Changing Modalities: Adapting Remote Sensing Models to New Satellites and Sensors
Pith reviewed 2026-06-26 09:12 UTC · model grok-4.3
The pith
DeluluNet trains remote sensing models on one set of sensors so they can still predict when sensors are swapped, added, or removed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
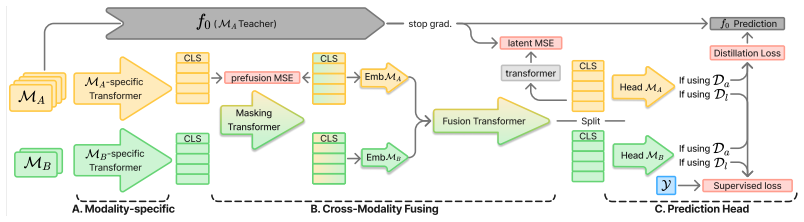
DeluluNet is an architecture with modular components for modality transfer, addition, and peeking; it is trained end-to-end by modality hallucination, in which missing-modality representations are predicted from the modalities that are present, using a unimodal teacher and unlabeled multimodal data, so that the model maintains prediction capability when input modalities change.
What carries the argument
Modality hallucination: the process of predicting representations for absent sensors from those that remain, learned from a unimodal teacher on unlabeled multimodal data.
If this is right
- A model trained on one satellite's sensors can be deployed on a replacement sensor without new labeled data.
- Additional sensors can be incorporated into an existing model by hallucinating their representations during inference.
- A model can operate on only a subset of its original sensors by hallucinating the missing ones.
- The same training procedure supplies a single set of weights usable across all three change scenarios.
Where Pith is reading between the lines
- The approach could lengthen the operational life of models trained on older satellite generations.
- It might reduce repeated data collection and labeling campaigns each time a sensor fleet is upgraded.
- The same hallucination training pattern could be tried on other multi-sensor domains such as medical imaging or autonomous driving.
Load-bearing premise
Representations produced by hallucination remain accurate enough that prediction performance does not drop sharply when modalities change.
What would settle it
A controlled test on held-out remote sensing data in which DeluluNet is evaluated on each of the three modality-change scenarios and accuracy falls by more than a small margin relative to a retrained baseline.
Figures


read the original abstract
Machine learning models for remote sensing are trained and deployed on a static set of modalities. However, as we equip newer satellites with novel sensors and retire old ones, practitioners may wish to deploy an existing model on a substitution, superset, or subset of modalities with minimal retraining given data availability or practical computational constraints. We study the setting of updating existing models to changing modalities and identify three main scenarios: Modality Transfer (substitution), Addition (superset), and Peeking (subset). We propose DeluluNet, an architecture with modular components for all three changing modality scenarios. DeluluNet is trained end-to-end, learning a multi-modal model from a unimodal teacher and unlabeled multimodal data via modality hallucination--predicting missing modality representations from those that are present. As a result, DeluluNet can keep predicting even when input modalities change, providing a practical alternative to re-labeling and re-training in a changing world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeluluNet, a modular architecture for adapting remote sensing models to changing input modalities without full retraining. It identifies three scenarios—Modality Transfer (substitution), Addition (superset), and Peeking (subset)—and trains the model end-to-end via modality hallucination, using a unimodal teacher and unlabeled multimodal data to predict missing modality representations.
Significance. If the central claims hold with supporting evidence, the work would address a practical deployment challenge in remote sensing where satellites and sensors evolve over time. By framing the problem around three concrete scenarios and proposing a hallucination-based alternative to re-labeling, it could reduce computational and data costs for model updates.
major comments (2)
- [Abstract] Abstract: The practicality claim—that DeluluNet provides an alternative to re-training when modalities change—depends on the availability of unlabeled multimodal data with co-occurring samples from old and new modalities to learn the hallucinator. For novel sensors on new satellites (where legacy satellites may be retired), such paired data often does not exist, and no zero-shot mechanism for unseen sensor distributions is described.
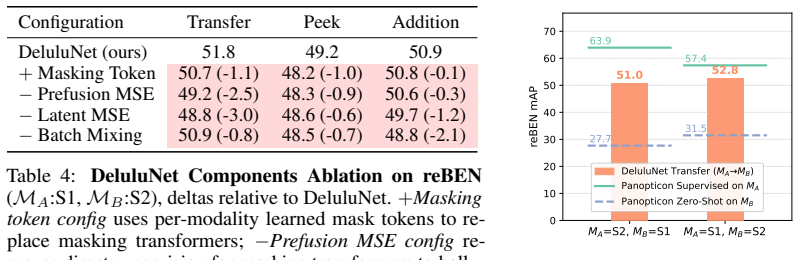
- [Abstract] Abstract: The assertion that modality hallucination 'can keep predicting even when input modalities change' without large performance drops is presented as a result, yet the provided text contains no experimental results, ablation studies, or quantitative metrics across the three scenarios to verify that the learned representations support effective downstream prediction.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript and providing these insightful comments. We address each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The practicality claim—that DeluluNet provides an alternative to re-training when modalities change—depends on the availability of unlabeled multimodal data with co-occurring samples from old and new modalities to learn the hallucinator. For novel sensors on new satellites (where legacy satellites may be retired), such paired data often does not exist, and no zero-shot mechanism for unseen sensor distributions is described.
Authors: We concur that the proposed approach presupposes the existence of unlabeled multimodal data containing co-occurring samples from both the original and new modalities. This data is necessary to train the modality hallucinator. Our work focuses on the practical setting where such data can be acquired during periods of sensor transition. We do not propose or evaluate a zero-shot approach for entirely novel sensor distributions without any paired samples, which remains an open challenge. In the revised version, we will explicitly articulate this assumption in the abstract and add a discussion of this limitation. revision: partial
-
Referee: [Abstract] Abstract: The assertion that modality hallucination 'can keep predicting even when input modalities change' without large performance drops is presented as a result, yet the provided text contains no experimental results, ablation studies, or quantitative metrics across the three scenarios to verify that the learned representations support effective downstream prediction.
Authors: The manuscript body contains the experimental section with results, ablations, and metrics for the three scenarios. The abstract condenses these outcomes. To improve clarity, we will revise the abstract to incorporate key quantitative findings, such as the observed performance metrics under modality changes. revision: yes
Circularity Check
No circularity detected in DeluluNet derivation
full rationale
The paper introduces DeluluNet as a new modular architecture trained end-to-end via modality hallucination from a unimodal teacher and unlabeled multimodal data. This supports the three scenarios (transfer, addition, peeking) through the described training procedure without any load-bearing steps that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claim of providing a practical alternative to re-labeling remains independent of its inputs and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DeluluNet
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Omnisat: Self- supervised modality fusion for earth observation
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. Omnisat: Self- supervised modality fusion for earth observation. InEuropean Conference on Computer Vision, pages 409–427. Springer, 2024
2024
-
[2]
Mixmatch: A holistic approach to semi-supervised learning.Advances in neural information processing systems, 32, 2019
David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning.Advances in neural information processing systems, 32, 2019
2019
-
[3]
Combining labeled and unlabeled data with co-training
Avrim Blum and Tom Mitchell. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, COLT’ 98, page 92–100, New York, NY , USA, 1998. Association for Computing Machinery. ISBN 1581130570. doi: 10.1145/279943.279962
-
[4]
Cristian Bucila, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. volume 2006, pages 535–541, 08 2006. doi: 10.1145/1150402.1150464
-
[5]
Bootstrapping chest ct image understanding by distilling knowledge from x-ray expert models
Weiwei Cao, Jianpeng Zhang, Yingda Xia, Tony CW Mok, Zi Li, Xianghua Ye, Le Lu, Jian Zheng, Yuxing Tang, and Ling Zhang. Bootstrapping chest ct image understanding by distilling knowledge from x-ray expert models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11238–11247, 2024
2024
-
[6]
Curriculum labeling: Revisiting pseudo-labeling for semi-supervised learning
Paola Cascante-Bonilla, Fuwen Tan, Yanjun Qi, and Vicente Ordonez. Curriculum labeling: Revisiting pseudo-labeling for semi-supervised learning. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 6912–6920, 2021
2021
-
[7]
reben: Refined bigearthnet dataset for remote sensing image analysis
Kai Norman Clasen, Leonard Hackel, Tom Burgert, Gencer Sumbul, Begüm Demir, and V olker Markl. reben: Refined bigearthnet dataset for remote sensing image analysis. InIGARSS 2025-2025 IEEE International Geoscience and Remote Sensing Symposium, pages 1264–1268. IEEE, 2025
2025
-
[8]
Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery.Advances in Neural Information Processing Systems, 35: 197–211, 2022
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David Lobell, and Stefano Ermon. Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery.Advances in Neural Information Processing Systems, 35: 197–211, 2022
2022
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[10]
M. Drusch, U. Del Bello, S. Carlier, O. Colin, V . Fernandez, F. Gascon, B. Hoersch, C. Isola, P. Laberinti, P. Martimort, A. Meygret, F. Spoto, O. Sy, F. Marchese, and P. Bargellini. Sentinel- 2: Esa’s optical high-resolution mission for gmes operational services.Remote Sensing of Environment, 120:25–36, 2012. ISSN 0034-4257. doi: https://doi.org/10.1016...
-
[11]
URL https://www.esa.int/Applications/Observing_the_Earth/ Copernicus/Free_access_to_Copernicus_Sentinel_satellite_data
ESA, 2013. URL https://www.esa.int/Applications/Observing_the_Earth/ Copernicus/Free_access_to_Copernicus_Sentinel_satellite_data. Accessed: 2026-02-04. 10
2013
-
[12]
Tessera: Temporal embeddings of surface spectra for earth representation and analysis, 2025
Zhengpeng Feng et al. Tessera: Temporal embeddings of surface spectra for earth representation and analysis, 2025. URLhttps://arxiv.org/abs/2506.20380
Pith/arXiv arXiv 2025
-
[13]
Clay foundation model, 2025
Clay Foundation. Clay foundation model, 2025. URL https://clay-foundation.github. io/model/index.html. Accessed: 2025-07-21
2025
-
[14]
Croma: Remote sensing representations with contrastive radar-optical masked autoencoders.Advances in Neural Information Processing Systems, 36:5506–5538, 2023
Anthony Fuller, Koreen Millard, and James Green. Croma: Remote sensing representations with contrastive radar-optical masked autoencoders.Advances in Neural Information Processing Systems, 36:5506–5538, 2023
2023
-
[15]
Domain-adversarial training of neural networks
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario March, and Victor Lempitsky. Domain-adversarial training of neural networks. Journal of machine learning research, 17(59):1–35, 2016
2016
-
[16]
Goward, Laura E
Samuel N. Goward, Laura E. P. Rocchio, Darrel L. Williams, Terry Arvidson, James R. Irons, Carol A. Russell, and Shaida S. Johnston. Landsat’s enduring legacy: Pioneering global land observations from space.Photogrammetric Engineering and Remote Sensing, 84:9–10, 2017. URLhttps://api.semanticscholar.org/CorpusID:134711498
2017
-
[17]
Semi-supervised learning by entropy minimization
Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In L. Saul, Y . Weiss, and L. Bottou, editors,Advances in Neural Information Processing Systems, volume 17. MIT Press, 2004. URL https://proceedings.neurips.cc/paper_files/ paper/2004/file/96f2b50b5d3613adf9c27049b2a888c7-Paper.pdf
2004
-
[18]
Cross modal distillation for supervision transfer
Saurabh Gupta, Judy Hoffman, and Jitendra Malik. Cross modal distillation for supervision transfer. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2827–2836, 2016
2016
-
[19]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[20]
Modality-incremental learning with disjoint relevance mapping networks for image-based semantic segmentation
Niharika Hegde, Shishir Muralidhara, René Schuster, and Didier Stricker. Modality-incremental learning with disjoint relevance mapping networks for image-based semantic segmentation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5540–5549. IEEE, 2025
2025
-
[21]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
2019
-
[22]
A comprehensive overhaul of feature distillation
Byeongho Heo, Jeesoo Kim, Sangdoo Yun, Hyojin Park, Nojun Kwak, and Jin Young Choi. A comprehensive overhaul of feature distillation. InProceedings of the IEEE/CVF international conference on computer vision, pages 1921–1930, 2019
1921
-
[23]
Olmoearth: Stable latent image modeling for multimodal earth observation, 2025
Henry Herzog, Favyen Bastani, Yawen Zhang, Gabriel Tseng, Joseph Redmon, Hadrien Sablon, Ryan Park, Jacob Morrison, Alexandra Buraczynski, Karen Farley, Joshua Hansen, Andrew Howe, Patrick Alan Johnson, Mark Otterlee, Ted Schmitt, Hunter Pitelka, Stephen Daspit, Rachel Ratner, Christopher Wilhelm, Sebastian Wood, Mike Jacobi, Hannah Kerner, Evan Shelhamer...
2025
-
[24]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[25]
Antoine Labatie, Michael Vaccaro, Nina Lardiere, Anatol Garioud, and Nicolas Gonthier. Mae- stro: Masked autoencoders for multimodal, multitemporal, and multispectral earth observation data, 2025. URLhttps://arxiv.org/abs/2508.10894
arXiv 2025
-
[26]
Geo-bench: Toward foundation models for earth monitoring.Advances in Neural Information Processing Systems, 36:51080–51093, 2023
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. Geo-bench: Toward foundation models for earth monitoring.Advances in Neural Information Processing Systems, 36:51080–51093, 2023. 11
2023
-
[27]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InWorkshop on challenges in representation learning, ICML, 2013
2013
-
[28]
Stefan Lee, Senthil Purushwalkam, Michael Cogswell, David Crandall, and Dhruv Batra. Why m heads are better than one: Training a diverse ensemble of deep networks.arXiv preprint arXiv:1511.06314, 2015
Pith/arXiv arXiv 2015
-
[29]
Rethinking the stability-plasticity trade- off in continual learning from an architectural perspective
Aojun Lu, Hangjie Yuan, Tao Feng, and Yanan Sun. Rethinking the stability-plasticity trade- off in continual learning from an architectural perspective. InForty-second International Conference on Machine Learning, 2025
2025
-
[30]
Schutz, Benjamin Smith, Yuekui Yang, and Jay Zwally
Thorsten Markus, Tom Neumann, Anthony Martino, Waleed Abdalati, Kelly Brunt, Beata Csatho, Sinead Farrell, Helen Fricker, Alex Gardner, David Harding, Michael Jasinski, Ron Kwok, Lori Magruder, Dan Lubin, Scott Luthcke, James Morison, Ross Nelson, Amy Neuenschwander, Stephen Palm, Sorin Popescu, CK Shum, Bob E. Schutz, Benjamin Smith, Yuekui Yang, and Jay...
-
[31]
Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist net- works: The sequential learning problem. In Gordon H. Bower, editor,Psychology of Learn- ing and Motivation, volume 24 ofPsychology of Learning and Motivation, pages 109–
-
[32]
Academic Press, 1989. doi: https://doi.org/10.1016/S0079-7421(08)60536-8. URL https://www.sciencedirect.com/science/article/pii/S0079742108605368
-
[33]
4m: Massively multimodal masked modeling.Advances in Neural Information Processing Systems, 36:58363–58408, 2023
David Mizrahi, Roman Bachmann, Oguzhan Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, and Amir Zamir. 4m: Massively multimodal masked modeling.Advances in Neural Information Processing Systems, 36:58363–58408, 2023
2023
-
[34]
Hyperspectral imaging technologies, 2019
NRC. Hyperspectral imaging technologies, 2019. URL https://nrc.canada.ca/ en/research-development/products-services/technical-advisory-services/ hyperspectral-imaging-technologies. Accessed: 2026-02-04
2019
-
[35]
xview3-sar: Detecting dark fishing activity using synthetic aperture radar imagery.Advances in Neural Information Processing Systems, 35: 37604–37616, 2022
Fernando Paolo, Tsu-ting Tim Lin, Ritwik Gupta, Bryce Goodman, Nirav Patel, Daniel Kuster, David Kroodsma, and Jared Dunnmon. xview3-sar: Detecting dark fishing activity using synthetic aperture radar imagery.Advances in Neural Information Processing Systems, 35: 37604–37616, 2022
2022
-
[36]
Teacher-student domain adaptation for biosensor models.ICLR, 2020
Lawrence G Phillips, David B Grimes, and Yihan Jessie Li. Teacher-student domain adaptation for biosensor models.ICLR, 2020
2020
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[38]
Shreelekha Revankar, Utkarsh Mall, Cheng Perng Phoo, Kavita Bala, and Bharath Hariharan. Monitrs: Multimodal observations of natural incidents through remote sensing.arXiv preprint arXiv:2507.16228, 2025
arXiv 2025
-
[39]
Caleb Robinson, Kolya Malkin, Nebojsa Jojic, Huijun Chen, Rongjun Qin, Changlin Xiao, Michael Schmitt, Pedram Ghamisi, Ronny Hänsch, and Naoto Yokoya. Global land-cover mapping with weak supervision: Outcome of the 2020 ieee grss data fusion contest.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 14:3185–3199,
2020
-
[40]
doi: 10.1109/JSTARS.2021.3063849
-
[41]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
Pith/arXiv arXiv 2025
-
[42]
Naomi Simumba, Nils Lehmann, Paolo Fraccaro, Hamed Alemohammad, Geeth De Mel, Salman Khan, Manil Maskey, Nicolas Longepe, Xiao Xiang Zhu, Hannah Kerner, et al. Geo- bench-2: From performance to capability, rethinking evaluation in geospatial ai.arXiv preprint arXiv:2511.15658, 2025
arXiv 2025
-
[43]
Fixmatch: Simplifying semi- supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raf- fel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi- supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
2020
-
[44]
Gencer Sumbul, Marcela Charfuelan, Begüm Demir, and V olker Markl. Bigearthnet: A large-scale benchmark archive for remote sensing image understanding.arXiv preprint arXiv:1902.06148, 2019
arXiv 1902
-
[45]
Deep coral: Correlation alignment for deep domain adaptation
Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. InEuropean conference on computer vision, pages 443–450. Springer, 2016
2016
-
[46]
Geocrossbench: Cross-band generalization for remote sensing.arXiv preprint arXiv:2511.02831, 2025
Hakob Tamazyan, Ani Vanyan, Alvard Barseghyan, Anna Khosrovyan, Evan Shelhamer, and Hrant Khachatrian. Geocrossbench: Cross-band generalization for remote sensing.arXiv preprint arXiv:2511.02831, 2025
arXiv 2025
-
[47]
Galileo: Learning global & local features of many remote sensing modalities
Gabriel Tseng, Anthony Fuller, Marlena Reil, Henry Herzog, Patrick Beukema, Favyen Bastani, James R Green, Evan Shelhamer, Hannah Kerner, and David Rolnick. Galileo: Learning global & local features of many remote sensing modalities. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Z...
2025
-
[48]
Galileo: Learning global & local features of many remote sensing modalities
Gabriel Tseng, Anthony Fuller, Marlena Reil, Henry Herzog, Patrick Beukema, Favyen Bastani, James R Green, Evan Shelhamer, Hannah Kerner, and David Rolnick. Galileo: Learning global & local features of many remote sensing modalities. InInternational Conference on Machine Learning, pages 60280–60300. PMLR, 2025
2025
-
[49]
Three types of incremental learning.Nature Machine Intelligence, 4(12):1185–1197, 2022
Gido M Van de Ven, Tinne Tuytelaars, and Andreas S Tolias. Three types of incremental learning.Nature Machine Intelligence, 4(12):1185–1197, 2022
2022
-
[50]
Panopticon: Advancing any-sensor foundation models for earth observation
Leonard Waldmann, Ando Shah, Yi Wang, Nils Lehmann, Adam Stewart, Zhitong Xiong, Xiao Xiang Zhu, Stefan Bauer, and John Chuang. Panopticon: Advancing any-sensor foundation models for earth observation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2204–2214, 2025
2025
-
[51]
Freematch: Self-adaptive thresholding for semi-supervised learning
Yidong Wang, Hao Chen, Qiang Heng, Wenxin Hou, Yue Fan, Zhen Wu, Jindong Wang, Marios Savvides, Takahiro Shinozaki, Bhiksha Raj, et al. Freematch: Self-adaptive thresholding for semi-supervised learning. InEleventh International Conference on Learning Representations. OpenReview. net, 2023
2023
-
[52]
Zhitong Xiong, Yi Wang, Fahong Zhang, Adam J Stewart, Joëlle Hanna, Damian Borth, Ioannis Papoutsis, Bertrand Le Saux, Gustau Camps-Valls, and Xiao Xiang Zhu. Neural plasticity- inspired multimodal foundation model for earth observation.arXiv preprint arXiv:2403.15356, 2024
arXiv 2024
-
[53]
One for all: Toward unified foundation models for earth vision
Zhitong Xiong, Yi Wang, Fahong Zhang, and Xiao Xiang Zhu. One for all: Toward unified foundation models for earth vision. InIGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Symposium, pages 2734–2738, 2024. doi: 10.1109/IGARSS53475.2024. 10641637
-
[54]
Multimodal knowledge expansion
Zihui Xue, Sucheng Ren, Zhengqi Gao, and Hang Zhao. Multimodal knowledge expansion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 854–863, 2021
2021
-
[55]
mixup: Beyond empirical risk minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. InInternational Conference on Learning Representations, 2018. 13
2018
-
[56]
Skysense v2: A unified foundation model for multi-modal remote sensing
Yingying Zhang, Lixiang Ru, Kang Wu, Lei Yu, Lei Liang, Yansheng Li, and Jingdong Chen. Skysense v2: A unified foundation model for multi-modal remote sensing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9136–9146, 2025
2025
-
[57]
Through-wall human pose estimation using radio signals
Mingmin Zhao, Tianhong Li, Mohammad Abu Alsheikh, Yonglong Tian, Hang Zhao, Antonio Torralba, and Dina Katabi. Through-wall human pose estimation using radio signals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
2018
-
[58]
Knowledge distillation based on transformed teacher matching.arXiv preprint arXiv:2402.11148, 2024
Kaixiang Zheng and En-Hui Yang. Knowledge distillation based on transformed teacher matching.arXiv preprint arXiv:2402.11148, 2024
arXiv 2024
-
[59]
Unidistill: A universal cross-modality knowledge distillation framework for 3d object detection in bird’s-eye view
Shengchao Zhou, Weizhou Liu, Chen Hu, Shuchang Zhou, and Chao Ma. Unidistill: A universal cross-modality knowledge distillation framework for 3d object detection in bird’s-eye view. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5116–5125, 2023
2023
-
[60]
agreement
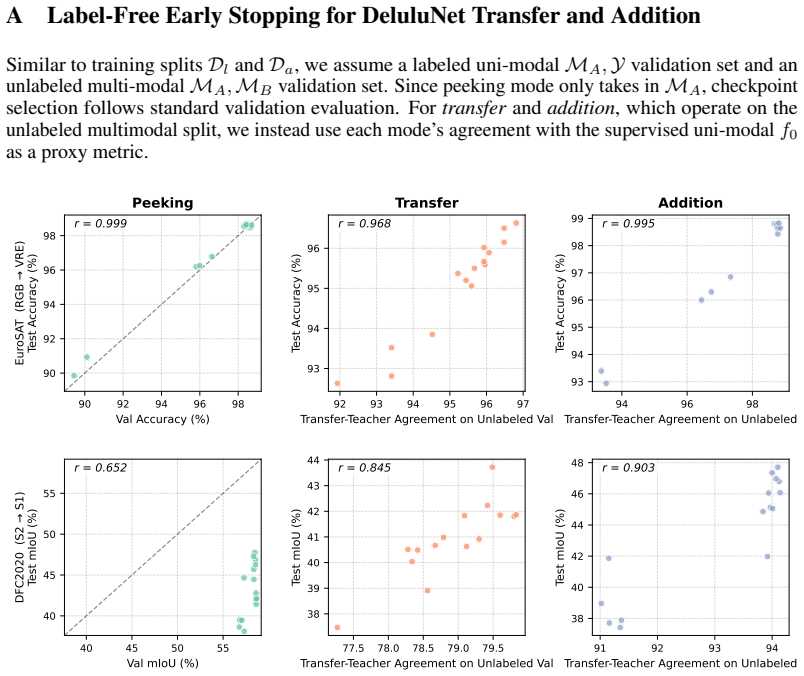
Tim G Zhou, Evan Shelhamer, and Geoff Pleiss. Asymmetric duos: Sidekicks improve uncertainty. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 14 A Label-Free Early Stopping for DeluluNet Transfer and Addition Similar to training splits Dl and Da, we assume a labeled uni-modal MA,Y validation set and an unlabeled multi-...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.