HeteroViT: A Versatile Single-Layer Vision Transformer Concept, Co-Designed for Distributed Real-Time Data Reduction on Scientific Detectors
Pith reviewed 2026-06-26 06:02 UTC · model grok-4.3
The pith
A single-layer vision transformer suffices for multiple detector tasks and maps directly to ASIC-FPGA-GPU stages for real-time reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single small vision transformer backbone can perform both supervised hit-miss classification and self-supervised latent space tasks across different learning paradigms and detector modalities, and because its blocks are uniform the model maps cleanly onto existing hardware stages via the one-unit-one-token rule, enabling progressive real-time data reduction and an edge decision without hardware-specific redesign for each task.
What carries the argument
The single-layer vision transformer under the one-unit-one-token mapping rule, which aligns uniform model blocks with successive hardware stages for distributed reduction.
If this is right
- The same backbone supports both supervised and self-supervised outputs and different detector modalities without changing the front end.
- Data is reduced at each hardware stage so only a keep-or-discard decision reaches the final processor.
- A reusable front-end becomes worth committing to silicon because it serves many tasks.
- Full raw data transfer and storage can be avoided for high-rate detectors.
Where Pith is reading between the lines
- Similar single-layer designs could apply to other high-throughput sensor systems if block uniformity holds across pipelines.
- Hardware testing would need to verify embedding feasibility and acceptable false-negative behavior on real devices.
- The approach might extend to other real-time scientific imaging instruments that face comparable data-volume limits.
Load-bearing premise
The uniform structure of the vision transformer blocks will allow a clean low-loss mapping to the detector hardware stages under the one-unit-per-token rule.
What would settle it
An ASIC-level implementation or end-to-end latency test showing that the embedding step cannot meet the sensor time or power budget, or that false-negative rates for key events exceed the threshold needed for safe data veto.
Figures


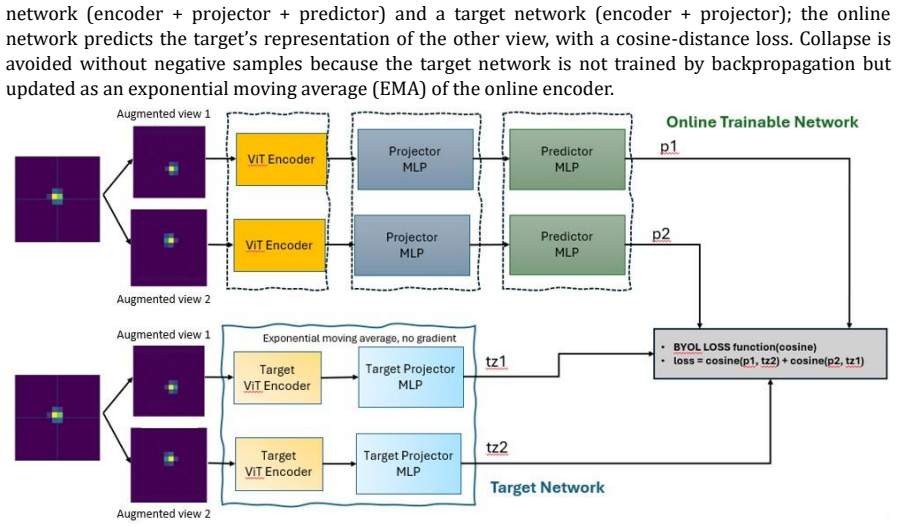
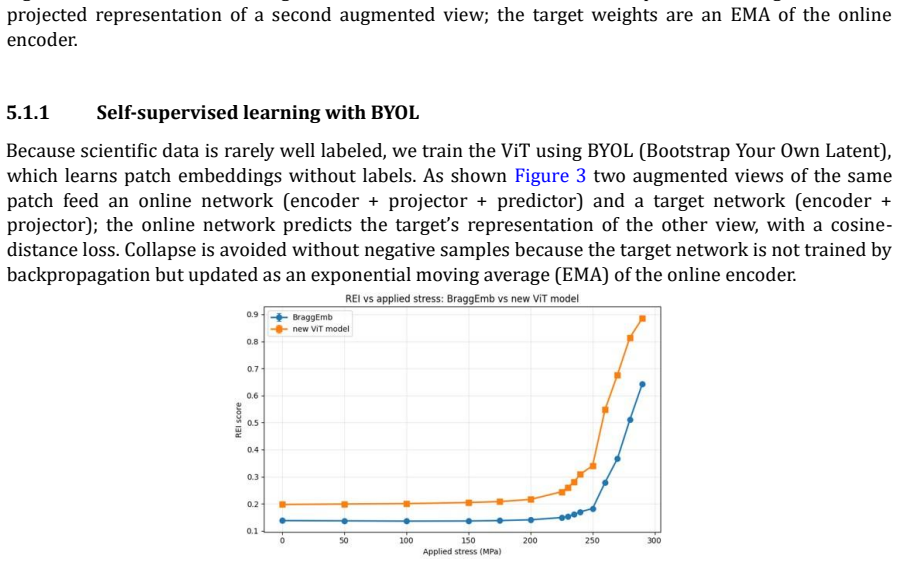
read the original abstract
Next-generation X-ray detectors generate data faster than any system can affordably store or process. LCLS-II, the upgraded Linac Coherent Light Source at SLAC, produces data on the order of terabytes per second, with raw-data transfer and storage projected to be prohibitively costly, even though much of the data is not scientifically useful. This concept paper focuses on two major points. The first is versatility: a deliberately tiny, single-layer Vision Transformer (ViT) is enough to serve distinct scientific quick-evaluation tasks. We demonstrate this on two very different problems: (a) a supervised hit/miss/maybe classification on the CSPAD dataset, made to resemble ePixUHR-like detector frames, and (b) a self-supervised latent space for rare-event detection in X-ray diffraction spanning two learning paradigms, two output types, and two detector modalities, with one small backbone. The second is hardware co-design: because the ViT's blocks are structurally uniform, the model maps cleanly onto the heterogeneous hardware already present in the LCLS detector pipeline (ASIC -> FPGA -> GPU) under a simple rule one ASIC is one token so the data is reduced progressively at each stage and a keep/discard decision is produced in real time at the edge. The two claims reinforce each other: versatility is precisely what justifies freezing the front-end in silicon, since a reusable front-end is only worth committing to hardware if it serves many tasks. We are explicit that this is a concept supported by early software analysis, not a hardware demonstration. The natural and primary next phase is the hardware implementation of this distributed pipeline. The decisive evidence still owed an end-to-end latency budget, ASIC feasibility of the in-sensor embedding, and the false-negative behavior that matters for a data veto defines that program. HeteroViT is our first step toward it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HeteroViT as a deliberately small single-layer Vision Transformer that can handle multiple scientific quick-evaluation tasks on X-ray detector data (supervised hit/miss/maybe classification on CSPAD-like frames and self-supervised latent-space rare-event detection on XRD data) while mapping directly onto the existing ASIC-FPGA-GPU pipeline in LCLS detectors via a one-ASIC-one-token rule for progressive real-time data reduction and edge veto decisions. The work is explicitly framed as a concept paper whose primary evidence is early software analysis; hardware implementation, latency budgets, and ASIC feasibility remain future work.
Significance. If the claimed hardware mapping and task versatility hold, the approach could enable substantial data-volume reduction at the sensor edge for TB/s-rate detectors such as LCLS-II, lowering storage and transfer costs while preserving scientifically relevant events. The single-backbone reuse across supervised and self-supervised paradigms on different detector modalities is a potentially attractive feature for justifying a fixed silicon front-end.
major comments (1)
- [Hardware co-design / abstract] Hardware co-design section: the central assertion that uniform ViT blocks permit a clean, low-loss partition across ASIC (embedding), FPGA (attention/MLP), and GPU stages under the one-ASIC-one-token rule is stated without any supporting resource estimates, quantization analysis, tokenization fidelity checks, or latency budgets; the software demonstrations on CSPAD and XRD frames therefore do not yet substantiate the co-design justification that versatility warrants freezing the front-end in silicon.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit numerical metrics (accuracy, F1, AUC, or reconstruction error) from the software experiments even if the work is conceptual, to allow readers to gauge the early-analysis baseline.
- [Hardware co-design] Notation for the one-ASIC-one-token mapping and the precise division of ViT operations across the three hardware stages should be defined more formally (e.g., a small diagram or pseudocode) to clarify the progressive reduction claim.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential impact of the HeteroViT concept. We address the single major comment point by point below.
read point-by-point responses
-
Referee: Hardware co-design section: the central assertion that uniform ViT blocks permit a clean, low-loss partition across ASIC (embedding), FPGA (attention/MLP), and GPU stages under the one-ASIC-one-token rule is stated without any supporting resource estimates, quantization analysis, tokenization fidelity checks, or latency budgets; the software demonstrations on CSPAD and XRD frames therefore do not yet substantiate the co-design justification that versatility warrants freezing the front-end in silicon.
Authors: We agree that the manuscript provides no resource estimates, quantization analysis, tokenization fidelity checks, or latency budgets for the proposed ASIC-FPGA-GPU partitioning. The paper is explicitly positioned as a concept paper whose primary evidence consists of early software demonstrations of task versatility; the hardware mapping is offered as a conceptual fit enabled by the uniform ViT block structure and the one-ASIC-one-token rule, not as a validated implementation. We will revise the hardware co-design section (and abstract) to more sharply separate the demonstrated software results from the prospective hardware proposal, and to state explicitly that the justification for silicon commitment remains conditional on the future hardware validation program already outlined in the manuscript. revision: yes
Circularity Check
No significant circularity; concept proposal without derivations, fitted predictions, or self-referential reductions
full rationale
The manuscript is a forward-looking concept paper that proposes a single-layer ViT architecture and its mapping to existing ASIC-FPGA-GPU hardware under a one-ASIC-one-token rule. It explicitly frames the work as early software analysis on CSPAD and X-ray diffraction data, not a hardware demonstration or closed derivation. No equations, parameter fits, predictions, or uniqueness theorems are presented that reduce to inputs by construction. The central claims rest on software demonstrations and an untested hardware-translation assertion, but this is an evidence gap rather than circularity. No self-citation chains or ansatzes are invoked as load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A single-layer Vision Transformer retains enough representational power for both supervised classification and self-supervised latent-space tasks on detector frames.
- domain assumption The structural uniformity of ViT blocks permits a clean mapping to ASIC-FPGA-GPU stages under the one-ASIC-one-token rule without major redesign.
invented entities (1)
-
HeteroViT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abhilasha Dave et al. “FPGA -Accelerated Real-Time Diagnostics at DIII -D Using the SLAC Neural Network Library for ML Inference” . In: arXiv preprint arXiv:2604.26042 (2026)
Pith/arXiv arXiv 2026
-
[2]
FPGA -accelerated SpeckleNN with SNL for real -time X-ray single-particle imaging
Abhilasha Dave et al. “FPGA -accelerated SpeckleNN with SNL for real -time X-ray single-particle imaging” . In: Frontiers in High Performance Computing 3 (2025), p. 1520151
2025
-
[3]
Applications and techniques for fast machine learning in science
Allison McCarn Deiana et al. “ Applications and techniques for fast machine learning in science” . In: Frontiers in big Data 5 (2022), p. 787421
2022
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy et al. “ An image is worth 16x16 words: Transformers for image recognition at scale” . In: arXiv preprint arXiv:2010.11929 (2020)
Pith/arXiv arXiv 2010
-
[5]
An empirical study on low gpu utilization of deep learning jobs
Yanjie Gao et al. “ An empirical study on low gpu utilization of deep learning jobs” . In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024, pp. 1– 13
2024
-
[6]
Bootstrap your own latent -a new approach to self -supervised learning
Jean-Bastien Grill et al. “Bootstrap your own latent -a new approach to self -supervised learning” . In: Advances in neural information processing systems 33 (2020), pp. 21271–21284
2020
-
[7]
Implementation of a framework for deploying AI inference engines in FPGAs
R. Herbst et al. “Implementation of a framework for deploying AI inference engines in FPGAs” . In: Smoky Mountains Computational Sciences and Engineering Conference . Springer, 2022, pp. 120 – 134
2022
-
[8]
A convolutional neural network -based screening tool for X -ray serial crystallography
T-W Ke et al. “ A convolutional neural network -based screening tool for X -ray serial crystallography” . In: Synchrotron Radiation 25.3 (2018), pp. 655–670
2018
-
[9]
Mind the memory gap: Unveiling gpu bottlenecks in large -batch llm inference
Pol G Recasens et al. “Mind the memory gap: Unveiling gpu bottlenecks in large -batch llm inference” . In: 2025 IEEE 18th International Conference on Cloud Computing (CLOUD) . IEEE. 2025, pp. 277–287
2025
-
[10]
GT Readout—A development platform for 1 MHz frame-rate detectors at LCLS- II
H Sandberg et al. “GT Readout—A development platform for 1 MHz frame-rate detectors at LCLS- II” . In: Journal of Instrumentation 20.08 (2025), P08019
2025
-
[11]
Megatron-lm: Training multi-billion parameter language models using model parallelism
Mohammad Shoeybi et al. “Megatron-lm: Training multi-billion parameter language models using model parallelism” . In: arXiv preprint arXiv:1909.08053 (2019)
Pith/arXiv arXiv 1909
-
[12]
AUREIS: Adaptive Ultra-fast Energy-efficient Intelligent Sensing
SLAC National Accelerator Laboratory. AUREIS: Adaptive Ultra-fast Energy-efficient Intelligent Sensing. https://lcls.slac.stanford.edu/depts/data-systems/projects/aureis. Accessed: June 8, 2026. 2026
2026
-
[13]
Massive scale data analytics at LCLS-II
Jana Thayer et al. “Massive scale data analytics at LCLS-II” . In: EPJ Web of Conferences. Vol. 295. EDP Sciences. 2024, p. 13002. 9
2024
-
[14]
Attention is all you need
Ashish Vaswani et al. “ Attention is all you need” . In: Advances in neural information processing systems 30 (2017)
2017
-
[15]
Rapid detection of rare events from in situ X-ray diffraction data using machine learning
Weijian Zheng et al. “Rapid detection of rare events from in situ X-ray diffraction data using machine learning” . In: Journal of Applied Crystallography 57.4 (Aug. 2024). doi: 10.1107/ S160057672400517X. url: https://doi.org/10.1107/S160057672400517X
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.