You Don't Need to Run Every Eval
Pith reviewed 2026-06-26 08:21 UTC · model grok-4.3
The pith
Model scores across 133 benchmarks collapse to a rank-2 structure that two numbers largely determine.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
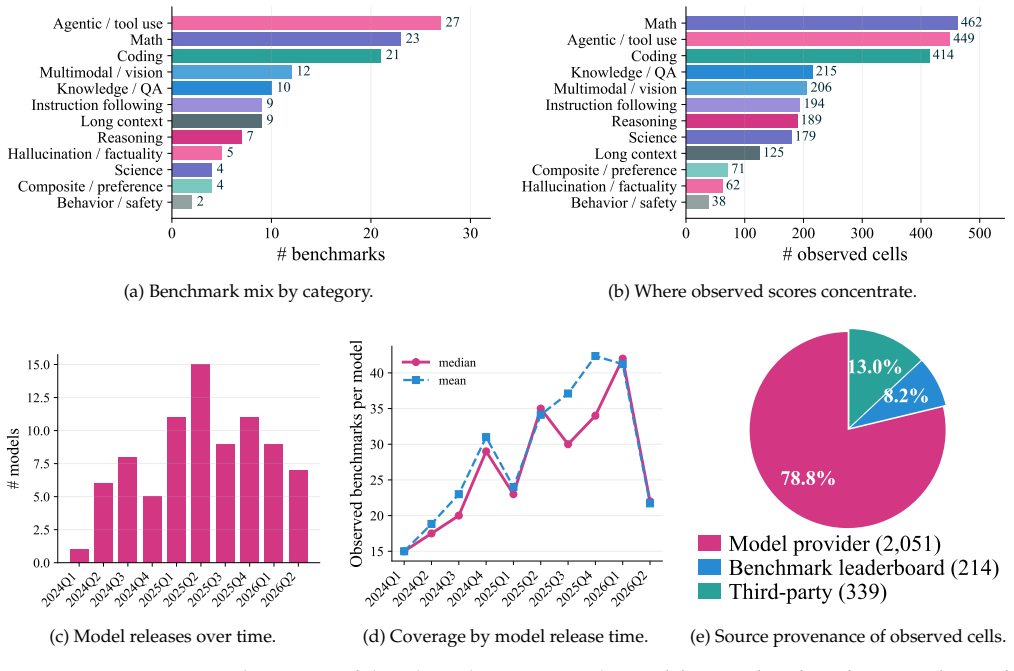
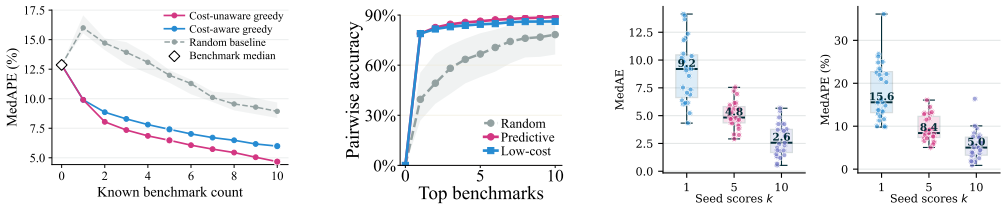
The compiled score matrix of 84 frontier models on 133 benchmarks is approximately rank-2. Two factors recover hidden scores to within 4.6 points on average and already explain over 90 percent of the shared variation. BenchPress performs logit-space rank-2 matrix completion together with a per-prediction confidence layer. Subsets of five benchmarks recover the remaining scores to within 3.93 points on average, and a cheaper five-benchmark set reaches 4.55 points.
What carries the argument
BenchPress, a logit-space rank-2 matrix completion method that recovers held-out benchmark scores with a built-in confidence layer.
If this is right
- Five benchmarks (GPQA-D, HLE, Codeforces, MMLU-Pro, ARC-AGI-1) recover the rest of a model's scores to within 3.93 points.
- A cheaper five-benchmark set (GPQA-D, MMLU-Pro, Aider Polyglot, MATH-500, AIME 2026) recovers scores to within 4.55 points.
- Two factors already explain over 90 percent of the variation among models on the benchmarks they share.
- The method supplies a per-prediction confidence layer that indicates when each recovered score can be trusted.
Where Pith is reading between the lines
- Many current benchmarks appear to measure overlapping capabilities rather than independent ones.
- If the low-rank pattern persists, organizations could release models after running only a small fixed set of evaluations.
- Newly proposed benchmarks could be tested for consistency with the existing two-factor model before adoption.
Load-bearing premise
The rank-2 structure seen in the current collection of models and benchmarks will continue to hold for future models and future benchmarks.
What would settle it
A new model whose scores across the 133 benchmarks require three or more factors to reach the same recovery accuracy as the two-factor model.
Figures











read the original abstract
A modern model release reports scores on 40+ benchmarks and the same evaluations were run many more times before it: to track training progress, compare design choices, and select the checkpoint for the release. But do we need to run every eval? We compile a public score matrix of 84 frontier models on 133 benchmarks (2,604 cells, 23.3% filled) and find it is approximately rank-2: a model's scores across all 133 benchmarks are largely determined by just two numbers. We confirm this in two ways: scores hidden from the matrix are best recovered using two factors, and two factors already explain over 90% of the variation among models on the benchmarks they share. Building on this, we design BenchPress: a logit-space rank-2 matrix completion method that recovers held-out scores to within 4.6 points, and a confidence layer that says when each prediction can be trusted. Using BenchPress, we find a subset of five benchmarks {GPQA-D, HLE, Codeforces, MMLU-Pro, ARC-AGI-1} that can recover the rest of a model's public scorecard to within 3.93 points. For a tighter inference budget, a cheaper set {GPQA-D, MMLU-Pro, Aider Polyglot, MATH-500, AIME 2026} can predict a model's evals to within 4.55. We release the score matrix, the BenchPress code, and an interactive tool that predicts any model's score on any benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compiles a sparse score matrix of 84 frontier models on 133 benchmarks (2,604 cells, 23.3% filled) and claims it is approximately rank-2, with a model's scores largely determined by two latent factors. This is supported by two confirmations: held-out scores are best recovered with two factors, and two factors explain over 90% of variance on shared benchmarks. BenchPress, a logit-space rank-2 matrix completion method with a confidence layer, recovers held-out scores to within 4.6 points. Small benchmark subsets (e.g., {GPQA-D, HLE, Codeforces, MMLU-Pro, ARC-AGI-1}) recover the full scorecard to within 3.93 points (or 4.55 for a cheaper set), and the matrix, code, and interactive tool are released.
Significance. If the rank-2 structure generalizes, the work could meaningfully reduce redundant evaluations in ML by enabling accurate prediction of many benchmark scores from a small subset, lowering compute costs for model development and comparison. The quantitative held-out recovery results, variance explanation, and open release of the score matrix, BenchPress code, and tool are concrete strengths that support reproducibility and further use.
major comments (1)
- [Abstract] Abstract and main results on generalization: the central claim that subsets suffice to recover a model's full public scorecard (and thus that not every eval needs to be run) depends on the rank-2 structure persisting for models and benchmarks outside the collected 84×133 matrix. Held-out recovery within the matrix (4.6 points) and the >90% variance claim provide internal checks, but no external validation on new models or new benchmarks is reported, leaving the generalization premise untested and load-bearing for the practical conclusions.
minor comments (1)
- [Abstract] The abstract reports recovery errors (4.6, 3.93) without reference to the typical score ranges or normalization of the benchmarks, which would help readers assess practical significance.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the clear identification of the generalization issue. We address the single major comment below and agree that a revision is warranted to clarify the scope of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and main results on generalization: the central claim that subsets suffice to recover a model's full public scorecard (and thus that not every eval needs to be run) depends on the rank-2 structure persisting for models and benchmarks outside the collected 84×133 matrix. Held-out recovery within the matrix (4.6 points) and the >90% variance claim provide internal checks, but no external validation on new models or new benchmarks is reported, leaving the generalization premise untested and load-bearing for the practical conclusions.
Authors: We agree this is a substantive limitation. All quantitative results (held-out recovery to 4.6 points, >90% variance explained, and the 3.93/4.55-point subset recoveries) are internal to the 84×133 matrix; no experiments on models or benchmarks outside this collection are presented. The abstract and introduction frame the work as evidence that the observed matrix is approximately rank-2 and that small subsets suffice to recover the remainder of that matrix, but the broader practical claim that “not every eval needs to be run” implicitly relies on the structure generalizing. We will revise the abstract to emphasize that the findings apply to the collected data, add an explicit Limitations paragraph stating that external validation on new models and benchmarks remains untested, and note this as an important direction for follow-up work. These changes will make the claims precise without overstating the evidence. revision: yes
Circularity Check
No circularity; rank-2 observation and held-out recovery are empirically independent
full rationale
The paper compiles an observed 84×133 score matrix (23.3% dense) and reports that it is approximately rank-2, confirmed by two internal checks: (1) held-out cells are recovered best with two factors, and (2) two factors explain >90% variance on shared benchmarks. BenchPress is a rank-2 matrix-completion procedure whose performance is measured on those same held-out entries. Subset selection (e.g., the five-benchmark set) is likewise evaluated by recovery error on the remaining observed cells. None of these steps reduces by construction to the inputs; the held-out recovery constitutes a genuine cross-validation test within the collected data. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. Generalization beyond the observed matrix is an untested modeling assumption, but that is a question of external validity, not circularity. The derivation chain is therefore self-contained against the internal benchmarks it reports.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank =
2
axioms (1)
- domain assumption Benchmark scores can be modeled as a rank-2 matrix in logit space.
Reference graph
Works this paper leans on
-
[1]
Foundations of Computational Mathematics , volume=
Exact Matrix Completion via Convex Optimization , author=. Foundations of Computational Mathematics , volume=
-
[2]
Journal of Machine Learning Research , volume=
Spectral Regularization Algorithms for Learning Large Incomplete Matrices , author=. Journal of Machine Learning Research , volume=
-
[3]
Computer , volume=
Matrix Factorization Techniques for Recommender Systems , author=. Computer , volume=. 2009 , publisher=
2009
-
[4]
International Conference on Machine Learning , year=
tinyBenchmarks: evaluating LLMs with fewer examples , author=. International Conference on Machine Learning , year=
-
[5]
Findings of EMNLP , year=
How Predictable Are Large Language Model Capabilities? A Case Study on BIG-bench , author=. Findings of EMNLP , year=
-
[6]
arXiv preprint arXiv:2506.07673 , year=
How Benchmark Prediction from Fewer Data Misses the Mark , author=. arXiv preprint arXiv:2506.07673 , year=
-
[7]
arXiv preprint arXiv:2410.02223 , year=
EmbedLLM: Learning Compact Representations of Large Language Models , author=. arXiv preprint arXiv:2410.02223 , year=
-
[8]
Intelligence , volume=
Evidence of Interrelated Cognitive-Like Capabilities in Large Language Models: Indications of Artificial General Intelligence or Achievement? , author=. Intelligence , volume=. 2024 , doi=
2024
-
[9]
2026 , eprint=
Rubinstein, Alexander and Raible, Benjamin and Gubri, Martin and Oh, Seong Joon , booktitle=. 2026 , eprint=
2026
-
[10]
2025 , howpublished=
Benchmark Scores = General Capability + Claudiness , author=. 2025 , howpublished=
2025
-
[11]
arXiv preprint arXiv:2512.00193 , year=
A Rosetta Stone for AI Benchmarks , author=. arXiv preprint arXiv:2512.00193 , year=
-
[12]
Rethink Reporting of Evaluation Results in
Burnell, Ryan and others , journal=. Rethink Reporting of Evaluation Results in
-
[13]
NeurIPS , year=
Observational Scaling Laws and the Predictability of Language Model Performance , author=. NeurIPS , year=
-
[14]
EMNLP , year=
Collaborative Performance Prediction for Large Language Models , author=. EMNLP , year=
-
[15]
2025 , eprint=
Kipnis, Alexander and others , booktitle=. 2025 , eprint=
2025
-
[16]
Sloth: Scaling Laws for
Polo, Felipe Maia and Somerstep, Seamus and Choshen, Leshem and Sun, Yuekai and Yurochkin, Mikhail , booktitle=. Sloth: Scaling Laws for. 2025 , eprint=
2025
-
[17]
and Stoica, Ion , booktitle=
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael and Gonzalez, Joseph E. and Stoica, Ion , booktitle=. Chatbot Arena: An Open Platform for Evaluating. 2024 , eprint=
2024
-
[18]
2026 , howpublished=
2026
-
[19]
Liu, Zirui and others , booktitle=. am-. 2025 , note=
2025
-
[20]
Performance Prediction via
Schram, Viktoria and Beck, Daniel and Cohn, Trevor , booktitle=. Performance Prediction via
-
[21]
Proceedings of NAACL , pages=
Efficient Benchmarking (of Language Models) , author=. Proceedings of NAACL , pages=
-
[22]
Benchmark Agreement Testing Done Right: A Guide for
Perlitz, Yotam and Gera, Ariel and Arviv, Ofir and Yehudai, Asaf and Bandel, Elron and Shnarch, Eyal and Shmueli-Scheuer, Michal and Choshen, Leshem , journal=. Benchmark Agreement Testing Done Right: A Guide for
-
[23]
What Are the Best Systems? New Perspectives on
Colombo, Pierre and Noiry, Nathan and Irurozki, Ekhine and Clemencon, Stephan , booktitle=. What Are the Best Systems? New Perspectives on
-
[24]
On Speeding Up Language Model Evaluation , author=. ICLR , year=. 2407.06172 , archivePrefix=
-
[25]
arXiv preprint arXiv:2306.10062 , year=
Revealing the Structure of Language Model Capabilities , author=. arXiv preprint arXiv:2306.10062 , year=
-
[26]
Ni, Jinjie and Xue, Fuzhao and Yue, Xiang and Deng, Yuntian and Shah, Mahir and Jain, Kabir and Neubig, Graham and You, Yang , booktitle=
-
[27]
Scales++: Compute Efficient Evaluation Subset Selection with Cognitive Scales Embeddings
Scales++: Compute Efficient Evaluation Subset Selection with Cognitive Scales Embeddings , author=. arXiv preprint arXiv:2510.26384 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Findings of ACL , year=
Pacchiardi, Lorenzo and Voudouris, Konstantinos and Slater, Ben and Mart. Findings of ACL , year=
-
[29]
Look Before You Leap: Estimating
Park, Jungsoo and Mendes, Ethan and Stanovsky, Gabriel and Ritter, Alan , journal=. Look Before You Leap: Estimating
-
[30]
Predicting
Koh, Woosung and Suk, Juyoung and Han, Sungjun and Yun, Se-Young and Shin, Jamin , booktitle=. Predicting. 2026 , eprint=
2026
-
[31]
Proceedings of EACL , year=
Anchor Points: Benchmarking Models with Much Fewer Examples , author=. Proceedings of EACL , year=
-
[32]
Saranathan, Gayathri and Xu, Cong and Alam, Mahammad Parwez and Kumar, Tarun and Foltin, Martin and Wong, Soon Yee and Bhattacharya, Suparna , booktitle=
-
[33]
Rethinking
Wang, Shaobo and others , booktitle=. Rethinking. 2026 , eprint=
2026
-
[34]
Journal of the Royal Statistical Society: Series B , volume=
Estimating the number of clusters in a data set via the gap statistic , author=. Journal of the Royal Statistical Society: Series B , volume=. 2001 , publisher=
2001
-
[35]
2026 , howpublished=
Qwen3.5-397B-A17B , author=. 2026 , howpublished=
2026
-
[36]
2026 , howpublished=
Kimi K2.5 , author=. 2026 , howpublished=
2026
-
[37]
2024 , howpublished=
2024
-
[38]
2025 , howpublished=
2025
-
[39]
Let's Verify Step by Step , author=. ICLR , year=. 2305.20050 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
-
[41]
2024 , howpublished=
Introducing. 2024 , howpublished=
2024
-
[42]
Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion , journal=
-
[43]
Transactions on Machine Learning Research , year=
Holistic Evaluation of Language Models , author=. Transactions on Machine Learning Research , year=
-
[44]
ICLR , year=
Measuring Massive Multitask Language Understanding , author=. ICLR , year=
-
[45]
, booktitle=
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , booktitle=
-
[46]
2025 , howpublished=
International Mathematical Olympiad , author=. 2025 , howpublished=
2025
-
[47]
Glazer, Elliot and Erdil, Ege and Besiroglu, Tamay and Chicharro, Diego and Chen, Evan and Gunning, Alex and Olsson, Caroline Falkman and Denain, Jean-Stanislas and Ho, Anson and Santos, Emily de Oliveira and others , journal=
-
[48]
2025 , howpublished=
Balunovi. 2025 , howpublished=
2025
-
[49]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
2009 , howpublished=
Codeforces , author=. 2009 , howpublished=
2009
-
[51]
Zhuo, Terry Yue and Vu, Minh Chien and Chim, Jenny and Hu, Han and Yu, Wenhao and Widyasari, Ratnadira and Yusuf, Imam Nur Bani and Zhan, Haolan and He, Junda and Paul, Indraneil and others , booktitle=
-
[52]
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and others , booktitle=
-
[53]
and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle=
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle=
-
[54]
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik , journal=
-
[55]
On the Measure of Intelligence
On the Measure of Intelligence , author=. arXiv preprint arXiv:1911.01547 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[56]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Chollet, Fran. arXiv preprint arXiv:2505.11831 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Humanity's Last Exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and others , booktitle=
-
[59]
Measuring short-form factuality in large language models
Measuring Short-Form Factuality in Large Language Models , author=. arXiv preprint arXiv:2411.04368 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Wei, Jason and Sun, Zhiqing and Papay, Spencer and McKinney, Scott and Han, Jeffrey and Fulford, Isa and Chung, Hyung Won and Passos, Alex Tachard and Fedus, William and Glaese, Amelia , journal=
-
[61]
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and others , booktitle=
-
[62]
Yue, Xiang and Zheng, Tianyu and Ni, Yuansheng and Wang, Yubo and Zhang, Kai and Tong, Shengbang and Sun, Yuxuan and Yu, Botao and Zhang, Ge and Sun, Huan and others , journal=
-
[63]
Hu, Kairui and Wu, Penghao and Pu, Fanyi and Xiao, Wang and Zhang, Yuanhan and Yue, Xiang and Li, Bo and Liu, Ziwei , journal=
-
[64]
Instruction-Following Evaluation for Large Language Models
Instruction-Following Evaluation for Large Language Models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Pyatkin, Valentina and others , journal=
-
[66]
and Stoica, Ion , journal=
Li, Tianle and Chiang, Wei-Lin and Frick, Evan and Dunlap, Lisa and Wu, Tianhao and Zhu, Banghua and Gonzalez, Joseph E. and Stoica, Ion , journal=. From Crowdsourced Data to High-Quality Benchmarks:
-
[67]
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Patwardhan, Tejal and others , year=. 2510.04374 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
2025 , howpublished=
Artificial Analysis Long Context Reasoning Benchmark , author=. 2025 , howpublished=
2025
-
[69]
2025 , howpublished=
Stanford Math Tournament 2025 , author=. 2025 , howpublished=
2025
-
[70]
2025 , eprint=
White, Colin and Dooley, Samuel and Roberts, Manley and Pal, Arka and Feuer, Ben and Jain, Siddhartha and Shwartz-Ziv, Ravid and Jain, Neel and Saifullah, Khalid and Naidu, Siddartha and others , booktitle=. 2025 , eprint=
2025
-
[71]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
2025 , howpublished=. 2509.26574 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
2025 , howpublished=
Brown University Mathematics Olympiad 2025 , author=. 2025 , howpublished=
2025
-
[74]
2025 , howpublished=. 2601.03267 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
2026 , howpublished=
Introducing. 2026 , howpublished=
2026
-
[76]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and others , journal=. The
-
[77]
arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Nature , volume=
Learning the Parts of Objects by Non-negative Matrix Factorization , author=. Nature , volume=
-
[79]
NeurIPS , year=
Probabilistic Matrix Factorization , author=. NeurIPS , year=
-
[80]
Foundations and Trends in Machine Learning , volume=
Conformal Prediction: A Gentle Introduction , author=. Foundations and Trends in Machine Learning , volume=. 2023 , doi=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.