LightSTAR: Efficient Visual Document Retrieval via Lightweight Selection with Vision-Adaptive Refinement
Pith reviewed 2026-06-26 08:41 UTC · model grok-4.3
The pith
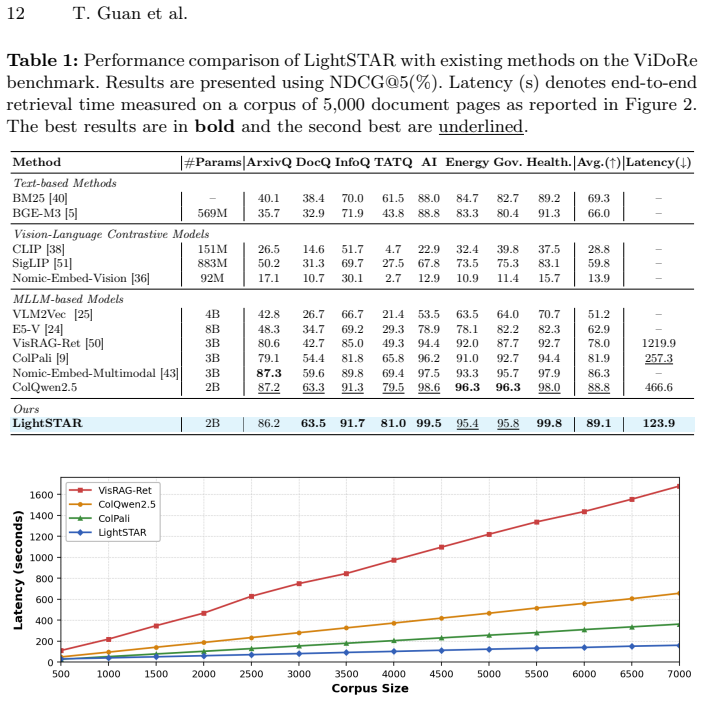
LightSTAR splits visual document retrieval into fast keyword-based candidate selection and targeted refinement to deliver top accuracy at several-fold lower latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
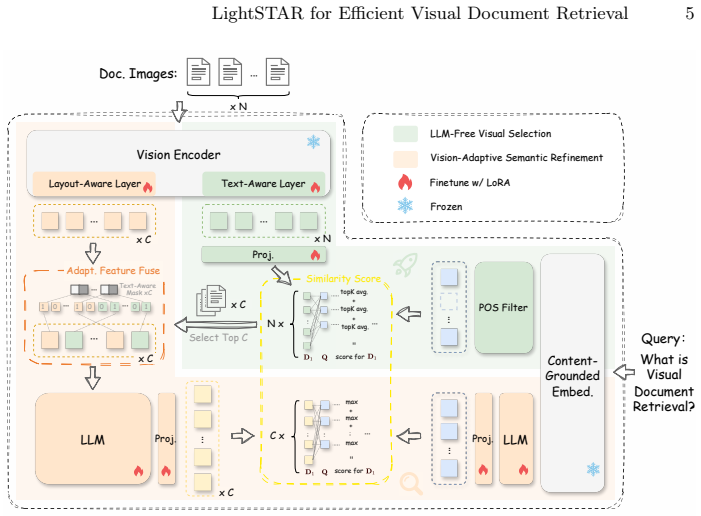
LightSTAR decomposes visual document retrieval into an LLM-free Visual Selection stage, which applies content-grounded query encoding and LLM-free visual embeddings to produce a high-recall candidate set, followed by a Vision-adaptive Semantic Refinement stage that performs fine-grained semantic matching exclusively on those candidates through adaptive region-wise feature fusion and a hardness-aware contrastive objective. This yields state-of-the-art retrieval accuracy while reducing end-to-end latency by several-fold.
What carries the argument
Two-stage pipeline of LLM-free Visual Selection for rapid high-recall filtering followed by Vision-adaptive Semantic Refinement using adaptive region-wise feature fusion on the selected candidates only.
If this is right
- The selection stage can filter thousands of pages using only lightweight embeddings without invoking heavy models on every page.
- Restricting the refinement stage to a small candidate set directly lowers total computation while preserving accuracy.
- Adaptive region-wise fusion of textual and layout cues improves matching quality beyond uniform page-level features.
- The hardness-aware contrastive objective focuses training on difficult negatives to raise final ranking precision.
Where Pith is reading between the lines
- The same lightweight-first decomposition could apply to other large-scale multi-modal search settings where initial keyword signals exist.
- If the selection stage maintains high recall at scale, the approach would make retrieval feasible over corpora orders of magnitude larger than current MLLM-only pipelines allow.
- Designers of document systems might deliberately encourage queries that contain distinctive visible words to maximize the efficiency gain.
- Replacing the visual encoder in the selection stage with even lighter alternatives could be tested without retraining the refinement stage.
Load-bearing premise
User queries are typically keyword-anchored, with semantically rich words expected to appear directly in the visible text of relevant pages.
What would settle it
Measure recall of the LLM-free selection stage on a test set where all queries have been rewritten to avoid direct lexical overlap with the text of their ground-truth pages.
Figures
read the original abstract
Visual document retrieval requires rapidly locating relevant pages from large multi-modal corpora in response to user queries. While recent methods powered by Multi-modal Large Language Models (MLLMs) show competitive accuracy, they suffer from prohibitive computational costs by applying intensive MLLM encoding to every single page. Meanwhile, we observe that user queries are typically keyword-anchored, containing semantically rich words that are expected to appear directly in the visible text of relevant pages, offering an efficient cue for quickly narrowing down candidate pages. Building on this insight, we propose LightSTAR, an efficient framework that decomposes visual document retrieval into: 1) LLM-free Visual Selection, which utilizes content-grounded query encoding to focus on informative words and employs LLM-free visual embeddings to produce a high-recall candidate set; and 2) Vision-adaptive Semantic Refinement, which further performs fine-grained semantic matching exclusively on these top candidates via adaptive region-wise feature fusion to effectively combine textual and layout cues, optimized through a hardness-aware contrastive objective. Experimental results demonstrate that LightSTAR achieves state-of-the-art retrieval accuracy while reducing end-to-end latency by several-fold, offering a highly practical solution to the accuracy-efficiency trade-off in visual document retrieval. Code is available at https://github.com/bokufa/LightSTAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LightSTAR, a two-stage framework for visual document retrieval from large multi-modal corpora. It decomposes the task into (1) an LLM-free Visual Selection stage that uses content-grounded query encoding to identify informative words and produce a high-recall candidate set via visual embeddings, leveraging the observation that queries are typically keyword-anchored with direct lexical overlap in relevant page text, and (2) a Vision-adaptive Semantic Refinement stage that performs fine-grained matching on the top candidates using adaptive region-wise feature fusion of textual and layout cues, trained with a hardness-aware contrastive objective. Experiments claim state-of-the-art retrieval accuracy with several-fold end-to-end latency reduction compared to full MLLM baselines; code is released.
Significance. If the accuracy and latency claims are supported by the experiments, the work addresses a practical accuracy-efficiency trade-off in visual document retrieval by avoiding full-page MLLM encoding on all candidates. The code release supports reproducibility. The approach is grounded in an observable property of queries rather than purely learned parameters.
major comments (2)
- [Abstract, §3.1] Abstract and §3.1 (LLM-free Visual Selection): The high-recall guarantee of the candidate selection stage is load-bearing for the overall latency claim and rests on the premise that 'user queries are typically keyword-anchored, containing semantically rich words that are expected to appear directly in the visible text of relevant pages.' No quantitative analysis (e.g., fraction of queries exhibiting sufficient lexical overlap, performance breakdown on paraphrased vs. keyword queries, or coverage statistics on the evaluation datasets) is provided to establish how often this assumption holds; if it fails on a non-trivial subset, the refinement stage alone cannot recover SOTA accuracy without reintroducing full MLLM costs.
- [§4] §4 (Experiments): The manuscript reports SOTA accuracy and latency gains, but without access to the full experimental details, baselines, ablations, or error analysis in the provided text, it is not possible to verify whether the gains are robust or whether they depend on the keyword-anchored assumption holding in the test sets. A dedicated ablation or query-type breakdown is needed to substantiate the central claim.
minor comments (2)
- [§3.2] Notation for the adaptive region-wise fusion and hardness-aware contrastive loss should be introduced with explicit equations rather than prose descriptions to improve clarity.
- [Figures] Figure captions and axis labels in the latency-accuracy plots should explicitly state the datasets and metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate additional analysis as outlined.
read point-by-point responses
-
Referee: [Abstract, §3.1] Abstract and §3.1 (LLM-free Visual Selection): The high-recall guarantee of the candidate selection stage is load-bearing for the overall latency claim and rests on the premise that 'user queries are typically keyword-anchored, containing semantically rich words that are expected to appear directly in the visible text of relevant pages.' No quantitative analysis (e.g., fraction of queries exhibiting sufficient lexical overlap, performance breakdown on paraphrased vs. keyword queries, or coverage statistics on the evaluation datasets) is provided to establish how often this assumption holds; if it fails on a non-trivial subset, the refinement stage alone cannot recover SOTA accuracy without reintroducing full MLLM costs.
Authors: We agree that a quantitative characterization of the keyword-anchored assumption would strengthen the central claim. The current manuscript presents the observation as motivation but does not report explicit statistics on lexical overlap or query-type breakdowns. In the revision we will add a dedicated subsection (likely in §3 or §4) that measures (i) the fraction of queries exhibiting direct lexical overlap with relevant page text, (ii) coverage statistics on the evaluation datasets, and (iii) retrieval performance stratified by keyword-anchored versus paraphrased queries. This analysis will be performed on the same test sets used for the main results. revision: yes
-
Referee: [§4] §4 (Experiments): The manuscript reports SOTA accuracy and latency gains, but without access to the full experimental details, baselines, ablations, or error analysis in the provided text, it is not possible to verify whether the gains are robust or whether they depend on the keyword-anchored assumption holding in the test sets. A dedicated ablation or query-type breakdown is needed to substantiate the central claim.
Authors: The complete manuscript already contains the full experimental protocol, baselines, and main ablations; however, it does not yet include an explicit query-type breakdown. We will add this breakdown (keyword-anchored vs. paraphrased queries) together with an ablation that isolates the contribution of the selection stage under varying degrees of lexical overlap. These additions will directly address whether the reported accuracy and latency gains remain robust when the assumption holds only partially. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical framework grounded in an external observation about keyword-anchored queries, decomposed into LLM-free selection and vision-adaptive refinement stages, with performance claims supported by experimental results on retrieval accuracy and latency. No equations, self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text that would reduce any claimed result to its inputs by construction. The method is self-contained against external benchmarks via reported experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User queries are typically keyword-anchored, containing semantically rich words that are expected to appear directly in the visible text of relevant pages.
Reference graph
Works this paper leans on
-
[1]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., Ring, R., Rutherford, E., Cabi, S., Han, T., Gong, Z., Samangooei, S., Monteiro, M., Menick, J.L., Borgeaud, S., Brock, A., Nematzadeh, A., Sharifzadeh, S., Bińkowski, M.a., Barreira, R., Vinyals, O., Zisser- man, A., Simonyan, K.: Fla...
2022
-
[2]
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond (2023),https://arxiv.org/abs/2308.12966
Pith/arXiv arXiv 2023
-
[3]
Beyer, L., Steiner, A., Pinto, A.S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., Unterthiner, T., Keysers, D., Koppula, S., Liu, F., Grycner, A., Gritsenko, A., Houlsby, N., Kumar, M., Rong, K., Eisenschlos, J., Kabra, R., Bauer, M., Bošnjak, M., Chen, X., Minderer, M., Voigtlaender, P., Bica, I., Ba...
Pith/arXiv arXiv 2024
-
[4]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A....
1901
-
[5]
Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., Liu, Z.: M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embeddings through self- knowledge distillation. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Findings of the Association for Computational Linguistics: ACL 2024. pp. 2318–2335. As- sociation for Computational Linguisti...
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24185–24198 (2024)
2024
-
[7]
In: Koyejo, S., Mohamed, S., Agar- wal, A., Belgrave, D., Cho, K., Oh, A
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. In: Koyejo, S., Mohamed, S., Agar- wal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Informa- tion Processing Systems. vol. 35, pp. 16344–16359. Curran Associates, Inc. (2022),https : / / proceedings . neurips . cc / ...
2022
-
[8]
Guan et al
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: 16 T. Guan et al. An image is worth 16x16 words: Transformers for image recognition at scale. In: In- ternational Conference on Learning Representations (2021),https://openreview. net/forum...
2021
-
[9]
In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R
Faysse, M., Sibille, H., Wu, T., Omrani, B., Viaud, G., HUDELOT, C., Colombo, P.: Colpali: Efficient document retrieval with vision language models. In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R. (eds.) International Conference on Learn- ing Representations. vol. 2025, pp. 61424–61449 (2025),https://proceedings. iclr.cc/paper_files/paper/2025/file/99e9e...
2025
-
[10]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Fu, P., Guan, T., Wang, Z., Guo, Z., Duan, C., Sun, H., Chen, B., Jiang, Q., Ma, J., Zhou, K., Luo, J.: Multimodal large language models for text-rich image understanding: A comprehensive review. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Findings of the Association for Computational Linguistics: ACL 2025. pp. 19941–19958 (2025)
2025
-
[11]
arXiv preprint arXiv:2410.16261 (2024)
Gao, Z., Chen, Z., Cui, E., Ren, Y., Wang, W., Zhu, J., Tian, H., Ye, S., He, J., Zhu, X., et al.: Mini-internvl: A flexible-transfer pocket multimodal model with 5% parameters and 90% performance. arXiv preprint arXiv:2410.16261 (2024)
arXiv 2024
-
[12]
IEEE Transactions on Circuits and Systems for Video Technology32(9), 6073–6085 (2022)
Guan, T., Gu, C., Lu, C., Tu, J., Feng, Q., Wu, K., Guan, X.: Industrial scene text detection with refined feature-attentive network. IEEE Transactions on Circuits and Systems for Video Technology32(9), 6073–6085 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guan, T., Gu, C., Tu, J., Yang, X., Feng, Q., Zhao, Y., Shen, W.: Self-supervised implicit glyph attention for text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15285– 15294 (June 2023)
2023
-
[14]
In: CVPR
Guan, T., Gu, C., Tu, J., Yang, X., Feng, Q., Zhao, Y., Shen, W.: Self-supervised implicit glyph attention for text recognition. In: CVPR. pp. 15285–15294 (2023)
2023
-
[15]
Guan,T.,Lin,C.,Shen,W.,Yang,X.:Posformer:recognizingcomplexhandwritten mathematicalexpressionwithpositionforesttransformer.In:EuropeanConference on Computer Vision. pp. 130–147. Springer (2025)
2025
-
[16]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Guan, T., Shen, W., Yang, X.: CCDPlus: Towards accurate character to charac- ter distillation for text recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Guan, T., Shen, W., Yang, X., Feng, Q., Jiang, Z., Yang, X.: Self-supervised character-to-character distillation for text recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19473–19484 (2023)
2023
-
[18]
In: European Conference on Computer Vision
Guan, T., Shen, W., Yang, X., Wang, X., Yang, X.: Bridging synthetic and real worlds for pre-training scene text detectors. In: European Conference on Computer Vision. pp. 428–446. Springer (2024)
2024
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Guan, T., Wang, Z., Fu, P., Guo, Z., Shen, W., Zhou, K., Yue, T., Duan, C., Sun, H., Jiang, Q., et al.: A token-level text image foundation model for docu- ment understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23210–23220 (2025)
2025
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guan, T., Yang, Z., Wan, J., Yang, M., Guo, Z., Hu, Z., Luo, R., Chen, R., Jiang, S., Wang, P., et al.: Codepercept: Code-grounded visual stem perception for mllms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 33542–33552 (2026)
2026
-
[21]
Günther, M., Sturua, S., Akram, M.K., Mohr, I., Ungureanu, A., Wang, B., Es- lami, S., Martens, S., Werk, M., Wang, N., Xiao, H.: jina-embeddings-v4: Uni- versal embeddings for multimodal multilingual retrieval. In: Adelani, D.I., Ar- nett, C., Ataman, D., Chang, T.A., Gonen, H., Raja, R., Schmidt, F., Stap, D., LightSTAR for Efficient Visual Document Ret...
-
[22]
Guo, J., Xu, G., Cheng, X., Li, H.: Named entity recognition in query. In: Proceed- ings of the 32nd International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval. p. 267–274. SIGIR ’09, Association for Computing Machinery, New York, NY, USA (2009).https://doi.org/10.1145/1571941. 1571989,https://doi.org/10.1145/1571941.1571989
-
[23]
In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= nZeVKeeFYf9
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= nZeVKeeFYf9
2022
-
[24]
Jiang, T., Song, M., Zhang, Z., Huang, H., Deng, W., Sun, F., Zhang, Q., Wang, D., Zhuang, F.: E5-v: Universal embeddings with multimodal large language models (2024),https://arxiv.org/abs/2407.12580
Pith/arXiv arXiv 2024
-
[25]
In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=TE0KOzWYAF
Jiang, Z., Meng, R., Yang, X., Yavuz, S., Zhou, Y., Chen, W.: VLM2vec: Train- ing vision-language models for massive multimodal embedding tasks. In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=TE0KOzWYAF
2025
-
[26]
Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D.: Scaling laws for neural language models (2020),https://arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2020
-
[27]
Khattab, O., Zaharia, M.: Colbert: Efficient and effective passage search via con- textualized late interaction over BERT. In: Huang, J.X., Chang, Y., Cheng, X., Kamps, J., Murdock, V., Wen, J., Liu, Y. (eds.) Proceedings of the 43rd Inter- national ACM SIGIR conference on research and development in Information Re- trieval, SIGIR 2020, Virtual Event, Chi...
-
[28]
In: Computer Vision – ECCV 2022
Kim, G., Hong, T., Yim, M., Nam, J., Park, J., Yim, J., Hwang, W., Yun, S., Han, D., Park, S.: Ocr-free document understanding transformer. In: Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVIII. p. 498–517. Springer-Verlag, Berlin, Heidelberg (2022). https://doi.org/10.1007/978-3-031-198...
-
[29]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[30]
In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J
Lee, K., Joshi, M., Turc, I.R., Hu, H., Liu, F., Eisenschlos, J.M., Khandelwal, U., Shaw, P., Chang, M.W., Toutanova, K.: Pix2Struct: Screenshot parsing as pre- training for visual language understanding. In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J. (eds.) Proceedings of the 40th Inter- national Conference on Machine Le...
2023
-
[31]
In: Larochelle, H., Ran- zato, M., Hadsell, R., Balcan, M., Lin, H
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küt- tler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval- augmented generation for knowledge-intensive nlp tasks. In: Larochelle, H., Ran- zato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Infor- 18 T. Guan et al. mation Processing Sys...
2020
-
[32]
In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S
Li, J., Li, D., Xiong, C., Hoi, S.: BLIP: Bootstrapping language-image pre- training for unified vision-language understanding and generation. In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S. (eds.) Proceedings of the 39th International Conference on Machine Learning. Proceedings of Ma- chine Learning Research, vol. 162, pp. 1...
2022
-
[33]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neu- ral Information Processing Systems. vol. 36, pp. 34892–34916. Curran Associates, Inc. (2023),https://proceedings.neurips.cc/paper_files/paper/2023/file/ 6dcf277ea32ce3288914faf369fe6de0-Paper-Conf...
2023
-
[34]
Loper, E., Bird, S.: Nltk: The natural language toolkit (2002),https://arxiv. org/abs/cs/0205028
Pith/arXiv arXiv 2002
-
[35]
doi:10.18653/v1/2023.eacl- main.240
Muennighoff, N., Tazi, N., Magne, L., Reimers, N.: MTEB: Massive text embed- ding benchmark. In: Vlachos, A., Augenstein, I. (eds.) Proceedings of the 17th Conference of the European Chapter of the Association for Computational Lin- guistics. pp. 2014–2037. Association for Computational Linguistics, Dubrovnik, Croatia (May 2023).https://doi.org/10.18653/v...
-
[36]
Nussbaum, Z., Duderstadt, B., Mulyar, A.: Nomic embed vision: Expanding the latent space (2024),https://arxiv.org/abs/2406.18587
arXiv 2024
-
[37]
van den Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding (2019),https://arxiv.org/abs/1807.03748
Pith/arXiv arXiv 2019
-
[38]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceed- ings of Machine Learning Res...
2021
-
[39]
Robertson, S., Zaragoza, H.: The probabilistic relevance framework: Bm25 and beyond. Found. Trends Inf. Retr.3(4), 333–389 (Apr 2009).https://doi.org/ 10.1561/1500000019,https://doi.org/10.1561/1500000019
-
[40]
Robertson,S.E.,Walker,S.,Jones,S.,Hancock-Beaulieu,M.M.,Gatford,M.,etal.: Okapi at trec (1994)
1994
-
[41]
arXiv preprint arXiv:2508.10104 (2025)
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[42]
Journal of Documentation , volume =
SPARCK JONES, K.: A statistical interpretation of term specificity and its ap- plication in retrieval. Journal of Documentation28(1), 11–21 (01 1972).https: //doi.org/10.1108/eb026526,https://doi.org/10.1108/eb026526
-
[43]
Team, N.: Nomic embed multimodal: Interleaved text, image, and screenshots for visual document retrieval (2025),https://nomic.ai/blog/posts/nomic-embed- multimodal
2025
-
[44]
Thakur, N., Reimers, N., Rücklé, A., Srivastava, A., Gurevych, I.: BEIR: A het- erogeneous benchmark for zero-shot evaluation of information retrieval models. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) (2021),https://openreview.net/forum?id= wCu6T5xFjeJ LightSTAR for Efficient Visual Docume...
2021
-
[45]
arXiv preprint arXiv:2502.14786 (2025)
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025)
Pith/arXiv arXiv 2025
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang,Z.,Guan,T.,Fu,P.,Duan,C.,Jiang,Q.,Guo,Z.,Guo,S.,Luo,J.,Shen,W., Yang, X.: Marten: Visual question answering with mask generation for multi-modal document understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14460–14471 (2025)
2025
-
[47]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wen, C., Peng, Z., Huang, Y., Shen, W.: Efficient segmentation with multimodal large language model via token routing. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 10593–10602 (2026)
2026
-
[48]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xu, Y., Xu, Y., Lv, T., Cui, L., Wei, F., Wang, G., Lu, Y., Florencio, D., Zhang, C., Che, W., Zhang, M., Zhou, L.: LayoutLMv2: Multi-modal pre-training for visually- rich document understanding. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Pro- ceedings of the 59th Annual Meeting of the Association for Computational Linguis- tics and the 11th Intern...
-
[49]
Xu,Y.,Li,M.,Cui,L.,Huang,S.,Wei,F.,Zhou,M.:Layoutlm:Pre-trainingoftext and layout for document image understanding. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. p. 1192–1200. KDD ’20, ACM (Aug 2020).https://doi.org/10.1145/3394486. 3403172,http://dx.doi.org/10.1145/3394486.3403172
-
[50]
In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R
Yu, S., Tang, C., Xu, B., Cui, J., Ran, J., Yan, Y., Liu, Z., Wang, S., Han, X., Liu, Z., Sun, M.: Visrag: Vision-based retrieval-augmented generation on multi-modality documents. In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R. (eds.) International Conference on Learning Representations. vol. 2025, pp. 21074– 21098 (2025),https://proceedings.iclr.cc/pape...
2025
-
[51]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11975–11986 (October 2023)
2023
-
[52]
Zhang, J., Zhang, Q., Wang, B., Ouyang, L., Wen, Z., Li, Y., Chow, K.H., He, C., Zhang, W.: Ocr hinders rag: Evaluating the cascading impact of ocr on retrieval- augmented generation (2025),https://arxiv.org/abs/2412.02592
arXiv 2025
-
[53]
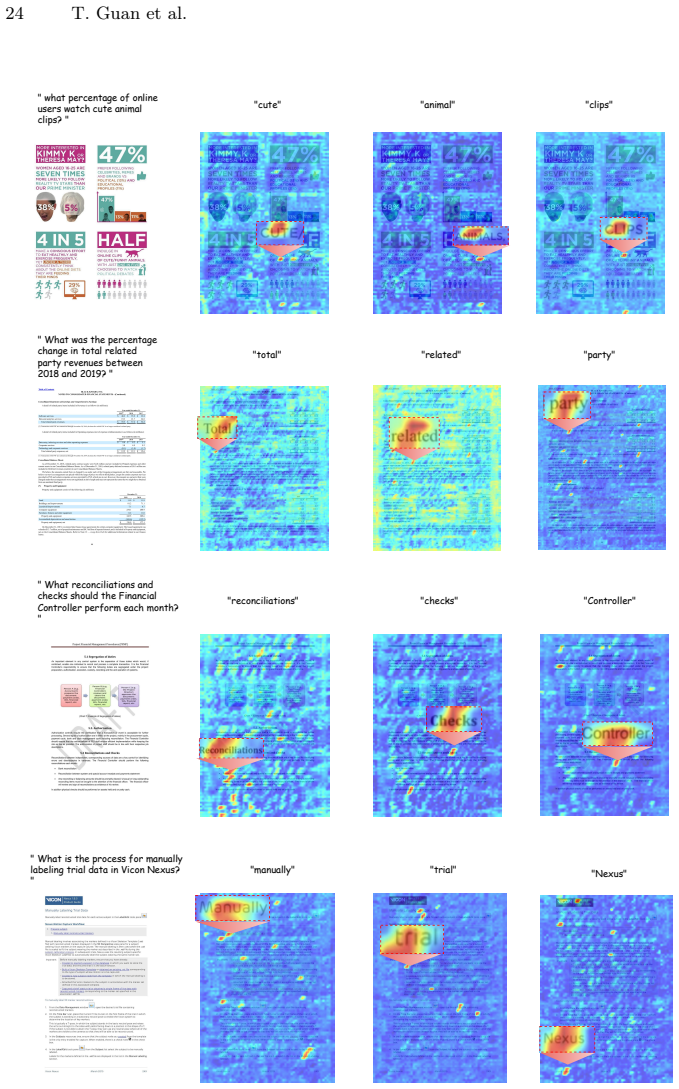
what percentage of onlineusers watch cute animal clips?
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., Gao, Z., Cui, E., Wang, X., Cao, Y., Liu, Y., Wei, X., Zhang, H., Wang, H., Xu, W., Li, H., Wang, J., Deng, N., Li, S., He, Y., Jiang, T., Luo, J., Wang, Y., He, C., Shi, B., Zhang, X., Shao, W., He, J., Xiong, Y., Qu, W., Sun, P., Jiao, P., Lv, H., Wu, L., Zhang, ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.