Latent Visual States for Efficient Multimodal Reasoning
Pith reviewed 2026-06-26 00:36 UTC · model grok-4.3
The pith
EVA generates continuous latent visual states as adaptive tokens during reasoning to improve both accuracy and inference speed in multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
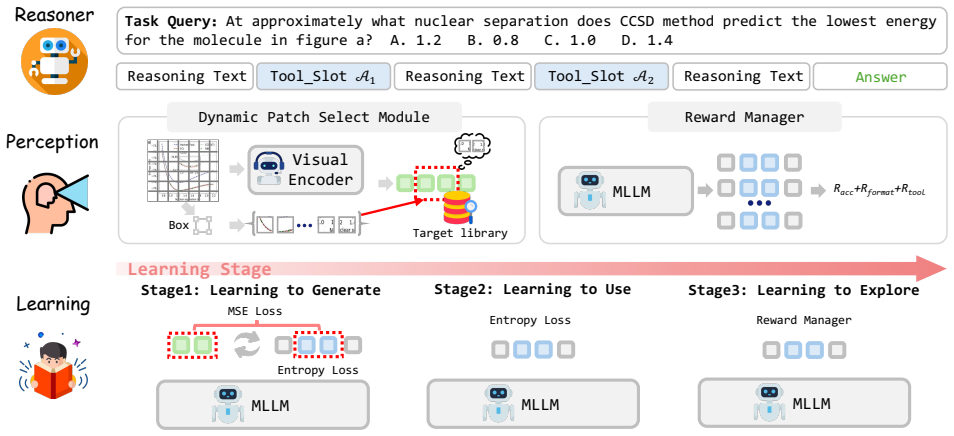
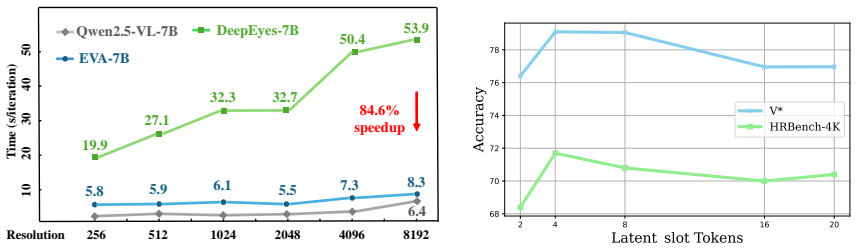
EVA natively generates continuous latent visual representations that appear as an adaptive sequence of Latent_slot tokens serving as intermediate visual thoughts. These tokens are trained end-to-end with discrete text tokens; the co-optimization produces extreme policy deviation in the transition window, which D-GSPO resolves by decoupling the latent and discrete components. The approach yields significant performance gains while enhancing inference efficiency across real-world scenes, documents, charts, and OCR tasks.
What carries the argument
Latent_slot tokens (adaptive sequences of continuous latent visual representations) together with D-GSPO (Decouple-GSPO), which decouples optimization of the latent visual and discrete text components to manage policy deviation during end-to-end training.
If this is right
- Multimodal reasoning can proceed with internal continuous visual states rather than external discrete tool calls.
- Inference latency decreases because the model avoids generating and executing separate tool invocations.
- End-to-end training remains feasible once the transition-window deviation is isolated by D-GSPO.
- Performance improves on interleaved visual-text tasks such as document understanding and chart reasoning.
Where Pith is reading between the lines
- The same latent-state mechanism could be tested on non-visual modalities to check whether continuous internal representations generalize beyond vision.
- Models using Latent_slot tokens might eventually reduce reliance on separate vision encoders by folding visual processing into the language-model token stream.
- Scaling experiments on larger base models would show whether the efficiency benefit persists when parameter count increases.
Load-bearing premise
Co-optimization of the latent visual tokens and discrete text tokens produces a policy deviation that D-GSPO can successfully decouple without losing the advantages of joint end-to-end training.
What would settle it
An ablation that trains the same architecture without D-GSPO and measures whether the reported accuracy gains and inference-time reductions disappear or training fails to converge.
Figures










read the original abstract
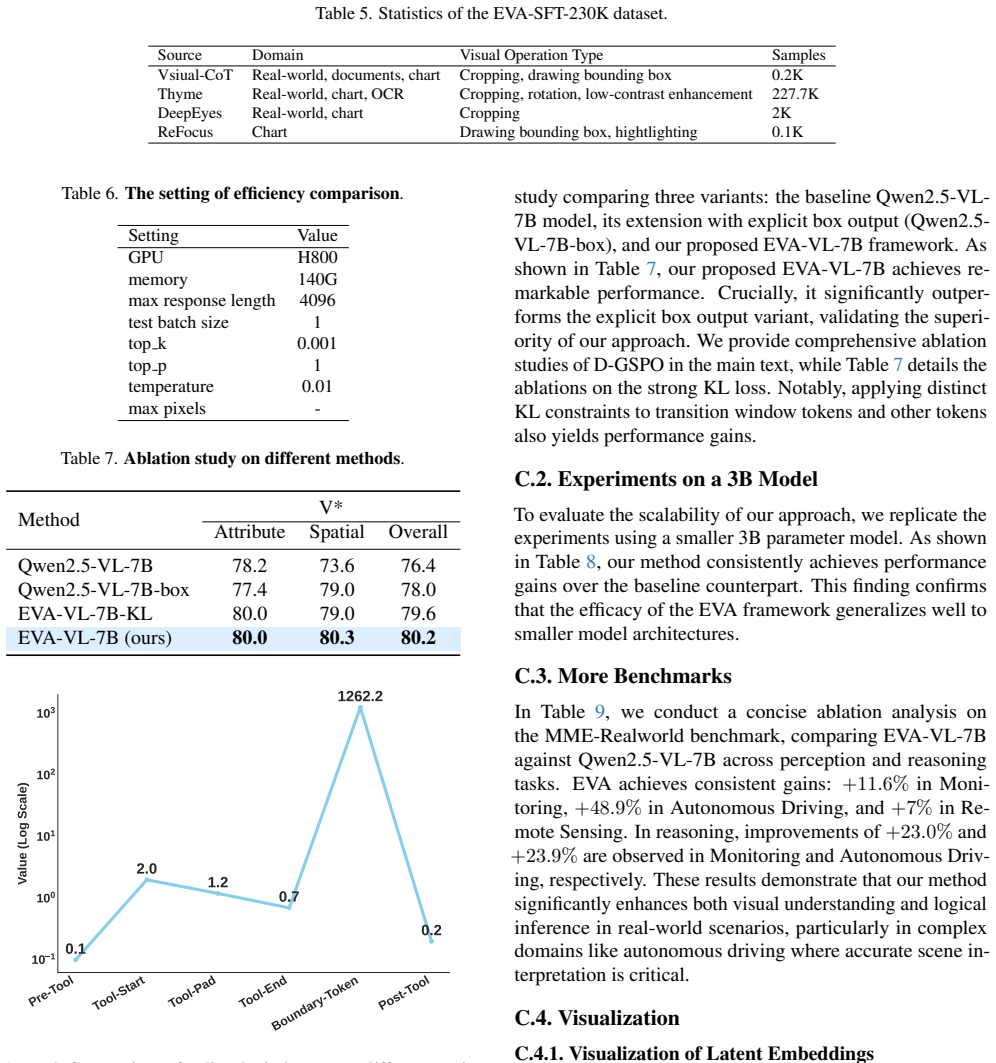
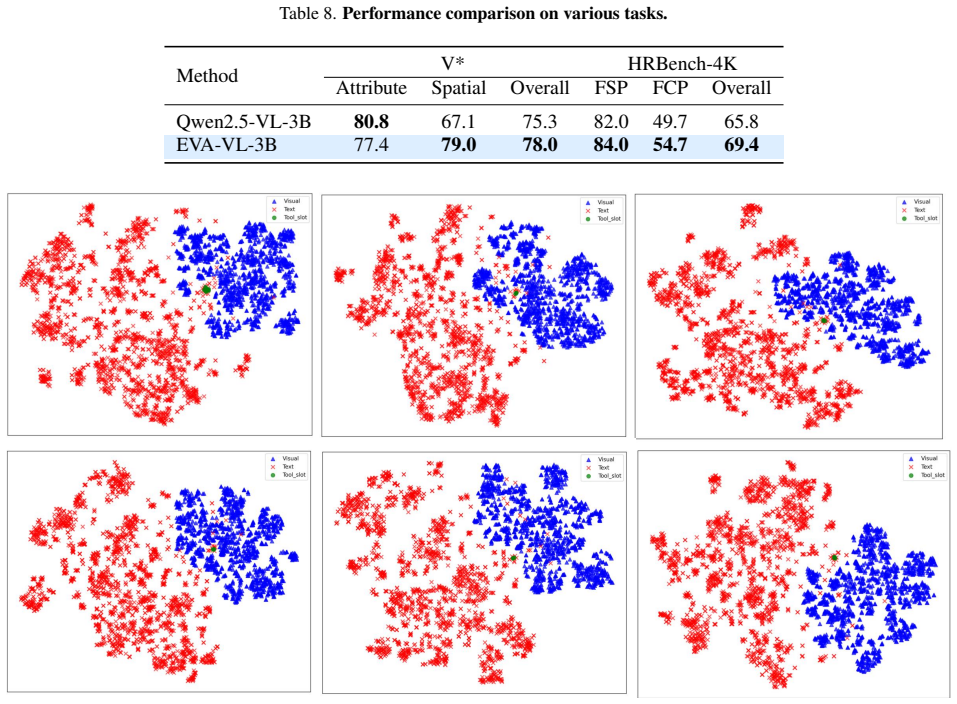
The integration of visual evidence has significantly enhanced the capabilities of large multimodal models. However, this integration predominantly relies on generating discrete outputs (etc., code or box coordinates) to invoke external tools, a process that introduces rigid dependencies and substantial latency. To overcome these limitations, we propose {EVA} (LatEnt Visual StAtes), a novel framework that natively generates continuous latent visual representations. These internal representations manifest as an adaptive sequence of Latent\_slot tokens, serving as intermediate visual thoughts during the reasoning process. These Latent\_slot tokens are then trained end-to-end with the discrete text tokens. This co-optimization, notably, causes extreme policy deviation in the 'transition window' following the Latent\_slot tokens. We develop D-GSPO (Decouple-GSPO) to target this root cause by decoupling the optimization of latent and discrete components. To support SFT, we construct EVA-230K, a high-quality text-image interleaved CoT dataset encompassing a diverse range of real-world scenes, documents, charts and OCR tasks. Extensive experiments across multiple benchmarks confirm that EVA achieves significant performance gains while enhancing inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EVA (LatEnt Visual StAtes), a framework for multimodal reasoning that natively generates continuous latent visual representations as an adaptive sequence of Latent_slot tokens. These tokens are trained end-to-end with discrete text tokens; the resulting co-optimization is said to produce extreme policy deviation in the transition window, which is addressed by D-GSPO (Decouple-GSPO) that decouples latent and discrete optimization. The authors introduce the EVA-230K text-image interleaved CoT dataset and claim that experiments across benchmarks demonstrate significant performance gains together with improved inference efficiency.
Significance. If the central claims were substantiated, the method could reduce latency in multimodal models by replacing discrete tool invocations with native continuous latent states. However, the manuscript supplies no quantitative results, benchmarks, ablation studies, or error analysis, so the claimed gains in performance and efficiency cannot be evaluated and the significance remains undetermined.
major comments (2)
- [Abstract] Abstract: the central claims of 'significant performance gains' and 'enhancing inference efficiency' are asserted without any supporting numbers, tables, baseline comparisons, or statistical analysis, rendering the primary empirical contribution unevaluable.
- [Abstract] Abstract: D-GSPO is described only at a high level as decoupling optimization to correct policy deviation in the transition window, with no formulation (modified loss, gradient routing, KL term, or objective) provided; this prevents verification that the method isolates the deviation without severing end-to-end gradient flow or reintroducing the rigid dependencies the framework claims to avoid.
minor comments (1)
- [Abstract] Abstract: the expansion 'LatEnt Visual StAtes' produces an awkward acronym; standard capitalization (e.g., EVA) should be clarified for consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our empirical results and methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'significant performance gains' and 'enhancing inference efficiency' are asserted without any supporting numbers, tables, baseline comparisons, or statistical analysis, rendering the primary empirical contribution unevaluable.
Authors: We agree that the abstract would benefit from concrete quantitative support. In the revised manuscript we will add specific performance metrics (e.g., accuracy gains on the evaluated benchmarks) and efficiency numbers (e.g., latency reduction relative to baselines) drawn from the experiments on EVA-230K and the reported benchmarks, together with pointers to the corresponding tables and figures. revision: yes
-
Referee: [Abstract] Abstract: D-GSPO is described only at a high level as decoupling optimization to correct policy deviation in the transition window, with no formulation (modified loss, gradient routing, KL term, or objective) provided; this prevents verification that the method isolates the deviation without severing end-to-end gradient flow or reintroducing the rigid dependencies the framework claims to avoid.
Authors: We acknowledge the abstract presents D-GSPO at a summary level. The methods section of the full manuscript contains the decoupling formulation; however, to improve accessibility we will expand the abstract with a concise statement of the modified objective and gradient routing strategy, ensuring it is clear that end-to-end differentiability is preserved. revision: yes
Circularity Check
No derivation chain or equations present; claims remain descriptive without self-referential reductions.
full rationale
The abstract and available text introduce EVA and D-GSPO at a conceptual level, stating that co-optimization of Latent_slot tokens with text tokens causes policy deviation addressed by decoupling, but provide no equations, objective functions, gradient formulations, or derivation steps. Without mathematical content, no self-definitional, fitted-input, or self-citation reductions can be exhibited. The framework is presented as an empirical proposal supported by a constructed dataset and benchmarks rather than a closed logical chain that reduces to its inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Latent_slot tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 6
Pith/arXiv arXiv 2025
-
[2]
Per- ception tokens enhance visual reasoning in multimodal lan- guage models
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G Shapiro, and Ranjay Krishna. Per- ception tokens enhance visual reasoning in multimodal lan- guage models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3836–3845, 2025. 3
2025
-
[3]
Xiuwei Chen, Wentao Hu, Xiao Dong, Sihao Lin, Zisheng Chen, Meng Cao, Yina Zhuang, Jianhua Han, Hang Xu, and Xiaodan Liang. Transmamba: Fast universal architec- ture adaption from transformers to mamba.arXiv preprint arXiv:2502.15130, 2025. 15
arXiv 2025
-
[4]
C2-evo: Co-evolving multimodal data and model for self-improving reasoning
Xiuwei Chen, Wentao Hu, Hanhui Li, Jun Zhou, Zisheng Chen, Meng Cao, Yihan Zeng, Kui Zhang, Yu-Jie Yuan, Jian- hua Han, Hang Xu, and Xiaodan Liang. C2-evo: Co-evolving multimodal data and model for self-improving reasoning. ArXiv, abs/2507.16518, 2025. 15
Pith/arXiv arXiv 2025
-
[5]
Xinyan Chen, Renrui Zhang, Dongzhi Jiang, Aojun Zhou, Shilin Yan, Weifeng Lin, and Hongsheng Li. Mint-cot: En- abling interleaved visual tokens in mathematical chain-of- thought reasoning.arXiv preprint arXiv:2506.05331, 2025. 1, 3
arXiv 2025
-
[7]
Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wan- jun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025. 1
Pith/arXiv arXiv 2025
-
[8]
Blink: Multimodal large language mod- els can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language mod- els can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024. 6
2024
-
[9]
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for struc- tured image understanding.arXiv preprint arXiv:2501.05452,
-
[10]
Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, and Lingpeng Kong. G-llava: Solving geomet- ric problem with multi-modal large language model.ArXiv, abs/2312.11370, 2023. 15
arXiv 2023
-
[11]
Xinyu Geng, Peng Xia, Zhen Zhang, Xinyu Wang, Qi- uchen Wang, Ruixue Ding, Chenxi Wang, Jialong Wu, Yida Zhao, Kuan Li, et al. Webwatcher: Breaking new fron- tier of vision-language deep research agent.arXiv preprint arXiv:2508.05748, 2025. 15
Pith/arXiv arXiv 2025
-
[12]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 15
Pith/arXiv arXiv 2025
-
[13]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large lan- guage models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024. 2
Pith/arXiv arXiv 2024
-
[14]
Visual sketchpad: Sketching as a visual chain of thought for mul- timodal language models.Advances in Neural Information Processing Systems, 37:139348–139379, 2024
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for mul- timodal language models.Advances in Neural Information Processing Systems, 37:139348–139379, 2024. 1
2024
-
[15]
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke S. Zettlemoyer, Noah A. Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.ArXiv, abs/2406.09403, 2024. 15
arXiv 2024
-
[17]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
-
[18]
Xinyu Huang, Yuhao Dong, Weiwei Tian, Bo Li, Rui Feng, and Ziwei Liu. High-resolution visual reasoning via multi- turn grounding-based reinforcement learning.arXiv preprint arXiv:2507.05920, 2025. 15
Pith/arXiv arXiv 2025
-
[19]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 1
Pith/arXiv arXiv 2024
-
[20]
Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 15
Pith/arXiv arXiv 2024
-
[21]
Xin Lai, Junyi Li, Wei Li, Tao Liu, Tianjian Li, and Heng- shuang Zhao. Mini-o3: Scaling up reasoning patterns and interaction turns for visual search.arXiv preprint arXiv:2509.07969, 2025. 1, 6, 15
Pith/arXiv arXiv 2025
-
[22]
Sicong Leng, Jing Wang, Jiaxi Li, Hao Zhang, Zhiqiang Hu, Boqiang Zhang, Yuming Jiang, Hang Zhang, Xin Li, Li Bing, Deli Zhao, Wei Lu, Yu Rong, Aixin Sun, and Shijian Lu. Mmr1: Enhancing multimodal reasoning with variance-aware sampling and open resources.ArXiv, abs/2509.21268, 2025. 15
arXiv 2025
-
[23]
Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025. 3, 6, 8
Pith/arXiv arXiv 2025
-
[24]
Hengli Li, Chenxi Li, Tong Wu, Xuekai Zhu, Yuxuan Wang, Zhaoxin Yu, Eric Hanchen Jiang, Song-Chun Zhu, Zixia Jia, Ying Nian Wu, et al. Seek in the dark: Reasoning via test-time instance-level policy gradient in latent space.arXiv preprint arXiv:2505.13308, 2025. 2
arXiv 2025
-
[25]
Implicit 9 reasoning in large language models: A comprehensive survey
Jindong Li, Yali Fu, Li Fan, Jiahong Liu, Yao Shu, Chengwei Qin, Menglin Yang, Irwin King, and Rex Ying. Implicit 9 reasoning in large language models: A comprehensive survey. arXiv preprint arXiv:2509.02350, 2025. 2
arXiv 2025
-
[26]
Xinji Mai, Haotian Xu, Zhong-Zhi Li, Weinong Wang, Jian Hu, Yingying Zhang, Wenqiang Zhang, et al. Agent rl scaling law: Agent rl with spontaneous code execution for mathemat- ical problem solving.arXiv preprint arXiv:2505.07773, 2025. 15
arXiv 2025
-
[27]
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforce- ment learning.arXiv preprint arXiv:2503.07365, 2025. 15
Pith/arXiv arXiv 2025
-
[28]
Introducing o3 and o4-mini, 2025
OpenAI. Introducing o3 and o4-mini, 2025. 1
2025
-
[29]
Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning. Advances in Neural Information Processing Systems, 37:8612– 8642, 2024. 5, 11
2024
-
[30]
Math-llava: Bootstrapping mathematical reasoning for multimodal large language models
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Li Bing, and Roy Ka wei Lee. Math-llava: Bootstrapping mathematical reasoning for multimodal large language models. InConference on Empirical Methods in Natural Language Processing, 2024. 15
2024
-
[31]
Alex Su, Haozhe Wang, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space rea- soning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025. 15
Pith/arXiv arXiv 2025
-
[32]
Zhengwei Tao, Jialong Wu, Wenbiao Yin, Junkai Zhang, Baix- uan Li, Haiyang Shen, Kuan Li, Liwen Zhang, Xinyu Wang, Yong Jiang, et al. Webshaper: Agentically data synthesiz- ing via information-seeking formalization.arXiv preprint arXiv:2507.15061, 2025. 15
arXiv 2025
-
[33]
Kimi k2: Open agentic intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534, 2025. 15
Pith/arXiv arXiv 2025
-
[34]
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 7907–7915, 2025. 6
2025
-
[35]
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Lin- jie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan Wang. Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement.arXiv preprint arXiv:2504.07934, 2025. 5, 11
arXiv 2025
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, F. Xia, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. ArXiv, abs/2201.11903, 2022. 15
Pith/arXiv arXiv 2022
-
[37]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024. 6
2024
-
[38]
Kun Xiang, Zhili Liu, Zihao Jiang, Yunshuang Nie, Runhu Huang, Haoxiang Fan, Hanhui Li, Weiran Huang, Yihan Zeng, Jianhua Han, Lanqing Hong, Hang Xu, and Xiaodan Liang. Atomthink: A slow thinking framework for multi- modal mathematical reasoning.ArXiv, abs/2411.11930, 2024. 15
arXiv 2024
-
[39]
Llava-cot: Let vision language models reason step-by-step.ArXiv, abs/2411.10440, 2024
Guowei Xu, Peng Jin, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step.ArXiv, abs/2411.10440, 2024. 1, 15
Pith/arXiv arXiv 2024
-
[40]
Simpletir: End-to-end rein- forcement learning for multi-turn tool-integrated reasoning
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun Ma, and Bo An. Simpletir: End-to-end rein- forcement learning for multi-turn tool-integrated reasoning. arXiv preprint arXiv:2509.02479, 2025. 15
arXiv 2025
-
[41]
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Min- feng Zhu, Bo Zhang, and Wei Chen. R1-onevision: Advanc- ing generalized multimodal reasoning through cross-modal formalization.ArXiv, abs/2503.10615, 2025. 1, 15
Pith/arXiv arXiv 2025
-
[42]
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine mental imagery: Empower multi- modal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025. 3
Pith/arXiv arXiv 2025
-
[43]
Mimo-vl technical report.ArXiv, abs/2506.03569,
Xiaomi LLM-Core Team Zihao Yue, Zhenrui Lin, Yi-Hao Song, Weikun Wang, Shu-Qin Ren, Shuhao Gu, Shicheng Li, Peidian Li, Liang Zhao, Lei Li, Kainan Bao, Hao Tian, Hailin Zhang, Gang Wang, Dawei Zhu, Cici, Chenhong He, Bowen Ye, Bowen Shen, Zihan Zhang, Zi-Ang Jiang, Zhixian Zheng, Zhichao Song, Zhen Luo, Yue Yu, Yudong Wang, Yu Tian, Yu Tu, Yihan Yan, Yi H...
-
[44]
Di Zhang, Jianbo Wu, Jingdi Lei, Tong Che, Jiatong Li, Tong Xie, Xiaoshui Huang, Shufei Zhang, Marco Pavone, Yuqiang Li, Wanli Ouyang, and Dongzhan Zhou. Llama-berry: Pair- wise optimization for o1-like olympiad-level mathematical reasoning.ArXiv, abs/2410.02884, 2024. 15
arXiv 2024
-
[45]
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learning to reason with multimodal large language mod- els via step-wise group relative policy optimization.ArXiv, abs/2503.12937, 2025. 1, 15
Pith/arXiv arXiv 2025
-
[46]
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xi- aowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv preprint arXiv:2505.15436, 2025. 1, 15
Pith/arXiv arXiv 2025
-
[47]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multi- modal llm challenge high-resolution real-world scenarios that 10 are difficult for humans?arXiv preprint arXiv:2408.13257,
-
[48]
Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025. 1, 5, 11, 15
Pith/arXiv arXiv 2025
-
[49]
Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 6
Pith/arXiv arXiv 2025
-
[50]
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing” thinking with images” via reinforcement learn- ing.arXiv preprint arXiv:2505.14362, 2025. 1, 5, 7, 11, 15
Pith/arXiv arXiv 2025
-
[51]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 1
Pith/arXiv arXiv 2023
-
[52]
Muzhi Zhu, Hao Zhong, Canyu Zhao, Zongze Du, Zheng Huang, Mingyu Liu, Hao Chen, Cheng Zou, Jingdong Chen, Ming Yang, et al. Active-o3: Empowering multimodal large language models with active perception via grpo.arXiv preprint arXiv:2505.21457, 2025. 15 A. Details A.1. Dataset Construction EV A training data consists of two parts.: EV A-SFT-230K and EV A-R...
Pith/arXiv arXiv 2025
-
[53]
To guarantee accurate alignment during the matching process with the ground truth, we use order constraints
We allocate a corresponding number of Latent slot placeholders based on the quantity of tool images present in each sample. To guarantee accurate alignment during the matching process with the ground truth, we use order constraints. Furthermore, in the Reinforcement Learning (RL) phase, we discard a small number of samples generated during the rollout pro...
-
[54]
Remove Python Code: Completely remove all <code>...</code> blocks and the Python code within them
-
[55]
Replace with Image Tag: In the exact place where the `<code>...</code>` block used to be, insert the following tag: `<output_image>`
-
[56]
I will crop the image to make a closer observation
Modify the Transition Sentence: Locate the sentence immediately preceding the newly inserted `<output_image>` tag. You must rewrite this sentence to explicitly state your intended action for closer observation. The action verb must match what the removed code was doing (e.g., crop, highlight, rotate). Example phrasing: "I will crop the image to make a clo...
-
[57]
original_image\
Preserve the Rest: Do not alter the logical flow, the `<sandbox_output><image></sandbox_output>` tags, or the final conclusion. Keep the `<answer>...</answer>` block exactly as it is in the original text. What does the graph indicate happens to the abundance of elements with a mass number around 195? A. It shows a significant increase in abundance. B. It ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.