Agentic Generation of AST Transformation Rules for Fixing Breaking Updates
Pith reviewed 2026-06-25 22:53 UTC · model grok-4.3
The pith
An agentic framework generates reusable AST transformations that fix breaking library updates across projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
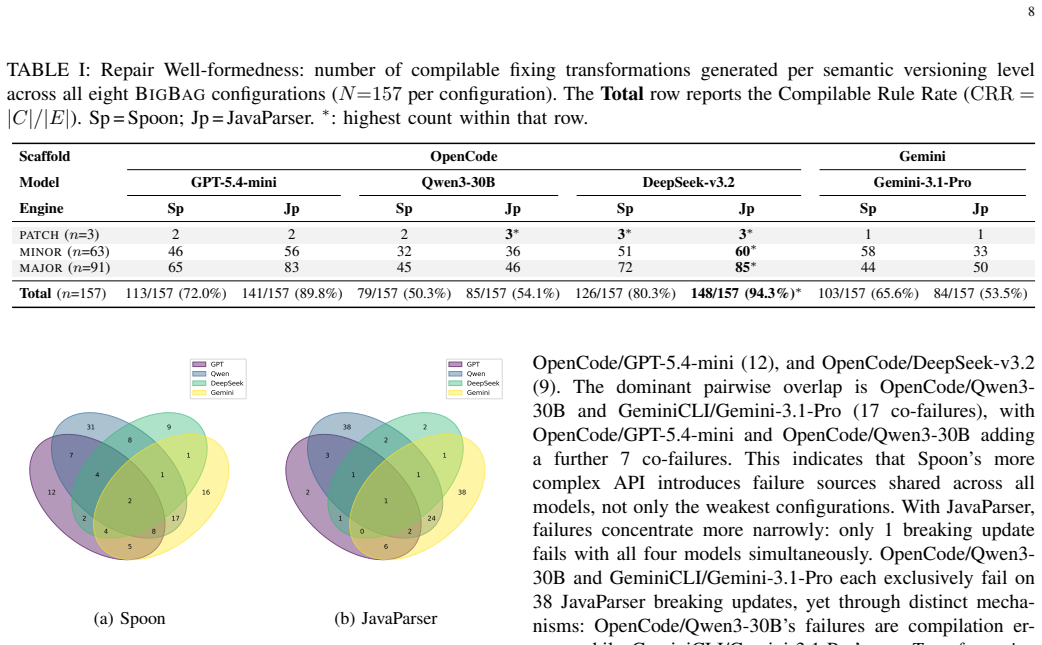
BigBag generates fixing transformations as executable programs that encode repair logic at the API level and transfer to any client broken by the same update, achieving 94.3 percent compilable rate and 78.6 percent fix rate on 157 BUMP cases with cross-project transfer of 33.3 percent overall.
What carries the argument
BigBag, an agentic framework that combines large language models with AST transformation engines (Spoon and JavaParser) to produce reusable fixing programs for breaking dependency updates.
If this is right
- Repair logic can be written once per breaking update and applied to every client project affected by that update.
- Projects can adopt library updates without each one requiring separate patch generation.
- Fixes become more reliable when all clients invoke the changed API element in the same way.
- The method applies to Java projects and can use either Spoon or JavaParser as the underlying AST engine.
Where Pith is reading between the lines
- A shared repository of generated transformations could reduce duplicated repair work across the open-source ecosystem.
- The approach could be tested on breaking changes that affect only a subset of clients to measure how performance drops with non-uniform usage.
- Integration with continuous integration pipelines might allow automatic detection of breaking updates followed by application of stored transformations.
Load-bearing premise
The agentic LLM process produces correct, executable AST transformations that generalize to new cases without introducing fresh compilation or runtime errors.
What would settle it
Running the same eight configurations on a fresh collection of breaking updates outside the 157 BUMP cases and obtaining fix rates well below 78.6 percent would show the approach does not scale as claimed.
Figures



read the original abstract
Modern software projects depend on third-party libraries that evolve continuously, introducing breaking API changes that prevent client code from compiling after a dependency update. When the same library update breaks multiple projects, existing repair approaches generate project-specific patches that cannot be reused, requiring each affected project to be repaired independently. We present BigBag, an agentic framework that generates fixing transformations: structured, executable programs that encode the repair logic at the API level and transfer to any client broken by the same update. We evaluate BigBag on 157 compilation failure breaking dependency updates from the BUMP benchmark, across eight configurations combining four large language models and two AST transformation engines (Spoon and JavaParser). The best configuration achieves a compilable transformation rate of 94.3% and a fix rate of 78.6%. Generated transformations transfer across projects, achieving a cross-project fix rate of 33.3% overall and 80% or above for breaking updates where all clients invoke the affected API element uniformly. These results show that agentic generation of reusable fixing transformations is a viable approach to scalable repair of breaking updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BigBag, an agentic framework that uses LLMs to generate structured, executable AST transformation rules (via Spoon or JavaParser) for repairing breaking dependency updates in Java client code. Evaluated on 157 compilation-failure cases from the BUMP benchmark across eight LLM+engine configurations, the best setup reports a 94.3% rate of compilable transformations and a 78.6% fix rate; generated rules also transfer across projects at 33.3% overall (and ≥80% when all clients invoke the affected API uniformly). The central claim is that this yields a viable, scalable approach to reusable repair of breaking updates.
Significance. If the generated transformations are shown to be semantically correct, the work would demonstrate a practical route to reusable, API-level fixes that avoid per-project patching. The empirical scale (157 cases, multiple models/engines, concrete rates, and cross-project transfer results) and use of an external benchmark are strengths that would support the viability argument.
major comments (2)
- [Evaluation] Evaluation section (results on 157 BUMP cases): success is defined exclusively via post-application compilation (94.3% compilable transformations, 78.6% fix rate). No test-suite execution, differential testing, or semantic-equivalence oracle is reported, so the rates do not establish that the transformations preserve original behavior or avoid introducing new runtime faults. This directly affects the interpretation of both the headline fix rate and the cross-project transfer claim.
- [Evaluation] Cross-project transfer results (33.3% overall, ≥80% on uniform-invocation subset): the paper does not detail how the subset of cases with uniform API invocation was identified or whether the same transformation was applied without project-specific adaptation. Without this, it is unclear whether the reported transfer rates reflect genuine reusability or selection effects in the benchmark.
minor comments (1)
- [Abstract] The abstract and evaluation should explicitly state the exact definition of 'fix rate' (e.g., does it require the original failing compilation to succeed, or merely any compilation success?).
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below and have revised the paper to improve clarity on the evaluation methodology and limitations.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (results on 157 BUMP cases): success is defined exclusively via post-application compilation (94.3% compilable transformations, 78.6% fix rate). No test-suite execution, differential testing, or semantic-equivalence oracle is reported, so the rates do not establish that the transformations preserve original behavior or avoid introducing new runtime faults. This directly affects the interpretation of both the headline fix rate and the cross-project transfer claim.
Authors: We agree that compilation success serves as a proxy metric and does not by itself confirm semantic equivalence or the absence of new runtime issues. The BUMP benchmark centers on compilation failures induced by breaking updates, so our fix rate specifically quantifies restoration of compilability. We have revised the Evaluation section to explicitly define the scope of this metric and added a dedicated Limitations subsection that acknowledges the lack of test-suite or oracle-based validation while outlining plans for future semantic verification work. revision: yes
-
Referee: [Evaluation] Cross-project transfer results (33.3% overall, ≥80% on uniform-invocation subset): the paper does not detail how the subset of cases with uniform API invocation was identified or whether the same transformation was applied without project-specific adaptation. Without this, it is unclear whether the reported transfer rates reflect genuine reusability or selection effects in the benchmark.
Authors: The uniform-invocation subset was identified via manual review of client code in the BUMP cases, classifying an update as uniform when every affected client invoked the changed API element identically (same signature and usage pattern). The identical generated transformation rule was then applied to all projects in the subset with no per-project adaptation. We have added a new explanatory paragraph in the Cross-Project Transfer subsection that describes the identification criteria and confirms verbatim rule application. revision: yes
Circularity Check
No circularity: purely empirical evaluation on external benchmark
full rationale
The paper reports experimental results from applying an agentic LLM framework to the independent BUMP benchmark of 157 breaking updates, measuring compilable transformation rate (94.3%) and fix rate (78.6%) plus cross-project transfer. No equations, parameters, derivations, or self-citations are used to derive claims; success metrics are defined directly from observable outcomes on the external test set. The work is self-contained against external benchmarks with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate correct and executable AST transformation rules for API-level breaking changes
Reference graph
Works this paper leans on
-
[1]
An empirical comparison of dependency network evolution in seven software packaging ecosystems,
A. Decan, T. Mens, and P. Grosjean, “An empirical comparison of dependency network evolution in seven software packaging ecosystems,” Empirical Software Engineering, vol. 24, no. 1, pp. 381–416, Feb
-
[2]
Available: https://doi.org/10.1007/s10664-017-9589-y
[Online]. Available: https://doi.org/10.1007/s10664-017-9589-y
-
[3]
Why and how Java developers break APIs,
A. Brito, L. Xavier, A. Hora, and M. T. Valente, “Why and how Java developers break APIs,” in2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER), 2018, pp. 255–265
2018
-
[4]
Can automated pull requests encourage software developers to upgrade out-of-date dependencies?
S. Mirhosseini and C. Parnin, “Can automated pull requests encourage software developers to upgrade out-of-date dependencies?” in2017 32nd IEEE/ACM international conference on automated software engineering (ASE). IEEE, 2017, pp. 84–94
2017
-
[5]
How do APIs evolve? A story of refactoring: Research Articles,
D. Dig and R. Johnson, “How do APIs evolve? A story of refactoring: Research Articles,”J. Softw. Maint. Evol., vol. 18, no. 2, p. 83–107, Mar. 2006
2006
-
[6]
Breaking bad? semantic versioning and impact of breaking changes in maven central: An external and differentiated replication study,
L. Ochoa, T. Degueule, J.-R. Falleri, and J. Vinju, “Breaking bad? semantic versioning and impact of breaking changes in maven central: An external and differentiated replication study,”Empirical Software Engineering, vol. 27, no. 3, p. 61, 2022
2022
-
[7]
Byam: Fixing breaking dependency updates with large language models,
F. Reyes, M. Mahmoud, F. Bono, S. Nadi, B. Baudry, and M. Monper- rus, “Byam: Fixing breaking dependency updates with large language models,”Empirical Software Engineering, vol. 31, no. 4, p. 113, 2026
2026
-
[8]
Automatically Fixing Dependency Breaking Changes,
F. Lukas and K. Jens, “Automatically Fixing Dependency Breaking Changes,”Proceedings of the Conference on the Foundations of Software Engineering, pp. 2146–2168, 2025
2025
-
[9]
ReAct: Synergizing Reasoning and Acting in Language Models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing Reasoning and Acting in Language Models,” in Proceedings of the Eleventh International Conference on Learning Representations (ICLR 2023). Kigali, Rwanda: OpenReview.net, 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
2023
-
[10]
BUMP: A Benchmark of Reproducible Breaking Dependency Up- dates,
F. Reyes, Y . Gamage, G. Skoglund, B. Baudry, and M. Monperrus, “BUMP: A Benchmark of Reproducible Breaking Dependency Up- dates,” in2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), 2024, pp. 159–170
2024
-
[11]
SPELL: Synthesis of Programmatic Edits using LLMs,
D. Ramos, C. Gamboa, I. Lynce, V . Manquinho, R. Martins, and C. Le Goues, “SPELL: Synthesis of Programmatic Edits using LLMs,”arXiv preprint arXiv:2602.01107, 2026
arXiv 2026
-
[12]
Do developers update their library dependencies? An empirical study on the impact of security advisories on library migration,
R. G. Kula, D. M. German, A. Ouni, T. Ishio, and K. Inoue, “Do developers update their library dependencies? An empirical study on the impact of security advisories on library migration,”Empirical Software Engineering, vol. 23, no. 1, pp. 384–417, 2018
2018
-
[13]
A survey of software refactoring,
T. Mens and T. Tourwe, “A survey of software refactoring,”IEEE Transactions on Software Engineering, vol. 30, no. 2, pp. 126–139, 2004
2004
-
[14]
Source transformation, analysis and generation in TXL,
J. R. Cordy, “Source transformation, analysis and generation in TXL,” inProceedings of the 2006 ACM SIGPLAN Symposium on Partial Evaluation and Semantics-Based Program Manipulation, ser. PEPM ’06. New York, NY , USA: Association for Computing Machinery, 2006, p. 1–11. [Online]. Available: https://doi.org/10.1145/1111542.1111544
-
[15]
Design patterns: Abstraction and reuse of object-oriented design,
E. Gamma, R. Helm, R. Johnson, and J. Vlissides, “Design patterns: Abstraction and reuse of object-oriented design,” inEuropean conference on object-oriented programming. Springer, 1993, pp. 406–431
1993
-
[16]
Spoon: A Library for Implementing Analyses and Transformations of Java Source Code,
R. Pawlak, M. Monperrus, N. Petitprez, C. Noguera, and L. Seinturier, “Spoon: A Library for Implementing Analyses and Transformations of Java Source Code,”Software: Practice and Experience, vol. 46, pp. 1155–1179, 2015. [Online]. Available: https://hal.archives-ouvertes.fr/ hal-01078532/document
2015
-
[17]
Javaparser: visited,
N. Smith, D. Van Bruggen, and F. Tomassetti, “Javaparser: visited,” Leanpub, oct. de, vol. 10, pp. 29–40, 2017
2017
-
[18]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50 528–50 652, 2024
2024
-
[19]
Introducing GPT-5.4 mini and nano — OpenAI
“Introducing GPT-5.4 mini and nano — OpenAI.” [Online]. Available: https://openai.com/index/introducing-gpt-5-4-mini-and-nano/
-
[20]
Qwen3 Coder 30B A3B Instruct - API Pricing & Benchmarks — OpenRouter
“Qwen3 Coder 30B A3B Instruct - API Pricing & Benchmarks — OpenRouter.” [Online]. Available: https://openrouter.ai/qwen/ qwen3-coder-30b-a3b-instruct
-
[21]
Deepseek-v3. 2: Pushing the frontier of open large language models,
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Donget al., “Deepseek-v3. 2: Pushing the frontier of open large language models,”arXiv preprint arXiv:2512.02556, 2025
Pith/arXiv arXiv 2025
-
[22]
Gemini 3.1 Pro - Model Card — Google DeepMind
“Gemini 3.1 Pro - Model Card — Google DeepMind.” [Online]. Avail- able: https://deepmind.google/models/model-cards/gemini-3-1-pro/
-
[23]
On randomness in agentic evals,
B. H. Bjarnason, A. Silva, and M. Monperrus, “On randomness in agentic evals,”arXiv preprint arXiv:2602.07150, 2026
arXiv 2026
-
[24]
Recommending adaptive changes for framework evolution,
B. Dagenais and M. P. Robillard, “Recommending adaptive changes for framework evolution,”ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 20, no. 4, pp. 1–35, 2011. 14
2011
-
[25]
Breaking-Good: Explaining Breaking Dependency Updates with Build Analysis,
F. Reyes, B. Baudry, and M. Monperrus, “Breaking-Good: Explaining Breaking Dependency Updates with Build Analysis,” in2024 IEEE International Conference on Source Code Analysis and Manipulation (SCAM), 2024, pp. 36–46
2024
-
[26]
MELT: Mining Effective Lightweight Transformations from Pull Requests,
D. Ramos, H. Mitchell, I. Lynce, V . M. Manquinho, R. Martins, and C. Le Goues, “MELT: Mining Effective Lightweight Transformations from Pull Requests,” in2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2023, pp. 1516–1528
2023
-
[27]
FOSSA: Automated dependency review and breaking change analysis,
“FOSSA: Automated dependency review and breaking change analysis,” https://fossa.com/products/fossabot/, 2025, accessed 2025
2025
-
[28]
Patchwork: Automated patch generation and dependency repair,
“Patchwork: Automated patch generation and dependency repair,” https: //docs.patched.codes/patchwork/overview, 2025, accessed 2025
2025
-
[29]
Genprog: A generic method for automatic software repair,
C. Le Goues, T. Nguyen, S. Forrest, and W. Weimer, “Genprog: A generic method for automatic software repair,”Ieee transactions on software engineering, vol. 38, no. 1, pp. 54–72, 2011
2011
-
[30]
Automated program repair in the era of large pre-trained language models,
C. S. Xia, Y . Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 1482–1494
2023
-
[31]
An analysis of the automatic bug fixing performance of chatgpt,
D. Sobania, M. Briesch, C. Hanna, and J. Petke, “An analysis of the automatic bug fixing performance of chatgpt,” in2023 IEEE/ACM International Workshop on Automated Program Repair (APR). IEEE, 2023, pp. 23–30
2023
-
[32]
Learning Syntactic Program Transformations from Examples,
R. R. de Sousa, G. Soares, L. D’Antoni, O. Polozov, S. Gulwani, R. Gheyi, R. Suzuki, and B. Hartmann, “Learning Syntactic Program Transformations from Examples,”2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), pp. 404–415, 2016. [Online]. Available: https://api.semanticscholar.org/CorpusID:11216724
2017
-
[33]
Learning to fix build errors with graph2diff neural net- works,
D. Tarlow, S. Moitra, A. Rice, Z. Chen, P.-A. Manzagol, C. Sutton, and E. Aftandilian, “Learning to fix build errors with graph2diff neural net- works,” inProceedings of the IEEE/ACM 42nd International Conference on Software Engineering Workshops, 2020, pp. 19–20
2020
-
[34]
Auto-repair without test cases: How LLMs fix compilation errors in large industrial embedded code,
H. Fu, S. Eldh, K. Wiklund, A. Ermedahl, P. Haller, and C. Artho, “Auto-repair without test cases: How LLMs fix compilation errors in large industrial embedded code,” in2025 28th Euromicro Conference on Digital System Design (DSD), 2025, pp. 97–105
2025
-
[35]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[36]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[37]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” 2024. [Online]. Available: https://arxiv. org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[38]
GitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities,
D. Misra, N. Islah, V . May, B. Rauby, Z. Wang, J. Gehring, A. Orvieto, M. Chaudhary, E. B. Muller, I. Rish, S. Ebrahimi Kahou, and M. Caccia, “GitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[39]
FreshBrew: A Benchmark for Evaluating AI Agents on Java Code Migration,
V . May, D. Misra, Y . Luo, A. Sridhar, J. Gehring, and S. Soares Ribeiro Junior, “FreshBrew: A Benchmark for Evaluating AI Agents on Java Code Migration,”arXiv preprint arXiv:2510.04852, 2025
arXiv 2025
-
[40]
Code Transformation Rule Synthesis Using LLMs: Potential and Limits,
A. Allain, A. Blot, D. E. Khelladi, and M. Acher, “Code Transformation Rule Synthesis Using LLMs: Potential and Limits,” HAL preprint hal-05607247, 2026. [Online]. Available: https://hal. science/hal-05607247v1
2026
-
[41]
Unprecedented Code Change Automation: The Fusion of LLMs and Transformation by Example,
M. Dilhara, A. Bellur, T. Bryksin, and D. Dig, “Unprecedented Code Change Automation: The Fusion of LLMs and Transformation by Example,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, 2024
2024
-
[42]
Don’t Transform the Code, Code the Trans- forms: Towards Precise Code Rewriting using LLMs,
C. Cummins, V . Seeker, J. Armengol-Estap ´e, A. H. Markosyan, G. Syn- naeve, and H. Leather, “Don’t Transform the Code, Code the Trans- forms: Towards Precise Code Rewriting using LLMs,” arXiv preprint arXiv:2410.08806, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.