Unified Multi-Task Relevance Modeling for E-Commerce: Comparing Task Routing Architectures Across LLMs and Cross-Encoders
Pith reviewed 2026-06-26 06:06 UTC · model grok-4.3
The pith
A multi-head private layer ensemble reaches 89.96 percent accuracy on 453K e-commerce relevance examples by unifying six entity-pair tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
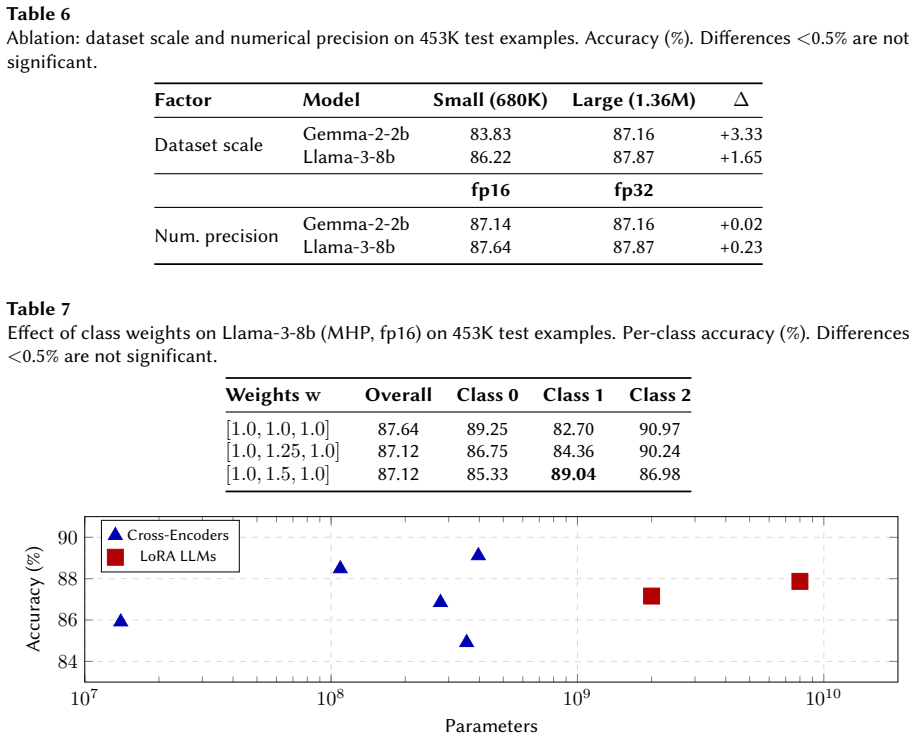
The central claim is that the MHP Ensemble, which combines multi-head classification with private transformer layers per task, reaches 89.96 percent accuracy on 453K test examples and outperforms all other routing configurations and single-task baselines; removing text prefixes without private layers hurts decoder-only LLMs far more than cross-encoders, while multi-task training produces up to 14 percent gains on low-resource tasks.
What carries the argument
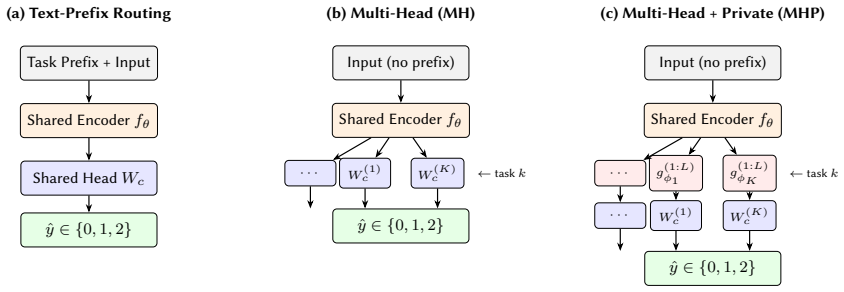
The multi-head with private layers (MHP) routing architecture, which routes each task through its own transformer layers after a shared encoder to encode task identity.
If this is right
- The MHP Ensemble achieves the highest accuracy of 89.96 percent on 453K test examples.
- Removing text prefixes without private layers causes severe degradation for decoder-only LLMs while cross-encoders remain robust.
- Multi-task training yields up to 14 percent improvement on low-resource tasks over single-task baselines.
- A majority-vote ensemble exploits the diversity induced by private-layer routing.
Where Pith is reading between the lines
- A single unified model could replace multiple task-specific models and reduce inconsistency in relevance signals across an e-commerce platform.
- Routing designs may need to be chosen according to whether the base model is decoder-only or encoder-based rather than applied uniformly.
- The same private-layer approach could be tested on other multi-task settings that mix high- and low-resource prediction problems.
Load-bearing premise
Encoder-based and decoder-only models encode task identity through different mechanisms, making routing choices affect the two families asymmetrically.
What would settle it
Finding that accuracy on the 453K test set is statistically identical across all routing architectures, or that removing prefixes without private layers degrades both LLMs and cross-encoders by similar amounts.
Figures

read the original abstract
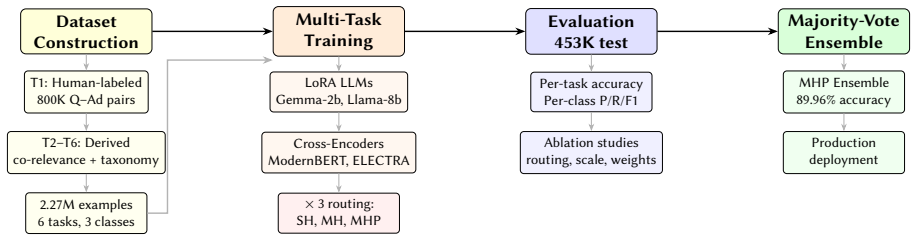
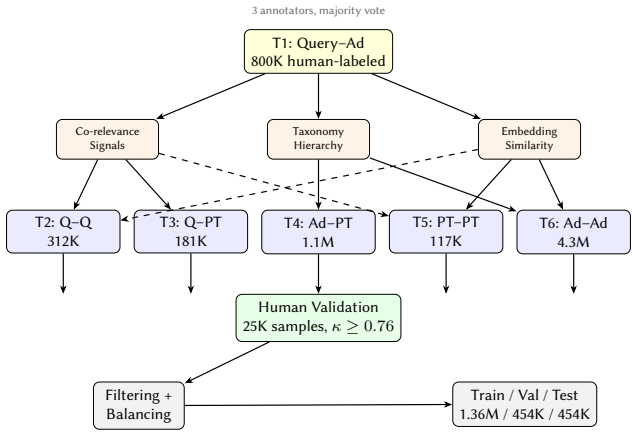
How can we build a single relevance model that handles six different entity pair relationship types in e commerce from query product matching to product type similarity when each task has different data volumes, different semantic requirements, and potentially conflicting learning signals? This question is important because current industry practice relies on separate models for each task, preventing knowledge transfer and producing inconsistent relevance signals. Our work is driven by the following insight: encoder based and decoder only models encode task identity through different mechanisms, so the choice of task routing architecture how task identity is communicated to the shared model affects these two families in asymmetric ways. As our key novelty, we combine three ideas: (a) a unified multi task framework that jointly trains on six entity pair tasks under a shared three point relevance scale, (b) a systematic comparison of three task routing architectures (text prefix routing, multi head classification, and multihead with private transformer layers) across both LoRA adapted LLMs and fully finetuned cross encoders, and (c) a majority vote ensemble that exploits the diversity induced by private layer routing. First, we show that the MHP Ensemble (multi head with private layers) achieves 89.96% accuracy on 453K test examples the highest across all configurations . Second, we show that removing text prefixes without private layers causes severe degradation for decoder only LLMs while cross encoders remain robust , suggesting an encoder decoder asymmetry in task identity encoding. Third, we show that multi task training yields up to 14% improvement on low resource tasks over single task baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified multi-task framework for six e-commerce entity-pair relevance tasks (query-product matching through product-type similarity) trained jointly on a shared three-point scale. It systematically compares three task-routing architectures (text-prefix, multi-head classification, multi-head with private transformer layers) across LoRA-adapted decoder-only LLMs and fully fine-tuned cross-encoders, and introduces a majority-vote ensemble exploiting private-layer diversity. Key reported results are that the MHP Ensemble reaches 89.96% accuracy on 453K test examples, that decoder-only models degrade sharply without text prefixes while cross-encoders do not, and that multi-task training yields up to 14% gains on low-resource tasks relative to single-task baselines.
Significance. If the central empirical claims hold after clarification, the work has clear practical value for e-commerce retrieval systems that currently deploy separate per-task models. The reported scale of the test set (453K examples) and the explicit multi-task gains on low-resource tasks are concrete strengths. The architecture comparison across encoder and decoder families also supplies actionable guidance on task-identity encoding mechanisms. No machine-checked proofs or parameter-free derivations are present; the contribution is empirical.
major comments (2)
- [Abstract] Abstract: The headline claim attributes 89.96% accuracy on the 453K test set to the MHP Ensemble and states that the ensemble exploits diversity induced by private-layer routing. However, no equivalent majority-vote ensembles are reported for the text-prefix or plain multi-head configurations. Without these controls it is impossible to separate the contribution of the routing architecture from a generic ensembling benefit.
- [Abstract] Abstract: Concrete accuracy and improvement figures are stated, yet the manuscript supplies no information on train/validation/test splits, baseline definitions, statistical tests, or hyperparameter search procedures. These omissions make the reported numbers impossible to interpret or reproduce and directly affect the soundness of all three main claims.
minor comments (2)
- Define all acronyms (MHP, LoRA, etc.) on first use and ensure consistent terminology between abstract and body.
- Clarify whether the 453K test examples are held-out from all six tasks or only a subset; this affects interpretation of the multi-task versus single-task comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve reproducibility and strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim attributes 89.96% accuracy on the 453K test set to the MHP Ensemble and states that the ensemble exploits diversity induced by private-layer routing. However, no equivalent majority-vote ensembles are reported for the text-prefix or plain multi-head configurations. Without these controls it is impossible to separate the contribution of the routing architecture from a generic ensembling benefit.
Authors: We agree that the absence of majority-vote ensembles for the text-prefix and plain multi-head configurations prevents cleanly isolating the benefit of private-layer diversity from generic ensembling effects. In the revised manuscript we will add equivalent majority-vote ensembles for all three routing architectures and report the corresponding accuracies. This will allow direct comparison and support a more precise attribution of gains to the private-layer mechanism. revision: yes
-
Referee: [Abstract] Abstract: Concrete accuracy and improvement figures are stated, yet the manuscript supplies no information on train/validation/test splits, baseline definitions, statistical tests, or hyperparameter search procedures. These omissions make the reported numbers impossible to interpret or reproduce and directly affect the soundness of all three main claims.
Authors: The referee is correct that the manuscript currently lacks these essential experimental details, which limits interpretability and reproducibility. We will add a dedicated subsection to the experimental setup that specifies the train/validation/test split ratios and construction method, precise definitions of the single-task baselines, any statistical significance tests performed, and the hyperparameter search procedure. These additions will be included in the revision. revision: yes
Circularity Check
No circularity: purely empirical model comparison
full rationale
The manuscript presents a set of controlled experiments training and evaluating multi-task relevance models on six e-commerce tasks. All reported numbers (e.g., 89.96% accuracy on the 453K test set) are measured performance metrics on held-out data. No equations, parameter-fitting steps, uniqueness theorems, or self-citations are used to derive results from inputs; the central claims are direct experimental outcomes. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Six entity-pair tasks can be jointly trained under a shared three-point relevance scale despite differing semantic requirements and data volumes
Reference graph
Works this paper leans on
-
[1]
L. M. Aiello, I. Arapakis, R. Baeza-Yates, X. Bai, N. Barbieri, A. Mantrach, F. Silvestri, The role of relevance in sponsored search, in: Proceedings of the 25th ACM International Conference on Information and Knowledge Management, 2016, pp. 185–194
2016
-
[2]
N. Su, J. He, Y. Liu, M. Zhang, S. Ma, User intent, behaviour, and perceived satisfaction in product search, in: Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, 2018, pp. 547–555
2018
-
[3]
Y. Wang, Y. Xue, B. Liu, M. Wen, W. Zhao, S. Guo, P. S. Yu, Click-conversion multi-task model with position bias mitigation for sponsored search in ecommerce, in: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023
2023
-
[4]
Caruana, Multitask learning, Machine Learning 28 (1997) 41–75
R. Caruana, Multitask learning, Machine Learning 28 (1997) 41–75
1997
-
[5]
S. Ruder, An overview of multi-task learning in deep neural networks, arXiv preprint arXiv:1706.05098 (2017)
Pith/arXiv arXiv 2017
-
[6]
X. Liu, P. He, W. Chen, J. Gao, Multi-task deep neural networks for natural language understanding, arXiv preprint arXiv:1901.11504 (2019)
Pith/arXiv arXiv 1901
-
[7]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, arXiv preprint arXiv:1810.04805 (2019)
Pith/arXiv arXiv 2019
-
[8]
M. Crawshaw, Multi-task learning with deep neural networks: A survey, arXiv preprint arXiv:2009.09796 (2020)
arXiv 2009
-
[9]
J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, E. H. Chi, Modeling task relationships in multi-task learning with multi-gate mixture-of-experts, in: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2018, pp. 1930–1939
2018
-
[10]
H. Tang, J. Liu, M. Zhao, X. Gong, Progressive layered extraction (PLE): A novel multi-task learning (MTL) model for personalized recommendations, in: Proceedings of the 14th ACM Conference on Recommender Systems, 2020, pp. 269–278
2020
-
[11]
Standley, A
T. Standley, A. R. Zamir, D. Chen, L. Guibas, J. Malik, S. Savarese, Which tasks should be learned together in multi-task learning?, in: International Conference on Machine Learning, 2020, pp. 9120–9132
2020
-
[12]
N. Rao, C. Bansal, S. Mukherjee, C. Maddila, Product insights: Analyzing product intents in web search, in: Proceedings of the 29th ACM International Conference on Information and Knowledge Management, 2020, pp. 2189–2192
2020
-
[13]
C. K. Reddy, L. Màrquez, F. Valero, N. Rao, H. Zaragoza, S. Bandyopadhyay, A. Biswas, A. Xing, K. Subbian, Shopping queries dataset: A large-scale ESCI benchmark for improving product search, in: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 4429–4439
2022
-
[14]
Järvelin, J
K. Järvelin, J. Kekäläinen, Cumulated gain-based evaluation of IR techniques, ACM Transactions on Information Systems 20 (2002) 422–446
2002
-
[15]
M. O. F. Rokon, A. Simion, W. Du, M. Wen, H. Yao, K.-c. Lee, Enhancement of e-commerce sponsored search relevancy with LLM, in: Proceedings of the SIGIR Workshop on eCommerce (eCom’24), 2024
2024
-
[16]
Z. Wang, W. Du, M. O. F. Rokon, P. Adhikary, Y. Xue, J. Xu, J. Zhou, K.-c. Lee, M. Wen, Semantic ads retrieval at Walmart ecommerce with language models progressively trained on multiple knowledge domains, arXiv preprint arXiv:2502.09089 (2025)
arXiv 2025
-
[17]
S. Desai, M. O. F. Rokon, J. N. Acharya, I. Shah, H. Yao, U. Porwal, K.-c. Lee, Unified supervision for walmarts sponsored search retrieval via joint semantic relevance and behavioral engagement modeling, arXiv preprint arXiv:2604.07930 (2026)
Pith/arXiv arXiv 2026
-
[18]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, LoRA: Low-rank adaptation of large language models, in: Proceedings of the Tenth International Conference on Learning Representations (ICLR), 2022
2022
-
[19]
T. Dettmers, A. Pagnoni, A. Holtzman, L. Zettlemoyer, QLoRA: Efficient finetuning of quantized LLMs, arXiv preprint arXiv:2305.14314 (2023)
Pith/arXiv arXiv 2023
-
[20]
Thomas, S
P. Thomas, S. Spielman, N. Craswell, B. Mitra, Large language models can accurately predict searcher preferences, in: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 1930–1940
2024
-
[21]
Faggioli, L
G. Faggioli, L. Dietz, C. Clarke, G. Demartini, M. Hagen, C. Hauff, N. Kando, E. Kanoulas, M. Potthast, B. Stein, H. Wachsmuth, Perspectives on large language models for relevance judgment, in: Proceedings of the 2023 ACM SIGIR International Conference on the Theory of Information Retrieval, 2023, pp. 39–50
2023
-
[22]
Gemma Team, Gemma: Open models based on Gemini research and technology, arXiv preprint arXiv:2403.08295 (2024)
Pith/arXiv arXiv 2024
-
[23]
A. Grattafiori, A. Dubey, A. Jauhri, et al., The Llama 3 herd of models, arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[24]
R. Nogueira, K. Cho, Passage re-ranking with BERT, arXiv preprint arXiv:1901.04085 (2019)
Pith/arXiv arXiv 1901
-
[25]
N. Reimers, I. Gurevych, Sentence-BERT: Sentence embeddings using siamese BERT-networks, arXiv preprint arXiv:1908.10084 (2019)
Pith/arXiv arXiv 1908
-
[26]
B. Warner, A. Chaffin, B. Clavié, O. Weller, O. Hallström, S. Taghadouini, A. Gallagher, R. Biswas, F. Ladhak, T. Aarsen, N. Cooper, G. Adams, J. Howard, I. Poli, Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, arXiv preprint arXiv:2412.13663 (2024)
Pith/arXiv arXiv 2024
-
[27]
Clark, M.-T
K. Clark, M.-T. Luong, Q. V. Le, C. D. Manning, ELECTRA: Pre-training text encoders as dis- criminators rather than generators, in: International Conference on Learning Representations, 2020
2020
-
[28]
X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, Q. Liu, TinyBERT: Distilling BERT for natural language understanding, arXiv preprint arXiv:1909.10351 (2020)
arXiv 1909
-
[29]
T. G. Dietterich, Ensemble methods in machine learning, in: International Workshop on Multiple Classifier Systems, 2000, pp. 1–15
2000
-
[30]
G. V. Cormack, C. L. Clarke, S. Buettcher, Reciprocal rank fusion outperforms Condorcet and individual rank learning methods, in: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2009, pp. 758–759
2009
-
[31]
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, arXiv preprint arXiv:1711.05101 (2019)
Pith/arXiv arXiv 2019
-
[32]
Cohen, A coefficient of agreement for nominal scales, Educational and Psychological Measure- ment 20 (1960) 37–46
J. Cohen, A coefficient of agreement for nominal scales, Educational and Psychological Measure- ment 20 (1960) 37–46
1960
-
[33]
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov, RoBERTa: A robustly optimized BERT pretraining approach, arXiv preprint arXiv:1907.11692 (2019)
Pith/arXiv arXiv 1907
-
[34]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, Z. Liu, BGE M3-embedding: Multi-lingual, multi- functionality, multi-granularity text embeddings through self-knowledge distillation, arXiv preprint arXiv:2402.03216 (2024). https://github.com/FlagOpen/FlagEmbedding
Pith/arXiv arXiv 2024
-
[35]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, et al., GPT-4 technical report, arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.