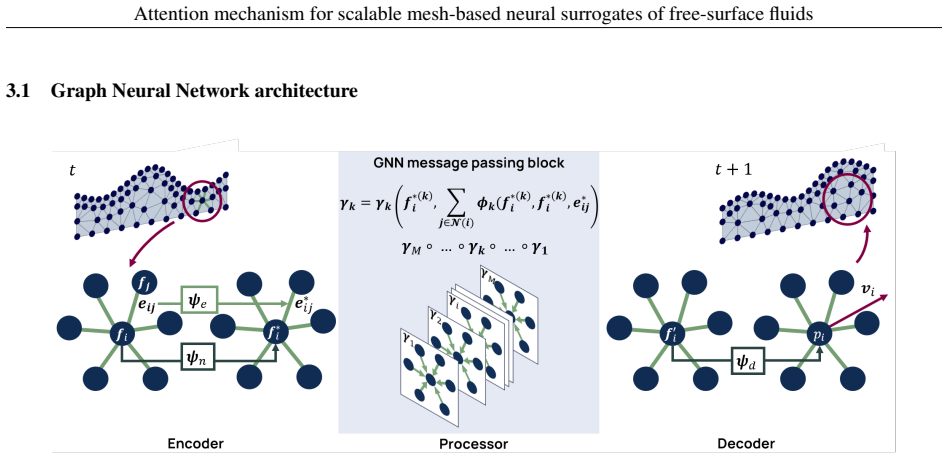
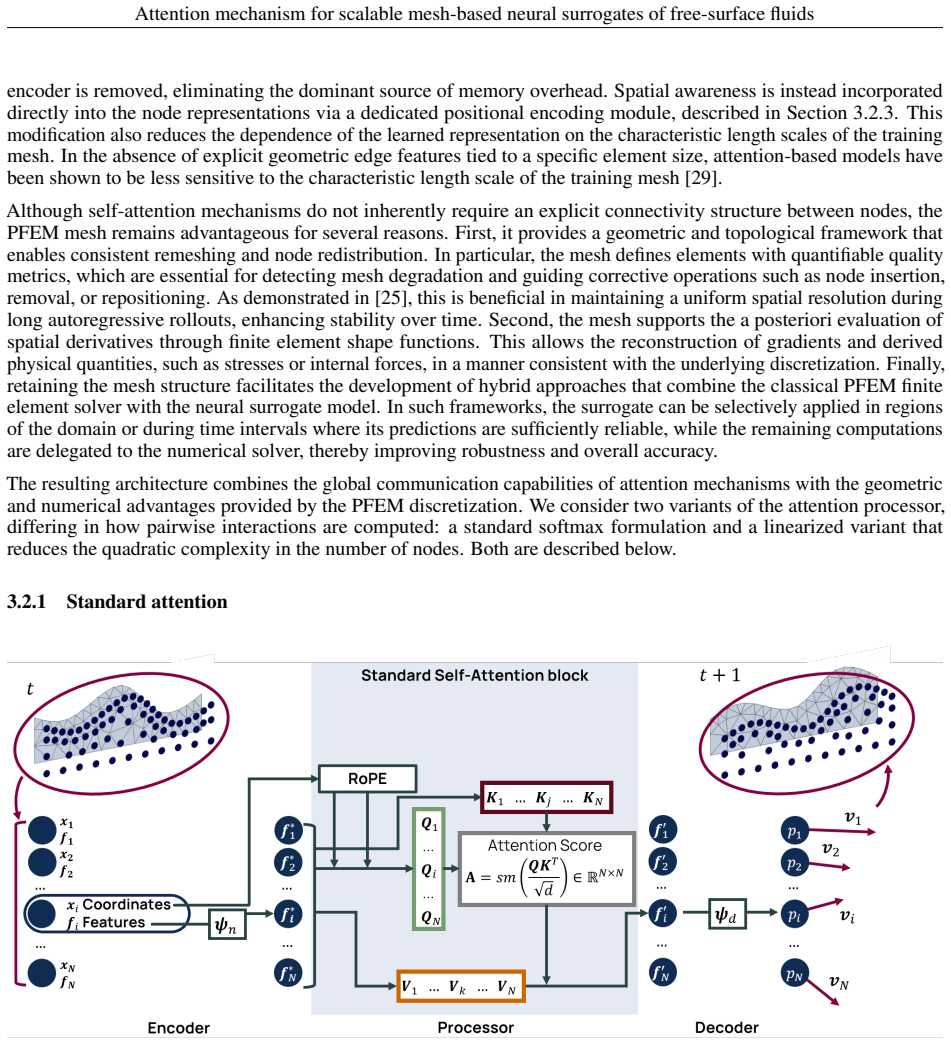
Self-attention layers that model interactions between nodes on the PFEM mesh to capture spatial dependencies in evolving free-surface flows.
If this is right
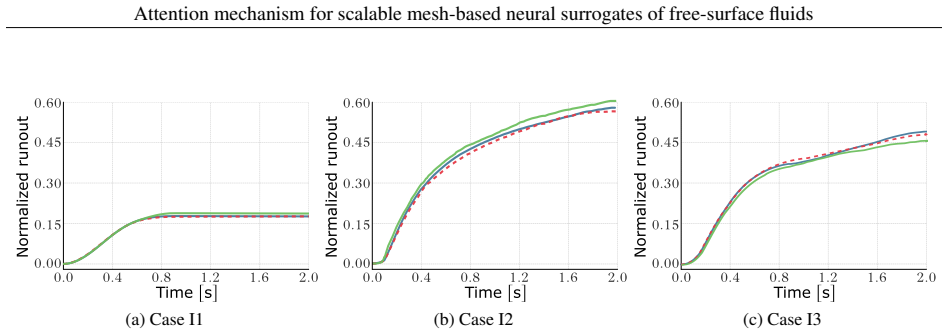
- Accurate predictions hold for two- and three-dimensional benchmarks with varying material parameters and non-Newtonian fluids.
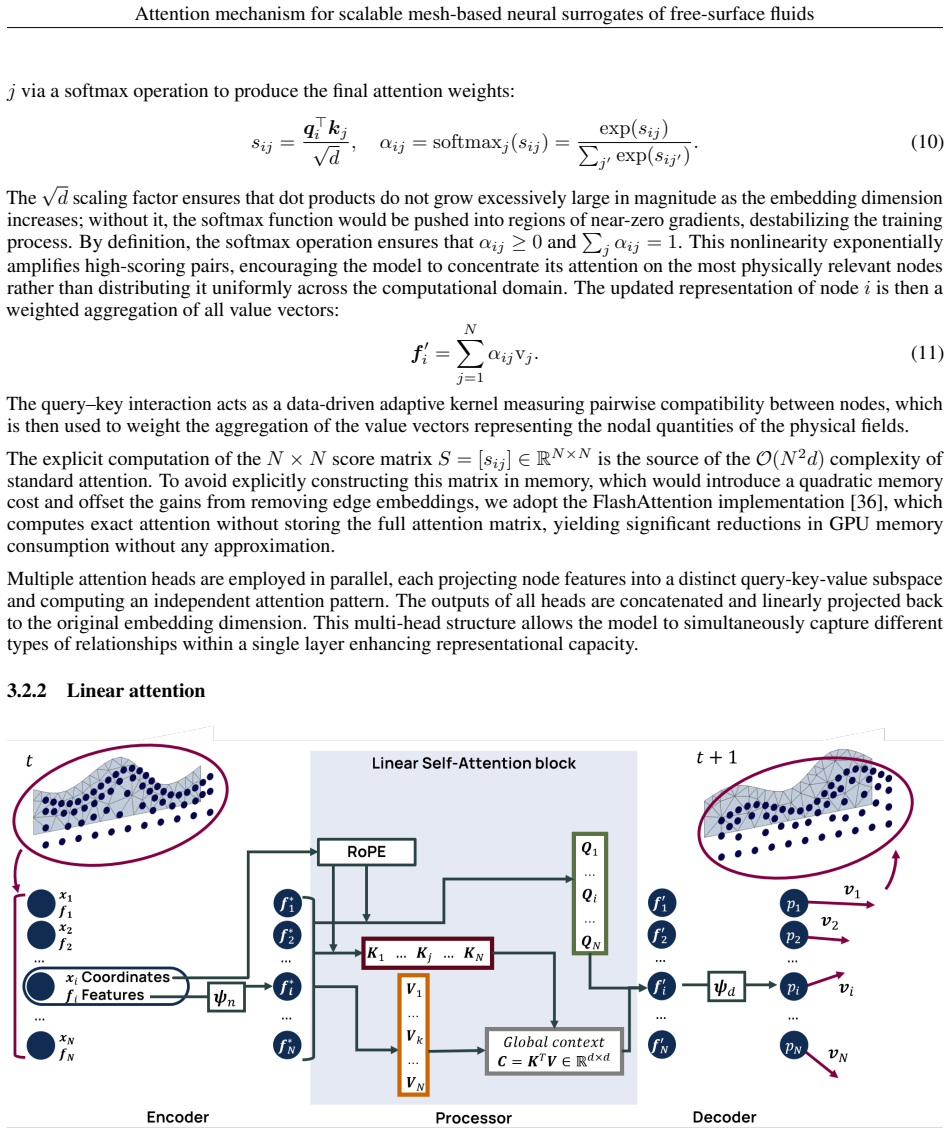
- The linear attention variant reduces computational cost and improves scalability over standard self-attention.
- Mesh preservation allows direct reconstruction of stress fields and other mechanical quantities via standard finite element operators.
- Improved long-term stability during rollouts on changing geometries without additional remeshing rules.
Where Pith is reading between the lines
- Such surrogates might be combined with optimization loops for design of fluid-handling structures.
- The approach could apply to other mesh-based Lagrangian simulations beyond free-surface flows.
- Future work might test generalization to unseen rheologies or larger domains not in the training set.
Load-bearing premise
Attention layers reliably capture spatial dependencies for stable long-term rollouts on arbitrary evolving meshes without needing extra constraints.
What would settle it
Running the surrogate on a long-duration 3D simulation of a non-Newtonian free-surface flow and comparing the predicted mesh evolution and quantities against a full PFEM reference solution to check for accumulating errors or instability.
Figures







read the original abstract
High-fidelity simulations of free-surface flows using Lagrangian methods such as the Particle Finite Element Method (PFEM) are computationally demanding due to continuous domain updates and repeated solution of the governing equations. This challenge is further amplified by non-Newtonian rheologies, where material nonlinearities increase computational cost. These limitations motivate the development of efficient surrogate models to approximate PFEM dynamics at reduced cost. While data-driven deep learning approaches are promising, a key challenge is designing models that operate on arbitrary and evolving geometries. We propose a self-attention-based neural surrogate for PFEM simulations of free-surface flows. The architecture leverages attention mechanisms to model node interactions and capture complex spatial dependencies, while preserving the PFEM mesh discretization. This provides a geometric and topological framework for remeshing and node redistribution, maintaining high-quality spatial discretization during rollouts, improving long-term stability, and enabling reconstruction of derived mechanical quantities via standard finite element operators. Two attention formulations are considered: a standard self-attention mechanism and a linear variant that reduces computational cost and improves scalability. The models are evaluated on two- and three-dimensional free-surface flow benchmarks with evolving geometries, varying material parameters, and non-Newtonian fluids. Results show accurate prediction of transient dynamics and final configurations, with significantly improved scalability. The mesh-based formulation also enables direct reconstruction of quantities such as stress fields. Overall, the framework provides an accurate and scalable surrogate strategy for PFEM simulations in engineering-scale applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-attention-based neural surrogate for Particle Finite Element Method (PFEM) simulations of free-surface flows. It employs standard and linear self-attention layers to model node interactions on arbitrary evolving meshes, preserving the PFEM discretization to support remeshing, long-term stability, and reconstruction of derived mechanical quantities via standard FE operators. The models are evaluated on 2D and 3D benchmarks involving varying material parameters and non-Newtonian fluids, with claims of accurate transient and final-state predictions plus significantly improved scalability.
Significance. If the quantitative claims hold, the work would supply a practical mesh-preserving surrogate that reduces the cost of repeated PFEM solves while retaining the ability to apply standard remeshing and post-process stress/strain fields, which is a concrete advantage over purely particle- or grid-based neural surrogates for engineering free-surface problems.
major comments (2)
- [Abstract] Abstract and evaluation description: the central claim that the surrogate 'accurately predicts transient dynamics and final configurations' and 'significantly improved scalability' is asserted without any reported error metrics (e.g., L2 velocity or interface error), baseline comparisons against PFEM or other surrogates, or validation protocols for long-horizon rollouts. This absence directly undermines assessment of the accuracy and stability assertions.
- [Architecture / Model description] The architecture description does not specify any explicit mechanism (regularization, loss term, or architectural constraint) that would enforce mesh-quality metrics, volume preservation, or divergence-free conditions on the evolving node sets. Because the skeptic correctly notes that standard self-attention supplies no such guarantees, the claim that the model 'maintains high-quality spatial discretization during rollouts' without post-hoc rules remains unsecured.
minor comments (1)
- [Abstract] The abstract is unusually long and contains several forward-looking claims that would be better placed in the conclusions or results summary.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the central claim that the surrogate 'accurately predicts transient dynamics and final configurations' and 'significantly improved scalability' is asserted without any reported error metrics (e.g., L2 velocity or interface error), baseline comparisons against PFEM or other surrogates, or validation protocols for long-horizon rollouts. This absence directly undermines assessment of the accuracy and stability assertions.
Authors: The abstract is a high-level summary. Quantitative error metrics (L2 norms on velocity and interface position), direct PFEM baseline comparisons, and long-horizon rollout statistics are reported in Sections 4 and 5 of the manuscript. We will revise the abstract to include representative quantitative values and a brief statement on the validation protocol. revision: yes
-
Referee: [Architecture / Model description] The architecture description does not specify any explicit mechanism (regularization, loss term, or architectural constraint) that would enforce mesh-quality metrics, volume preservation, or divergence-free conditions on the evolving node sets. Because the skeptic correctly notes that standard self-attention supplies no such guarantees, the claim that the model 'maintains high-quality spatial discretization during rollouts' without post-hoc rules remains unsecured.
Authors: The surrogate is formulated to output updated nodal positions and velocities on the existing PFEM mesh connectivity. This design choice deliberately retains the PFEM discretization so that the standard PFEM remeshing and node-redistribution algorithms can be applied after each surrogate step exactly as in the original solver. No additional regularization terms for volume or divergence are present in the loss; the network is trained to reproduce the PFEM trajectories, which already satisfy these constraints. The claim of maintained discretization quality therefore rests on the ability to invoke the existing PFEM remeshing machinery rather than on an internal architectural guarantee. revision: partial
Circularity Check
No significant circularity; standard data-driven surrogate
full rationale
The paper describes a neural surrogate architecture (self-attention or linear attention) trained on PFEM simulation trajectories to predict node positions and velocities on evolving meshes. No load-bearing equations, uniqueness theorems, or ansatzes are presented that reduce a claimed prediction to a fitted input or self-citation by construction. Evaluation relies on empirical rollout accuracy against held-out PFEM runs; the mesh-based output enables post-hoc FE operators but does not redefine or tautologically derive any mechanical quantity. This is the expected non-finding for a purely empirical ML modeling paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Idelsohn, E. Oñate, F. D. Pin, The particle finite element method: A powerful tool to solve incompressible flows with free-surfaces and breaking waves, International Journal for Numerical Methods in Engineering 61 (7) (2004) 964–989.doi:10.1002/nme.1096
-
[2]
M. Cremonesi, A. Franci, S. Idelsohn, E. Oñate, A State of the Art Review of the Particle Finite Element Method (PFEM), Arch Computat Methods Eng 27 (5) (2020) 1709–1735.doi:10.1007/s11831-020-09468-4
-
[3]
A. Franci, M. Cremonesi, U. Perego, G. Crosta, E. Oñate, 3D simulation of Vajont disaster. Part 1: Numerical formulation and validation, Engineering Geology 279 (2020) 105854. doi:10.1016/j.enggeo.2020.105854
-
[4]
J. M. Carbonell, L. Monforte, M. O. Ciantia, M. Arroyo, A. Gens, Geotechnical particle finite element method for modeling of soil-structure interaction under large deformation conditions, Journal of Rock Mechanics and Geotechnical Engineering 14 (3) (2022) 967–983.doi:10.1016/j.jrmge.2021.12.006
-
[5]
G. Rizzieri, L. Ferrara, M. Cremonesi, Simulation of viscoelastic free-surface flows with the Particle Finite Element Method, Comp. Part. Mech. 11 (5) (2024) 2043–2067.doi:10.1007/s40571-024-00730-1. 22 Attention mechanism for scalable mesh-based neural surrogates of free-surface fluids
-
[6]
G. Rizzieri, L. Ferrara, M. Cremonesi, A partitioned Lagrangian finite element approach for the simulation of viscoelastic and elasto-viscoplastic free-surface flows, Computer Methods in Applied Mechanics and Engineering 443 (2025) 118071.doi:10.1016/j.cma.2025.118071
-
[7]
S. Idelsohn, M. Mier-Torrecilla, E. Oñate, Multi-fluid flows with the Particle Finite Element Method, Computer Methods in Applied Mechanics and Engineering 198 (33) (2009) 2750–2767. doi:10.1016/j.cma.2009.04. 002
-
[8]
S. Meduri, M. Cremonesi, U. Perego, O. Bettinotti, A. Kurkchubasche, V . Oancea, A partitioned fully explicit Lagrangian finite element method for highly nonlinear fluid-structure interaction problems, International Journal for Numerical Methods in Engineering 113 (1) (2018) 43–64.doi:10.1002/nme.5602
-
[10]
C. Fu, M. Cremonesi, U. Perego, A hybrid Lagrangian–Eulerian particle finite element method for free-surface and fluid–structure interaction problems, International Journal for Numerical Methods in Engineering 125 (5) (2024) e7402.doi:10.1002/nme.7402
-
[11]
P. B. Ryzhakov, J. García, E. Oñate, Lagrangian finite element model for the 3D simulation of glass forming processes, Computers & Structures 177 (2016) 126–140.doi:10.1016/j.compstruc.2016.09.007
-
[12]
G. Rizzieri, L. Ferrara, M. Cremonesi, Numerical simulation of the extrusion and layer deposition processes in 3D concrete printing with the Particle Finite Element Method, Comput Mech 73 (2) (2024) 277–295. doi: 10.1007/s00466-023-02367-y
-
[13]
T. Leyssens, M. Henry, J. Lambrechts, J.-F. Remacle, A Delaunay refinement algorithm for the particle finite element method applied to free surface flows, International Journal for Numerical Methods in Engineering 125 (18) (2024) e7554.doi:10.1002/nme.7554
-
[14]
A. Quarteroni, A. Manzoni, F. Negri, Reduced Basis Methods for Partial Differential Equations, V ol. 92 of UNITEXT, Springer International Publishing, Cham, 2016.doi:10.1007/978-3-319-15431-2
-
[15]
M. Beckermann, R. Scanff, M. Cremonesi, A. Barbarulo, A new strategy using the Proper Generalized De- composition to model time evolving spatial domains, Computers & Structures 316 (2025) 107860. doi: 10.1016/j.compstruc.2025.107860
-
[16]
S. Brivio, S. Fresca, A. Manzoni, Handling geometrical variability in nonlinear reduced order modeling through Continuous Geometry-Aware DL-ROMs, Computer Methods in Applied Mechanics and Engineering 442 (2025) 117989.doi:10.1016/j.cma.2025.117989
-
[17]
A. Tierz, I. Alfaro, D. González, F. Chinesta, E. Cueto, Graph neural networks informed locally by thermodynamics, Engineering Applications of Artificial Intelligence 144 (2025) 110108. doi:10.1016/j.engappai.2025. 110108
-
[18]
V . Sharma, O. Fink, A physics-informed graph neural network conserving linear and angular momentum for dynamical systems, Nat Commun 17 (1) (2026) 1045.doi:10.1038/s41467-025-67802-5
-
[19]
A. Sanchez-Gonzalez, J. Godwin, T. Pfaff, R. Ying, J. Leskovec, P. W. Battaglia, Learning to Simulate Complex Physics with Graph Networks (Sep. 2020).arXiv:2002.09405,doi:10.48550/arXiv.2002.09405
-
[20]
Z. Li, A. B. Farimani, Graph neural network-accelerated Lagrangian fluid simulation, Computers & Graphics 103 (2022) 201–211.doi:10.1016/j.cag.2022.02.004
-
[21]
S. Zhao, H. Chen, J. Zhao, A physical-information-flow-constrained temporal graph neural network-based simulator for granular materials, Computer Methods in Applied Mechanics and Engineering 433 (2025) 117536. doi:10.1016/j.cma.2024.117536
-
[22]
Y . Choi, K. Kumar, Graph Neural Network-based surrogate model for granular flows, Computers and Geotechnics 166 (2024) 106015.doi:10.1016/j.compgeo.2023.106015
-
[23]
Z. Li, K. Meidani, P. Yadav, A. Barati Farimani, Graph neural networks accelerated molecular dynamics, J. Chem. Phys. 156 (14) (2022) 144103.doi:10.1063/5.0083060
-
[24]
Com- puter Methods in Applied Mechanics and Engineering449, 118476 (2026)
L. Tesán, M. M. Iparraguirre, D. González, P. Martins, E. Cueto, On the under-reaching phenomenon in message passing neural PDE solvers: Revisiting the CFL condition, Computer Methods in Applied Mechanics and Engineering 449 (2026) 118476.doi:10.1016/j.cma.2025.118476
-
[25]
F. Lanteri, M. Cremonesi, A mesh-based Graph Neural Network approach for surrogate modeling of Lagrangian free surface fluid flows, Computers & Fluids 301 (2025) 106773.doi:10.1016/j.compfluid.2025.106773. 23 Attention mechanism for scalable mesh-based neural surrogates of free-surface fluids
-
[26]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. ukasz Kaiser, I. Polosukhin, Attention is All you Need, in: Advances in Neural Information Processing Systems, V ol. 30, Curran Associates, Inc., 2017
2017
-
[27]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Jun. 2021).arXiv:2010.11929,doi:10.48550/arXiv.2010.11929
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2021
-
[28]
Jumper, R
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. Žídek, A. Potapenko, A. Bridgland, C. Meyer, S. A. A. Kohl, A. J. Ballard, A. Cowie, B. Romera-Paredes, S. Nikolov, R. Jain, J. Adler, T. Back, S. Petersen, D. Reiman, E. Clancy, M. Zielinski, M. Steinegger, M. Pacholska, T. Berghammer, S. Bodenstein, ...
2021
-
[29]
Z. Li, K. Meidani, A. B. Farimani, Transformer for Partial Differential Equations’ Operator Learning (Apr. 2023). arXiv:2205.13671,doi:10.48550/arXiv.2205.13671
-
[30]
H. Wu, H. Luo, H. Wang, J. Wang, M. Long, Transolver: A Fast Transformer Solver for PDEs on General Geometries (Jun. 2024).arXiv:2402.02366,doi:10.48550/arXiv.2402.02366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.02366 2024
-
[31]
C. Adams, R. Ranade, R. Cherukuri, S. Choudhry, GeoTransolver: Learning Physics on Irregular Domains Using Multi-scale Geometry Aware Physics Attention Transformer (Dec. 2025). arXiv:2512.20399, doi: 10.48550/arXiv.2512.20399
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.20399 2025
-
[32]
M. M. Iparraguirre, I. Alfaro, D. Gonzalez, E. Cueto, MeshGraphNet-Transformer: Scalable Mesh-based Learned Simulation for Solid Mechanics (Feb. 2026).arXiv:2601.23177,doi:10.48550/arXiv.2601.23177
-
[33]
N. Wang, S. Zheng, Y . Chen, H. Zhao, Z. Fang, FluidFormer : Transformer with continuous convolution for particle-based fluid simulation, Neural Networks 198 (2026) 108631. doi:10.1016/j.neunet.2026.108631
-
[34]
B. Alkin, M. Bleeker, R. Kurle, T. Kronlachner, R. Sonnleitner, M. Dorfer, J. Brandstetter, AB-UPT: Scaling Neural CFD Surrogates for High-Fidelity Automotive Aerodynamics Simulations via Anchored-Branched Universal Physics Transformers (Oct. 2025).arXiv:2502.09692,doi:10.48550/arXiv.2502.09692
-
[35]
M. Saberi, A. B. Farimani, S. Jamali, RheOFormer: A generative transformer model for simulation of complex fluids and flows (Oct. 2025).arXiv:2510.01365,doi:10.48550/arXiv.2510.01365
-
[36]
T. Dao, D. Fu, S. Ermon, A. Rudra, C. Ré, FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Advances in Neural Information Processing Systems 35 (2022) 16344–16359
2022
-
[37]
H. Zhou, H. Wu, H. Shangguan, Y . Ma, H. Weng, J. Wang, M. Long, Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries (Feb. 2026). arXiv:2602.04940, doi:10.48550/arXiv.2602.04940
-
[38]
B. Alkin, T. Kronlachner, S. Papa, S. Pirker, T. Lichtenegger, J. Brandstetter, NeuralDEM – Real-time Simulation of Industrial Particulate Flows (Feb. 2025).arXiv:2411.09678,doi:10.48550/arXiv.2411.09678
-
[39]
Katharopoulos, A
A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret, Transformers are RNNs: Fast autoregressive transformers with linear attention, in: Proceedings of the 37th International Conference on Machine Learning, V ol. 119 of ICML’20, JMLR.org, 2020, pp. 5156–5165
2020
-
[40]
In: IEEE Winter Conference on Applications of Computer Vision (WACV)
S. Zhuoran, Z. Mingyuan, Z. Haiyu, Y . Shuai, L. Hongsheng, Efficient Attention: Attention with Linear Com- plexities, in: 2021 IEEE Winter Conference on Applications of Computer Vision (W ACV), 2021, pp. 3530–3538. doi:10.1109/WACV48630.2021.00357
-
[41]
T. C. Papanastasiou, Flows of materials with yield, J. Rheol. 31 (5) (1987) 385–404.doi:10.1122/1.549926
-
[42]
T. J. R. Hughes, L. P. Franca, M. Balestra, A new finite element formulation for computational fluid dynamics: V. Circumventing the babuška-brezzi condition: A stable Petrov-Galerkin formulation of the stokes problem accommodating equal-order interpolations, Computer Methods in Applied Mechanics and Engineering 59 (1) (1986) 85–99.doi:10.1016/0045-7825(86)90025-3
-
[43]
E. Oñate, S. R. Idelsohn, F. Del Pin, R. Aubry, The particle finite element method — an overview, Int. J. Comput. Methods 01 (02) (2004) 267–307.doi:10.1142/S0219876204000204
-
[44]
H. Edelsbrunner, E. P. Mücke, Three-dimensional alpha shapes, in: Proceedings of the 1992 Workshop on V olume Visualization, VVS ’92, Association for Computing Machinery, New York, NY , USA, 1992, pp. 75–82. doi:10.1145/147130.147153
-
[45]
S. Meduri, M. Cremonesi, U. Perego, An efficient runtime mesh smoothing technique for 3D explicit Lagrangian free-surface fluid flow simulations, International Journal for Numerical Methods in Engineering 117 (4) (2019) 430–452.doi:10.1002/nme.5962. 24 Attention mechanism for scalable mesh-based neural surrogates of free-surface fluids
-
[46]
H. Zhou, S. Cheng, Improving long-term autoregressive spatiotemporal predictions: A proof of concept with fluid dynamics, Computer Methods in Applied Mechanics and Engineering 447 (2025) 118332. doi:10.1016/j.cma. 2025.118332
-
[47]
McCabe, P
M. McCabe, P. Harrington, S. Subramanian, J. Brown, Towards Stability of Autoregressive Neural Operators, Transactions on Machine Learning Research (Jun. 2023)
2023
-
[48]
IEEE Transactions on Neural Networks20(1), 61–80 (2008)
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, G. Monfardini, The Graph Neural Network Model, IEEE Transactions on Neural Networks 20 (1) (2009) 61–80.doi:10.1109/TNN.2008.2005605
-
[49]
P. W. Battaglia, J. B. Hamrick, V . Bapst, A. Sanchez-Gonzalez, V . Zambaldi, M. Malinowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner, C. Gulcehre, F. Song, A. Ballard, J. Gilmer, G. Dahl, A. Vaswani, K. Allen, C. Nash, V . Langston, C. Dyer, N. Heess, D. Wierstra, P. Kohli, M. Botvinick, O. Vinyals, Y . Li, R. Pascanu, Relational inductive biases...
Pith/arXiv arXiv 2018
-
[51]
T. K. Rusch, M. M. Bronstein, S. Mishra, A Survey on Oversmoothing in Graph Neural Networks (Mar. 2023). arXiv:2303.10993,doi:10.48550/arXiv.2303.10993
-
[52]
Z. Li, N. B. Kovachki, C. Choy, B. Li, J. Kossaifi, S. P. Otta, M. A. Nabian, M. Stadler, C. Hundt, K. Azizzade- nesheli, A. Anandkumar, Geometry-informed neural operator for large-scale 3D PDEs, in: Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Curran Associates Inc., Red Hook, NY , USA, 2023, pp. 35...
2023
-
[53]
C. K. Joshi, Transformers are Graph Neural Networks (Jun. 2025). arXiv:2506.22084, doi:10.48550/arXiv. 2506.22084
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[54]
Cao, Choose a Transformer: Fourier or Galerkin, in: Advances in Neural Information Processing Systems, V ol
S. Cao, Choose a Transformer: Fourier or Galerkin, in: Advances in Neural Information Processing Systems, V ol. 34, Curran Associates, Inc., 2021, pp. 24924–24940
2021
-
[55]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, Y . Liu, RoFormer: Enhanced transformer with Rotary Position Embedding, Neurocomputing 568 (2024) 127063.doi:10.1016/j.neucom.2023.127063
-
[56]
FiLM: Visual Reasoning with a General Conditioning Layer
E. Perez, F. Strub, H. de Vries, V . Dumoulin, A. Courville, FiLM: Visual Reasoning with a General Conditioning Layer (Dec. 2017).arXiv:1709.07871,doi:10.48550/arXiv.1709.07871
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1709.07871 2017
-
[57]
G. Rizzieri, F. Lanteri, L. Ferrara, M. Cremonesi,ShapeGen3DCP: A deep learning framework for layer shape prediction in 3D concrete printing, Computers & Structures 323 (2026) 108142. doi:10.1016/j.compstruc. 2026.108142
-
[58]
S. Wen, A. Kumbhat, L. Lingsch, S. Mousavi, Y . Zhao, P. Chandrashekar, S. Mishra, Geometry Aware Operator Transformer as an efficient and accurate neural surrogate for PDEs on arbitrary domains, Advances in Neural Information Processing Systems 38 (2026) 155423–155501. 25
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.