Advancing WordArt-Oriented Scene Text Recognition: Datasets and Methods
Pith reviewed 2026-06-26 01:03 UTC · model grok-4.3
The pith
A 2-million-image synthetic dataset paired with an arbitrary-shape encoder and autoregressive decoder reaches 90.4 percent accuracy on WordArt scene text recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
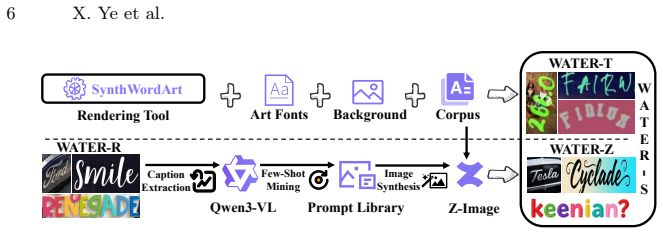
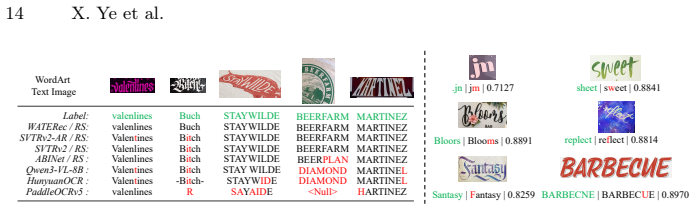
By generating two complementary subsets of WATER-S—one via an upgraded SynthWordArt renderer and one via Qwen3-VL prompt mining plus Z-Image synthesis—and training WATERec with an arbitrary-shape visual encoder plus autoregressive decoder, the system attains 90.40 percent accuracy on WordArt-Bench while surpassing prior STR methods and both general-purpose and OCR-specialized vision-language models.
What carries the argument
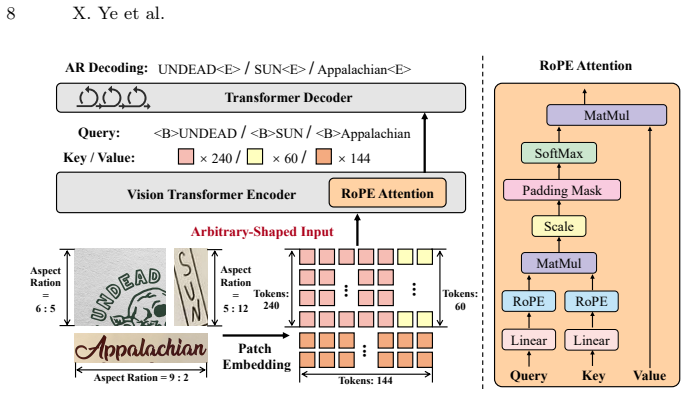
WATERec, a model that pairs a visual encoder supporting arbitrary-shaped inputs with an autoregressive decoder to model complex layouts.
If this is right
- The architecture removes the fixed-template bottleneck that limits conventional scene-text recognizers on irregular artistic text.
- Performance on WordArt-Bench exceeds both general vision-language models and OCR-specialized models by a large margin.
- The two-part synthetic construction supplies controllable yet diverse training data at a scale previously unavailable for this task.
- Reorganization of existing real STR data into WATER-R further strengthens the baseline when combined with the new synthetic set.
Where Pith is reading between the lines
- The same synthesis-plus-autoregressive approach could be tested on related stylized-text domains such as comic lettering or product logos.
- Real deployment would likely require targeted fine-tuning on domain-specific artistic styles not fully represented in the current generation pipeline.
- The method suggests a template for scaling recognition in other data-scarce visual domains by pairing large synthetic sets with layout-aware decoders.
Load-bearing premise
The synthetic images produced by the upgraded rendering pipeline and the AI synthesis tools capture the visual diversity and real-world challenges of artistic text without introducing biases that block generalization.
What would settle it
Measuring accuracy on a fresh collection of real-world photographs of artistic text that were never used in the synthetic generation or the WordArt-Bench construction would directly test whether performance holds outside the created data.
Figures








read the original abstract
WordArt (artistic text) features highly customized fonts, textures, and layouts, making WordArt-oriented scene TExt Recognition (WATER) substantially more challenging than general Scene Text Recognition (STR). Existing STR datasets and methods, typically built around regular scene text and fixed-template inputs, struggle to scale to WATER. Thus, we aim to advance this task from both data and model perspectives. On the data side, we construct a 2M synthetic dataset, WATER-S, with the scale improved by hundreds of times compared to existing artistic text data. WATER-S consists of two complementary subsets. One rendered by an upgraded rendering pipeline (SynthWordArt), which provides highly accurate and controllable synthetic WordArt data. The other is generated by combining Qwen3-VL for prompt mining and Z-Image for image synthesis, which improves the coverage of realistic and diverse data. On the model side, we propose WATERec. It adopts an visual encoder supporting arbitrary-shaped inputs and an autoregressive decoder to model complex layouts, structurally breaking the bottleneck of fixed-template STR on WordArt. Experiments show that this architecture outperforms prior STR methods, achieving state-of-the-art performance on irregular texts such as WordArt. Together with WATER-R, carefully reorganized from existing real STR data, our strong baseline with the new synthetic data and model design reaches 90.40% accuracy on WordArt-Bench, surpassing both general-purpose and OCR-specialized vision-language models by a large margin. Code and data are available at https://github.com/YesianRohn/WATER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to advance WordArt-oriented scene text recognition (WATER) by constructing a 2M-image synthetic dataset WATER-S via an upgraded SynthWordArt pipeline and Qwen3-VL/Z-Image AI synthesis, reorganizing existing real data into WATER-R, and introducing the WATERec architecture with an arbitrary-shaped visual encoder plus autoregressive decoder. Experiments are reported to yield 90.40% accuracy on WordArt-Bench, outperforming both general-purpose and OCR-specialized vision-language models, with public code and data release.
Significance. If the empirical results hold, the work provides a substantial contribution to scene text recognition by scaling artistic-text data by hundreds of times and structurally departing from fixed-template STR architectures. The public release of code and data is an explicit strength supporting reproducibility and future benchmarking.
major comments (2)
- [Abstract] Abstract: The central performance claim of 90.40% accuracy and SOTA status is asserted without any specification of the evaluation metric (word accuracy, character accuracy, etc.), the exact baselines compared, data splits used, or controls for the synthetic-to-real domain gap. This information is load-bearing for assessing whether the reported margin over prior methods is robust.
- [Experiments] Experiments section: No error bars, multiple runs, or statistical significance tests are referenced for the 90.40% result or the architectural improvements, undermining confidence in the claim that WATERec plus the new data reliably surpasses existing STR and VLM approaches.
minor comments (2)
- [Abstract] The abstract introduces 'WordArt-Bench' without a one-sentence definition or pointer to its construction, which would aid readers unfamiliar with the benchmark.
- Notation for the two subsets of WATER-S (SynthWordArt-rendered vs. AI-synthesized) could be introduced more explicitly when first mentioned to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarity and experimental robustness. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim of 90.40% accuracy and SOTA status is asserted without any specification of the evaluation metric (word accuracy, character accuracy, etc.), the exact baselines compared, data splits used, or controls for the synthetic-to-real domain gap. This information is load-bearing for assessing whether the reported margin over prior methods is robust.
Authors: We agree the abstract requires greater precision. The reported 90.40% is word-level accuracy on the WordArt-Bench test split following the standard STR evaluation protocol (exact match after normalization). Baselines encompass both prior STR models (e.g., ABINet, PARSeq) and VLMs (e.g., Qwen-VL, GPT-4V). Data splits match the public WordArt-Bench definitions, and domain-gap controls consist of training exclusively on synthetic WATER-S while evaluating solely on real images in WATER-R and WordArt-Bench. We will revise the abstract to state these details explicitly. revision: yes
-
Referee: [Experiments] Experiments section: No error bars, multiple runs, or statistical significance tests are referenced for the 90.40% result or the architectural improvements, undermining confidence in the claim that WATERec plus the new data reliably surpasses existing STR and VLM approaches.
Authors: We acknowledge that error bars and multi-run statistics would increase confidence. All results derive from single training runs, consistent with common practice for large-scale (2M-image) experiments in the STR literature. We will add an explicit limitations paragraph in the experiments section noting the single-run nature and computational rationale. We cannot supply new multi-seed results or significance tests without substantial additional compute. revision: partial
Circularity Check
No significant circularity; purely empirical contribution
full rationale
The paper advances WATER via dataset construction (2M synthetic WATER-S from upgraded SynthWordArt pipeline plus Qwen3-VL/Z-Image synthesis) and a new architecture (WATERec: arbitrary-shape visual encoder + autoregressive decoder), plus reorganized real data WATER-R. The central claim is the empirical result of 90.40% accuracy on WordArt-Bench. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear. All steps are data/model engineering evaluated on external benchmarks; the chain is self-contained and falsifiable outside any internal fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- Model training hyperparameters
axioms (2)
- domain assumption Synthetic data from upgraded rendering and VLM-guided synthesis approximates real WordArt distributions sufficiently for model training and evaluation
- domain assumption Autoregressive decoding can effectively capture complex text layouts where fixed-template methods fail
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
Pith/arXiv arXiv 2025
-
[2]
In: ECCV
Bautista, D., Atienza, R.: Scene text recognition with permuted autoregressive sequence models. In: ECCV. pp. 178–196 (2022)
2022
-
[3]
Cai, H., Cao, S., Du, R., Gao, P., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L., et al.: Z-image: An efficient image generation foundation model with single-stream diffusion transformer. CoRRabs/2511.22699(2025)
Pith/arXiv arXiv 2025
-
[4]
Chen, J., Yu, H., Ma, J., Guan, M., Xu, X., Wang, X., Qu, S., Li, B., Xue, X.: Benchmarkingchinesetextrecognition:Datasets,baselines,andanempiricalstudy. CoRRabs/2112.15093(2021)
arXiv 2021
-
[5]
In: CVPR
Cui, C., Sun, T., Liang, S., Gao, T., Zhang, Z., Liu, J., Wang, X., Zhou, C., Liu, H., Lin, M., et al.: Boosting document parsing efficiency and performance with coarse-to-fine visual processing. In: CVPR. pp. 16655–16665 (2026)
2026
-
[6]
Cui, C., Sun, T., Lin, M., Gao, T., Zhang, Y., Liu, J., Wang, X., Zhang, Z., Zhou, C., Liu, H., et al.: Paddleocr 3.0 technical report. CoRRabs/2507.05595(2025)
Pith/arXiv arXiv 2025
-
[7]
NeurIPS36, 2252– 2274 (2023)
Dehghani, M., Mustafa, B., Djolonga, J., Heek, J., Minderer, M., Caron, M., Steiner, A., Puigcerver, J., Geirhos, R., Alabdulmohsin, I.M., et al.: Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution. NeurIPS36, 2252– 2274 (2023)
2023
-
[8]
Deshmukh, A.S., Chumachenko, K., Rintamaki, T., Le, M., Poon, T., Taheri, D.M., Karmanov, I., Liu, G., Seppanen, J., Chen, G., et al.: Nvidia nemotron nano v2 vl. CoRRabs/2511.03929(2025)
arXiv 2025
-
[9]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[10]
In: AAAI
Du, Y., Chen, Z., Jia, C., Gao, X., Jiang, Y.G.: Out of length text recognition with sub-string matching. In: AAAI. vol. 39, pp. 2798–2806 (2025)
2025
-
[11]
Du, Y., Chen, Z., Jia, C., Yin, X., Li, C., Du, Y., Jiang, Y.G.: Context perception parallel decoder for scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 47(6), 4668–4683 (2025).https://doi.org/10.1109/TPAMI.2025.3545453
-
[12]
In: IJCAI
Du, Y., Chen, Z., Jia, C., Yin, X., Zheng, T., Li, C., Du, Y., Jiang, Y.G.: SVTR: Scene text recognition with a single visual model. In: IJCAI. pp. 884–890 (2022)
2022
-
[13]
In: ICCV
Du, Y., Chen, Z., Xie, H., Jia, C., Jiang, Y.G.: Svtrv2: Ctc beats encoder-decoder models in scene text recognition. In: ICCV. pp. 20147–20156 (2025) 16 X. Ye et al
2025
-
[14]
IEEE Trans
Du, Y., Chen, Z., Yuchen, S., Jia, C., Jiang, Y.G.: Instruction-guided scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell.47(4), 2723–2738 (2025)
2025
-
[15]
In: AAAI
Du, Y., Zhao, M., Fan, S., Chen, Z., Jia, C., Jiang, Y.G.: Mdiff4str: Mask diffusion model for scene text recognition. In: AAAI. vol. 40, pp. 3705–3713 (2026)
2026
-
[16]
In: CVPR
Fang, S., Xie, H., Wang, Y., Mao, Z., Zhang, Y.: Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In: CVPR. pp. 7098–7107 (2021)
2021
-
[17]
In: ICML
Graves, A., Fernández, S., Gomez, F., Schmidhuber, J.: Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural net- works. In: ICML. pp. 369–376 (2006)
2006
-
[18]
Guan, T., Shen, W., Yang, X.: Ccdplus: Towards accurate character to character distillation for text recognition. IEEE Trans. Pattern Anal. Mach. Intell.47(5), 3546–3562 (2025).https://doi.org/10.1109/TPAMI.2025.3533737
-
[19]
In: ICCV
Guan, T., Shen, W., Yang, X., Feng, Q., Jiang, Z., Yang, X.: Self-supervised character-to-character distillation for text recognition. In: ICCV. pp. 19473–19484 (2023)
2023
-
[20]
In: CVPR
Gupta, A., Vedaldi, A., Zisserman, A.: Synthetic data for text localisation in nat- ural images. In: CVPR. pp. 2315–2324 (2016)
2016
-
[21]
In: ECCV
Heo, B., Park, S., Han, D., Yun, S.: Rotary position embedding for vision trans- former. In: ECCV. pp. 289–305 (2024)
2024
-
[22]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[23]
Jaderberg, M., Simonyan, K., Vedaldi, A., Zisserman, A.: Synthetic data and ar- tificial neural networks for natural scene text recognition. CoRRabs/1406.2227 (2014)
Pith/arXiv arXiv 2014
-
[24]
In: ICCV
Jiang, Q., Wang, J., Peng, D., Liu, C., Jin, L.: Revisiting scene text recognition: A data perspective. In: ICCV. pp. 20486–20497 (2023)
2023
-
[25]
In: ICDAR
Karatzas, D., Gomez-Bigorda, L., Nicolaou, A., Ghosh, S., Bagdanov, A., Iwamura, M., Matas, J., Neumann, L., Chandrasekhar, V.R., Lu, S., et al.: ICDAR 2015 competition on robust reading. In: ICDAR. pp. 1156–1160 (2015)
2015
-
[26]
In: ICDAR
Karatzas, D., Shafait, F., Uchida, S., Iwamura, M., i Bigorda, L.G., Mestre, S.R., Mas, J., Mota, D.F., Almazan, J.A., De Las Heras, L.P.: ICDAR 2013 robust reading competition. In: ICDAR. pp. 1484–1493 (2013)
2013
-
[27]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space. CoRRabs/2506.15742(2025)
Pith/arXiv arXiv 2025
-
[28]
In: AAAI
Li, H., Wang, P., Shen, C., Zhang, G.: Show, attend and read: A simple and strong baseline for irregular text recognition. In: AAAI. vol. 33, pp. 8610–8617 (2019)
2019
-
[29]
In: AAAI
Li, M., Lv, T., Chen, J., Cui, L., Lu, Y., Florencio, D., Zhang, C., Li, Z., Wei, F.: Trocr: Transformer-based optical character recognition with pre-trained models. In: AAAI. vol. 37, pp. 13094–13102 (2023)
2023
-
[30]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[31]
In: BMVC
Mishra, A., Alahari, K., Jawahar, C.: Scene text recognition using higher order language priors. In: BMVC. pp. 1–11 (2012)
2012
-
[32]
In: ICCV
Phan, T.Q., Shivakumara, P., Tian, S., Tan, C.L.: Recognizing text with perspec- tive distortion in natural scenes. In: ICCV. pp. 569–576 (2013)
2013
-
[33]
In: ACM MM
Qiao, Z., Zhou, Y., Wei, J., Wang, W., Zhang, Y., Jiang, N., Wang, H., Wang, W.: Pimnet: a parallel, iterative and mimicking network for scene text recognition. In: ACM MM. pp. 2046–2055 (2021) Advancing WordArt-Oriented Scene Text Recognition 17
2046
-
[34]
ESWA41(18), 8027–8048 (2014)
Risnumawan, A., Shivakumara, P., Chan, C.S., Tan, C.L.: A robust arbitrary text detection system for natural scene images. ESWA41(18), 8027–8048 (2014)
2014
-
[35]
In: ICDAR
Sheng, F., Chen, Z., Xu, B.: NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In: ICDAR. pp. 781–786 (2019)
2019
-
[36]
Shi, B., Bai, X., Yao, C.: An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell.39(11), 2298–2304 (2016).https://doi.org/10.1109/ TPAMI.2016.2646371
arXiv 2016
-
[37]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[38]
Team, H.V., Lyu, P., Wan, X., Li, G., Peng, S., Wang, W., Wu, L., Shen, H., Zhou, Y., Tang, C., et al.: Hunyuanocr technical report. CoRRabs/2511.19575(2025)
arXiv 2025
-
[39]
In: ICCV
Wang, K., Babenko, B., Belongie, S.: End-to-end scene text recognition. In: ICCV. pp. 1457–1464 (2011)
2011
-
[40]
5: Advancing open-source multimodal models in versatility, reasoning, and efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. CoRRabs/2508.18265(2025)
Pith/arXiv arXiv 2025
-
[41]
Wei, H., Liu, C., Chen, J., Wang, J., Kong, L., Xu, Y., Ge, Z., Zhao, L., Sun, J., Peng, Y., et al.: General ocr theory: Towards ocr-2.0 via a unified end-to-end model. CoRRabs/2409.01704(2024)
Pith/arXiv arXiv 2024
-
[42]
Wei, H., Sun, Y., Li, Y.: Deepseek-ocr: Contexts optical compression. CoRR abs/2510.18234(2025)
Pith/arXiv arXiv 2025
-
[43]
Wei, H., Sun, Y., Li, Y.: Deepseek-ocr 2: Visual causal flow. CoRR abs/2601.20552(2026)
arXiv 2026
-
[44]
In: AAAI
Wei, J., Zhan, H., Lu, Y., Tu, X., Yin, B., Liu, C., Pal, U.: Image as a language: Revisiting scene text recognition via balanced, unified and synchronized vision- language reasoning network. In: AAAI. vol. 38, pp. 5885–5893 (2024)
2024
-
[45]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. CoRRabs/2508.02324(2025)
Pith/arXiv arXiv 2025
-
[46]
In: ICDAR
Xie, X., Deng, L., Zhang, Z., Wang, Z., Liu, Y.: Icdar 2024 competition on artistic text recognition. In: ICDAR. pp. 301–314 (2024)
2024
-
[47]
In: ECCV
Xie, X., Fu, L., Zhang, Z., Wang, Z., Bai, X.: Toward understanding wordart: Corner-guided transformer for scene text recognition. In: ECCV. pp. 303–321 (2022)
2022
-
[48]
In: ECCV
Xie, X., Li, Y., Liu, Y., Zhang, Z., Wang, Z., Xiong, W., Bai, X.: Was: Dataset and methods for artistic text segmentation. In: ECCV. pp. 237–254 (2024)
2024
-
[49]
In: CVPR
Xu,J.,Wang,Y.,Xie,H.,Zhang,Y.:Ote:Exploringaccuratescenetextrecognition using one token. In: CVPR. pp. 28327–28336 (2024)
2024
-
[50]
In: CVPR
Xu, X., Zhang, Z., Wang, Z., Price, B., Wang, Z., Shi, H.: Rethinking text segmen- tation: A novel dataset and a text-specific refinement approach. In: CVPR. pp. 12045–12055 (2021)
2021
-
[51]
In: ICCV
Ye, X., Du, Y., Tao, Y., Chen, Z.: Textssr: Diffusion-based data synthesis for scene text recognition. In: ICCV. pp. 17464–17473 (2025)
2025
-
[52]
In: CVPR
Ye, X., Du, Y., Zhang, J., Li, C., LYU, J., Chen, Z.: What’s wrong with synthetic data for scene text recognition? a strong synthetic engine with diverse simulations and self-evolution. In: CVPR. pp. 16645–16654 (2026)
2026
-
[53]
In: ICDAR
Yim, M., Kim, Y., Cho, H.C., Park, S.: Synthtiger: Synthetic text image generator towards better text recognition models. In: ICDAR. pp. 109–124 (2021)
2021
-
[54]
In: CVPR
Yu, D., Li, X., Zhang, C., Liu, T., Han, J., Liu, J., Ding, E.: Towards accurate scene text recognition with semantic reasoning networks. In: CVPR. pp. 12113– 12122 (2020) 18 X. Ye et al
2020
-
[55]
In: CCPR
Zhai, C., Chen, Z., Li, J., Xu, B.: Chinese image text recognition with blstm-ctc: a segmentation-free method. In: CCPR. pp. 525–536 (2016)
2016
-
[56]
In: IJCAI
Zhang, B., Xie, H., Wang, Y., Xu, J., Zhang, Y.: Linguistic more: Taking a further step toward efficient and accurate scene text recognition. In: IJCAI. pp. 1704–1712 (2023)
2023
-
[57]
Zhu, Y., Liu, J., Gao, F., Liu, W., Wang, X., Wang, P., Huang, F., Yao, C., Yang, Z.: Visual text generation in the wild. In: ECCV. pp. 89–106 (2024) Appendix Fig. 1:Word cloud of artistic font tags used in WATER-T. A More Data Details A.1 Resources Used and Generated in WATER-S Artistic FontsWe first collect artistic font resources from open-source font ...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.