VisCritic: Visual State Comparison as Process Reward for GUI Agents
Pith reviewed 2026-06-26 00:49 UTC · model grok-4.3
The pith
Direct visual comparison of pre- and post-action screenshots verifies GUI agent actions and boosts benchmark performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
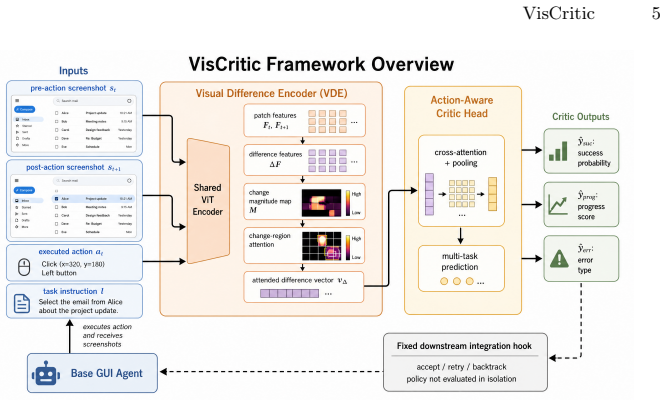
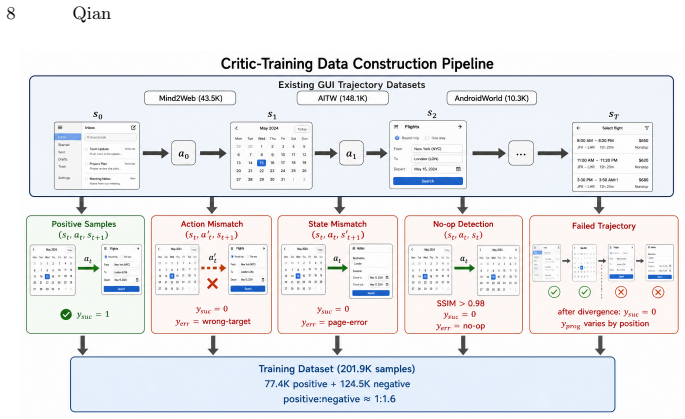
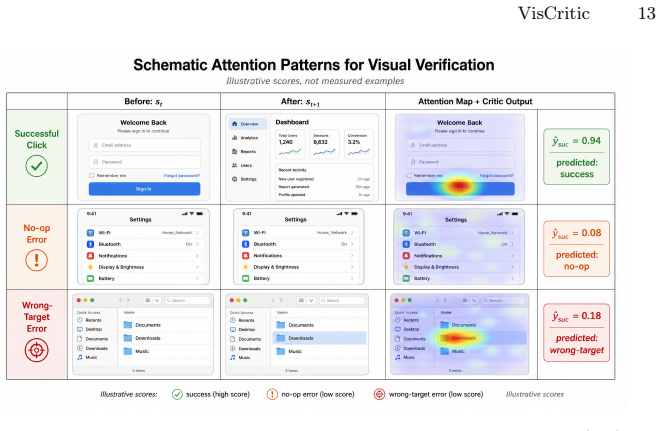
VisCritic is a visual process reward framework that verifies agent actions by directly comparing pre-action and post-action screenshots in visual feature space. It employs a Siamese vision transformer to extract change-aware representations, coupled with an Action-Aware Critic Head that jointly evaluates action success, task progress, and error type. A critic-training data construction pipeline generates weakly supervised samples from existing trajectories without additional human labels. Experiments across five benchmarks show it serves as a plug-and-play enhancement that generally improves metrics while providing visual diagnostic cues.
What carries the argument
Siamese vision transformer paired with an Action-Aware Critic Head that processes change-aware representations from before-and-after screenshots to assess action success, task progress, and error type.
If this is right
- Serves as a plug-and-play enhancement for diverse GUI agents.
- Generally improves benchmark metrics across the five tested benchmarks.
- Provides visual diagnostic cues alongside the reward signals.
- Trains using weakly supervised samples generated from existing trajectories without new human labels.
Where Pith is reading between the lines
- The visual approach could be combined with text-based rewards to create hybrid verification for agents that handle both visual and semantic errors.
- Similar before-and-after image comparison might extend to agent tasks in robotics or mobile apps where state changes are also visual.
- Agents trained with these visual rewards might handle longer sequences better by focusing on observable state transitions rather than inferred text descriptions.
Load-bearing premise
That direct visual feature comparison of screenshots can reliably verify action success, task progress, and error type without textual reasoning.
What would settle it
A test measuring whether VisCritic's visual scores match human judgments of action outcomes on held-out trajectories, or an ablation where removing the visual comparison eliminates the reported benchmark gains.
Figures

read the original abstract
GUI agents powered by vision-language models show strong potential for automating digital tasks, yet frequently fail in long-horizon scenarios due to the absence of step-level verification. Existing process reward models verify actions through textual reasoning alone, missing the visual nature of GUI state changes. We introduce VisCritic, a visual process reward framework that verifies agent actions by directly comparing pre-action and post-action screenshots in visual feature space. VisCritic employs a Siamese vision transformer to extract change-aware representations, coupled with an Action-Aware Critic Head that jointly evaluates action success, task progress, and error type. A critic-training data construction pipeline generates weakly supervised samples from existing trajectories without additional human labels for critic training. Experiments and offline analyses across five benchmarks demonstrate that VisCritic serves as a plug-and-play enhancement for diverse GUI agents, generally improving benchmark metrics while providing visual diagnostic cues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VisCritic, a visual process reward framework for GUI agents. It employs a Siamese vision transformer to extract change-aware representations by directly comparing pre- and post-action screenshots, paired with an Action-Aware Critic Head that jointly assesses action success, task progress, and error type. The model is trained via a weakly supervised data construction pipeline on existing trajectories without additional human labels, and the abstract reports that it acts as a plug-and-play enhancement improving metrics across five benchmarks while supplying visual diagnostic cues.
Significance. If the empirical claims hold after proper validation, the work could meaningfully extend process reward modeling for GUI agents by shifting from purely textual reasoning to direct visual state comparison, potentially improving reliability in long-horizon visual tasks where textual PRMs fall short.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: The manuscript asserts improvements across five benchmarks and offline analyses, yet supplies no information on experimental setup, chosen baselines, error bars, data splits, or statistical testing; this absence renders the central empirical claim unverifiable and load-bearing for the plug-and-play enhancement assertion.
- [Method] Method section (Siamese ViT + Action-Aware Critic Head): The design premise that visual feature comparison alone suffices to reliably verify action success, task progress, and error type without textual reasoning is central to the contribution, but the provided description offers no ablations or targeted validation demonstrating robustness against visual ambiguities common in GUI screenshots.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the five benchmarks and briefly indicated the magnitude of reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to improve clarity and completeness of the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The manuscript asserts improvements across five benchmarks and offline analyses, yet supplies no information on experimental setup, chosen baselines, error bars, data splits, or statistical testing; this absence renders the central empirical claim unverifiable and load-bearing for the plug-and-play enhancement assertion.
Authors: We acknowledge that the current presentation of experimental details is insufficient for full verifiability. While the manuscript references five benchmarks and describes the overall evaluation, it does not explicitly detail error bars, statistical testing procedures, precise data splits, or a consolidated list of baselines. We will revise the Experiments section to add a dedicated 'Experimental Setup' subsection that reports these elements, including any multi-run statistics and baseline specifications, to make the empirical claims transparent and reproducible. revision: yes
-
Referee: [Method] Method section (Siamese ViT + Action-Aware Critic Head): The design premise that visual feature comparison alone suffices to reliably verify action success, task progress, and error type without textual reasoning is central to the contribution, but the provided description offers no ablations or targeted validation demonstrating robustness against visual ambiguities common in GUI screenshots.
Authors: The referee correctly notes the absence of ablations supporting the core design choice. The manuscript describes the Siamese ViT and Action-Aware Critic Head but does not include targeted experiments isolating the contribution of visual comparison or testing against common GUI ambiguities such as icon similarity or dynamic UI elements. We will add an ablation study subsection in the revised manuscript, including variants that remove the Siamese structure or introduce controlled visual perturbations, to demonstrate robustness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents VisCritic as a Siamese ViT-based visual comparator trained on weakly supervised trajectory data to produce process rewards. No load-bearing step reduces by construction to its own inputs: the model architecture, data construction pipeline, and evaluation on external benchmarks are described as independent supervised learning components without self-definitional equations, renamed fitted parameters presented as predictions, or uniqueness claims imported solely via self-citation. The central claim of plug-and-play improvement rests on empirical results rather than tautological re-derivation of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ECCV Workshops (2016)
Bertinetto, L., Valmadre, J., Henriques, J.F., Vedaldi, A., Torr, P.H.S.: Fully- convolutional siamese networks for object tracking. In: ECCV Workshops (2016)
2016
-
[2]
arXiv preprint arXiv:2601.04035 (2026)
Cao, Y., Zhong, Y., Zeng, Z., Zheng, L., Huang, J., Qiu, H., Shi, P., Mao, W., Wan Guanglu: MobileDreamer: Generative sketch world model for GUI agent. arXiv preprint arXiv:2601.04035 (2026)
arXiv 2026
-
[3]
In: NeurIPS (2025)
Chae, H., Kim, S., Cho, J., Kim, S., Moon, S., Hwangbo, G., Lim, D., Kim, M., Hwang, Y., Gwak, M., Choi, D., Kang, M., Im, G., Cho, B., Kim, H., Han, J., Kwon, T., Kim, M., Kwak, B.w., Kang, D., Yeo, J.: Web-Shepherd: Advancing PRMs for reinforcing web agents. In: NeurIPS (2025)
2025
-
[4]
arXiv preprint arXiv:2509.23738 (2025)
Chen, C., Ji, K., Zhong, H., Zhu, M., Li, A., Gan, G., Huang, Z., Zou, C., Liu, J., Chen, J., Chen, H., Shen, C.: GUI-Shepherd: Reliable process reward and verifica- tion for long-sequence GUI tasks. arXiv preprint arXiv:2509.23738 (2025)
arXiv 2025
-
[5]
In: ICML (2020)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: ICML (2020)
2020
-
[6]
arXiv preprint arXiv:2412.05271 (2024)
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., Gu, L., Wang, X., Li, Q., Ren, Y., Chen, Z., Luo, J., Wang, J., Jiang, T., Wang, B., He, C., Shi, B., Zhang, X., Lv, H., Wang, Y., Shao, W., Chu, P., Tu, Z., He, T., Wu, Z., Deng, H., Ge, J., Chen, K., Zhang, K., Wang, L., Dou, M., Lu, L., Zhu, X., Lu, T., Lin, D.,...
Pith/arXiv arXiv 2024
-
[7]
In: ACL (2024)
Cheng, K., Sun, Q., Chu, Y., Xu, F., YanTao, L., Zhang, J., Wu, Z.: SeeClick: Harnessing GUI grounding for advanced visual GUI agents. In: ACL (2024)
2024
-
[8]
In: IEEE International Conference on Image Processing (ICIP) (2018)
Daudt, R.C., Saux, B.L., Boulch, A.: Fully convolutional siamese networks for change detection. In: IEEE International Conference on Image Processing (ICIP) (2018)
2018
-
[9]
In: NeurIPS (2023)
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2Web: Towards a generalist agent for the web. In: NeurIPS (2023)
2023
-
[10]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[11]
arXiv preprint arXiv:2602.07787 (2026) 16 Qian
Favreau, P.L., Lo, J.P., Guiguet, C., Simon-Meunier, C., Dehandschoewercker, N., Roush, A.G., Goldfeder, J., Shwartz-Ziv, R.: Do multi-agents dream of electric screens? achieving perfect accuracy on AndroidWorld through task decomposition. arXiv preprint arXiv:2602.07787 (2026) 16 Qian
arXiv 2026
-
[12]
In: ICLR (2025)
Gou, B., Wang, R., Zheng, B., Xie, Y., Chang, C., Shu, Y., Sun, H., Su, Y.: Navigating the digital world as humans do: Universal visual grounding for GUI agents. In: ICLR (2025)
2025
-
[13]
arXiv preprint arXiv:2602.17365 (2026)
Guan, Y., Yu, R., Zhang, J., Wang, L., Zhang, C., Li, L., Qiao, B., Qin, S., Huang, H., Yang, F., Zhao, P., Wutschitz, L., Kessler, S., Inan, H.A., Sim, R., Rajmohan, S., Lin, Q., Zhang, D.: Computer-using world model. arXiv preprint arXiv:2602.17365 (2026)
arXiv 2026
-
[14]
In: ICLR (2024)
Gur, I., Furuta, H., Huang, A., Safdari, M., Matsuo, Y., Eck, D., Faust, A.: A real-world WebAgent with planning, long context understanding, and program synthesis. In: ICLR (2024)
2024
-
[15]
In: CVPR (2024)
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., Tang, J.: CogAgent: A visual language model for GUI agents. In: CVPR (2024)
2024
-
[16]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[17]
arXiv preprint arXiv:2504.16073 (2025)
Hu, Z., Xiong, S., Zhang, Y., Ng, S.K., Luu, A.T., An, B., Yan, S., Hooi, B.: Guiding VLM agents with process rewards at inference time for GUI navigation. arXiv preprint arXiv:2504.16073 (2025)
arXiv 2025
-
[18]
In: CVPR (2018)
Kendall, A., Gal, Y., Cipolla, R.: Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In: CVPR (2018)
2018
-
[19]
Liao, Y.H., Mahmood, R., Fidler, S., Acuna, D.: Can large vision-language models correct semantic grounding errors by themselves? In: CVPR (2025)
2025
-
[20]
In: ICLR (2024)
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., Cobbe, K.: Let’s verify step by step. In: ICLR (2024)
2024
-
[21]
In: CVPR (2025)
Lin, K.Q., Li, L., Gao, D., Yang, Z., Wu, S., Bai, Z., Lei, S.W., Wang, L., Shou, M.Z.: ShowUI: One vision-language-action model for GUI visual agent. In: CVPR (2025)
2025
-
[22]
In: NeurIPS (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023)
2023
-
[23]
Nong, S., Tang, X., Xu, J., Zhou, S., Chen, J., Jiang, T., Xu, W.: CRAFT-GUI: Curriculum-reinforcedagentforGUItasks.arXivpreprintarXiv:2508.11360(2025)
arXiv 2025
-
[24]
arXiv preprint arXiv:1807.03748 (2018)
van den Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
Pith/arXiv arXiv 2018
-
[25]
arXiv preprint arXiv:2303.08774 (2023)
OpenAI: GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[26]
arXiv preprint arXiv:2604.16966 (2026)
Qian, J.: Visual inception: Compromising long-term planning in agentic rec- ommenders via multimodal memory poisoning. arXiv preprint arXiv:2604.16966 (2026)
Pith/arXiv arXiv 2026
-
[27]
arXiv preprint arXiv:2604.16515 (2026)
Qian, J., Kang, Z.: Penny wise, pixel foolish: Bypassing price constraints in multi- modal agents via visual adversarial perturbations. arXiv preprint arXiv:2604.16515 (2026)
Pith/arXiv arXiv 2026
-
[28]
arXiv preprint arXiv:2502.13923 (2025)
Qwen Team: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[29]
In: ICLR (2025)
Rawles, C., Clinckemaillie, S., Chang, Y., Waltz, J., Lau, G., Fair, M., Li, A., Bishop, W., Li, W., Campbell-Ajala, F., Toyama, D., Berry, R., Tyamagundlu, D., Lillicrap, T., Riva, O.: AndroidWorld: A dynamic benchmarking environment for autonomous agents. In: ICLR (2025)
2025
-
[30]
In: NeurIPS (2023)
Rawles, C., Li, A., Rodriguez, D., Riva, O., Lillicrap, T.: AndroidInTheWild: A large-scale dataset for android device control. In: NeurIPS (2023)
2023
-
[31]
Shi, W., Zhang, M., Zhang, R., Chen, S., Zhan, Z.: Change detection based on artificialintelligence:State-of-the-artandchallenges.RemoteSensing12(10), 1688 (2020) VisCritic 17
2020
-
[32]
arXiv preprint arXiv:2602.02995 (2026)
Tang, S., Chen, R., Lan, T.: Agent Alpha: Tree search unifying generation, explo- ration and evaluation for computer-use agents. arXiv preprint arXiv:2602.02995 (2026)
arXiv 2026
-
[33]
arXiv preprint arXiv:2401.16158 (2024)
Wang, J., Xu, H., Ye, J., Yan, M., Shen, W., Zhang, J., Huang, F., Sang, J.: Mobile- Agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158 (2024)
Pith/arXiv arXiv 2024
-
[34]
In: NeurIPS (2025)
Wanyan, Y., Zhang, X., Xu, H., Liu, H., Wang, J., Ye, J., Kou, Y., Yan, M., Huang, F., Yang, X., Dong, W., Xu, C.: Look before you leap: A GUI-critic-R1 model for pre-operative error diagnosis in GUI automation. In: NeurIPS (2025)
2025
-
[35]
In: EMNLP (2025)
Wu, Q., Gao, P., Liu, W., Luan, J.: BacktrackAgent: Enhancing GUI agent with error detection and backtracking mechanism. In: EMNLP (2025)
2025
-
[36]
In: NeurIPS (2024)
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V., Yu, T.: OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. In: NeurIPS (2024)
2024
-
[37]
arXiv preprint arXiv:2509.23263 (2025)
Xiong, T., Hu, X., Chen, Y., Liu, Y., Wu, C., Gao, P., Liu, W., Luan, J., Zhang, S.: GUI-PRA: Process reward agent for GUI tasks. arXiv preprint arXiv:2509.23263 (2025)
arXiv 2025
-
[38]
arXiv preprint arXiv:2510.09577 (2025)
Yu, X., Peng, B., Galley, M., Cheng, H., Wu, Q., Kulkarni, J., Nath, S., Yu, Z., Gao, J.: Dyna-Mind: Learning to simulate from experience for better AI agents. arXiv preprint arXiv:2510.09577 (2025)
arXiv 2025
-
[39]
In: NeurIPS (2025)
Yuan, X., Zhang, J., Li, K., Cai, Z., Yao, L., Chen, J., Wang, E., Hou, Q., Chen, J., Jiang, P.T., Li, B.: SE-GUI: Enhancing visual grounding for GUI agents via self-evolutionary reinforcement learning. In: NeurIPS (2025)
2025
-
[40]
In: ICCV (2023)
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. In: ICCV (2023)
2023
-
[41]
Zhang, C., Yang, Z., Liu, J., Li, Y., Han, Y., Chen, X., Huang, Z., Fu, B., Yu, G.: AppAgent: Multimodal agents as smartphone users. In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (2025).https: //doi.org/10.1145/3706598.3713600
-
[42]
arXiv preprint arXiv:2602.11524 (2026)
Zheng, C., Mo, X., Ma, X., Lin, Q., Zhao, Y., Zhu, J., Lou, X., Wang, J., Wang, Z., Liu, W., Zhang, Z., Yu, Y., Zhang, W.: Adaptive milestone reward for GUI agents. arXiv preprint arXiv:2602.11524 (2026)
arXiv 2026
-
[43]
In: ICML (2024)
Zhou, A., Yan, K., Shlapentokh-Rothman, M., Wang, H., Wang, Y.X.: Language agent tree search unifies reasoning, acting, and planning in language models. In: ICML (2024)
2024
-
[44]
In: ICLR (2024)
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U., Neubig, G.: WebArena: A realistic web environment for building autonomous agents. In: ICLR (2024)
2024
-
[45]
In: NeurIPS (2025)
Zhou, Y., Dai, S., Wang, S., Zhou, K., Jia, Q., Xu, J.: GUI-G1: Understanding R1-zero-like training for visual grounding in GUI agents. In: NeurIPS (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.