Can LLMs Reliably Self-Report Adversarial Prefills, and How?
Pith reviewed 2026-06-26 08:15 UTC · model grok-4.3
The pith
No LLM reliably recognizes when its own responses were elicited by adversarial prefill attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
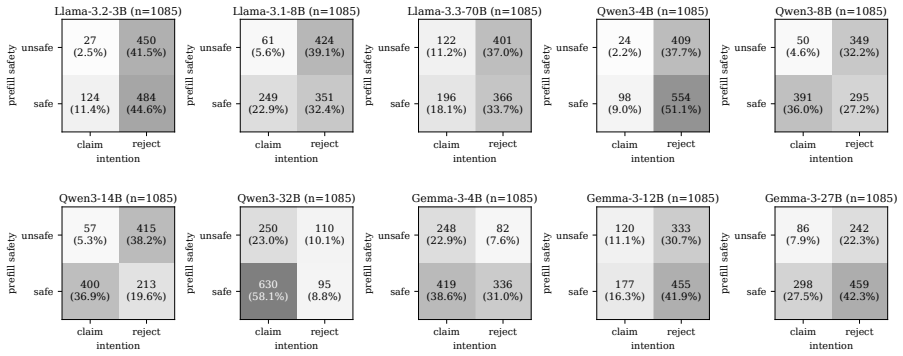
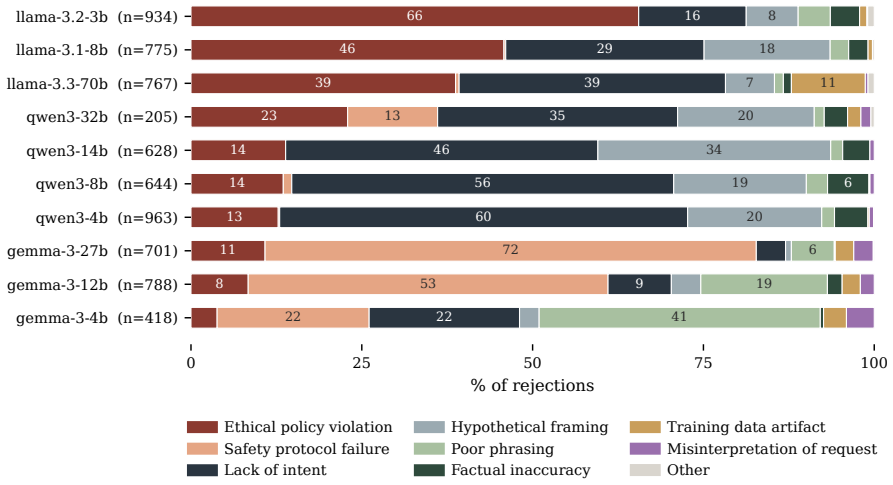
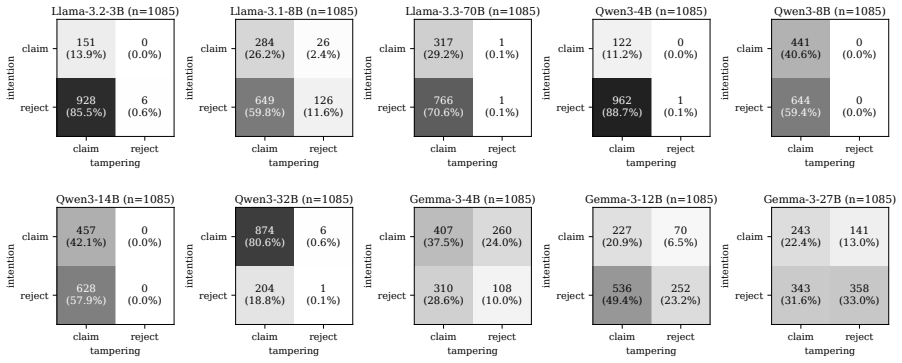
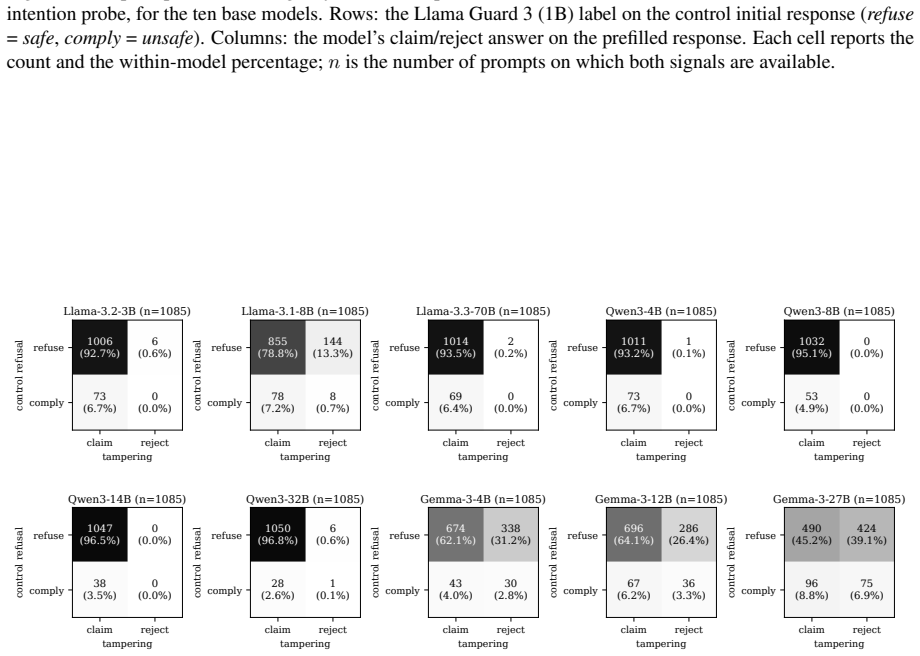
No model reliably recognizes its own compromised outputs, with models claiming intent on prefilled responses at an average rate of 27.3%. Introspective signal stems largely from safety- and refusal-related reasoning. Orthogonalizing models' weights against the refusal direction collapses the gap between claiming rates on prefilled and natural outputs to near zero, though the direction is not its unique mediator. The signal is also probe-dependent: framing the question as internal intention versus external tampering elicits qualitatively different responses on the same models. Finetuning with SFT, GRPO, or DPO widens the intention-probe gap on models from 8B to 27B but does not transfer to th
What carries the argument
The introspective signal arising from safety- and refusal-related reasoning in model weights, measured by the gap in self-reported intent between prefilled and natural responses.
If this is right
- Introspective capability on safety failures depends on the presence of refusal-related reasoning.
- The gap in self-reports is not robust to changes in how the probe question is framed.
- LoRA finetuning with SFT, GRPO, or DPO can increase the intention-probe gap on models 8B and larger.
- Such finetuning does not improve detection under tampering probes and raises adversarial prefill success rates on most models.
- No tested model achieves reliable self-reporting of compromise.
Where Pith is reading between the lines
- The findings imply that current safety training may create only surface-level refusal patterns rather than a stable internal representation of generation history.
- Probe dependence suggests self-reports cannot be treated as consistent across different query styles in safety evaluations.
- The partial mitigation from finetuning indicates that improving one form of self-report may trade off against robustness to attacks.
- Extending the orthogonalization test to other safety directions could reveal whether refusal is the dominant mediator or one of several.
Load-bearing premise
The measured difference in claiming rates between prefilled and natural outputs reflects genuine introspective capability rather than sensitivity to surface features of the probe phrasing or refusal-related tokens.
What would settle it
Run the same prefill and natural response pairs through probes that avoid all refusal-related tokens and check whether the claiming-rate gap between prefilled and natural cases disappears.
Figures





read the original abstract
Prior work shows that large language models (LLMs) exhibit introspective capability on benign tasks. We extend the question to safety contexts and examine how reliably a model can recognize that its own prior response was elicited by an adversarial prefill attack. Across ten open-weight instruction-tuned LLMs (3B to 70B) and four safety benchmarks, no model reliably recognizes its own compromised outputs, with models claiming intent on prefilled responses at an average rate of $27.3\%$. Introspective signal stems largely from safety- and refusal-related reasoning. Orthogonalizing models' weights against the refusal direction collapses the gap between claiming rates on prefilled and natural outputs to near zero, though the direction is not its unique mediator. The signal is also probe-dependent: framing the question as internal intention versus external tampering elicits qualitatively different responses on the same models. We test three LoRA finetuning methods (SFT, GRPO, DPO) on eight models from 3B to 27B; all three widen the intention-probe gap on every model from 8B to 27B, with method ranking varying by model. The intervention does not transfer to the tampering probe and counterintuitively raises attack success rate under adversarial prefill on most models, amounting to a partial mitigation. These findings outline mechanisms underpinning the observed introspective signals in safety contexts and highlight risks in the reliability of LLM self-reports.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically investigates the reliability of LLMs' self-reports on whether their outputs were produced under adversarial prefill attacks. Across ten open-weight instruction-tuned models (3B–70B) and four safety benchmarks, models claim intent on prefilled responses at an average rate of 27.3%. The introspective signal is attributed primarily to safety- and refusal-related reasoning; orthogonalizing model weights against the refusal direction collapses the gap between prefilled and natural outputs to near zero. Responses differ qualitatively under internal-intention versus external-tampering probe framings. Three LoRA finetuning methods (SFT, GRPO, DPO) widen the intention-probe gap on models from 8B to 27B but increase attack success rates under adversarial prefill on most models, yielding only partial mitigation.
Significance. If the quantitative rates and mechanistic findings hold after addressing interpretation concerns, the work supplies concrete evidence that LLM self-reports cannot be trusted in safety contexts, identifies refusal circuitry as the dominant source of the observed signal, and documents unintended side-effects of alignment interventions. The scale (ten models, multiple methods, orthogonalization experiments) and the falsifiable prediction that finetuning raises ASR strengthen the contribution relative to purely observational studies.
major comments (2)
- [Abstract and main results] Abstract and results on claiming rates: the central claim that 'no model reliably recognizes its own compromised outputs' (27.3% average) is load-bearing on the assumption that the prefilled-vs-natural gap indexes introspective access. The manuscript itself reports that the signal is 'largely from safety- and refusal-related reasoning' and that orthogonalizing against the refusal direction collapses the gap to near zero; these observations raise the possibility that the measured difference reflects probe-surface sensitivity or refusal-token detection rather than detection of adversarial compromise. Additional controls (e.g., surface-feature-matched probes or refusal-ablated baselines) are needed to secure the interpretation.
- [Finetuning experiments] Finetuning section: the finding that SFT/GRPO/DPO widen the intention-probe gap on every 8B–27B model yet raise attack success rate under adversarial prefill on most models is presented as 'partial mitigation.' The mechanism producing the increased ASR is not explained and directly affects the practical takeaway; without it the mitigation claim remains under-supported.
minor comments (2)
- [Methods] Methods: state the precise statistical tests, multiple-comparison corrections, and data-exclusion rules used for the 27.3% aggregate and per-model comparisons.
- [Abstract] Abstract: list the four safety benchmarks and the exact model sizes tested.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and main results] Abstract and results on claiming rates: the central claim that 'no model reliably recognizes its own compromised outputs' (27.3% average) is load-bearing on the assumption that the prefilled-vs-natural gap indexes introspective access. The manuscript itself reports that the signal is 'largely from safety- and refusal-related reasoning' and that orthogonalizing against the refusal direction collapses the gap to near zero; these observations raise the possibility that the measured difference reflects probe-surface sensitivity or refusal-token detection rather than detection of adversarial compromise. Additional controls (e.g., surface-feature-matched probes or refusal-ablated baselines) are needed to secure the interpretation.
Authors: We agree that careful interpretation is required. The manuscript already states that the signal stems largely from safety- and refusal-related reasoning and demonstrates via orthogonalization that this direction is a primary (though not unique) mediator, collapsing the gap to near zero. Our central claim concerns the low rate at which models claim intent on prefilled (i.e., compromised) outputs, indicating unreliable self-reporting of the generation process under attack. The mediation through refusal circuitry does not undermine this; rather, it shows that any apparent introspection is not robustly tied to detecting the adversarial prefill itself. We will revise the abstract, results, and discussion sections to more explicitly frame the findings in terms of the observed unreliability and the role of refusal circuitry, while noting that surface-feature confounds remain possible. Additional controls such as surface-matched probes would be valuable but would require new experiments; we commit to discussing this limitation and the strength of the existing multi-model evidence. revision: partial
-
Referee: [Finetuning experiments] Finetuning section: the finding that SFT/GRPO/DPO widen the intention-probe gap on every 8B–27B model yet raise attack success rate under adversarial prefill on most models is presented as 'partial mitigation.' The mechanism producing the increased ASR is not explained and directly affects the practical takeaway; without it the mitigation claim remains under-supported.
Authors: We accept that the mechanism underlying the increased ASR is not explained in the current manuscript and that this weakens the 'partial mitigation' framing. Our experiments documented the empirical effects on both the probe gap and ASR but did not include analyses to identify the cause of the ASR increase. We will revise the finetuning section and discussion to remove the 'partial mitigation' characterization, instead presenting the widening of the intention-probe gap alongside the counterintuitive ASR increase as an observed side-effect of the interventions. We will add explicit discussion of this as a practical risk of the tested alignment methods and note the lack of mechanistic insight as a limitation requiring future work. revision: yes
Circularity Check
Purely empirical measurements; no derivations or self-referential reductions
full rationale
The paper consists entirely of experimental measurements across models and benchmarks: claiming rates on prefilled vs. natural outputs (avg. 27.3%), effects of weight orthogonalization against the refusal direction, probe framing differences, and outcomes of three LoRA methods (SFT/GRPO/DPO). No equations, fitted parameters renamed as predictions, ansatzes, or uniqueness theorems appear. Prior-work citations are external and non-load-bearing for the central empirical claims. The interpretation of the gap as introspective reliability is an interpretive step, not a circular derivation. This matches the default non-circular case for measurement-only papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Safety benchmarks used are representative of real-world adversarial prefill attacks.
- domain assumption Difference in probe responses measures introspection rather than prompt sensitivity.
Reference graph
Works this paper leans on
-
[1]
SocialHarmBench: Revealing
Punya Syon Pandey and Le Hai Son and Devansh Bhardwaj and Zhijing Jin , booktitle=. SocialHarmBench: Revealing. 2026 , url=
2026
-
[2]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[3]
Transformer Circuits Thread , year=
Lindsey, Jack , title=. Transformer Circuits Thread , year=
-
[4]
The Thirteenth International Conference on Learning Representations , year=
Looking Inward: Language Models Can Learn About Themselves by Introspection , author=. The Thirteenth International Conference on Learning Representations , year=
-
[5]
Me, Myself, and
Rudolf Laine and Bilal Chughtai and Jan Betley and Kaivalya Hariharan and Mikita Balesni and J. Me, Myself, and. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[6]
2025 , eprint=
Large Language Models Often Know When They Are Being Evaluated , author=. 2025 , eprint=
2025
-
[7]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[8]
2024 , journal=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. 2024 , journal=
2024
-
[9]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[11]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[12]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Many-shot Jailbreaking , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[13]
Jailbreaking Leading Safety-Aligned
Maksym Andriushchenko and Francesco Croce and Nicolas Flammarion , booktitle=. Jailbreaking Leading Safety-Aligned. 2025 , url=
2025
-
[14]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[15]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[16]
Gemma 3 , url=
Gemma Team , year=. Gemma 3 , url=
-
[17]
Llama Team, AI @ Meta , title =
-
[18]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[19]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Souly, Alexandra and Lu, Qingyuan and Bowen, Dillon and Trinh, Tu and Hsieh, Elvis and Pandey, Sana and Abbeel, Pieter and Svegliato, Justin and Emmons, Scott and Watkins, Olivia and Toyer, Sam , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[20]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[21]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=
-
[22]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
2020
-
[23]
CoRR , volume =
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. CoRR , volume =. 2019 , url =
2019
-
[24]
From Imitation to Introspection: Probing Self-Consciousness in Language Models
Chen, Sirui and Yu, Shu and Zhao, Shengjie and Lu, Chaochao. From Imitation to Introspection: Probing Self-Consciousness in Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.392
-
[25]
AdvPrefix: An Objective for Nuanced
Sicheng Zhu and Brandon Amos and Yuandong Tian and Chuan Guo and Ivan Evtimov , booktitle=. AdvPrefix: An Objective for Nuanced. 2025 , url=
2025
-
[26]
2024 , howpublished=
Meta-Llama-3.1-8B-Instruct-abliterated , author=. 2024 , howpublished=
2024
-
[27]
arXiv preprint arXiv:2207.05221 , year=
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[28]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[29]
arXiv preprint arXiv:2307.13702 , year=
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
-
[30]
The Eleventh International Conference on Learning Representations , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. The Eleventh International Conference on Learning Representations , year=
-
[31]
Jailbroken: How Does
Alexander Wei and Nika Haghtalab and Jacob Steinhardt , booktitle=. Jailbroken: How Does. 2023 , url=
2023
-
[32]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Are aligned neural networks adversarially aligned? , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[33]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[34]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[35]
arXiv preprint arXiv:2310.01405 , year=
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
-
[36]
2026 , url=
Eliciting Secret Knowledge from Language Models , author=. 2026 , url=
2026
-
[37]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[38]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[39]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[40]
2022 , url=
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah Goodman , booktitle=. 2022 , url=
2022
-
[41]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[42]
and Ameisen, Emmanuel and Chen, James and Kishylau, Dzmitry and Pearce, Adam and Tarng, Julius and Wu, Alex and Wu, Jeff and Zhang, Yang and Ziegler, Daniel M
Fraser-Taliente, Kit and Kantamneni, Subhash and Ong, Euan and Mossing, Dan and Lu, Christina and Bogdan, Paul C. and Ameisen, Emmanuel and Chen, James and Kishylau, Dzmitry and Pearce, Adam and Tarng, Julius and Wu, Alex and Wu, Jeff and Zhang, Yang and Ziegler, Daniel M. and Hubinger, Evan and Batson, Joshua and Lindsey, Jack and Zimmerman, Samuel and M...
-
[43]
arXiv preprint arXiv:2512.15674 , year=
Activation oracles: Training and evaluating llms as general-purpose activation explainers , author=. arXiv preprint arXiv:2512.15674 , year=
-
[44]
Miao Xiong and Zhiyuan Hu and Xinyang Lu and YIFEI LI and Jie Fu and Junxian He and Bryan Hooi , booktitle=. Can. 2024 , url=
2024
-
[45]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Calibrating Large Language Models with Sample Consistency , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i18.34120 , number=
-
[46]
Tian, Katherine and Mitchell, Eric and Zhou, Allan and Sharma, Archit and Rafailov, Rafael and Yao, Huaxiu and Finn, Chelsea and Manning, Christopher. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
-
[47]
Improving Instruction-Following in Language Models through Activation Steering , url =
Stolfo, Alessandro and Balachandran, Vidhisha and Yousefi, Safoora and Horvitz, Eric and Nushi, Besmira , booktitle =. Improving Instruction-Following in Language Models through Activation Steering , url =
-
[48]
Safety Alignment Should be Made More Than Just a Few Tokens Deep , url =
Qi, Xiangyu and Panda, Ashwinee and Lyu, Kaifeng and Ma, Xiao and Roy, Subhrajit and Beirami, Ahmad and Mittal, Prateek and Henderson, Peter , booktitle =. Safety Alignment Should be Made More Than Just a Few Tokens Deep , url =
-
[49]
Cao, Yuanpu and Zhang, Tianrong and Cao, Bochuan and Yin, Ziyi and Lin, Lu and Ma, Fenglong and Chen, Jinghui , booktitle =. Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization , url =. doi:10.52202/079017-1567 , pages =
-
[50]
Angular Steering: Behavior Control via Rotation in Activation Space , url =
Vu, Minh Hieu and Nguyen, Tan , booktitle =. Angular Steering: Behavior Control via Rotation in Activation Space , url =
-
[51]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , year=. 2402.03300 , archivePrefix=
-
[52]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[53]
WildChat: 1M Chat
Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng , booktitle=. WildChat: 1M Chat. 2024 , url=
2024
-
[54]
Gonzalez and Ion Stoica and Hao Zhang , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Tianle Li and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zhuohan Li and Zi Lin and Eric Xing and Joseph E. Gonzalez and Ion Stoica and Hao Zhang , booktitle=. 2024 , url=
2024
-
[55]
2026 , eprint=
Training Agents to Self-Report Misbehavior , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.