BiJuTy: An Interactive HPC-Aware Big Data Cluster Lifecycle Manager and Performance Assessment Utility for JupyterHub
Pith reviewed 2026-06-25 23:00 UTC · model grok-4.3
The pith
BiJuTy provides an interactive interface for managing big data cluster lifecycles and assessing performance on HPC systems from within Jupyter notebooks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BiJuTy is an interactive interface within Jupyter Notebook that guides users through setting up cluster configurations, managing the cluster lifecycle, and carrying out performance assessments. It enables seamless management of multiple clusters directly in the notebook, eliminating the need to switch environments, and collects performance metrics from various sources to simplify optimization, as illustrated by optimizing a big data application iteratively.
What carries the argument
BiJuTy, the interactive utility that embeds HPC big data cluster lifecycle management and performance assessment inside the JupyterHub interface.
If this is right
- Users can configure and assess clusters without switching tools.
- Multiple clusters are managed seamlessly within one notebook session.
- Performance data from multiple sources supports easier optimization workflows.
- Big data applications can be set up, run, and tuned interactively in few steps.
Where Pith is reading between the lines
- This approach may lower the barrier for data scientists to use HPC resources regularly.
- It could inspire similar embedded management tools for other scientific computing environments.
- Wider adoption might lead to more user feedback on HPC usability that influences system designs.
Load-bearing premise
That providing the management functions inside the Jupyter interface will remove the need for users to switch outside the environment and enable effective cluster management for those without HPC experience.
What would settle it
Observing whether novice users can successfully set up and optimize a big data cluster using only BiJuTy in Jupyter compared to traditional methods, measuring completion rates and time taken.
Figures

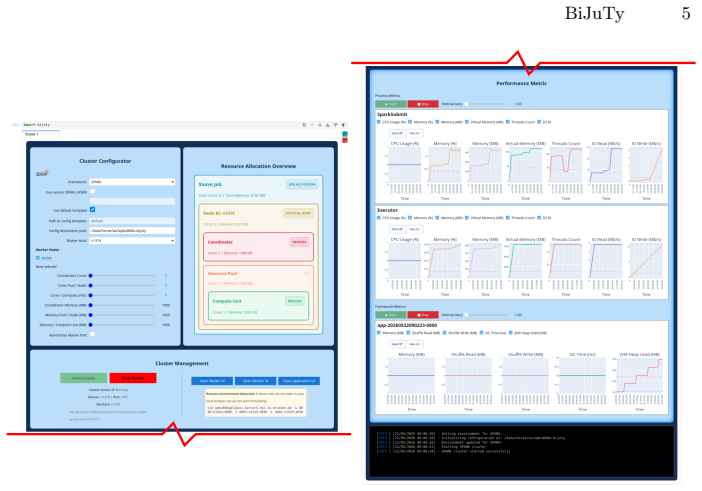
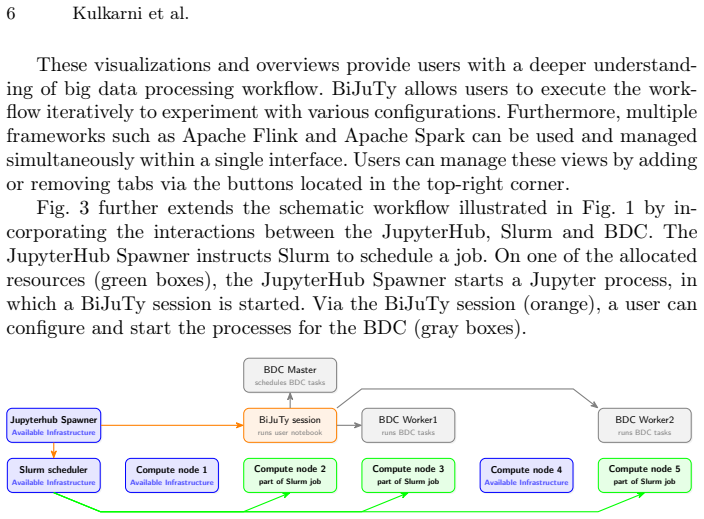
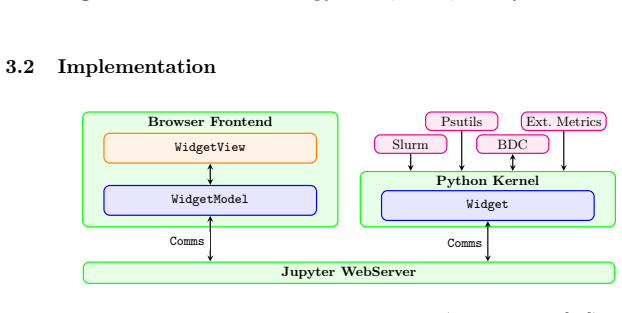


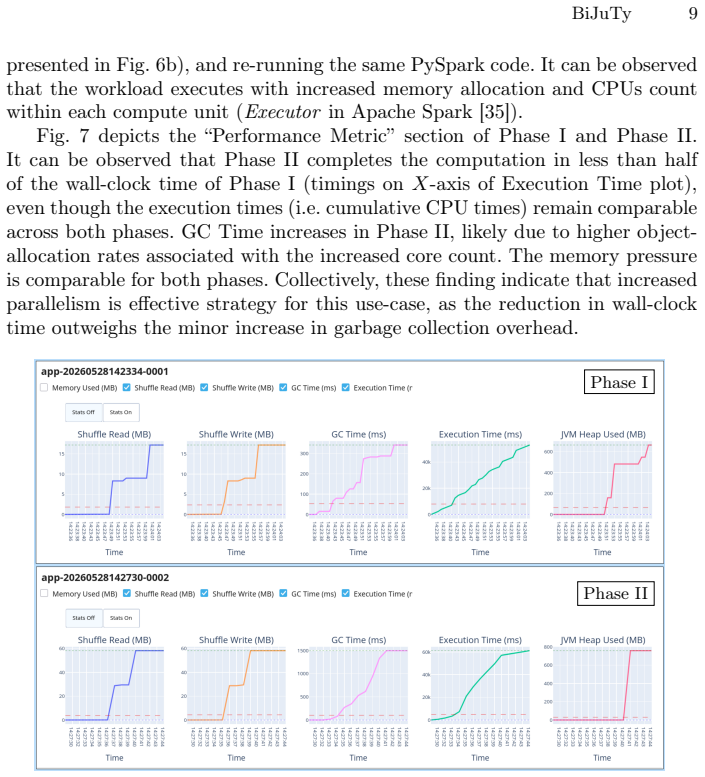
read the original abstract
The increasing demand for data processing has created a pressing need for access to high-performance computing (HPC) systems. Nevertheless, leveraging these systems to execute complex big data processing workflows remains a significant challenge, especially for beginners. This work presents BiJuTy, a solution designed to bridge the accessibility gap for big data workflows on HPC systems within the Jupyter ecosystem. By providing an interactive and user-friendly interface, BiJuTy simplifies cluster lifecycle management and performance assessment, making it more accessible on HPC systems to beginners and experienced users alike. The solution is presented as an interactive interface that guides the user through the entire process, from setting up the cluster configuration to carrying out initial performance assessments. Additionally, the framework enables seamless management of multiple clusters directly within the Jupyter Notebook interface, eliminating the need to switch outside of working environment. The collection of performance metrics from various sources further simplifies the optimization workflow. Furthermore, an illustrative example is provided to demonstrate how BiJuTy can be deployed to optimize the performance of a big data processing application. This example showcases how the entire big data processing lifecycle can be iteratively executed and optimized in just a few clicks, helping to reach the goal of optimization easily and interactively. By facilitating such workflows, this work contributes in bringing the field of big data computing and high-performance computing one step closer to the goal of seamless interaction and usability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BiJuTy, a tool for interactive HPC-aware big data cluster lifecycle management and performance assessment integrated with JupyterHub. It describes an interface that handles cluster configuration, multi-cluster management within notebooks, metric collection from various sources, and performance optimization, illustrated by a single example claiming the full lifecycle can be executed and optimized in a few clicks.
Significance. If the described interface functions as outlined, BiJuTy offers a practical contribution by embedding cluster management directly in the Jupyter environment, which could reduce context-switching for big data workflows on HPC systems. The provision of a design description together with an illustrative example is a strength for a tool-description paper in distributed computing.
major comments (1)
- [Abstract] Abstract: The central claim that BiJuTy 'simplifies cluster lifecycle management and performance assessment' and enables optimization 'in just a few clicks' is not supported by any quantitative performance metrics, error bars, user studies, or validation results; the manuscript supplies only a design description and one illustrative example.
Simulated Author's Rebuttal
We thank the referee for the constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that BiJuTy 'simplifies cluster lifecycle management and performance assessment' and enables optimization 'in just a few clicks' is not supported by any quantitative performance metrics, error bars, user studies, or validation results; the manuscript supplies only a design description and one illustrative example.
Authors: We agree that the abstract's phrasing regarding simplification and optimization 'in just a few clicks' is not supported by quantitative metrics, error bars, or user studies. The manuscript is a tool-description paper whose contribution lies in the interface design, multi-cluster management within Jupyter notebooks, and metric collection; the single illustrative example is intended only to show the workflow qualitatively. We will revise the abstract (and the corresponding sentence in the introduction) to remove unsubstantiated performance claims and to state explicitly that the example demonstrates the lifecycle in a qualitative manner. revision: yes
Circularity Check
No derivations, equations, or fitted predictions; tool-description paper is self-contained
full rationale
The manuscript is a software-tool description whose claims rest on interface design and one illustrative example. No equations, parameters, predictions, or derivation chains appear anywhere in the text. No self-citations are invoked as load-bearing premises, and none of the six enumerated circularity patterns are present. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems
Agrawal, N., Binns, R., Van Kleek, M., Laine, K., Shadbolt, N.: Exploring design and governance challenges in the development of privacy-preserving computation. In: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. CHI ’21, Association for Computing Machinery, New York, NY, USA (2021).https://doi.org/10.1145/3411764.3445677
-
[2]
openpbs.org/, accessed: 2026-05-23
Altair Engineering, Inc.: OpenPBS: Open PBS Professional,https://www. openpbs.org/, accessed: 2026-05-23
2026
-
[3]
Andrew Flowers, Reuben Fischer-Baum, D.M.: Uber TLC FOIL Response,https: //github.com/fivethirtyeight/uber-tlc-foil-response, accessed: 2026-05-28
2026
-
[4]
Apache Software Foundation: Flink Operations Playground - Flink WebUI, https://nightlies.apache.org/flink/flink-docs-stable/docs/try-flink/ flink-operations-playground/#flink-webui, accessed: 2026-03-15 BiJuTy 11
2026
-
[5]
Apache Software Foundation: Web UI - Spark 4.0.0 Documentation,https:// spark.apache.org/docs/latest/web-ui.html, accessed: 2026-03-15
2026
-
[6]
Azure CycleCloud Team: cyclecloud-open-ondemand,https://github.com/ Azure/cyclecloud-open-ondemand, accessed: 2026-03-15
2026
-
[7]
Baer, T., Peltz, P., Yin, J., Begoli, E.: Integrating apache spark into pbs-based hpc environments. In: Proceedings of the 2015 XSEDE Conference: Scientific Ad- vancements Enabled by Enhanced Cyberinfrastructure. XSEDE ’15, Association for Computing Machinery, New York, NY, USA (2015).https://doi.org/10. 1145/2792745.2792779
arXiv 2015
-
[8]
Chalker, A., Franz, E., Rodgers, M., Dockendorf, T., Johnson, D., Sajdak, D., White, J.P., Plessinger, B.D., Zia, M., Gallo, S.M., Settlage, R.E., Hudak, D.E.: Open ondemand: State of the platform, project, and the future. Concurrency and Computation: Practice and Experience33(19), e6114 (2021).https://doi.org/ 10.1002/cpe.6114
-
[9]
In: 2020 IEEE International Conference on Cluster Comput- ing (CLUSTER)
Dietrich, R., Winkler, F., Knüpfer, A., Nagel, W.: Pika: Center-wide and job-aware cluster monitoring. In: 2020 IEEE International Conference on Cluster Comput- ing (CLUSTER). pp. 424–432 (2020).https://doi.org/10.1109/CLUSTER49012. 2020.00061
-
[10]
DrudgeCAS: spark-in-slurm,https://github.com/DrudgeCAS/spark-in-slurm, accessed: 2026-03-15
2026
-
[11]
Future Generation Computer Sys- tems87, 420–437 (2018).https://doi.org/10.1016/j.future.2017.12.068
Enes, J., Expósito, R.R., Touriño, J.: Bdwatchdog: Real-time monitoring and pro- filing of big data applications and frameworks. Future Generation Computer Sys- tems87, 420–437 (2018).https://doi.org/10.1016/j.future.2017.12.068
-
[12]
giampaolo: psutil: Cross-platform lib for process and system monitoring in Python, https://github.com/giampaolo/psutil, accessed: 2026-05-18
2026
-
[13]
glennklockwood:myhadoop,https://github.com/glennklockwood/myhadoop,ac- cessed: 2026-03-15
2026
-
[14]
HPC UGent: hanythingondemand,https://github.com/hpcugent/ hanythingondemand, accessed: 2026-03-15
2026
-
[15]
Modules.https://hpc-wiki.info/hpc/Modules, accessed: 2026-05-18
2026
-
[16]
tu-chemnitz.de/scads.ai/bigdataframeworkconfigure, accessed: 2026-05-22
Jan Frenzel, A.D.K.: Bigdataframeworkconfigure (2025),https://gitlab.hrz. tu-chemnitz.de/scads.ai/bigdataframeworkconfigure, accessed: 2026-05-22
2025
-
[17]
Kołakowski, G.: streaming-jupyter-integrations: Jupyterlab extensions for streaming data processing (flink sql),https://github.com/getindata/ streaming-jupyter-integrations, accessed: 2026-03-15
2026
-
[18]
Krishnan, R., SWAN Team at CERN: Sparkmonitor,https://github.com/ swan-cern/sparkmonitor, accessed: 2026-03-15
2026
-
[19]
Lawrence Livermore National Laboratory: Magpie.https://github.com/LLNL/ magpie(2026), accessed: 2026-03-15
2026
-
[20]
BMC Bioinformatics26(2025).https://doi.org/10.1186/ s12859-025-06121-4
Liberati, F., Marino, T.M.P., Bottoni, P., Canestrelli, D., Castrignanò, T.: Hpc-t-assembly: a pipeline for de novo transcriptome assembly of large multi- specie datasets. BMC Bioinformatics26(2025).https://doi.org/10.1186/ s12859-025-06121-4
2025
-
[21]
Microsoft: Manage resources for Apache Spark cluster on Azure HDIn- sight,https://learn.microsoft.com/en-us/azure/hdinsight/spark/ apache-spark-resource-manager, accessed: 2026-05-23
2026
-
[22]
NIH-HPC: spark-slurm,https://github.com/NIH-HPC/spark-slurm, accessed: 2026-03-15
2026
-
[23]
(2025),https://www.puppet.com/, accessed: 2026-05-23 12 Kulkarni et al
PerforceSoftware,Inc.:Puppet-infrastructureautomationandconfigurationman- agement. (2025),https://www.puppet.com/, accessed: 2026-05-23 12 Kulkarni et al
2025
-
[24]
Pramanik, M.I., Lau, R.Y.K., Hossain, M.S., Rahoman, M.M., Debnath, S.K., Rashed, M.G., Uddin, M.Z.: Privacy preserving big data analytics: A critical anal- ysisofstate-of-the-art.WIREsDataMiningandKnowledgeDiscovery11(1),e1387 (2021).https://doi.org/10.1002/widm.1387
-
[25]
Progress Software Corporation: Chef- infrastructure automation platform (2025), https://www.chef.io/, accessed: 2026-05-23
2025
-
[26]
Project Jupyter: JupyterHub,https://jupyter.org/hub, accessed: 2026-05-23
2026
-
[27]
Project Jupyter Contributors: Messaging in jupyter — jupyter_client 8.8.1.dev0 documentation,https://jupyter-client.readthedocs.io/en/ latest/messaging.html, accessed: 2026-05-19
2026
-
[28]
Project Jupyter Contributors: Widget — ipywidgets documentation, https://ipywidgets.readthedocs.io/en/latest/examples/Widget%20Low% 20Level.html, accessed: 2026-05-18
2026
-
[29]
Pulumi Corporation: Pulumi (2025),https://www.pulumi.com/, accessed: 2026- 05-23
2025
-
[30]
com/, accessed: 2026-05-23
Red Hat, Inc.: Ansible - it automation platform (2025),https://www.ansible. com/, accessed: 2026-05-23
2025
-
[31]
Roškar, R.: sparkhpc,https://github.com/rokroskar/sparkhpc, accessed: 2026- 03-15
2026
-
[32]
JBDTP Professional1(1), 51–65 (2022).https://doi.org/10.54116/jbdtp.v1i1.16
Samuel, J., Brennan-Tonetta, M., Samuel, Y., Subedi, P., Smith, J.: Strategies for democratization of supercomputing: Availability, accessibility and usability of high performance computing for education and practice of big data analytics. JBDTP Professional1(1), 51–65 (2022).https://doi.org/10.54116/jbdtp.v1i1.16
-
[33]
SchedMD LLC: SLURM: Simple Linux Utility for Resource Management (2025), https://slurm.schedmd.com/overview.html, accessed: 2026-05-23
2025
-
[34]
Shahnawaz, M., Kumar, M.: A comprehensive survey on big data analytics: Characteristics, tools and techniques. ACM Comput. Surv.57(8) (Mar 2025). https://doi.org/10.1145/3718364
-
[35]
The Apache Software Foundation: Cluster mode overview - spark 4.1.1 doc- umentation.https://spark.apache.org/docs/latest/cluster-overview.html, accessed: 2026-05-18
2026
-
[36]
apache.org/flink/flink-docs-stable/docs/internals/job_scheduling/, ac- cessed: 2026-05-18
The Apache Software Foundation: Jobs and scheduling.https://nightlies. apache.org/flink/flink-docs-stable/docs/internals/job_scheduling/, ac- cessed: 2026-05-18
2026
-
[37]
The Apache Software Foundation: PySpark overview - PySpark 4.1.1 doc- umentation.https://spark.apache.org/docs/latest/api/python/index.html, accessed: 2026-05-18
2026
-
[38]
VMware, Inc.: Salt- intelligent it automation software (2025),https:// saltproject.io/, accessed: 2026-05-23
2025
-
[39]
IEEE Software33(2), 60–67 (2016).https://doi.org/10.1109/MS.2016.35
Wu, D., Zhu, L., Xu, X., Sakr, S., Sun, D., Lu, Q.: Building pipelines for heteroge- neous execution environments for big data processing. IEEE Software33(2), 60–67 (2016).https://doi.org/10.1109/MS.2016.35
-
[40]
Zhang, M.: jupyterlab spark: A jupyterlab extension to show spark application ui in a jupyterlab panel,https://github.com/manuzhang/jupyterlab_spark, accessed: 2026-03-15
2026
-
[41]
ZIH Team: HPC Systems,https://tu-dresden.de/zih/hochleistungsrechnen/ hpc, accessed: 2026-05-17
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.