UniTranslator: A Unified Multi-modal Framework for End-to-end In-Image Machine Translation
Pith reviewed 2026-06-26 00:48 UTC · model grok-4.3
The pith
UniTranslator adds alignment and spatial mask modules to a unified multimodal model to translate and render scene text without conflicts or misalignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
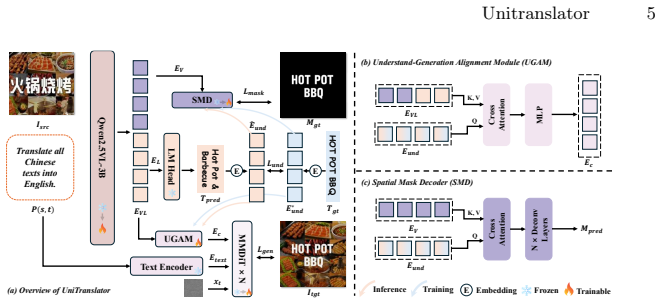
UniTranslator is a unified multimodal framework for end-to-end in-image machine translation that tightly couples translation understanding and text editing; an Understand-Generation Alignment Module bridges the representation gap to encourage semantic consistency between translated content prediction and text rendering, while a Spatial Mask Decoder supplies pixel-level supervision over text regions to improve spatial grounding, geometric alignment, and layout controllability, yielding state-of-the-art performance and a mutual reinforcement effect between understanding and generation.
What carries the argument
Understand-Generation Alignment Module (UGAM) that bridges representation gaps between understanding and generation, together with Spatial Mask Decoder (SMD) that supplies pixel-level supervision over text regions.
If this is right
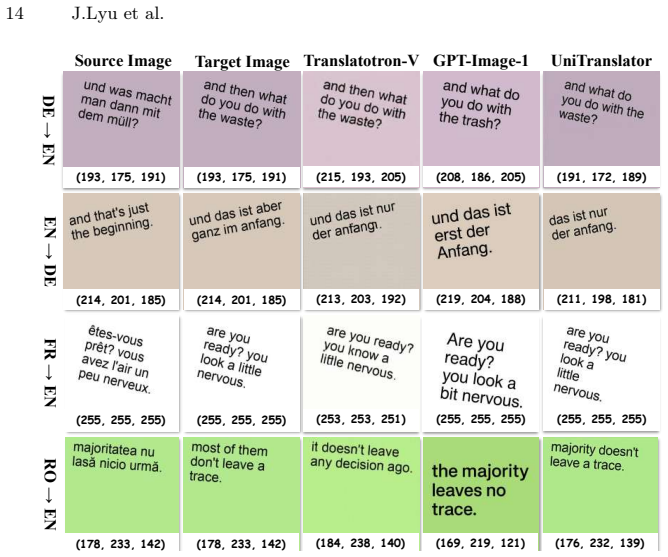
- State-of-the-art performance across diverse language directions and complex real-world layouts.
- Strong mutual reinforcement effect between translation understanding and image generation.
- Improved semantic consistency between translated content prediction and text rendering.
- Enhanced geometric alignment and layout controllability during generation.
Where Pith is reading between the lines
- Joint training of understanding and generation may transfer to other multimodal editing tasks that require both content prediction and visual output.
- The spatial supervision approach could be tested on video or live camera feeds where text must be translated and overlaid in real time.
- If the mutual reinforcement holds, similar unified backbones might benefit from adding alignment and mask-style supervision in non-text domains such as object editing.
Load-bearing premise
Adding the alignment module and spatial mask decoder to an existing unified multimodal backbone will resolve understanding-generation conflicts and spatial misalignment.
What would settle it
Ablation experiments on the benchmarks showing no gain in translation accuracy, consistency, or spatial alignment when the Understand-Generation Alignment Module or Spatial Mask Decoder is removed would falsify the necessity of these components.
Figures







read the original abstract
In-Image Machine Translation (IIMT) aims to translate scene text in an image and render the translated text back into the original regions while preserving the overall visual appearance. Recent unified multimodal models provide a promising solution by combining visual-text understanding and image generation within a single framework. However, directly adapting such models to IIMT remains challenging. In particular, they often suffer from understanding-generation conflicts, where the translation inferred during understanding is inconsistent with the text supervision used in generation, and spatial position misalignment, where the rendered text does not accurately match the target text regions. To address these issues, we present UniTranslator, a unified multimodal framework for IIMT that tightly couples translation understanding and text editing. Specifically, we introduce an Understand-Generation Alignment Module (UGAM) to bridge the representation gap between understanding and generation, encouraging semantic consistency between translated content prediction and text rendering. We further propose a Spatial Mask Decoder (SMD) with pixel-level supervision over text regions to improve spatial grounding, geometric alignment, and layout controllability during generation. Extensive experiments on multiple benchmarks demonstrate that UniTranslator achieves state-of-the-art performance across diverse language directions and complex real-world layouts. Moreover, our results reveal a strong mutual reinforcement effect between translation understanding and image generation, highlighting the advantage of unified translation multimodal learning. Code is available at https://github.com/SeerRay-Lab/Unitranslator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniTranslator, a unified multimodal framework for end-to-end In-Image Machine Translation (IIMT). It identifies two challenges when adapting unified multimodal models—understanding-generation conflicts and spatial position misalignment—and introduces an Understand-Generation Alignment Module (UGAM) to enforce semantic consistency between translated content prediction and text rendering, plus a Spatial Mask Decoder (SMD) with pixel-level supervision to improve spatial grounding and layout controllability. The manuscript claims that these additions yield state-of-the-art results across diverse language directions and complex real-world layouts on multiple benchmarks, while also demonstrating a mutual reinforcement effect between translation understanding and image generation.
Significance. If the experimental results hold, the work would be significant for multimodal machine translation and scene-text editing. It provides a concrete architectural approach to coupling understanding and generation in a single backbone, with modules that directly target identified failure modes. The reported mutual reinforcement between the two tasks is a potentially useful empirical observation that could inform future unified multimodal designs.
major comments (1)
- [Abstract] Abstract: the central claim of state-of-the-art performance is stated without any accompanying metrics, baselines, ablation results, or dataset details. This absence prevents verification that UGAM and SMD are responsible for the reported gains and that the mutual-reinforcement effect is robust.
minor comments (1)
- The GitHub link for code release is provided; confirming that the repository contains the full training and evaluation pipelines would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the feedback. The sole major comment concerns the abstract's lack of quantitative details supporting the SOTA claim. We agree this is a valid observation and will revise the abstract to include key metrics, baselines, and dataset references while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of state-of-the-art performance is stated without any accompanying metrics, baselines, ablation results, or dataset details. This absence prevents verification that UGAM and SMD are responsible for the reported gains and that the mutual-reinforcement effect is robust.
Authors: We agree the abstract would benefit from added specificity. In the revision we will incorporate concise quantitative results (e.g., BLEU improvements over prior SOTA on the primary benchmarks), name the main datasets and baselines, and briefly note that ablations isolating UGAM and SMD appear in Section 4. The mutual-reinforcement analysis remains in the experiments; the abstract will reference it without expanding into full details. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces architectural modules (UGAM and SMD) to a multimodal backbone and supports its SOTA and mutual-reinforcement claims solely through benchmark experiments. No equations, derivations, or predictions appear that reduce by construction to fitted inputs, self-citations, or renamed ansatzes. The argument is empirical and externally falsifiable on public datasets, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
com/index/image-generation-api/(2025), accessed: 2025-04-23 2, 8, 9
AI,Z.:IntroducingourlatestimagegenerationmodelintheAPI.https://openai. com/index/image-generation-api/(2025), accessed: 2025-04-23 2, 8, 9
2025
-
[2]
In: European conference on computer vision
Bautista, D., Atienza, R.: Scene text recognition with permuted autoregressive se- quence models. In: European conference on computer vision. pp. 178–196. Springer (2022) 11, 22
2022
-
[3]
In: Proceedings of the 14th International Conference on Spoken Language Translation
Cettolo, M., Federico, M., Bentivogli, L., Niehues, J., Stüker, S., Sudoh, K., Yoshino, K., Federmann, C.: Overview of the iwslt 2017 evaluation campaign. In: Proceedings of the 14th International Conference on Spoken Language Translation. pp. 2–14 (2017) 9
2017
-
[4]
In: Proceedings of the 11th International Workshop on Spoken Language Translation: Evaluation Campaign
Cettolo, M., Niehues, J., Stüker, S., Bentivogli, L., Federico, M.: Report on the 11th iwslt evaluation campaign. In: Proceedings of the 11th International Workshop on Spoken Language Translation: Evaluation Campaign. pp. 2–17 (2014) 9
2014
-
[5]
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked gener- ative image transformer (2022) 10, 21
2022
-
[6]
arXiv preprint arXiv:2501.17811 (2025) 8, 9
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025) 8, 9
Pith/arXiv arXiv 2025
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Zhao, F., Shu, Y., Liu, Y., Yu, L., Zhou, Y.: Styletextgen: Style- conditioned multilingual scene text generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7643–7653 (2026) 2
2026
-
[8]
In: 2020 25th Interna- tional Conference on Pattern Recognition (ICPR)
Chen, Z., Yin, F., Zhang, X.Y., Yang, Q., Liu, C.L.: Cross-lingual text image recognition via multi-task sequence to sequence learning. In: 2020 25th Interna- tional Conference on Pattern Recognition (ICPR). pp. 3122–3129. IEEE (2021) 4
2020
-
[9]
arXiv preprint arXiv:2507.06261 (2025) 2, 8, 9
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025) 2, 8, 9
Pith/arXiv arXiv 2025
-
[10]
arXiv preprint arXiv:2505.14683 (2025) 4, 8, 9
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025) 4, 8, 9
Pith/arXiv arXiv 2025
-
[11]
In: ACL (2016) 10
Elliott, D., Frank, S., Sima’an, K., Specia, L.: Multi30k: Multilingual english- german image descriptions. In: ACL (2016) 10
2016
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12873–12883 (June 2021) 10
2021
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021) 21
2021
-
[14]
arXiv preprint arXiv:2504.01934 (2025) 4
Huang, R., Wang, C., Yang, J., Lu, G., Yuan, Y., Han, J., Hou, L., Zhang, W., Hong, L., Zhao, H., et al.: Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement. arXiv preprint arXiv:2504.01934 (2025) 4
arXiv 2025
-
[15]
Visual Intelligence 3(1), 27 (2025) 4
Jin, Y., Li, J., Gu, T., Liu, Y., Zhao, B., Lai, J., Gan, Z., Wang, Y., Wang, C., Tan, X., et al.: Efficient multimodal large language models: A survey. Visual Intelligence 3(1), 27 (2025) 4
2025
-
[16]
In: Findings of the Association for Computational Linguistics ACL 2024
Lan, Z., Niu, L., Meng, F., Zhou, J., Zhang, M., Su, J.: Translatotron-v (ison): An end-to-end model for in-image machine translation. In: Findings of the Association for Computational Linguistics ACL 2024. pp. 5472–5485 (2024) 4, 8, 9, 10, 11, 21, 23 16 J.Lyu et al
2024
-
[17]
Lan, Z., Niu, L., Meng, F., Zhou, J., Zhang, M., Su, J.: Translatotron-v(ison): An end-to-end model for in-image machine translation (2024),https://arxiv.org/ abs/2407.0289421
arXiv 2024
-
[18]
arXiv preprint arXiv:2305.17415 (2023) 4, 10, 22
Lan, Z., Yu, J., Li, X., Zhang, W., Luan, J., Wang, B., Huang, D., Su, J.: Ex- ploring better text image translation with multimodal codebook. arXiv preprint arXiv:2305.17415 (2023) 4, 10, 22
arXiv 2023
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, G., Zhang, C., Liang, Y., Shen, H., Zhang, Y., Lyu, P., Wang, W., Wan, X., Zeng, G., Hu, H., et al.: Mmtit-bench: A multilingual and multi-scenario bench- mark with cognition-perception-reasoning guided text-image machine translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16593–16602 (2026) 4
2026
-
[20]
arXiv preprint arXiv:2410.10168 (2024) 2
Li, Z., Shu, Y., Zeng, W., Yang, D., Zhou, Y.: First creating backgrounds then rendering texts: A new paradigm for visual text blending. arXiv preprint arXiv:2410.10168 (2024) 2
arXiv 2024
-
[21]
In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Liang, Y., Zhang, Y., Ma, C., Zhang, Z., Zhao, Y., Xiang, L., Zong, C., Zhou, Y.: Document image machine translation with dynamic multi-pre-trained models assembling. In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 7084–7095 (2024) 4
2024
-
[22]
arXiv preprint arXiv:2506.03147 (2025) 4, 8, 9
Lin, B., Li, Z., Cheng, X., Niu, Y., Ye, Y., He, X., Yuan, S., Yu, W., Wang, S., Ge, Y., et al.: Uniworld: High-resolution semantic encoders for unified visual understanding and generation. arXiv preprint arXiv:2506.03147 (2025) 4, 8, 9
Pith/arXiv arXiv 2025
-
[23]
arXiv preprint arXiv:2505.05422 (2025) 4
Lin, H., Wang, T., Ge, Y., Ge, Y., Lu, Z., Wei, Y., Zhang, Q., Sun, Z., Shan, Y.: Toklip: Marry visual tokens to clip for multimodal comprehension and generation. arXiv preprint arXiv:2505.05422 (2025) 4
arXiv 2025
-
[24]
arXiv preprint arXiv:2603.10495 (2026) 4
Lyu, J., Fu, P., Li, Z., Zeng, W., Zhang, S., Yang, J., Ma, C., Zhou, Y., Luo, Z., Luan, J.: Imtbench: A multi-scenario cross-modal collaborative evaluation bench- mark for in-image machine translation. arXiv preprint arXiv:2603.10495 (2026) 4
arXiv 2026
-
[25]
OpenAI: GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Im- age Generation.https://z.ai/blog/glm-image/(2026), accessed: 2026-01-04 8, 9
2026
-
[26]
In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002) 9
2002
-
[27]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Qian, Z., Zhang, P., Yang, B., Fan, K., Ma, Y., Wong, D., Sun, X., Ji, R.: Any- trans: Translate anytext in the image with large scale models. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 2432–2444 (2024) 4, 13, 23
2024
-
[28]
In: Webber, B., Cohn, T., He, Y., Liu, Y
Rei,R.,Stewart,C.,Farinha,A.C.,Lavie,A.:COMET:AneuralframeworkforMT evaluation. In: Webber, B., Cohn, T., He, Y., Liu, Y. (eds.) Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 2685–2702. Association for Computational Linguistics, Online (Nov 2020).https: //doi.org/10.18653/v1/2020.emnlp- main.213,https:...
-
[29]
Salesky,E., Koehn,P.,Post, M.:Benchmarkingvisually-situated translationoftext innaturalimages.In:ProceedingsoftheNinthConferenceonMachineTranslation. pp. 1167–1182 (2024) 4
2024
-
[30]
arXiv preprint arXiv:2505.23606 (2025) 4 Unitranslator 17
Shi, Q., Bai, J., Zhao, Z., Chai, W., Yu, K., Wu, J., Song, S., Tong, Y., Li, X., Li, X., et al.: Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model. arXiv preprint arXiv:2505.23606 (2025) 4 Unitranslator 17
Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2504.21682 (2025) 2
Shu, Y., Zeng, W., Zhao, F., Chen, Z., Li, Z., Yang, X., Zhou, Y., Rota, P., Bai, X., Jin, L., et al.: Visual text processing: A comprehensive review and unified evaluation. arXiv preprint arXiv:2504.21682 (2025) 2
arXiv 2025
-
[32]
In: International Conference on Document Analysis and Recognition
Su, T., Liu, S., Zhou, S.: Rtnet: An end-to-end method for handwritten text image translation. In: International Conference on Document Analysis and Recognition. pp. 99–113. Springer (2021) 4
2021
-
[33]
arXiv preprint arXiv:2503.20853 (2025) 4
Swerdlow, A., Prabhudesai, M., Gandhi, S., Pathak, D., Fragkiadaki, K.: Unified multimodal discrete diffusion. arXiv preprint arXiv:2503.20853 (2025) 4
arXiv 2025
-
[34]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024) 4
Pith/arXiv arXiv 2024
-
[35]
Team, M.L., Ma, H., Tan, H., Huang, J., Wu, J., He, J.Y., Gao, L., Xiao, S., Wei, X., Ma, X., Cai, X., Guan, Y., Hu, J.: Longcat-image technical report (2025), https://arxiv.org/abs/2512.075848, 9
Pith/arXiv arXiv 2025
-
[36]
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalable image generation via next-scale prediction (2024) 10, 21
2024
-
[37]
In: Findings of the Association for Computational Linguistics: EMNLP 2023
Tian, Y., Li, X., Liu, Z., Guo, Y., Wang, B.: In-image neural machine translation with segmented pixel sequence-to-sequence model. In: Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 15046–15057 (2023) 4
2023
-
[38]
arXiv preprint arXiv:2509.05146 (2025) 4, 10, 11, 22, 25
Tian, Y., Liu, Z., Liu, Z., Feng, C., Li, X., Huang, H., Guo, Y.: Prim: Towards prac- tical in-image multilingual machine translation. arXiv preprint arXiv:2509.05146 (2025) 4, 10, 11, 22, 25
arXiv 2025
-
[39]
arXiv preprint arXiv:2505.15282 (2025) 4, 10, 22, 24
Tian, Y., Liu, Z., Liu, Z., Guo, Y.: Exploring in-image machine translation with real-world background. arXiv preprint arXiv:2505.15282 (2025) 4, 10, 22, 24
arXiv 2025
-
[40]
In: International Conference on Pattern Recognition
Vaidya, S., Sharma, A.K., Gatti, P., Mishra, A.: Show me the world in my lan- guage: Establishing the first baseline for scene-text to scene-text translation. In: International Conference on Pattern Recognition. pp. 312–328. Springer (2024) 4
2024
-
[41]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need (2023) 10
2023
-
[42]
arXiv preprint arXiv:2505.20147 (2025) 4
Wang, J., Lai, Y., Li, A., Zhang, S., Sun, J., Kang, N., Wu, C., Li, Z., Luo, P.: Fudoki: Discrete flow-based unified understanding and generation via kinetic- optimal velocities. arXiv preprint arXiv:2505.20147 (2025) 4
arXiv 2025
-
[43]
arXiv preprint arXiv:2409.18869 (2024) 4
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024) 4
Pith/arXiv arXiv 2024
-
[44]
arXiv preprint arXiv:2506.11820 (2025) 4
Wang, X., Pan, J., Liu, Y., Zhao, X., Lyu, C., Wu, M., Biemann, C., Wang, L., Xu, L., Luo, W., et al.: Rethinking multilingual vision-language translation: Dataset, evaluation, and adaptation. arXiv preprint arXiv:2506.11820 (2025) 4
arXiv 2025
-
[45]
IEEE transactions on image processing 13(4), 600–612 (2004) 9
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004) 9
2004
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang,Z.,Guan,T.,Fu,P.,Duan,C.,Jiang,Q.,Guo,Z.,Guo,S.,Luo,J.,Shen,W., Yang, X.: Marten: Visual question answering with mask generation for multi-modal document understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14460–14471 (2025) 9
2025
-
[47]
arXiv preprint arXiv:2508.02324 (2025) 2, 8, 9
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 2, 8, 9
Pith/arXiv arXiv 2025
-
[48]
arXiv preprint arXiv:2503.21979 (2025) 4 18 J.Lyu et al
Wu, S., Zhang, W., Xu, L., Jin, S., Wu, Z., Tao, Q., Liu, W., Li, W., Loy, C.C.: Harmonizing visual representations for unified multimodal understanding and gen- eration. arXiv preprint arXiv:2503.21979 (2025) 4 18 J.Lyu et al
arXiv 2025
-
[49]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiao, S., Wang, Y., Zhou, J., Yuan, H., Xing, X., Yan, R., Li, C., Wang, S., Huang, T., Liu, Z.: Omnigen: Unified image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13294–13304 (2025) 4
2025
-
[50]
arXiv preprint arXiv:2408.12528 (2024) 4
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. arXiv preprint arXiv:2408.12528 (2024) 4
Pith/arXiv arXiv 2024
-
[51]
arXiv preprint arXiv:2505.15809 (2025) 4
Yang, L., Tian, Y., Li, B., Zhang, X., Shen, K., Tong, Y., Wang, M.: Mmada: Mul- timodal large diffusion language models. arXiv preprint arXiv:2505.15809 (2025) 4
Pith/arXiv arXiv 2025
-
[52]
Advances in Neural Information Processing Systems37, 138569–138594 (2024) 2
Zeng, W., Shu, Y., Li, Z., Yang, D., Zhou, Y.: Textctrl: Diffusion-based scene text editing with prior guidance control. Advances in Neural Information Processing Systems37, 138569–138594 (2024) 2
2024
-
[53]
arXiv preprint arXiv:2505.02567 (2025) 4
Zhang, X., Guo, J., Zhao, S., Fu, M., Duan, L., Hu, J., Chng, Y.X., Wang, G.H., Chen, Q.G., Xu, Z., Luo, W., Zhang, K.: Unified multimodal understanding and generation models: Advances, challenges, and opportunities. arXiv preprint arXiv:2505.02567 (2025) 4
arXiv 2025
-
[54]
IEEE Transactions on Audio, Speech and Language Processing (2025) 4
Zhang, Z., Zhang, Y., Liang, Y., Ma, C., Xiang, L., Zhao, Y., Zhou, Y., Zong, C.: Reading when translating: Multi-modal document image machine translation with reading flow prediction. IEEE Transactions on Audio, Speech and Language Processing (2025) 4
2025
-
[55]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 4
Zhang, Z., Zhang, Y., Liang, Y., Ma, C., Xiang, L., Zhao, Y., Zhou, Y., Zong, C.: Understand layout and translate text: Unified feature-conductive end-to-end document image translation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 4
2025
-
[56]
In: Proceedings of the 61st Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers)
Zhu, S., Li, S., Lei, Y., Xiong, D.: Peit: bridging the modality gap with pre-trained models for end-to-end image translation. In: Proceedings of the 61st Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13433–13447 (2023) 4, 8, 9, 10, 11, 21, 22 Unitranslator 19 The appendix includes the following aspects: –A...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.