Token-to-Token Alignment of Text Embeddings for Semantic Blending
Pith reviewed 2026-06-26 08:31 UTC · model grok-4.3
The pith
Text embedding spaces in text-to-image models contain continuous semantic structure that token-to-token alignment makes usable for interpolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
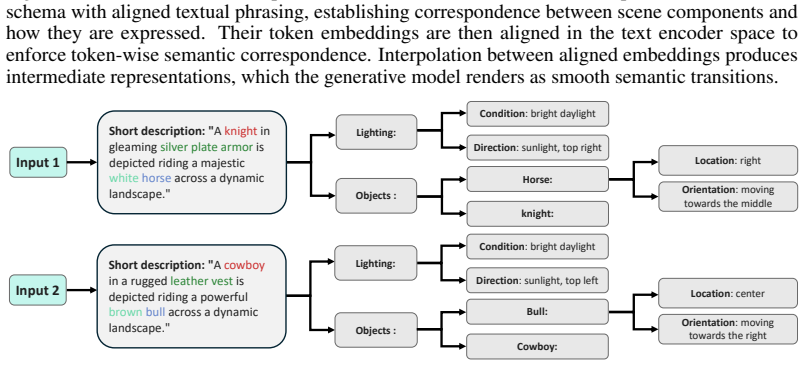
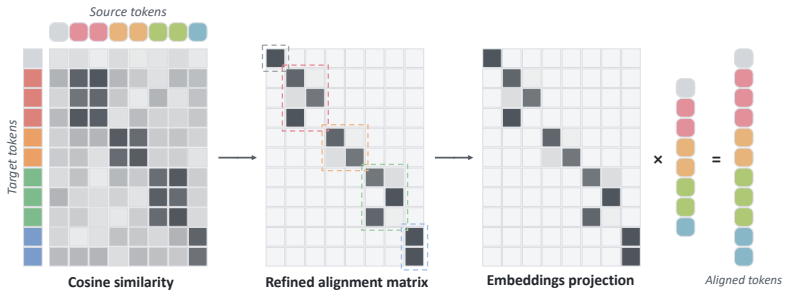
Text embedding spaces in text-to-image models implicitly encode a continuous semantic structure that becomes accessible once representations are properly aligned; the Token-to-Token alignment framework maps semantically corresponding concepts to consistent positions across prompts and aligns their embeddings, after which simple linear interpolation yields smooth and coherent semantic transitions for blending and continuous editing.
What carries the argument
Token-to-Token alignment: a two-stage process of structural alignment that rephrases prompts into shared form followed by embedding-level alignment that matches tokens by semantic similarity.
If this is right
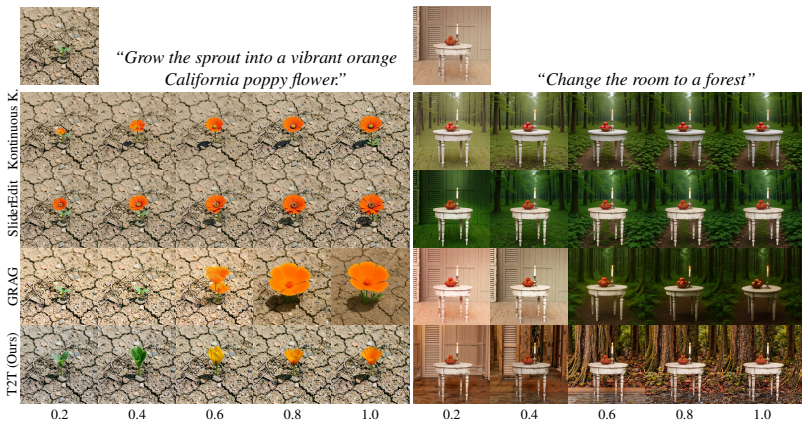
- Linear interpolation between aligned embeddings produces smooth and coherent semantic transitions.
- Image blending and continuous control of edits become feasible operations.
- Semantic control is achievable by organizing existing representations rather than modifying the generative model.
Where Pith is reading between the lines
- The same alignment principle could be tested on prompt pairs that differ in style or abstraction level to measure how far the structure generalizes.
- If the method works, it might reduce reliance on hand-crafted prompt templates by automatically standardizing token positions.
- Extending the approach to video or 3D generation would test whether the continuous structure holds across temporal or spatial dimensions.
Load-bearing premise
Arbitrary prompts can be rephrased into a shared structured form while preserving their original semantics and that semantic similarity between tokens can be determined reliably enough to produce valid correspondences.
What would settle it
Apply the alignment to a set of prompts, perform linear interpolation between the aligned embeddings, and check whether the generated images exhibit gradual semantic changes or instead show abrupt discontinuities and artifacts.
Figures





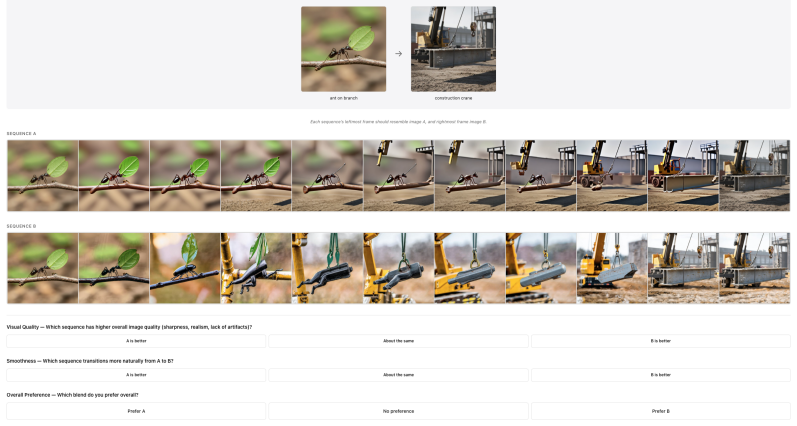




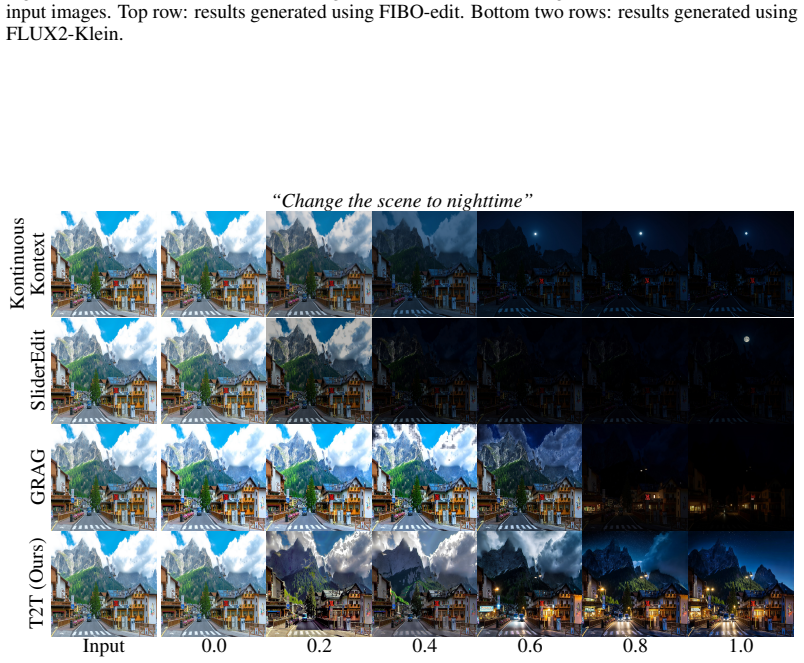


read the original abstract
In modern generative models, images are specified and controlled through text prompts. In practice, images are generated from sequences of tokens derived from these prompts. However, the space of token sequences lacks a consistent accessible structure: semantically similar images may correspond to sequences that differ in wording, ordering, and placement of concepts, while similar token sequences may encode very different semantics. This apparent lack of structure makes it difficult to perform smooth transitions in this space, hindering applications such as image blending and continuous control of edits. We argue that this limitation stems not from the absence of semantic structure, but from misalignment between representations. To address this misalignment, we introduce Token-to-Token alignment, a framework that establishes explicit semantic correspondence between tokens across prompts. Our approach transforms prompts into a structured representation in which semantically corresponding concepts are mapped to consistent positions across prompts, and then aligns their token embeddings based on semantic similarity. Concretely, the method consists of two stages: a structural alignment that rephrases prompts into a shared structured form, followed by an embedding-level alignment that matches token representations across prompts. With this alignment in place, simple linear interpolation becomes a meaningful operation, producing smooth and coherent semantic transitions and enabling applications such as blending and continuous editing. Our results show that text embedding spaces in text-to-image models implicitly encode a continuous semantic structure that becomes accessible once representations are properly aligned, suggesting that semantic control can be achieved by organizing existing representations rather than modifying the generative model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token sequences in text-to-image models lack consistent structure due to misalignment of representations, and introduces a Token-to-Token alignment framework consisting of a structural alignment stage (rephrasing arbitrary prompts into a shared structured form) followed by an embedding-level alignment stage (matching tokens across prompts by semantic similarity). With this alignment, linear interpolation becomes meaningful, enabling smooth semantic transitions for applications such as blending and continuous editing. The central thesis is that text embedding spaces already encode continuous semantic structure implicitly, which becomes accessible once representations are properly aligned, allowing semantic control by organizing existing representations rather than modifying the generative model.
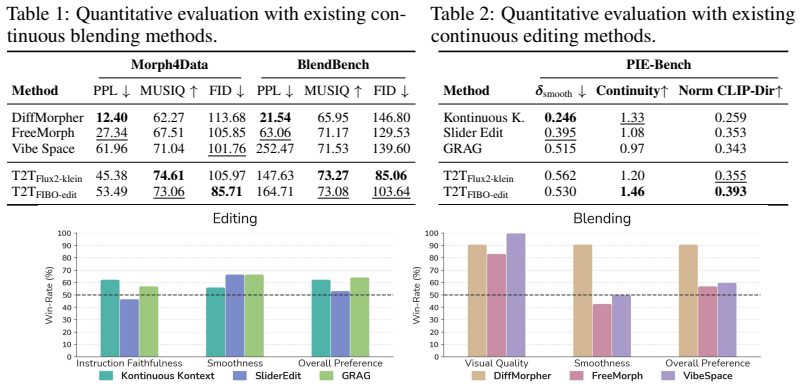
Significance. If the central claim holds after verification, the work would indicate that semantic blending and continuous control can be achieved without retraining or architectural changes to the underlying text-to-image model, potentially lowering the barrier for applications that require smooth interpolation in prompt space. The emphasis on revealing rather than imposing structure distinguishes it from purely template-driven or external-rephrasing approaches, though this distinction requires explicit testing.
major comments (2)
- [Abstract] Abstract: The claim that alignment 'reveals' implicit continuous semantic structure (rather than the structural rephrasing stage imposing it) is load-bearing for the central thesis, yet the description provides no implementation details on the rephrasing procedure, no ablation removing the rephrasing step, and no comparison showing that correspondences arise from the embedding space itself. Without such evidence the observed coherence could be an artifact of the external structuring step.
- [Abstract] Abstract: The assertion that 'simple linear interpolation becomes a meaningful operation' and produces 'smooth and coherent semantic transitions' is presented without any quantitative results, error metrics, baseline comparisons, or failure-case analysis. The soundness assessment therefore rests on an unverified procedural description rather than falsifiable predictions or empirical grounding.
minor comments (1)
- The abstract is written at a high level of generality; expanding the method description with at least one concrete example of prompt rephrasing and token correspondence would improve readability without altering the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the empirical support and clarity of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that alignment 'reveals' implicit continuous semantic structure (rather than the structural rephrasing stage imposing it) is load-bearing for the central thesis, yet the description provides no implementation details on the rephrasing procedure, no ablation removing the rephrasing step, and no comparison showing that correspondences arise from the embedding space itself. Without such evidence the observed coherence could be an artifact of the external structuring step.
Authors: We agree that explicit evidence is required to substantiate that the embedding space itself supplies the continuous structure. The rephrasing stage only normalizes prompt syntax to enable positional consistency; token correspondences are then computed exclusively via cosine similarity in the frozen text embedding space. In revision we will (1) detail the rephrasing template and procedure, (2) add an ablation that performs embedding-level alignment directly on un-rephrased prompts, and (3) include a random-matching baseline to isolate the contribution of semantic similarity. These additions will be placed in the method and experiments sections. revision: yes
-
Referee: [Abstract] Abstract: The assertion that 'simple linear interpolation becomes a meaningful operation' and produces 'smooth and coherent semantic transitions' is presented without any quantitative results, error metrics, baseline comparisons, or failure-case analysis. The soundness assessment therefore rests on an unverified procedural description rather than falsifiable predictions or empirical grounding.
Authors: The body of the manuscript reports qualitative blending results and application examples, yet the abstract does not cite quantitative metrics. We will revise the abstract to reference the specific metrics (e.g., CLIP-based semantic consistency scores and user-study preference rates) already computed in the experiments. We will also expand the experiments section with direct baseline comparisons against unaligned interpolation and a failure-case analysis. These changes will supply the requested empirical grounding. revision: yes
Circularity Check
No circularity detected; method is procedural without self-referential derivations
full rationale
The paper describes a two-stage procedural framework (structural rephrasing of prompts into shared form, followed by token embedding alignment) and concludes that embedding spaces implicitly encode continuous semantic structure. No equations, quantitative predictions, fitted parameters, or derivations are present that reduce to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central claim follows from applying the method rather than from any self-definitional or fitted-input loop, making the presentation self-contained as a methodological contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
Mikel Artetxe, Gorka Labaka, and Eneko Agirre. A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 789–798, 2018
2018
-
[2]
SmolLM3: smol, multilingual, long-context reasoner
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Carlos Miguel Patiño, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gallouédec, Kashif Rasul, Nathan Habib, Clémentine Fourrier, Hynek Kydlicek, Guilherme Penedo, Hugo Larcher, Mathieu Morlon, Vaibhav Srivastav, Joshua Lochner, Xuan-Son Nguyen, Colin Raffel, Lean...
2025
-
[3]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[4]
Continuous, subject-specific attribute control in t2i models by identifying semantic directions
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Melvin Sevi, Vincent Tao Hu, and Björn Ommer. Continuous, subject-specific attribute control in t2i models by identifying semantic directions. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13231– 13241, 2025
2025
-
[5]
Semantic parsing via paraphrasing
Jonathan Berant and Percy Liang. Semantic parsing via paraphrasing. InProceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1415–1425, 2014
2014
-
[6]
Improving image generation with better captions.Computer Science
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
2023
-
[7]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[8]
Freemorph: Tuning-free generalized image morphing with diffusion model
Yukang Cao, Chenyang Si, Jinghao Wang, and Ziwei Liu. Freemorph: Tuning-free generalized image morphing with diffusion model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18111–18120, 2025
2025
-
[9]
Text slider: Efficient and plug-and-play continuous concept control for image/video synthesis via lora adapters
Pin-Yen Chiu, I Fang, Jun-Cheng Chen, et al. Text slider: Efficient and plug-and-play continuous concept control for image/video synthesis via lora adapters. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 613–622, 2026
2026
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Word Translation Without Parallel Data
Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data.arXiv preprint arXiv:1710.04087, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
On-the-fly Repulsion in the Contextual Space for Rich Diversity in Diffusion Transformers
Omer Dahary, Benaya Koren, Daniel Garibi, and Daniel Cohen-Or. On-the-fly repulsion in the contextual space for rich diversity in diffusion transformers.arXiv preprint arXiv:2603.28762, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Noiseclr: A contrastive learning approach for unsupervised discovery of interpretable directions in diffusion models, 2023
Yusuf Dalva and Pinar Yanardag. Noiseclr: A contrastive learning approach for unsupervised discovery of interpretable directions in diffusion models, 2023
2023
-
[14]
Fluxspace: Disentangled semantic editing in rectified flow transformers, 2024
Yusuf Dalva, Kavana Venkatesh, and Pinar Yanardag. Fluxspace: Disentangled semantic editing in rectified flow transformers, 2024. 10
2024
-
[15]
Interpreting the weight space of customized diffusion models
Amil Dravid, Yossi Gandelsman, Kuan-Chieh Wang, Rameen Abdal, Gordon Wetzstein, Alexei A Efros, and Kfir Aberman. Interpreting the weight space of customized diffusion models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
-
[16]
Yigit Ekin and Yossi Gandelsman. The unreasonable effectiveness of text embedding interpolation for continuous image steering.arXiv preprint arXiv:2603.17998, 2026
-
[17]
Concept sliders: Lora adaptors for precise control in diffusion models
Rohit Gandikota, Joanna Materzy ´nska, Tingrui Zhou, Antonio Torralba, and David Bau. Concept sliders: Lora adaptors for precise control in diffusion models. InEuropean Conference on Computer Vision, pages 172–188. Springer, 2024
2024
-
[18]
Tokenverse: Versatile multi-concept personalization in token modulation space,
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, and Tali Dekel. Tokenverse: Versatile multi-concept personalization in token modulation space,
- [19]
-
[20]
Eyal Gutflaish, Eliran Kachlon, Hezi Zisman, Tal Hacham, Nimrod Sarid, Alexander Visheratin, Saar Huber- man, Gal Davidi, Guy Bukchin, Kfir Goldberg, and Ron Mokady. Generating an image from 1,000 words: Enhancing text-to-image with structured captions.arXiv preprint arXiv:2511.06876, abs/2511.06876, 2025
-
[21]
Ganspace: Discovering interpretable gan controls.Advances in neural information processing systems, 33:9841–9850, 2020
Erik Härkönen, Aaron Hertzmann, Jaakko Lehtinen, and Sylvain Paris. Ganspace: Discovering interpretable gan controls.Advances in neural information processing systems, 33:9841–9850, 2020
2020
-
[22]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[24]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.arXiv preprint arxiv:2006.11239, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Disentangling semantics and syntax in sentence embeddings with pre-trained language models
James Y Huang, Kuan-Hao Huang, and Kai-Wei Chang. Disentangling semantics and syntax in sentence embeddings with pre-trained language models. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1372–1379, 2021
2021
-
[27]
Image generation from contextually-contradictory prompts
Saar Huberman, Or Patashnik, Omer Dahary, Ron Mokady, and Daniel Cohen-Or. Image generation from contextually-contradictory prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14885–14894, 2026
2026
-
[28]
Pnp inversion: Boosting diffusion-based editing with 3 lines of code
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Pnp inversion: Boosting diffusion-based editing with 3 lines of code. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[29]
Eliran Kachlon, Alexander Visheratin, Nimrod Sarid, Tal Hacham, Eyal Gutflaish, Saar Huberman, Hezi Zisman, David Ruppin, and Ron Mokady. Bbq-to-image: Numeric bounding box and qolor control in large-scale text-to-image models.arXiv preprint arXiv:2602.20672, 2026
-
[30]
Ronen Kamenetsky, Sara Dorfman, Daniel Garibi, Roni Paiss, Or Patashnik, and Daniel Cohen-Or. Saedit: Token-level control for continuous image editing via sparse autoencoder.arXiv preprint arXiv:2510.05081, 2025
-
[31]
Analyzing and improving the image quality of stylegan
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119, 2020
2020
-
[32]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InConference on Computer Vision and Pattern Recognition 2023, 2023
2023
-
[33]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 11
2021
-
[34]
Flowedit: Inversion- free text-based editing using pre-trained flow models
Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, and Tomer Michaeli. Flowedit: Inversion- free text-based editing using pre-trained flow models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19721–19730, 2025
2025
-
[35]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[36]
Bingchen Liu, Ehsan Akhgari, Alexander Visheratin, Aleks Kamko, Linmiao Xu, Shivam Shrirao, Chase Lambert, Joao Souza, Suhail Doshi, and Daiqing Li. Playground v3: Improving text-to-image alignment with deep-fusion large language models.arXiv preprint arXiv:2409.10695, 2024
-
[37]
Llm4gen: Leveraging semantic representation of llms for text-to-image generation
Mushui Liu, Yuhang Ma, Zhen Yang, Jun Dan, Yunlong Yu, Zeng Zhao, Zhipeng Hu, Bai Liu, and Changjie Fan. Llm4gen: Leveraging semantic representation of llms for text-to-image generation. InProceedings of the AAAI conference on Artificial Intelligence, volume 39, pages 5523–5531, 2025
2025
-
[38]
Tokendial: Continuous attribute control in text-to-video via spatiotemporal token offsets,
Zhixuan Liu, Peter Schaldenbrand, Yijun Li, Long Mai, Aniruddha Mahapatra, Cusuh Ham, Jean Oh, and Jui-Hsien Wang. Tokendial: Continuous attribute control in text-to-video via spatiotemporal token offsets,
- [39]
-
[40]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
Video Analysis and Generation via a Semantic Progress Function
Gal Metzer, Sagi Polaczek, Ali Mahdavi-Amiri, Raja Giryes, and Daniel Cohen-Or. Video analysis and generation via a semantic progress function.arXiv preprint arXiv:2604.22554, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Exploiting Similarities among Languages for Machine Translation
Tomas Mikolov, Quoc V Le, and Ilya Sutskever. Exploiting similarities among languages for machine translation.arXiv preprint arXiv:1309.4168, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[43]
Rishubh Parihar, Or Patashnik, Daniil Ostashev, R Venkatesh Babu, Daniel Cohen-Or, and Kuan-Chieh Wang. Kontinuous kontext: Continuous strength control for instruction-based image editing.arXiv preprint arXiv:2510.08532, 2025
-
[44]
Styleclip: Text-driven manipulation of stylegan imagery
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. InProceedings of the IEEE/CVF international conference on computer vision, pages 2085–2094, 2021
2085
-
[45]
Now Foundations and Trends, 2019
Gabriel Peyré and Marco Cuturi.Computational optimal transport: With applications to data science. Now Foundations and Trends, 2019
2019
-
[46]
Zero-Shot Text-to-Image Generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation, 2021. URL https://arxiv.org/abs/2102.12092
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[47]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[48]
Pathways on the image manifold: Image editing via video generation
Noam Rotstein, Gal Yona, Daniel Silver, Roy Velich, David Bensaïd, and Ron Kimmel. Pathways on the image manifold: Image editing via video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7857–7866, 2025
2025
-
[49]
Dynamic programming algorithm optimization for spoken word recognition
Hiroaki Sakoe and Seibi Chiba. Dynamic programming algorithm optimization for spoken word recognition. IEEE transactions on acoustics, speech, and signal processing, 26(1):43–49, 1978
1978
-
[50]
Interfacegan: Interpreting the disentangled face representation learned by gans.IEEE transactions on pattern analysis and machine intelligence, 44(4): 2004–2018, 2020
Yujun Shen, Ceyuan Yang, Xiaoou Tang, and Bolei Zhou. Interfacegan: Interpreting the disentangled face representation learned by gans.IEEE transactions on pattern analysis and machine intelligence, 44(4): 2004–2018, 2020
2004
-
[51]
Plug-and-play diffusion features for text- driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text- driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023
1921
-
[52]
Alon Wolf, Chen Katzir, Kfir Aberman, and Or Patashnik. Continuous control of editing models via adaptive-origin guidance.arXiv preprint arXiv:2602.03826, 2026
-
[53]
Uncovering the disentanglement capability in text-to-image diffusion models
Qiucheng Wu, Yujian Liu, Handong Zhao, Ajinkya Kale, Trung Bui, Tong Yu, Zhe Lin, Yang Zhang, and Shiyu Chang. Uncovering the disentanglement capability in text-to-image diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1900–1910, 2023. 12
1900
-
[54]
Zhenyu Xu, Xiaoqi Shen, Haotian Nan, and Xinyu Zhang. Numerikontrol: Adding numeric control to diffusion transformers for instruction-based image editing.arXiv preprint arXiv:2511.23105, 2025
-
[55]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Huzheng Yang, Katherine Xu, Andrew Lu, Michael D Grossberg, Yutong Bai, and Jianbo Shi. Vibe spaces for creatively connecting and expressing visual concepts.arXiv preprint arXiv:2512.14884, 2025
-
[57]
Hu Yu, Hao Luo, Fan Wang, and Feng Zhao. Uncovering the text embedding in text-to-image diffusion models.arXiv preprint arXiv:2404.01154, 2024
-
[58]
Arman Zarei, Samyadeep Basu, Mobina Pournemat, Sayan Nag, Ryan Rossi, and Soheil Feizi. Slideredit: Continuous image editing with fine-grained instruction control.arXiv preprint arXiv:2511.09715, 2025
-
[59]
Diffmorpher: Unleashing the capability of diffusion models for image morphing
Kaiwen Zhang, Yifan Zhou, Xudong Xu, Bo Dai, and Xingang Pan. Diffmorpher: Unleashing the capability of diffusion models for image morphing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7912–7921, 2024
2024
-
[60]
a samurai standing and holding a sword in the middle of a forest
Xuanpu Zhang, Xuesong Niu, Ruidong Chen, Dan Song, Jianhao Zeng, Penghui Du, Haoxiang Cao, Kai Wu, and An-an Liu. Group relative attention guidance for image editing.arXiv preprint arXiv:2510.24657, 2025. A Additional details A.1 Benchmarks Morph4dataFollowing the protocol of FreeMorph [ 8], we evaluate semantic interpolation on Morph4Data, a curated data...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.