Universal Guideline-Driven Image Clustering via a Hybrid LLM Agent
Pith reviewed 2026-06-26 01:17 UTC · model grok-4.3
The pith
A hybrid LLM agent uses textual guidelines and generative proxies to cluster images across any scenario without task-specific training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
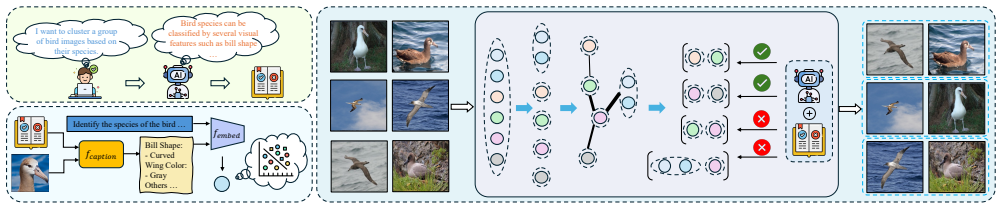
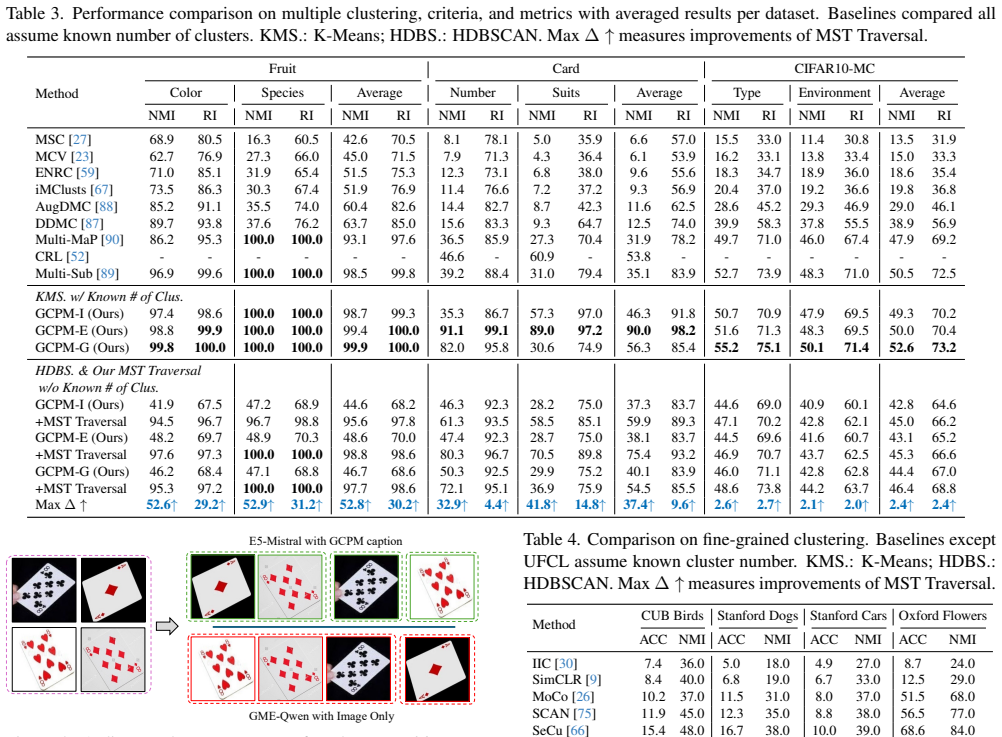
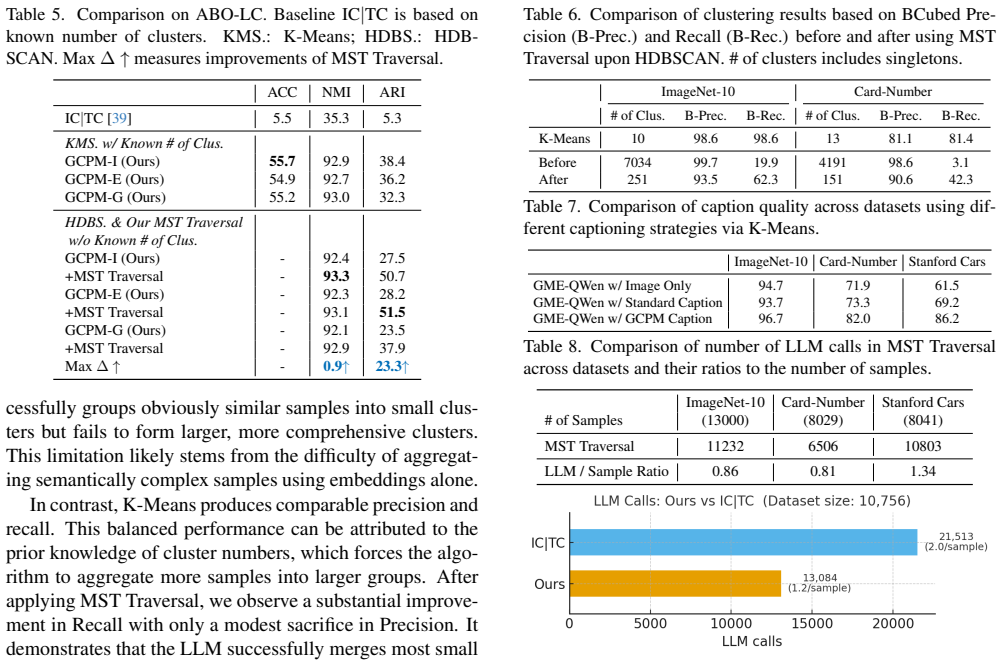
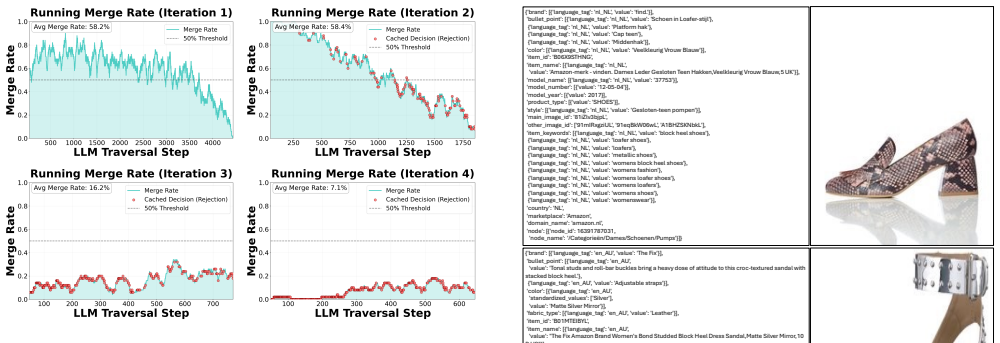
The Guideline-Driven Image Clustering Agent is the first framework that unifies image clustering across fundamentally different tasks by ingesting textual guidelines, generating guideline-aware embeddings through Generative Concept Proxy Modeling that extracts concept proxies without any task-specific training, and applying LLM Traversal based on Minimum Spanning Tree to selectively invoke reasoning only for complex semantic judgments, thereby generalizing from general to fine-grained categorization, global to local criteria, and balanced to long-tail distributions while outperforming specialized methods.
What carries the argument
Generative Concept Proxy Modeling, which produces guideline-aware embeddings by extracting concept proxies from the input textual guidelines so that a single embedding space serves many different clustering rules.
If this is right
- Any new clustering goal can be addressed by writing a fresh textual guideline rather than collecting labels or retraining a model.
- The same trained components remain usable when the balance of classes changes or when criteria shift from global appearance to local detail.
- LLM calls occur only on selected edges of the minimum spanning tree, limiting expensive reasoning to the hardest decisions.
- The framework can replace multiple narrow clustering pipelines in applications that encounter changing user-defined grouping rules.
Where Pith is reading between the lines
- If the proxy extraction step proves robust, similar guideline-driven proxies might be tested on other embedding-based tasks such as retrieval or few-shot classification.
- The selective use of LLM traversal suggests a broader pattern for hybrid systems that reserve expensive reasoning for graph edges where cheaper distances disagree with semantic cues.
- Long-term deployment would require checking whether repeated guideline changes gradually degrade the fixed embedding space.
Load-bearing premise
That concept proxies generated from guidelines will produce embeddings effective for fundamentally different clustering rules without any task-specific training or fine-tuning.
What would settle it
Run the method on a new image dataset whose clustering rule (for example, grouping by subtle lighting direction) is described only in a guideline never used in its development and measure whether accuracy falls below a task-specific baseline trained directly on that rule.
Figures





read the original abstract
Unifying image clustering across different clustering scenarios remains challenging due to fundamental gaps among tasks. We introduce a Guideline-Driven Image Clustering Agent, the first universal framework that bridges these gaps through textual guidelines. To incorporate complex guidelines without task-specific training, we propose Generative Concept Proxy Modeling, which generates guideline-aware embeddings via concept proxy extraction. For scenarios requiring automatic cluster discovery, we introduce LLM Traversal based on Minimum Spanning Tree that selectively applies LLM reasoning for complex semantic judgments. Our method generalizes across diverse clustering scenarios spanning from general to fine-grained categorization, from global to local criteria, and from balanced to long-tail distributions. Our framework consistently outperforms specialized methods across diverse clustering tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a Guideline-Driven Image Clustering Agent as the first universal framework for image clustering that incorporates textual guidelines. It proposes Generative Concept Proxy Modeling to produce guideline-aware embeddings without task-specific training or fine-tuning, and LLM Traversal based on Minimum Spanning Tree for automatic cluster discovery in scenarios requiring semantic judgments. The method is claimed to generalize across scenarios spanning general to fine-grained categorization, global to local criteria, and balanced to long-tail distributions, with consistent outperformance over specialized methods.
Significance. If the empirical results hold, the work could be significant for offering a training-free, guideline-driven unification of image clustering tasks that have previously required specialized models. The hybrid LLM agent design, particularly the concept proxy extraction and MST-based traversal, represents a novel direction. However, the complete absence of quantitative results, baselines, datasets, or experimental protocol in the abstract prevents any assessment of whether the claimed generality across fundamentally different criteria is achieved.
major comments (2)
- [Abstract] Abstract: the central claim that the framework 'consistently outperforms specialized methods across diverse clustering tasks' is presented with no quantitative results, baselines, experimental protocol, or tables, rendering the universality assertion unverifiable and load-bearing for the paper's contribution.
- [Method] Method description (Generative Concept Proxy Modeling): no formal guarantee, parameter-free derivation, or ablation is supplied showing that LLM-generated concept proxies preserve the necessary distinctions for local vs. global or balanced vs. long-tail criteria without task-specific adaptation; this directly bears on the skeptic's concern that the proxy mechanism may fail to transfer across guideline types.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key performance metric or dataset name to support the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework 'consistently outperforms specialized methods across diverse clustering tasks' is presented with no quantitative results, baselines, experimental protocol, or tables, rendering the universality assertion unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract's strong claim would benefit from additional context to improve verifiability. In the revised version we will expand the abstract to include a concise statement of the experimental protocol (e.g., the range of datasets and guideline types evaluated) together with a high-level summary of the quantitative gains (average improvement margins over the strongest specialized baselines). The full tables, baselines, datasets, and protocol remain in the Experiments section; the abstract revision will simply make the universality claim traceable without exceeding typical length constraints. revision: yes
-
Referee: [Method] Method description (Generative Concept Proxy Modeling): no formal guarantee, parameter-free derivation, or ablation is supplied showing that LLM-generated concept proxies preserve the necessary distinctions for local vs. global or balanced vs. long-tail criteria without task-specific adaptation; this directly bears on the skeptic's concern that the proxy mechanism may fail to transfer across guideline types.
Authors: The Generative Concept Proxy Modeling is deliberately parameter-free by construction: it extracts concept proxies directly from the LLM's frozen reasoning without any gradient updates or task-specific fine-tuning. While a closed-form theoretical guarantee is difficult to obtain for black-box LLMs, the method's transferability is supported by the empirical results across the paper's diverse guideline regimes. To directly address the concern, we will add a targeted ablation study in the revision that isolates performance on local-versus-global and balanced-versus-long-tail guideline subsets, thereby providing concrete evidence of cross-criterion robustness. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The paper introduces an empirical framework (Guideline-Driven Image Clustering Agent with Generative Concept Proxy Modeling and LLM Traversal) whose central claims rest on experimental outperformance across tasks rather than any mathematical derivation, equation, or parameter fit. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The generality claim is presented as a design property of the method, not derived from prior self-work or ansatz smuggling. The result is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The claude 3 model family: Opus, sonnet, haiku
Anthropic. The claude 3 model family: Opus, sonnet, haiku. 2, 3
-
[2]
Entity-based cross- document coreferencing using the vector space model
Amit Bagga and Breck Baldwin. Entity-based cross- document coreferencing using the vector space model. In COLING 1998 Volume 1: The 17th international conference on computational linguistics, 1998. 7
1998
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 3, 4, 5
Pith/arXiv arXiv 2025
-
[4]
Onegan: Simultaneous unsuper- vised learning of conditional image generation, foreground segmentation, and fine-grained clustering
Yaniv Benny and Lior Wolf. Onegan: Simultaneous unsuper- vised learning of conditional image generation, foreground segmentation, and fine-grained clustering. InEuropean Con- ference on Computer Vision, pages 514–530. Springer, 2020. 2, 5, 7, 10
2020
-
[5]
Ergun, Chen Wang, and Sam- son Zhou
Vladimir Braverman, Jon C. Ergun, Chen Wang, and Sam- son Zhou. Learning-augmented hierarchical clustering. In Forty-second International Conference on Machine Learn- ing, 2025. 2
2025
-
[6]
Density-based clustering based on hierarchical density esti- mates
Ricardo JGB Campello, Davoud Moulavi, and J ¨org Sander. Density-based clustering based on hierarchical density esti- mates. InPacific-Asia conference on knowledge discovery and data mining, pages 160–172. Springer, 2013. 2, 4
2013
-
[7]
Global-local dirichlet processes for clustering grouped data in the presence of group-specific idiosyncratic variables
Arhit Chakrabarti, Yang Ni, Debdeep Pati, and Bani Mallick. Global-local dirichlet processes for clustering grouped data in the presence of group-specific idiosyncratic variables. In Forty-second International Conference on Machine Learn- ing, 2025. 2
2025
-
[8]
Incremental clustering and dynamic information retrieval
Moses Charikar, Chandra Chekuri, Tom ´as Feder, and Rajeev Motwani. Incremental clustering and dynamic information retrieval. InProceedings of the twenty-ninth annual ACM symposium on Theory of computing, pages 626–635, 1997. 5
1997
-
[9]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on ma- chine learning, pages 1597–1607. PmLR, 2020. 5, 7, 10
2020
-
[10]
Infogan: Interpretable rep- resentation learning by information maximizing generative adversarial nets.Advances in neural information processing systems, 29, 2016
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable rep- resentation learning by information maximizing generative adversarial nets.Advances in neural information processing systems, 29, 2016. 5, 7, 10
2016
-
[11]
Ziye Chen, Yiqun Duan, Riheng Zhu, Zhenbang Sun, and Mingming Gong. Agent-centric personalized mul- tiple clustering with multi-modal llms.arXiv preprint arXiv:2503.22241, 2025. 2, 7
arXiv 2025
-
[12]
Agent-centric personalized multiple clus- tering with multi-modal llms, 2025
Ziye Chen, Yiqun Duan, Riheng Zhu, Zhenbang Sun, and Mingming Gong. Agent-centric personalized multiple clus- tering with multi-modal llms, 2025. 8
2025
-
[13]
An analysis of single-layer networks in unsupervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 215–223. JMLR Workshop and Conference Proceedings, 2011. 5, 4
2011
-
[14]
Abo: Dataset and benchmarks for real-world 3d object un- derstanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object un- derstanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21126– 21136, 2022. 5, 3
2022
-
[15]
Nearest neighbor matching for deep clustering
Zhiyuan Dang, Cheng Deng, Xu Yang, Kun Wei, and Heng Huang. Nearest neighbor matching for deep clustering. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 13693–13702, 2021. 5, 6, 9
2021
-
[16]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 5, 4
2009
-
[17]
Information-theoretic generative clustering of documents, 2024
Xin Du and Kumiko Tanaka-Ishii. Information-theoretic generative clustering of documents, 2024. 2, 9
2024
-
[18]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, J ¨org Sander, Xiaowei Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, pages 226–231,
-
[19]
Mark: Multi-agent collabora- tion with ranking guidance for text-attributed graph cluster- ing
Yiwei Fu, Yuxing Zhang, Chunchun Chen, JianwenMa Jian- wenMa, Quan Yuan, Rong-Cheng Tu, Xinli Huang, Wei Ye, Xiao Luo, and Minghua Deng. Mark: Multi-agent collabora- tion with ranking guidance for text-attributed graph cluster- ing. InFindings of the Association for Computational Lin- guistics: ACL 2025, pages 6057–6072, 2025. 2, 4, 8
2025
-
[20]
Personalized clustering via targeted representation learning
Xiwen Geng, Suyun Zhao, Yixin Yu, Borui Peng, Pan Du, Hong Chen, Cuiping Li, and Mengdie Wang. Personalized clustering via targeted representation learning. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 16790–16798, 2025. 2, 3
2025
-
[21]
Cards image dataset-classification
gpiosenka. Cards image dataset-classification. Kaggle dataset. Accessed: 2025-09-07. 3
2025
-
[22]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Ghesh- laghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020. 5, 6, 9
2020
-
[23]
Joris Gu ´erin and Byron Boots. Improving image cluster- ing with multiple pretrained cnn feature extractors.arXiv preprint arXiv:1807.07760, 2018. 5, 7, 10
Pith/arXiv arXiv 2018
-
[24]
Task-aware clustering for prompting vision-language models
Fusheng Hao, Fengxiang He, Fuxiang Wu, Tichao Wang, Chengqun Song, and Jun Cheng. Task-aware clustering for prompting vision-language models. InProceedings of the 9 Computer Vision and Pattern Recognition Conference, pages 14745–14755, 2025. 2
2025
-
[25]
Algorithm as 136: A k-means clustering algorithm.Journal of the royal sta- tistical society
John A Hartigan and Manchek A Wong. Algorithm as 136: A k-means clustering algorithm.Journal of the royal sta- tistical society. series c (applied statistics), 28(1):100–108,
-
[26]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9729–9738, 2020. 5, 7, 10
2020
-
[27]
Finding multiple stable clusterings.Knowledge and Infor- mation Systems, 51(3):991–1021, 2017
Juhua Hu, Qi Qian, Jian Pei, Rong Jin, and Shenghuo Zhu. Finding multiple stable clusterings.Knowledge and Infor- mation Systems, 51(3):991–1021, 2017. 5, 7, 10
2017
-
[28]
Deep se- mantic clustering by partition confidence maximisation
Jiabo Huang, Shaogang Gong, and Xiatian Zhu. Deep se- mantic clustering by partition confidence maximisation. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 8849–8858, 2020. 5, 6, 9
2020
-
[29]
Learning representation for clustering via prototype scattering and positive sampling.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 45(6):7509–7524,
Zhizhong Huang, Jie Chen, Junping Zhang, and Hongming Shan. Learning representation for clustering via prototype scattering and positive sampling.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 45(6):7509–7524,
-
[30]
Invariant in- formation clustering for unsupervised image classification and segmentation
Xu Ji, Joao F Henriques, and Andrea Vedaldi. Invariant in- formation clustering for unsupervised image classification and segmentation. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 9865–9874,
-
[31]
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. E5-v: Universal embeddings with multimodal large language models.arXiv preprint arXiv:2407.12580, 2024. 3
Pith/arXiv arXiv 2024
-
[32]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. Vlm2vec: Training vision-language models for massive multimodal embedding tasks.arXiv preprint arXiv:2410.05160, 2024. 3
Pith/arXiv arXiv 2024
-
[33]
Hwiyeol Jo, Hyunwoo Lee, Kang Min Yoo, and Tai- woo Park. Zerodl: Zero-shot distribution learning for text clustering via large language models.arXiv preprint arXiv:2406.13342, 2024. 2, 4, 8
arXiv 2024
-
[34]
Towards better-than-2 approximation for constrained corre- lation clustering
Andreas Kalavas, Evangelos Kipouridis, and Nithin Varma. Towards better-than-2 approximation for constrained corre- lation clustering. InForty-second International Conference on Machine Learning, 2025. 2
2025
-
[35]
Novel dataset for fine-grained image categorization
Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao, and Li Fei-Fei. Novel dataset for fine-grained image categorization. InFirst Workshop on Fine-Grained Visual Categorization, IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, 2011. 3, 5
2011
-
[36]
Yunji Kim and Jung-Woo Ha. Contrastive fine-grained class clustering via generative adversarial networks.arXiv preprint arXiv:2112.14971, 2021. 2, 5, 7, 10
arXiv 2021
-
[37]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In Proceedings of the IEEE international conference on com- puter vision workshops, pages 554–561, 2013. 5
2013
-
[38]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 5, 4
2009
-
[39]
Image clustering con- ditioned on text criteria.arXiv preprint arXiv:2310.18297,
Sehyun Kwon, Jaeseung Park, Minkyu Kim, Jaewoong Cho, Ernest K Ryu, and Kangwook Lee. Image clustering con- ditioned on text criteria.arXiv preprint arXiv:2310.18297,
-
[40]
Dual mutual infor- mation constraints for discriminative clustering
Hongyu Li, Lefei Zhang, and Kehua Su. Dual mutual infor- mation constraints for discriminative clustering. InProceed- ings of the AAAI conference on artificial intelligence, pages 8571–8579, 2023. 6, 9
2023
-
[41]
Junnan Li, Pan Zhou, Caiming Xiong, and Steven CH Hoi. Prototypical contrastive learning of unsupervised representa- tions.arXiv preprint arXiv:2005.04966, 2020. 5, 6, 9
arXiv 2005
-
[42]
Mixnmatch: Multifactor disentanglement and encoding for conditional image generation
Yuheng Li, Krishna Kumar Singh, Utkarsh Ojha, and Yong Jae Lee. Mixnmatch: Multifactor disentanglement and encoding for conditional image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8039–8048, 2020. 5, 7, 10
2020
-
[43]
Contrastive clustering
Yunfan Li, Peng Hu, Zitao Liu, Dezhong Peng, Joey Tianyi Zhou, and Xi Peng. Contrastive clustering. InProceedings of the AAAI conference on artificial intelligence, pages 8547– 8555, 2021. 5, 6, 9
2021
-
[44]
Twin contrastive learning for online clustering.International Journal of Computer Vision, 130 (9):2205–2221, 2022
Yunfan Li, Mouxing Yang, Dezhong Peng, Taihao Li, Jiantao Huang, and Xi Peng. Twin contrastive learning for online clustering.International Journal of Computer Vision, 130 (9):2205–2221, 2022. 5, 6, 9
2022
-
[45]
Image clustering with external guidance
Yunfan Li, Peng Hu, Dezhong Peng, Jiancheng Lv, Jianping Fan, and Xi Peng. Image clustering with external guidance. arXiv preprint arXiv:2310.11989, 2023. 2, 6, 7
arXiv 2023
-
[46]
Learning from sample stability for deep clustering
Zhixin Li, Yuheng Jia, Junhui Hou, et al. Learning from sample stability for deep clustering. InForty-second Inter- national Conference on Machine Learning. 1, 2, 3, 5, 6
-
[47]
I-Fan Lin, Faegheh Hasibi, and Suzan Verberne. Spill: Domain-adaptive intent clustering based on selection and pooling with large language models.arXiv preprint arXiv:2503.15351, 2025. 2, 4, 8
arXiv 2025
-
[48]
Mm-embed: Universal multimodal retrieval with multimodal llms.arXiv preprint arXiv:2411.02571, 2024
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal llms.arXiv preprint arXiv:2411.02571, 2024. 3
arXiv 2024
-
[49]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 7
Pith/arXiv arXiv 2024
-
[50]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 8
2023
-
[51]
Interactive deep clustering via value mining
Honglin Liu, Peng Hu, Changqing Zhang, Yunfan Li, and Xi Peng. Interactive deep clustering via value mining. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 1, 2, 5, 6
2024
-
[52]
Conditional representation learning for customized tasks
Honglin Liu, Chao Sun, Peng Hu, Yunfan Li, and Xi Peng. Conditional representation learning for customized tasks. Advances in Neural Information Processing Systems, 38: 31706–31737, 2026. 5, 7
2026
-
[53]
Llm-guided 10 semantic-aware clustering for topic modeling
Jianghan Liu, Ziyu Shang, Wenjun Ke, Peng Wang, Zhizhao Luo, Jiajun Liu, Guozheng Li, and Yining Li. Llm-guided 10 semantic-aware clustering for topic modeling. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18420–18435, 2025. 2, 4, 8
2025
-
[54]
Mingxuan Liu, Zhun Zhong, Jun Li, Gianni Franchi, Sub- hankar Roy, and Elisa Ricci. Organizing unstructured im- age collections using natural language.arXiv preprint arXiv:2410.05217, 2024. 3
Pith/arXiv arXiv 2024
-
[55]
Lamra: Large multimodal model as your advanced retrieval assistant
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4015–4025, 2025. 3
2025
-
[56]
Llm as dataset ana- lyst: Subpopulation structure discovery with large language model
Yulin Luo, Ruichuan An, Bocheng Zou, Yiming Tang, Ji- aming Liu, and Shanghang Zhang. Llm as dataset ana- lyst: Subpopulation structure discovery with large language model. InEuropean Conference on Computer Vision, pages 235–252. Springer, 2024. 3, 5
2024
-
[57]
Multivariate observations
J MacQueen. Multivariate observations. InProceedings ofthe 5th Berkeley Symposium on Mathematical Statisticsand Probability, pages 281–297, 1967. 1
1967
-
[58]
Divclust: Controlling diversity in deep clus- tering
Ioannis Maniadis Metaxas, Georgios Tzimiropoulos, and Ioannis Patras. Divclust: Controlling diversity in deep clus- tering. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 3418–3428,
-
[59]
Deep embedded non- redundant clustering
Lukas Miklautz, Dominik Mautz, Muzaffer Can Altinigneli, Christian B ¨ohm, and Claudia Plant. Deep embedded non- redundant clustering. InProceedings of the AAAI conference on artificial intelligence, pages 5174–5181, 2020. 7, 10
2020
-
[60]
Segment any cell: A sam-based auto- prompting fine-tuning framework for nuclei segmentation
Saiyang Na, Yuzhi Guo, Feng Jiang, Hehuan Ma, Jean Gao, and Junzhou Huang. Segment any cell: A sam-based auto- prompting fine-tuning framework for nuclei segmentation. IEEE Transactions on Neural Networks and Learning Sys- tems, 2025. 2
2025
-
[61]
Forensic self-descriptions are all you need for zero-shot de- tection, open-set source attribution, and clustering of ai- generated images
Tai D Nguyen, Aref Azizpour, and Matthew C Stamm. Forensic self-descriptions are all you need for zero-shot de- tection, open-set source attribution, and clustering of ai- generated images. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 3040–3050,
-
[62]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. InIn- dian Conference on Computer Vision, Graphics and Image Processing, 2008. 3, 5
2008
-
[63]
Spice: Seman- tic pseudo-labeling for image clustering.IEEE Transactions on Image Processing, 31:7264–7278, 2022
Chuang Niu, Hongming Shan, and Ge Wang. Spice: Seman- tic pseudo-labeling for image clustering.IEEE Transactions on Image Processing, 31:7264–7278, 2022. 5, 6, 9
2022
-
[64]
Rapid se- lection and ordering of in-context demonstrations via prompt embedding clustering
Kha Pham, Hung Le, Man Ngo, and Truyen Tran. Rapid se- lection and ordering of in-context demonstrations via prompt embedding clustering. InThe Thirteenth International Con- ference on Learning Representations, 2025. 2
2025
-
[65]
Control-oriented clustering of visual latent representation.arXiv preprint arXiv:2410.05063, 2024
Han Qi, Haocheng Yin, and Heng Yang. Control-oriented clustering of visual latent representation.arXiv preprint arXiv:2410.05063, 2024. 2
arXiv 2024
-
[66]
Stable cluster discrimination for deep clustering
Qi Qian. Stable cluster discrimination for deep clustering. InProceedings of the IEEE/CVF international conference on computer vision, pages 16645–16654, 2023. 1, 5, 6, 7, 9, 10
2023
-
[67]
A diversified attention model for interpretable multiple clusterings.IEEE Trans- actions on Knowledge and Data Engineering, 35(9):8852– 8864, 2022
Liangrui Ren, Guoxian Yu, Jun Wang, Lei Liu, Carlotta Domeniconi, and Xiangliang Zhang. A diversified attention model for interpretable multiple clusterings.IEEE Trans- actions on Knowledge and Data Engineering, 35(9):8852– 8864, 2022. 5, 7, 10
2022
-
[68]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 5, 7, 10
2022
-
[69]
You never cluster alone.Advances in Neural Information Processing Systems, 34:27734–27746,
Yuming Shen, Ziyi Shen, Menghan Wang, Jie Qin, Philip Torr, and Ling Shao. You never cluster alone.Advances in Neural Information Processing Systems, 34:27734–27746,
-
[70]
Finegan: Unsupervised hierarchical disentanglement for fine-grained object generation and discovery
Krishna Kumar Singh, Utkarsh Ojha, and Yong Jae Lee. Finegan: Unsupervised hierarchical disentanglement for fine-grained object generation and discovery. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6490–6499, 2019. 5, 7, 10
2019
-
[71]
Fixmatch: Simplifying semi-supervised learning with consistency and confidence
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in neural information processing systems, 33:596– 608, 2020. 5, 6, 9
2020
-
[72]
One embedder, any task: Instruction-finetuned text embeddings.arXiv preprint arXiv:2212.09741, 2022
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A Smith, Luke Zettlemoyer, and Tao Yu. One embedder, any task: Instruction-finetuned text embeddings.arXiv preprint arXiv:2212.09741, 2022. 2, 5, 7
arXiv 2022
-
[73]
Yaling Tao, Kentaro Takagi, and Kouta Nakata. Clustering- friendly representation learning via instance discrimination and feature decorrelation.arXiv preprint arXiv:2106.00131,
-
[74]
Mice: Mixture of contrastive experts for unsupervised image clustering
Tsung Wei Tsai, Chongxuan Li, and Jun Zhu. Mice: Mixture of contrastive experts for unsupervised image clustering. In International conference on learning representations, 2020. 6, 9
2020
-
[75]
Scan: Learning to classify images without labels
Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool. Scan: Learning to classify images without labels. InEuropean con- ference on computer vision, pages 268–285. Springer, 2020. 5, 6, 7, 9, 10
2020
-
[76]
Large language mod- els enable few-shot clustering, 2023
Vijay Viswanathan, Kiril Gashteovski, Carolin Lawrence, Tongshuang Wu, and Graham Neubig. Large language mod- els enable few-shot clustering, 2023. 2, 4, 8
2023
-
[77]
Constrained k-means clustering with background knowledge
Kiri Wagstaff, Claire Cardie, Seth Rogers, Stefan Schr ¨odl, et al. Constrained k-means clustering with background knowledge. InIcml, pages 577–584, 2001. 5, 6, 9
2001
-
[78]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical report,
2011
-
[79]
Bridge the gap between supervised and unsupervised learning for fine-grained classification.In- formation Sciences, 649:119653, 2023
Jiabao Wang, Yang Li, Xiu-Shen Wei, Hang Li, Zhuang Miao, and Rui Zhang. Bridge the gap between supervised and unsupervised learning for fine-grained classification.In- formation Sciences, 649:119653, 2023. 5, 7, 10 11
2023
-
[80]
Improving text em- beddings with large language models.arXiv preprint arXiv:2401.00368, 2023
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Improving text em- beddings with large language models.arXiv preprint arXiv:2401.00368, 2023. 2, 3, 5, 7
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.