Layer-wise Probing of wav2vec 2.0 and Whisper for Consonant Cluster Reduction in African American English
Pith reviewed 2026-06-26 07:57 UTC · model grok-4.3
The pith
Both wav2vec2 and Whisper encode AAE consonant cluster reduction as structured gradient variation with retained cues to underlying stops rather than deletion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Both models distinguish reduced and canonical forms with high accuracy. Crucially, reduced segments retain cues to their underlying stops, indicating that CCR is encoded as structured gradient phonological variation rather than simple segmental deletion. These results demonstrate structured phonological encoding of AAE CCR patterns in modern speech models.
What carries the argument
Layer-wise probing classifiers on wav2vec2-base and Whisper-small representations for segmental reduction detection and segmental restoration of underlying cluster identity.
If this is right
- Both self-supervised and supervised models capture CCR patterns in AAE with high accuracy.
- Reduced segments are represented with partial cues to the full underlying cluster rather than complete deletion.
- Phonological variation is encoded in a structured, gradient manner across model layers.
- This structured encoding holds for both wav2vec2-base and Whisper-small.
- The findings apply directly to understanding sources of ASR disparity for AAE speakers.
Where Pith is reading between the lines
- ASR systems could improve by treating reductions as recoverable gradient forms instead of errors to be corrected.
- The same probing approach could test whether other phonological processes in AAE or other dialects are encoded similarly.
- Retained cues suggest the models might support reconstruction of canonical forms from reduced input for better transcription.
- Findings indicate that internal representations preserve enough dialect-specific structure to support linguistic analysis of variation beyond surface acoustics.
Load-bearing premise
The probing classifiers accurately reflect the linguistic information encoded in the model's internal representations rather than artifacts of the probe training or the specific dataset of AAE speech samples used.
What would settle it
Re-running the same layer-wise probing tasks on a new speaker-independent AAE dataset with different probe architectures that yields no evidence of retained stop cues in reduced segments would falsify the encoding claim.
Figures
read the original abstract
Self-supervised and supervised speech models are increasingly used to investigate which linguistic information their internal representations encode, and at what level of abstraction they encode it. One underexplored phenomenon is consonant cluster reduction (CCR) in African American English (AAE), a widespread phonological process and a source of automatic speech recognition (ASR) disparity. To examine how CCR is represented, we conduct speaker-independent layer-wise probing of wav2vec2-base and Whisper-small using two tasks: segmental reduction detection and segmental restoration of underlying cluster identity. Both models distinguish reduced and canonical forms with high accuracy. Crucially, reduced segments retain cues to their underlying stops, indicating that CCR is encoded as structured gradient phonological variation rather than simple segmental deletion. These results demonstrate structured phonological encoding of AAE CCR patterns in modern speech models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts speaker-independent layer-wise probing of wav2vec2-base and Whisper-small on consonant cluster reduction (CCR) in African American English. Using segmental reduction detection and segmental restoration tasks, it reports that both models distinguish reduced and canonical forms with high accuracy and that reduced segments retain cues to underlying stops, concluding that CCR is encoded as structured gradient phonological variation rather than simple deletion.
Significance. If the central empirical claims hold after addressing methodological gaps, the work would provide useful evidence on how modern speech models represent sociophonetic variation in AAE, with potential implications for ASR fairness and phonological modeling of gradient processes. The layer-wise design and dual-task approach are appropriate for locating where such information is encoded.
major comments (2)
- [Methods] Methods: The description provides no dataset size, token counts, speaker numbers, or explicit validation of speaker independence (e.g., train/test speaker splits or cross-speaker controls). These omissions make it impossible to evaluate whether the reported high accuracies reflect genuine model encoding or dataset-specific artifacts.
- [Segmental restoration task] Segmental restoration task (results section): The probe input specification does not state whether features are restricted to the reduced segment's internal representation or include word identity, lexical context, or surrounding phonetic frames. Without such isolation, restoration accuracy on reduced forms could arise from higher-level leakage rather than retention of segment-internal cues to underlying stops, directly undermining the gradient-variation claim versus deletion.
minor comments (1)
- [Abstract] Abstract: Accuracy figures are stated qualitatively ('high accuracy') without numerical values, confidence intervals, or baseline comparisons; adding these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Methods] Methods: The description provides no dataset size, token counts, speaker numbers, or explicit validation of speaker independence (e.g., train/test speaker splits or cross-speaker controls). These omissions make it impossible to evaluate whether the reported high accuracies reflect genuine model encoding or dataset-specific artifacts.
Authors: We agree that these quantitative details and validation steps were omitted from the submitted manuscript. The revised Methods section will include the total number of tokens and utterances analyzed, the number of speakers, and an explicit description of the speaker-independent partitioning (with no speaker overlap between training and test sets) used for all probing experiments. These additions will allow direct evaluation of whether the accuracies reflect model encoding rather than artifacts. revision: yes
-
Referee: [Segmental restoration task] Segmental restoration task (results section): The probe input specification does not state whether features are restricted to the reduced segment's internal representation or include word identity, lexical context, or surrounding phonetic frames. Without such isolation, restoration accuracy on reduced forms could arise from higher-level leakage rather than retention of segment-internal cues to underlying stops, directly undermining the gradient-variation claim versus deletion.
Authors: The referee correctly notes that the original text did not explicitly isolate the probe input. The segmental restoration probe uses only the hidden-state activations from the time steps aligned to the reduced segment itself; no word identity, lexical context, or neighboring phonetic frames are provided as input. We will revise the Methods section to state this restriction unambiguously, thereby confirming that any restoration accuracy derives from segment-internal cues rather than higher-level leakage. revision: yes
Circularity Check
No significant circularity; empirical probing study with no derivations or self-referential reductions
full rationale
The paper performs layer-wise probing experiments on wav2vec2 and Whisper using classification tasks for CCR detection and restoration. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. Claims rest on experimental accuracy metrics rather than any definitional or constructional equivalence to inputs. This is a standard empirical setup with independent content from the data and models; no load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probing classifier performance on held-out data reflects the information present in the model's hidden representations.
Reference graph
Works this paper leans on
-
[1]
Introduction Modern ASR systems exhibit significant performance dispar- ities across demographic groups, with particularly high error rates for speakers of AAE, a rule-governed variety of English shaped by historical, social, and cultural factors [1]. Multiple studies have documented racial bias in commercial ASR tech- nologies, showing word error rates (...
Pith/arXiv arXiv 2026
-
[2]
This probe directly evaluates the phonetic sensitivity of each model to CCR
on frozen encoder representations: •Segmental reduction detection: We test whether encoder representations distinguish reduced and canonical cluster pronunciations, thereby assessing whether the presence or absence of a final stop is explicitly encoded across model lay- ers. This probe directly evaluates the phonetic sensitivity of each model to CCR. •Seg...
-
[3]
For self-supervised models such as wav2vec 2.0, Pasad et al
Related Work Probing speech encoders has emerged as the standard method for dissecting the linguistic hierarchy of speech understanding [10]. For self-supervised models such as wav2vec 2.0, Pasad et al. [7] perform a detailed layer-wise analysis and show that early transformer layers are dominated by low-level acoustic cues, mid-layers maximize phonetic a...
-
[4]
report that different types of stuttered disfluencies are best discriminated from fluent speech using mid-to-late Whisper lay- ers, while Yue et al. [23] find that layers 13-15 of Whisper- medium yield peak performance for dysarthric speech detection and severity assessment. Closer to our research, Gessinger et al. [14] investigate phonemic restoration in...
-
[5]
Data Preparation 3.1.1
Methodology 3.1. Data Preparation 3.1.1. Corpus The Corpus of Regional African American Language (CORAAL) [24] serves as the foundational dataset for this study. The corpus provides rich linguistic resources, including audio recordings with time-aligned orthographic transcriptions in TextGrid format, featuring speaker-specific tiers at both utterance and ...
1927
-
[6]
Experiment 1 4.1.1
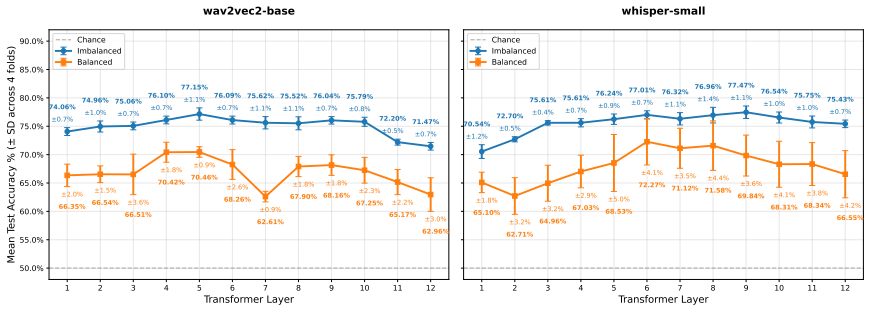
Results 4.1. Experiment 1 4.1.1. Imbalanced vs. balanced Figure 1 illustrates the layer-wise distribution of information in both wav2vec 2.0 and Whisper representations for the imbal- anced and balanced datasets described in Section 3.3.1. Both wav2vec2-base and Whisper-small clearly distinguish reduced from canonical tokens, with accuracies consistently ...
-
[7]
Our results generally follow this pattern, although in our plot the accuracy peaks more strongly at layer 5 than at layer 9, whereas they report a higher peak at layer 9 than at layer
-
[8]
Additionally, the decline after layer 10 in our data is more moderate than what they observed. In contrast, prior analyses of Whisper’s encoder (particularly for larger models) report a rising-then-plateau pattern for phonetic tasks, with performance increasing toward mid-layers and then remaining relatively sta- ble without a sharp decline toward higher ...
-
[9]
The standard deviations are broadly comparable across models, with slightly higher variability for wav2vec 2.0 in the early layers
Whisper follows a similar trajectory, but with a steeper rise toward the peak at layer 9, followed by a more moderate decline and a subsequent plateau toward the final layers. The standard deviations are broadly comparable across models, with slightly higher variability for wav2vec 2.0 in the early layers. This probe is theoretically more challenging than...
-
[10]
In each case, reduced/canonical labels were randomly shuffled while preserving original train/test splits, speaker independence, and token-cluster distributions
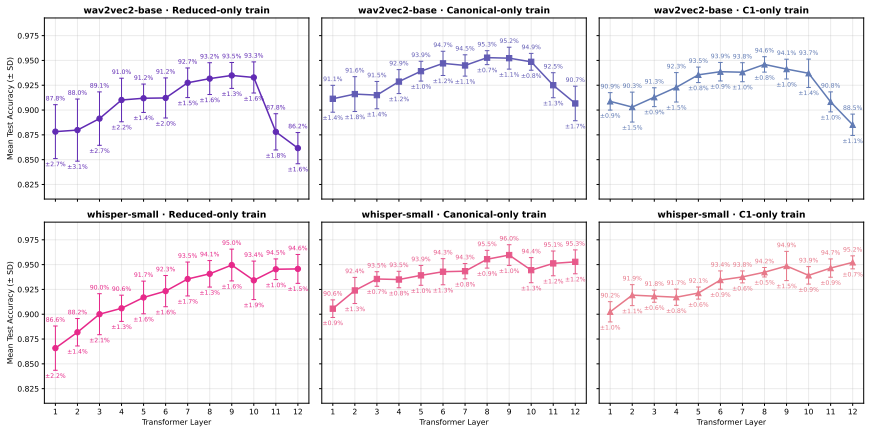
and the reduced-only train probe (Experiment 2). In each case, reduced/canonical labels were randomly shuffled while preserving original train/test splits, speaker independence, and token-cluster distributions. MLP probes trained on these shuf- fled labels yielded a baseline performance floor of 46-53%, con- firming that the observed accuracies exceed cha...
-
[11]
preceding segment
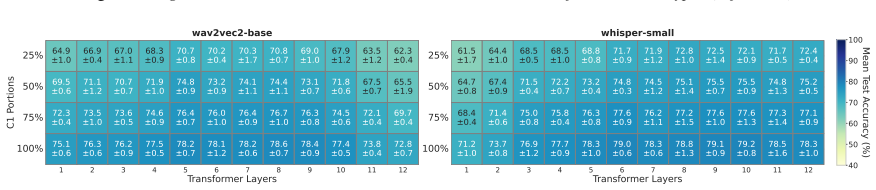
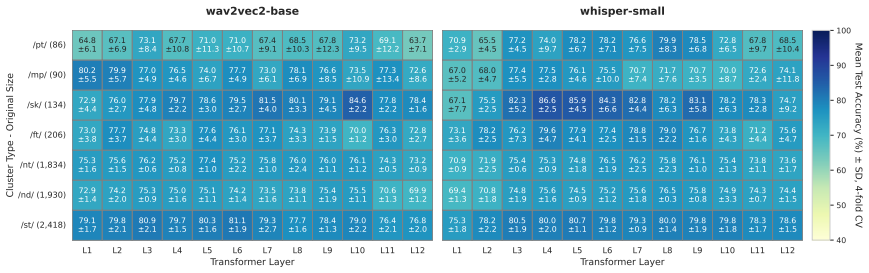
Discussion In this paper, we examined how layer-wise probing results can inform our understanding of phonological structure, focusing in particular on consonant cluster reduction, coronal stop deletion, and broader patterns in consonant cluster typology. While the Results section emphasized the computational behavior of the models, tracing how representat...
-
[12]
This suggests that Whisper’s representations may more closely mirror human perceptual patterns in this case
followed by a steady decline to 72.6%, Whisper aligns more closely with Thomas and Bailey [19]’s expectations, exhibit- ing the lowest accuracy among all clusters analyzed so far for this non-homorganic type with low susceptibility to reduction. This suggests that Whisper’s representations may more closely mirror human perceptual patterns in this case. Mo...
-
[13]
Layer-wise probing on 6,760 CORAAL tokens revealed that both wav2vec 2.0-base and Whisper-small encode CCR in a phonologically structured manner
Conclusion This study set out to determine whether self-supervised and su- pervised models treat CCR in AAE as a low-level segmental deletion phenomenon, or whether they encode it as structured, gradient phonological variation with preserved cues to under- lying forms. Layer-wise probing on 6,760 CORAAL tokens revealed that both wav2vec 2.0-base and Whisp...
-
[14]
As a result, it remains unclear to what extent our findings generalize to other speech repre- sentation models
Limitations and future work One limitation of this study is that we evaluated only two mod- els, wav2vec 2.0 and Whisper. As a result, it remains unclear to what extent our findings generalize to other speech repre- sentation models. In addition, certain CCR cluster types (e.g., /mp/, /pt/) were underrepresented in the data due to their lower frequency in...
-
[15]
The authors would like to thank Erfan Amirzadeh Shams for his helpful contribution in refining the research concept and for his technical guidance on the implementation
Acknowledgments This work is part of HM’s PhD research. The authors would like to thank Erfan Amirzadeh Shams for his helpful contribution in refining the research concept and for his technical guidance on the implementation. The authors also thank the anonymous reviewers for their insightful comments and constructive feed- back, which helped improve the ...
-
[16]
Perplexity.ai and Grok were used for English grammar checking, improving sentence readability, suggesting relevant literature, and code refining or debugging
Generative AI Use Disclosure No Generative AI tools were used to produce the content or re- sults of this paper. Perplexity.ai and Grok were used for English grammar checking, improving sentence readability, suggesting relevant literature, and code refining or debugging
-
[17]
Z. Mengesha, C. Heldreth, M. Lahav, J. Sublewski, and E. Tuennerman, “I don’t think these devices are very culturally sensitive.-impact of automated speech recognition errors on African Americans,”Frontiers in Artificial Intelligence, vol. V olume 4 - 2021, 2021. [Online]. Available: https://doi.org/10. 3389/frai.2021.725911
arXiv 2021
-
[18]
Proceedings of the National Academy of Sciences , author =
A. Koenecke, A. Nam, E. Lake, J. Nudell, M. Quartey, Z. Mengesha, C. Toups, J. R. Rickford, D. Jurafsky, and S. Goel, “Racial disparities in automated speech recognition,” Proceedings of the National Academy of Sciences, vol. 117, no. 14, pp. 7684–7689, 2020. [Online]. Available: https://doi.org/10.1073/pnas.1915768117
-
[19]
Understanding Racial Disparities in Automatic Speech Recognition: The Case of Habitual “be
J. L. Martin and K. Tang, “Understanding Racial Disparities in Automatic Speech Recognition: The Case of Habitual “be”,” inInterspeech 2020, 2020, pp. 626–630. [Online]. Available: https://doi.org/10.21437/Interspeech.2020-2893
-
[20]
Bias in automatic speech recognition: The case of African American Language,
J. L. Martin and K. E. Wright, “Bias in automatic speech recognition: The case of African American Language,”Applied Linguistics, vol. 44, no. 4, pp. 613–630, 12 2022. [Online]. Available: https://doi.org/10.1093/applin/amac066
-
[21]
Speech Communication , author =
A. B. Wassink, C. Gansen, and I. Bartholomew, “Uneven success: automatic speech recognition and ethnicity-related dialects,” Speech Communication, vol. 140, pp. 50–70, 2022. [Online]. Available: https://doi.org/10.1016/j.specom.2022.03.009
-
[22]
Interpretable sparse features for probing self-supervised speech models,
I. Parra, “Interpretable sparse features for probing self-supervised speech models,” inThe 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia- Pacific Chapter of the Association for Computational Linguistics, S. T.y.s.s, S. Shimizu, and Y . Gong, Eds. Mumbai, India: Association for Computational Linguisti...
2025
-
[23]
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” in2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2021, pp. 914–921. [Online]. Available: https: //doi.org/10.1109/ASRU51503.2021.9688093
-
[24]
wav2vec 2.0: a framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: a framework for self-supervised learning of speech representations,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates Inc., 2020. [Online]. Available: https://dl.acm.org/doi/abs/10.5555/3495724. 3496768
-
[25]
Robust speech recognition via large-scale w eak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023. [Online]. Available: https://dl.acm.org/doi/10.5555/3618408.3619590
-
[26]
A. Pasad, B. Shi, and K. Livescu, “Comparative layer-wise analysis of self-supervised speech models,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5. [Online]. Available: https://doi.org/10.1109/ICASSP49357.2023.10096149
-
[27]
Domain-informed probing of wav2vec 2.0 embeddings for phonetic features,
P. Cormac English, J. D. Kelleher, and J. Carson-Berndsen, “Domain-informed probing of wav2vec 2.0 embeddings for phonetic features,” inProceedings of the 19th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, G. Nicolai and E. Chodroff, Eds. Seattle, Washington: Association for Computational Linguistics, Jul. 2022, pp...
2022
-
[28]
M. Yang, R. C. M. C. Shekar, O. Kang, and J. H. L. Hansen, “What Can an Accent Identifier Learn? Probing Phonetic and Prosodic Information in a Wav2vec2-based Accent Identification Model,” inInterspeech 2023, 2023, pp. 1923–1927. [Online]. Available: https://doi.org/10.21437/Interspeech.2023-2254
-
[29]
Uncovering syllable constituents in the self-attention-based speech represen- tations of whisper,
E. A Shams, I. Gessinger, and J. Carson-Berndsen, “Uncovering syllable constituents in the self-attention-based speech represen- tations of whisper,” inProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, Y . Belinkov, N. Kim, J. Jumelet, H. Mohebbi, A. Mueller, and H. Chen, Eds. Miami, Florida, US: Association ...
-
[30]
I. Gessinger, E. A. Shams, and J. Carson-Berndsen, “Under the hood: phonemic restoration in transformer-based automatic speech recognition,”Computer Speech & Language, vol. 96, p. 101893, 2026. [Online]. Available: https://doi.org/10.1016/j.csl. 2025.101893
-
[31]
Labov,Sociolinguistic Patterns
W. Labov,Sociolinguistic Patterns. Philadelphia: University of Pennsylvania Press, 1972
1972
-
[32]
Schreier,Consonant Change in English Worldwide: Synchrony Meets Diachrony
D. Schreier,Consonant Change in English Worldwide: Synchrony Meets Diachrony. New York: Palgrave Macmillan, 2005
2005
-
[33]
W. Wolfram,Dialect in Society. John Wiley & Sons, Ltd, 2017, ch. 7, pp. 107–126. [Online]. Available: https: //doi.org/10.1002/9781405166256.ch7
-
[34]
Explanation in variable phonology: An exponential model of morphological constraints,
G. R. Guy, “Explanation in variable phonology: An exponential model of morphological constraints,”Language Variation and Change, vol. 3, no. 1, pp. 1–22, 1991. [Online]. Available: https://doi.org/10.1017/S0954394500000429
-
[35]
Segmental phonology of African American English,
E. R. Thomas and G. Bailey, “Segmental phonology of African American English,” inThe Oxford Handbook of African American Language. Oxford University Press, 07
-
[36]
Available: https://doi.org/10.1093/oxfordhb/ 9780199795390.013.13
[Online]. Available: https://doi.org/10.1093/oxfordhb/ 9780199795390.013.13
-
[37]
Automatic Speech Recognition of African American English: Lexical and Contextual Effects,
H. Mojarad and K. Tang, “Automatic Speech Recognition of African American English: Lexical and Contextual Effects,” in Interspeech 2025, 2025, pp. 3883–3887. [Online]. Available: https://doi.org/10.21437/Interspeech.2025-1511
-
[38]
Using wav2vec 2.0 for phonetic classification tasks: methodological aspects,
L. Kim and C. Gendrot, “Using wav2vec 2.0 for phonetic classification tasks: methodological aspects,” inInterspeech 2024, 2024, pp. 1530–1534. [Online]. Available: https: //doi.org/10.21437/Interspeech.2024-1155
-
[39]
Exploring Whisper embeddings for stutter detection: A layer-wise study,
A. Batra, B. Kar, and P. K. Das, “Exploring Whisper embeddings for stutter detection: A layer-wise study,” in2025 33rd European Signal Processing Conference (EUSIPCO), 2025, pp. 61–65. [Online]. Available: https://doi.org/10.23919/EUSIPCO63237. 2025.11226086
-
[40]
Probing Whisper for dysarthric speech in detection and assessment,
Z. Yue, D. Kayande, Z. Cvetkovic, and E. Loweimi, “Probing Whisper for dysarthric speech in detection and assessment,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.04219
-
[41]
The Corpus of Regional African American Language,
T. Kendall and C. Farrington, “The Corpus of Regional African American Language,” 2023, publisher: The Online Resources for African American Language Project. [Online]. Available: https://oraal.uoregon.edu/coraal
2023
-
[42]
T. Kendall, C. Vaughn, C. Farrington, K. Gunter, J. McLean, C. Tacata, and S. Arnson, “Considering performance in the automated and manual coding of sociolinguistic variables: Lessons from variable (ING),”Frontiers in Artificial Intelligence, vol. 4, 2021. [Online]. Available: https://doi.org/10.3389/frai. 2021.648543
-
[43]
Montreal Forced Aligner: Trainable Text- Speech Alignment Using Kaldi,
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, “Montreal Forced Aligner: Trainable Text- Speech Alignment Using Kaldi,” inProc. Interspeech 2017, 2017, pp. 498–502. [Online]. Available: https://doi.org/10.21437/ Interspeech.2017-1386
2017
-
[44]
Homophone disambiguation reveals patterns of con- text mixing in speech transformers,
H. Mohebbi, G. Chrupała, W. Zuidema, and A. Al- ishahi, “Homophone disambiguation reveals patterns of con- text mixing in speech transformers,” inProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Lin- guistics, Dec. 2023, pp. 8249–8260. ...
-
[45]
Scikit-learn: Machine learning in python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and ´Edouard Duchesnay, “Scikit-learn: Machine learning in python,”Journal of Machine Learning Research, vol. 12, no. 85, pp. 2825–2830, 2011. [Online]. Available: h...
2011
-
[46]
R. Bayley and D. Villarreal,Coronal Stop Deletion in a Rural South Texas Community, ser. Studies in English Language. Cambridge University Press, 2019, p. 198–214. [Online]. Available: https://doi.org/10.1017/9781316162316.008
-
[47]
Spoken word recognition processes and the gating paradigm,
F. Grosjean, “Spoken word recognition processes and the gating paradigm,”Perception & Psychophysics, vol. 28, no. 4, pp. 267–283, 1980. [Online]. Available: https://doi.org/10.3758/ BF03204386
1980
-
[48]
How does OpenAI’s Whisper interpret dysarthric speech?
O. Agaoglu, Z. Yue, and Y . Zhang, “How does OpenAI’s Whisper interpret dysarthric speech?” TU Delft, Tech. Rep., 2024, student thesis/project report. [Online]. Available: https://resolver.tudelft. nl/uuid:47837feb-1b2e-4bba-9fad-f92d84024abb
2024
-
[49]
A layer-wise analysis of Mandarin and English suprasegmentals in SSL speech models,
A. de la Fuente and D. Jurafsky, “A layer-wise analysis of Mandarin and English suprasegmentals in SSL speech models,” inInterspeech 2024, 2024, pp. 1290–1294. [Online]. Available: https://doi.org/10.21437/Interspeech.2024-2341
-
[50]
Phonological abstraction without phonemes in speech perception,
H. Mitterer, O. Scharenborg, and J. M. McQueen, “Phonological abstraction without phonemes in speech perception,”Cognition, vol. 129, no. 2, pp. 356–361, 2013. [Online]. Available: https://doi.org/10.1016/j.cognition.2013.07.011
-
[51]
W. Wolfram and E. R. Thomas,The development of African American English. Blackwell Publishers, 2002. [Online]. Available: https://doi.org/10.1002/9780470690178
-
[52]
The child as linguistic historian,
W. Labov, “The child as linguistic historian,”Language Variation and Change, vol. 1, no. 1, p. 85–97, 1989. [Online]. Available: https://doi.org/10.1017/S0954394500000120
-
[53]
Reexamining the development of African Amer- ican English: Evidence from isolated communities,
W. Wolfram, “Reexamining the development of African Amer- ican English: Evidence from isolated communities,”Lan- guage, vol. 79, pp. 282–316, 06 2003. [Online]. Available: https://doi.org/10.1353/lan.2003.0144
-
[54]
Phonological and phonetic characteristics of African American Vernacular English,
E. R. Thomas, “Phonological and phonetic characteristics of African American Vernacular English,”Language and Linguistics Compass, vol. 1, no. 5, pp. 450–475, 2007. [Online]. Available: https://doi.org/10.1111/j.1749-818X.2007.00029.x
-
[55]
L. J. Green,African American English: A Linguistic Introduction. Cambridge University Press, 2002
2002
-
[56]
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021. [Online]. Available: https://doi.org/10.1109/TASLP.2021.3122291
-
[57]
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing , volume=
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022. [Online]. Ava...
-
[58]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandi, A. Baevski, Y . Adi, X. Zhang, W.-N. Hsu, A. Conneau, and M. Auli, “Scaling speech technology to 1,000+ languages,”Journal of Machine Learning Research, vol. 25, no. 97, pp. 1–52, 2024. [Online]. Available: http://jmlr.org/papers/v25/23-1318.html
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.