ReMMD: Realistic Multilingual Multi-Image Agentic Verification for Multimodal Misinformation Detection
Pith reviewed 2026-06-26 00:31 UTC · model grok-4.3
The pith
ReMMD-Agent achieves the highest five-way veracity accuracy on a new multilingual multi-image misinformation benchmark while cutting verification costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
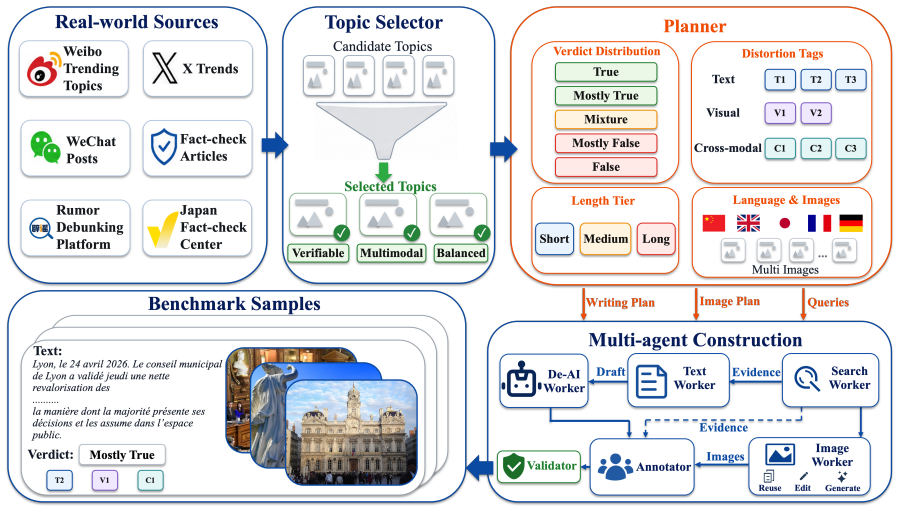
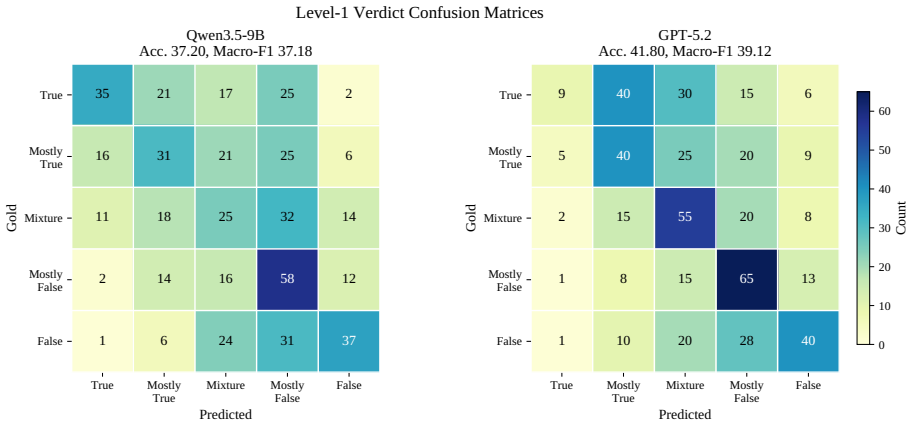
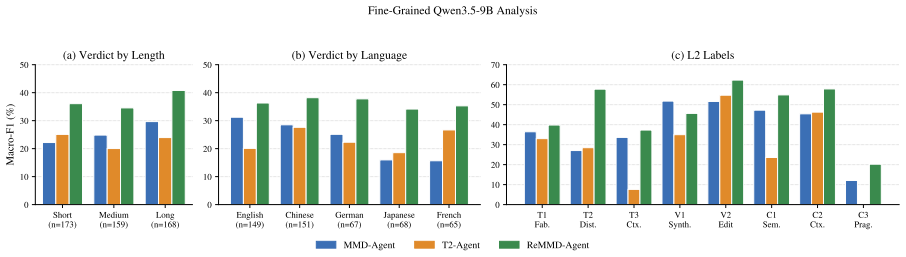
ReMMD-Agent obtains the best five-way veracity performance, with 41.80% accuracy and 39.12% macro-F1 using GPT-5.2, while reducing cost by 17.5% relative to MMD-Agent and 79.9% relative to T2-Agent, by decomposing posts into atomic points, building a reusable evidence set, and predicting structured L1/L2/L3 outputs on a benchmark with five monolingual languages, two cross-lingual settings, three text-length tiers, multi-image posts, five-way veracity labels, eight distortion labels, evidence provenance, and rationales.
What carries the argument
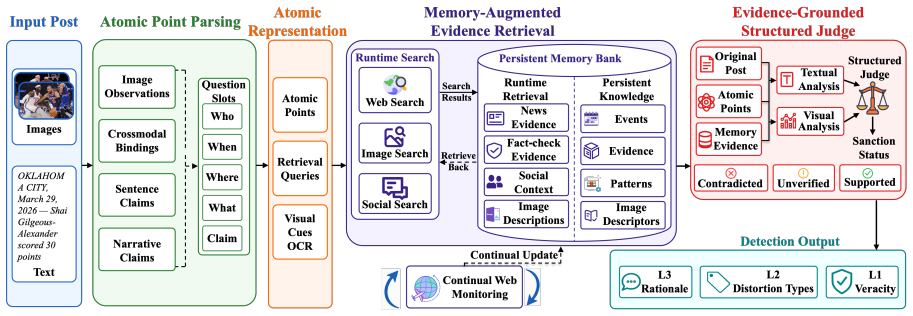
ReMMD-Agent, a persistent-memory verifier that decomposes posts into atomic points, builds a reusable evidence set, and predicts structured L1/L2/L3 outputs.
If this is right
- ReMMD-Agent outperforms proprietary systems, open LVLMs, MMD-Agent, and T2-Agent on five-way veracity classification.
- The method supports structured outputs that include L1/L2/L3 levels along with evidence provenance and rationales.
- The benchmark covers five languages in monolingual and cross-lingual modes, multi-image posts, and three text-length tiers.
- Verification cost drops 17.5 percent versus MMD-Agent and 79.9 percent versus T2-Agent while accuracy rises.
Where Pith is reading between the lines
- The persistent-memory reuse pattern could extend to other long-form verification tasks that involve repeated evidence lookup across sessions.
- If the structured decomposition proves robust, future work might test whether it reduces hallucination rates in base models on similar tasks.
- Larger-scale deployment on live social media feeds would test whether the reported cost savings persist when evidence search must run continuously.
Load-bearing premise
The 500 samples and associated labels in ReMMDBench constitute a representative and reliable sample of real-world multimodal misinformation across languages, image counts, and distortion types.
What would settle it
Re-evaluate all compared systems on a new collection of at least 2000 additional labeled multimodal posts drawn from the same sources but with different distribution of languages, image counts, and distortion types; if the accuracy ordering or cost savings change, the central performance claim does not hold.
Figures




read the original abstract
Multimodal misinformation detection is increasingly important because viral posts now combine long multilingual narratives, several images, mixed provenance, and subtle text--image framing errors. Existing benchmarks and methods remain poorly matched to this setting: they usually isolate short captions, single images, binary labels, or one manipulation source, while agentic verification remains costly under realistic evidence search. We present ReMMD, a realistic multilingual multi-image agentic verification framework for multimodal misinformation detection. ReMMD includes ReMMDBench, a real-world multimodal misinformation detection benchmark with 500 samples, 2,756 images, five monolingual languages, two cross-lingual settings, three text-length tiers, multi-image posts, five-way veracity labels, eight distortion labels, evidence provenance, and rationales. It also includes ReMMD-Agent, a persistent-memory verifier that decomposes posts into atomic points, builds a reusable evidence set, and predicts structured L1/L2/L3 outputs. Across proprietary systems, open LVLMs, MMD-Agent, and T2-Agent, ReMMD-Agent obtains the best five-way veracity performance, with 41.80% accuracy and 39.12% macro-F1 using GPT-5.2, while reducing cost by 17.5% relative to MMD-Agent and 79.9% relative to T2-Agent. The project is available at https://dang-ai.github.io/ReMMD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReMMD, a framework for agentic verification of multimodal misinformation in realistic settings involving multilingual text, multiple images, and mixed provenance. It contributes ReMMDBench, a new benchmark of 500 samples (2,756 images, 5 languages, 3 text tiers, multi-image posts) with 5-way veracity labels, 8 distortion labels, evidence provenance, and rationales, plus ReMMD-Agent, a persistent-memory agent that decomposes posts, builds reusable evidence, and outputs structured predictions. On this benchmark, ReMMD-Agent with GPT-5.2 achieves the highest five-way veracity performance (41.80% accuracy, 39.12% macro-F1) while cutting costs 17.5% vs. MMD-Agent and 79.9% vs. T2-Agent; the project is released publicly.
Significance. If the benchmark construction and labels are shown to be reliable and representative, the work would supply a more ecologically valid testbed for multimodal misinformation than prior single-image or binary-label resources, while demonstrating that structured agentic decomposition with memory reuse can improve both accuracy and efficiency over direct baselines. The public release of the benchmark and code is a clear strength for reproducibility and follow-on research.
major comments (1)
- [Abstract / ReMMDBench section] Abstract and ReMMDBench description: the headline results (41.80% accuracy and 39.12% macro-F1 on five-way veracity) rest entirely on the 500-sample ReMMDBench, yet no sampling protocol, inter-annotator agreement statistics, label-validation procedure, statistical significance tests, or external corpus comparison are supplied. Without these, it is impossible to determine whether the reported superiority over MMD-Agent and T2-Agent generalizes beyond this particular set.
minor comments (1)
- [Abstract] The abstract lists 'five monolingual languages, two cross-lingual settings' without naming the languages or settings; adding this information would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the need to demonstrate the reliability and representativeness of ReMMDBench. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / ReMMDBench section] Abstract and ReMMDBench description: the headline results (41.80% accuracy and 39.12% macro-F1 on five-way veracity) rest entirely on the 500-sample ReMMDBench, yet no sampling protocol, inter-annotator agreement statistics, label-validation procedure, statistical significance tests, or external corpus comparison are supplied. Without these, it is impossible to determine whether the reported superiority over MMD-Agent and T2-Agent generalizes beyond this particular set.
Authors: We agree that the current manuscript does not supply these details and that they are necessary to support claims of generalizability. The ReMMDBench section provides an overview of the dataset composition but omits the requested methodological specifics. In the revised manuscript we will expand this section with: (1) a full sampling protocol describing how the 500 samples were drawn from real-world multilingual social-media sources across the five languages and text tiers; (2) inter-annotator agreement statistics (e.g., Fleiss’ kappa or percentage agreement) obtained during the five-way veracity and eight-way distortion labeling; (3) the label-validation procedure, including the number of annotators, adjudication steps, and any expert review; (4) statistical significance tests (e.g., McNemar’s test) comparing ReMMD-Agent against MMD-Agent and T2-Agent on the five-way task; and (5) a comparison table relating ReMMDBench’s statistics (image count, language distribution, label balance) to prior multimodal misinformation corpora. These additions will directly address the concern about whether the observed performance gains are tied to this particular 500-sample set. revision: yes
Circularity Check
No circularity; empirical evaluation on newly introduced benchmark
full rationale
The paper introduces ReMMDBench (500 samples with explicit composition details) and ReMMD-Agent, then reports empirical accuracy/F1 and cost metrics against external baselines (MMD-Agent, T2-Agent, various LVLMs). No equations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatz smuggling appear in the provided text. Performance numbers are direct measurements on the held-out benchmark, not reductions by construction. The representativeness concern is a validity issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark labels accurately reflect veracity and distortion categories.
invented entities (2)
-
ReMMDBench
no independent evidence
-
ReMMD-Agent
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Alimohammad Beigi, Bohan Jiang, Dawei Li, Zhen Tan, Pouya Shaeri, Tharindu Kumarage, Amrita Bhattacharjee, and Huan Liu. 2025. Can llms improve multimodal fact-checking by asking relevant questions? In 2025 IEEE International Conference on Big Data (BigData), pages 2732--2741. IEEE
2025
-
[3]
Canyu Chen and Kai Shu. 2024. Can llm-generated misinformation be detected? In International Conference on Learning Representations, volume 2024, pages 34687--34726
2024
-
[4]
Sanxing Chen, Yukun Huang, and Bhuwan Dhingra. 2025. Real-time factuality assessment from adversarial feedback. In Proceedings of ACL
2025
-
[5]
Xing Cui, Yueying Zou, Zekun Li, Peipei Li, Xinyuan Xu, Xuannan Liu, and Huaibo Huang. 2026. T2agent: A tool-augmented multimodal misinformation detection agent with monte carlo tree search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 175--183
2026
-
[6]
Hwang, Antoine Bosselut, and Yejin Choi
Jeff Da, Maxwell Forbes, Rowan Zellers, Anthony Zheng, Jena D. Hwang, Antoine Bosselut, and Yejin Choi. 2021. Edited media understanding frames: Reasoning about the intent and implications of visual misinformation. In Proceedings of ACL
2021
-
[8]
Anastasia Giachanou, Guobiao Zhang, and Paolo Rosso. 2020. https://doi.org/10.1109/DSAA49011.2020.00091 Multimodal multi-image fake news detection . In 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), pages 647--654
-
[9]
Hao Guo, Zihan Ma, Zhi Zeng, Minnan Luo, Weixin Zeng, Jiuyang Tang, and Xiang Zhao. 2025. Each fake news is fake in its own way: An attribution multi-granularity benchmark for multimodal fake news detection. In Proceedings of the AAAI conference on artificial intelligence, volume 39, pages 228--236
2025
-
[10]
Andreas Hanselowski, Christian Stab, Claudia Schulz, Zile Li, and Iryna Gurevych. 2019. A richly annotated corpus for different tasks in automated fact-checking. In Proceedings of the 23rd conference on computational natural language learning (CoNLL), pages 493--503
2019
-
[11]
Xuming Hu, Zhijiang Guo, GuanYu Wu, Aiwei Liu, Lijie Wen, and Philip S Yu. 2022. Chef: A pilot chinese dataset for evidence-based fact-checking. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3362--3376
2022
-
[12]
Runsheng Huang, Liam Dugan, Yue Yang, and Chris Callison-Burch. 2024. Miragenews: Multimodal realistic ai-generated news detection. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16436--16448
2024
-
[14]
Fanxiao Li, Jiaying Wu, Tingchao Fu, Yunyun Dong, Bingbing Song, and Wei Zhou. 2026. Drifting away from truth: Genai-driven news diversity challenges lvlm-based misinformation detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 588--596
2026
-
[16]
Xuannan Liu, Zekun Li, Pei Li, Huaibo Huang, Shuhan Xia, Xing Cui, Linzhi Huang, Weihong Deng, and Zhaofeng He. 2025. Mmfakebench: A mixed-source multimodal misinformation detection benchmark for lvlms. In International Conference on Learning Representations, volume 2025, pages 86327--86352
2025
-
[17]
Grace Luo, Trevor Darrell, and Anna Rohrbach. 2021. Newsclippings: Automatic generation of out-of-context multimodal media. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6801--6817
2021
-
[18]
Jinna Lv, Yuan Gao, Li Li, Lei Shi, and Siyu Li. 2025. Multi-modal fake news detection: A comprehensive survey on deep learning technology, advances, and challenges. Journal of King Saud University Computer and Information Sciences, 37(9):306
2025
-
[19]
Manus . 2026. Manus . https://manus.im/. Version 1.6. Accessed: 2026-05-26
2026
-
[21]
Qiong Nan, Juan Cao, Yongchun Zhu, Yanyan Wang, and Jintao Li. 2021. Mdfend: Multi-domain fake news detection. In Proceedings of the 30th ACM international conference on information & knowledge management, pages 3343--3347
2021
-
[22]
Dan S Nielsen and Ryan McConville. 2022. Mumin: A large-scale multilingual multimodal fact-checked misinformation social network dataset. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, pages 3141--3153
2022
-
[23]
OpenAI . 2026. ChatGPT . https://chatgpt.com/. Accessed: 2026-05-26
2026
-
[24]
Stefanos-Iordanis Papadopoulos, Christos Koutlis, Symeon Papadopoulos, and Panagiotis C Petrantonakis. 2024. Verite: a robust benchmark for multimodal misinformation detection accounting for unimodal bias. International Journal of Multimedia Information Retrieval, 13(1):4
2024
-
[27]
Michael Schlichtkrull, Zhijiang Guo, and Andreas Vlachos. 2023. Averitec: A dataset for real-world claim verification with evidence from the web. Advances in Neural Information Processing Systems, 36:65128--65167
2023
-
[28]
Serper . 2026. Serper API . https://serper.dev/. Accessed: 2026-05-26
2026
-
[29]
Rui Shao, Tianxing Wu, and Ziwei Liu. 2023. Detecting and grounding multi-modal media manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6904--6913
2023
-
[30]
Segev Shlomov, Alon Oved, Sami Marreed, Ido Levy, Offer Akrabi, Avi Yaeli, ukasz Str a k, Elizabeth Koumpan, Yinon Goldshtein, Eilam Shapira, Nir Mashkif, and Asaf Adi. 2026. https://doi.org/10.1609/aaai.v40i47.41485 From benchmarks to business impact: Deploying IBM generalist agent in enterprise production . In Proceedings of the AAAI Conference on Artif...
-
[31]
Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. 2020. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big data, 8(3):171--188
2020
-
[32]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. Fever: a large-scale dataset for fact extraction and verification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809--819
2018
-
[33]
Soroush Vosoughi, Deb Roy, and Sinan Aral. 2018. https://doi.org/10.1126/science.aap9559 The spread of true and false news online . Science, 359(6380):1146--1151
-
[34]
Shengkang Wang, Hongzhan Lin, Ziyang Luo, Zhen Ye, Guang Chen, and Jing Ma. 2025. https://arxiv.org/abs/2406.11288 Mfc-bench: Benchmarking multimodal fact-checking with large vision-language models . In ICLR Workshop on Data Problems for Foundation Models
arXiv 2025
-
[38]
Cheng Xu and Nan Yan. 2025. Triplefact: Defending data contamination in the evaluation of llm-driven fake news detection. In Proceedings of ACL
2025
-
[39]
Qingzheng Xu, Huiqiang Chen, Heming Du, Hu Zhang, Szymon ukasik, Tianqing Zhu, and Xin Yu. 2024. M3a: A multimodal misinformation dataset for media authenticity analysis. Computer Vision and Image Understanding, 249:104205
2024
-
[40]
Qingzheng Xu, Heming Du, Szymon ukasik, Tianqing Zhu, Sen Wang, and Xin Yu. 2025. MDAM3 : A misinformation detection and analysis framework for multitype multimodal media. In Proceedings of the ACM Web Conference (WWW)
2025
-
[41]
Bingjian Yang, Danni Xu, Kaipeng Niu, Wenxuan Liu, Zheng Wang, and Mohan Kankanhalli. 2025 a . A new dataset and benchmark for grounding multimodal misinformation. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 12571--12577
2025
-
[42]
Shuo Yang, Yuqin Dai, Guoqing Wang, Xinran Zheng, Jinfeng Xu, Jinze Li, Zhenzhe Ying, Weiqiang Wang, and Edith CH Ngai. 2025 b . Realfactbench: A benchmark for evaluating large language models in real-world fact-checking. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 13435--13441
2025
-
[43]
Barry Menglong Yao, Aditya Shah, Lichao Sun, Jin-Hee Cho, and Lifu Huang. 2023. End-to-end multimodal fact-checking and explanation generation: A challenging dataset and models. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2733--2743
2023
-
[44]
Ye Zhu, Yunan Wang, and Zitong Yu. 2025. Multimodal fake news detection: Mfnd dataset and shallow-deep multitask learning. In Proceedings of IJCAI
2025
-
[45]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
FEVER: a large-scale dataset for fact extraction and VERification , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages=
2018
-
[46]
Science , volume=
The spread of true and false news online , author=. Science , volume=. 2018 , doi=
2018
-
[47]
Big data , volume=
Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media , author=. Big data , volume=. 2020 , publisher=
2020
-
[48]
Proceedings of the 23rd conference on computational natural language learning (CoNLL) , pages=
A richly annotated corpus for different tasks in automated fact-checking , author=. Proceedings of the 23rd conference on computational natural language learning (CoNLL) , pages=
-
[49]
``Liar, Liar Pants on Fire'': A New Benchmark Dataset for Fake News Detection
``Liar, Liar Pants on Fire'': A New Benchmark Dataset for Fake News Detection , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=. 2017 , address=. doi:10.18653/v1/P17-2067 , url=
-
[50]
Augenstein, Isabelle and Lioma, Christina and Wang, Dongsheng and Chaves Lima, Lucas and Hansen, Casper and Hansen, Christian and Simonsen, Jakob Grue , booktitle=. 2019 , address=. doi:10.18653/v1/D19-1475 , url=
-
[51]
Harvard Kennedy School (HKS) Misinformation Review , year=
``Fact-checking'' fact checkers: A data-driven approach , author=. Harvard Kennedy School (HKS) Misinformation Review , year=. doi:10.37016/mr-2020-126 , url=
-
[52]
Proceedings of the twelfth language resources and evaluation conference , pages=
Fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection , author=. Proceedings of the twelfth language resources and evaluation conference , pages=
-
[53]
arXiv preprint arXiv:2011.04088 , year=
Mm-covid: A multilingual and multimodal data repository for combating covid-19 disinformation , author=. arXiv preprint arXiv:2011.04088 , year=
arXiv 2011
-
[54]
arXiv preprint arXiv:2101.06278 , year=
Cosmos: Catching out-of-context misinformation with self-supervised learning , author=. arXiv preprint arXiv:2101.06278 , year=
-
[55]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Newsclippings: Automatic generation of out-of-context multimodal media , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[56]
Proceedings of the 30th ACM international conference on information & knowledge management , pages=
MDFEND: Multi-domain fake news detection , author=. Proceedings of the 30th ACM international conference on information & knowledge management , pages=
-
[57]
Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval , pages=
Mumin: A large-scale multilingual multimodal fact-checked misinformation social network dataset , author=. Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[58]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
CHEF: A pilot Chinese dataset for evidence-based fact-checking , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[59]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
End-to-end multimodal fact-checking and explanation generation: A challenging dataset and models , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[60]
International Journal of Multimedia Information Retrieval , volume=
Verite: a robust benchmark for multimodal misinformation detection accounting for unimodal bias , author=. International Journal of Multimedia Information Retrieval , volume=. 2024 , publisher=
2024
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Detecting and grounding multi-modal media manipulation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[62]
Advances in Neural Information Processing Systems , volume=
Averitec: A dataset for real-world claim verification with evidence from the web , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Computer Vision and Image Understanding , volume=
M3a: A multimodal misinformation dataset for media authenticity analysis , author=. Computer Vision and Image Understanding , volume=. 2024 , publisher=
2024
-
[64]
International Conference on Learning Representations , volume=
Can llm-generated misinformation be detected? , author=. International Conference on Learning Representations , volume=
-
[65]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
MiRAGeNews: Multimodal realistic AI-generated news detection , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[66]
Proceedings of the AAAI conference on artificial intelligence , volume=
Each fake news is fake in its own way: An attribution multi-granularity benchmark for multimodal fake news detection , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[67]
International Conference on Learning Representations , volume=
Mmfakebench: A mixed-source multimodal misinformation detection benchmark for lvlms , author=. International Conference on Learning Representations , volume=
-
[68]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
T2Agent: A Tool-augmented Multimodal Misinformation Detection Agent with Monte Carlo Tree Search , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[69]
From Benchmarks to Business Impact: Deploying
Shlomov, Segev and Oved, Alon and Marreed, Sami and Levy, Ido and Akrabi, Offer and Yaeli, Avi and Str. From Benchmarks to Business Impact: Deploying. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2026 , doi=
2026
-
[70]
Journal of King Saud University Computer and Information Sciences , volume=
Multi-modal fake news detection: A comprehensive survey on deep learning technology, advances, and challenges , author=. Journal of King Saud University Computer and Information Sciences , volume=. 2025 , publisher=
2025
-
[71]
2025 IEEE International Conference on Big Data (BigData) , pages=
Can LLMs improve multimodal fact-checking by asking relevant questions? , author=. 2025 IEEE International Conference on Big Data (BigData) , pages=. 2025 , organization=
2025
-
[72]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Drifting Away from Truth: GenAI-Driven News Diversity Challenges LVLM-Based Misinformation Detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[73]
ICLR Workshop on Data Problems for Foundation Models , year=
MFC-Bench: Benchmarking Multimodal Fact-Checking with Large Vision-Language Models , author=. ICLR Workshop on Data Problems for Foundation Models , year=
-
[74]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
A New Dataset and Benchmark for Grounding Multimodal Misinformation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[75]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Realfactbench: A benchmark for evaluating large language models in real-world fact-checking , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[76]
Proceedings of the ACM Web Conference (WWW) , year=
Xu, Qingzheng and Du, Heming and. Proceedings of the ACM Web Conference (WWW) , year=
-
[77]
arXiv preprint arXiv:2508.09999 , year=
XFacta: Contemporary, Real-World Dataset and Evaluation for Multimodal Misinformation Detection with Multimodal LLMs , author=. arXiv preprint arXiv:2508.09999 , year=
-
[78]
arXiv preprint arXiv:2601.08611 , year=
VeriTaS: The First Dynamic Benchmark for Multimodal Automated Fact-Checking , author=. arXiv preprint arXiv:2601.08611 , year=
-
[79]
arXiv preprint arXiv:2510.23508 , year=
M4FC: A Multimodal, Multilingual, Multicultural, Multitask Real-World Fact-Checking Dataset , author=. arXiv preprint arXiv:2510.23508 , year=
-
[80]
arXiv preprint arXiv:2604.04815 , year=
LiveFact: A Dynamic, Time-Aware Benchmark for LLM-Driven Fake News Detection , author=. arXiv preprint arXiv:2604.04815 , year=
-
[81]
Proceedings of ACL , year=
TripleFact: Defending Data Contamination in the Evaluation of LLM-Driven Fake News Detection , author=. Proceedings of ACL , year=
-
[82]
Proceedings of IJCAI , year=
Multimodal Fake News Detection: MFND Dataset and Shallow-Deep Multitask Learning , author=. Proceedings of IJCAI , year=
-
[83]
Proceedings of ACL , year=
Edited Media Understanding Frames: Reasoning About the Intent and Implications of Visual Misinformation , author=. Proceedings of ACL , year=
-
[84]
arXiv preprint arXiv:1808.06686 , year=
Deep Multimodal Image-Repurposing Detection , author=. arXiv preprint arXiv:1808.06686 , year=
-
[85]
Proceedings of ACL , year=
Real-time Factuality Assessment from Adversarial Feedback , author=. Proceedings of ACL , year=
-
[86]
2026 , howpublished=
2026
-
[87]
From Mind to Machine: The Rise of
Shen, Minjie and Li, Yanshu and Chen, Lulu and Fan, Zhichao and Li, Yanhang and Yang, Qikai , journal=. From Mind to Machine: The Rise of
-
[88]
2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA) , pages=
Multimodal Multi-image Fake News Detection , author=. 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA) , pages=. 2020 , keywords=
2020
-
[89]
Proceedings of the 2020 International Conference on Multimedia Retrieval , pages=
Multimodal Analytics for Real-world News using Measures of Cross-modal Entity Consistency , author=. Proceedings of the 2020 International Conference on Multimedia Retrieval , pages=. 2020 , publisher=. doi:10.1145/3372278.3390670 , isbn=
-
[90]
Navigating the Digital World as Humans Do: Universal Visual Grounding for
Gou, Boyu and Wang, Ruohan and Zheng, Boyuan and Xie, Yanan and Chang, Cheng and Shu, Yiheng and Sun, Huan and Su, Yu , booktitle=. Navigating the Digital World as Humans Do: Universal Visual Grounding for. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.