PointVG-R: Internalizing Geometric Reasoning in MLLMs for Precise Pointing Localization via Visual Chain of Thought
Pith reviewed 2026-06-26 00:43 UTC · model grok-4.3
The pith
PointVG-R internalizes geometric reasoning in MLLMs for precise pointing-based visual grounding via visual chain-of-thought trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
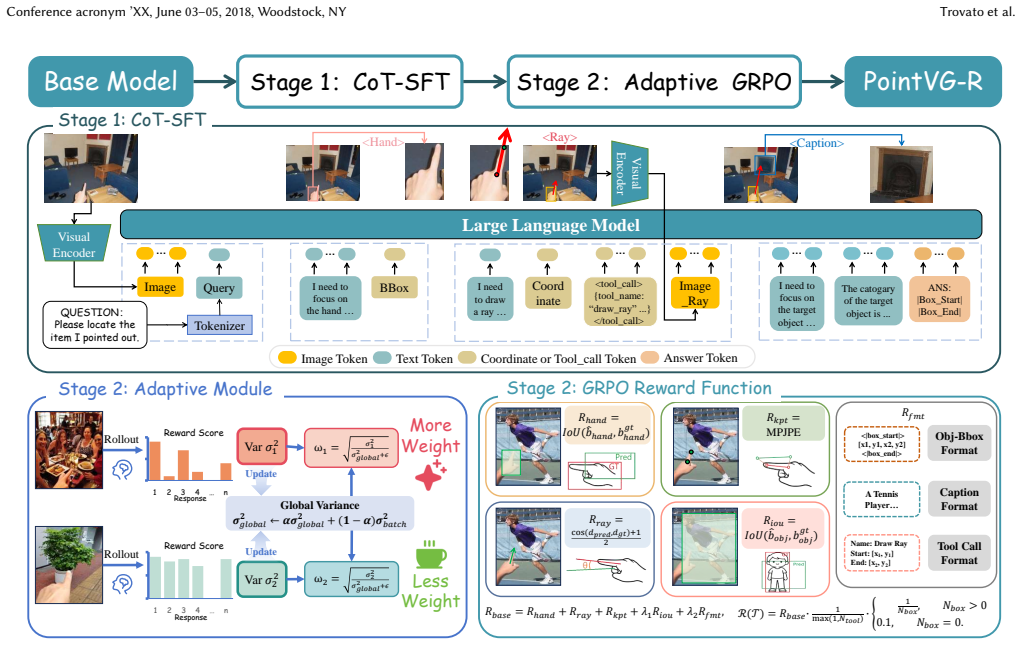
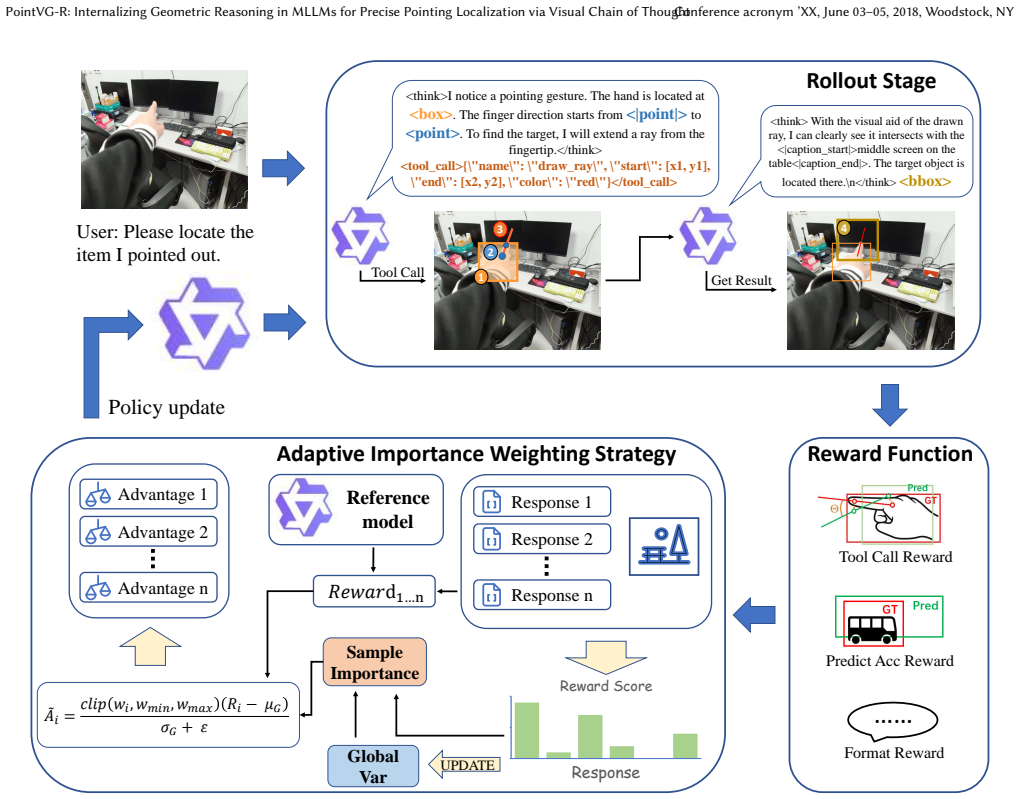
PointVG-R introduces a geometric reasoning pipeline that simulates the iterative cognitive process humans employ when interpreting pointing gestures, together with the EgoPoint-CoT dataset of detailed visual chain-of-thought trajectories, trained first by supervised fine-tuning and then by reinforcement learning, with an Adaptive Importance Weighting strategy based on Group Variance to handle varying signal quality; this combination produces state-of-the-art performance, outperforming the baseline by 15.86 points in mIoU.
What carries the argument
The geometric reasoning pipeline that enables the model to think with images by generating and following visual chain-of-thought trajectories for pointing gestures.
If this is right
- The model outperforms prior methods by 15.86 mIoU points on pointing localization tasks.
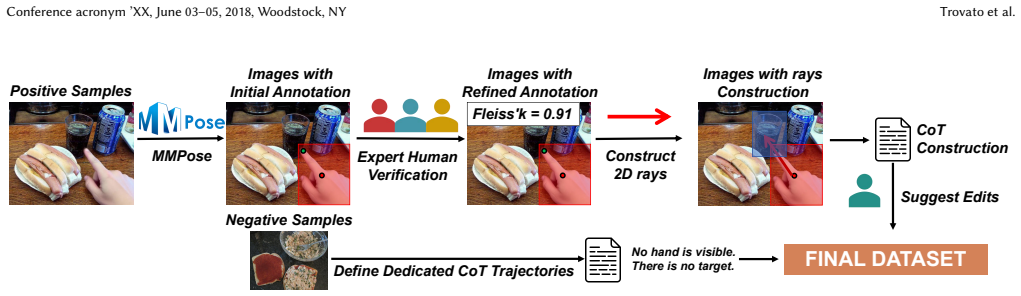
- The EgoPoint-CoT dataset supplies high-quality visual trajectories that guide both supervised fine-tuning and reinforcement learning stages.
- Adaptive Importance Weighting based on Group Variance dynamically scales reward signals to improve training efficiency.
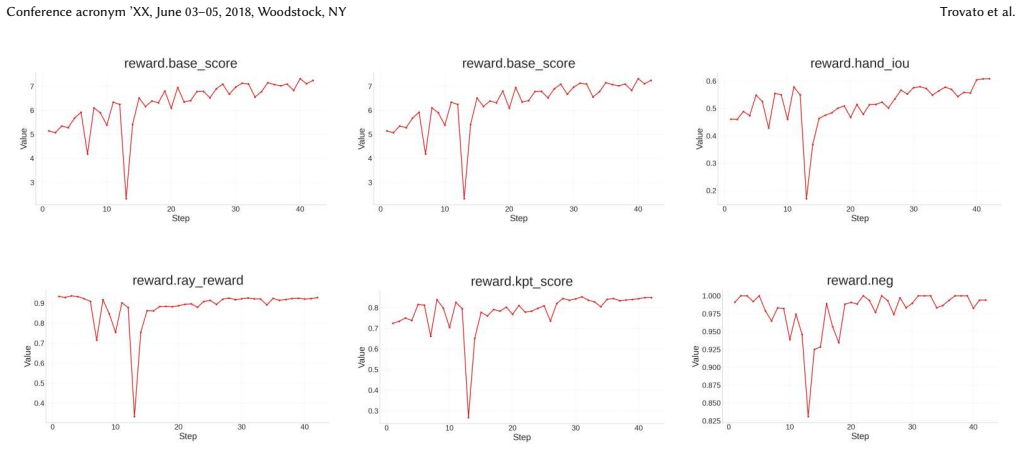
- Ablation studies confirm that each proposed component contributes measurably to the final performance gain.
Where Pith is reading between the lines
- The same visual chain-of-thought construction could be adapted to other spatial tasks such as referring expression comprehension or visual navigation.
- If the internalized geometric steps transfer, models might require fewer explicit language descriptions of spatial relations in future multimodal systems.
- Real-world deployment in gesture-controlled interfaces would become more reliable once the pipeline is shown to work on live camera feeds rather than static images.
Load-bearing premise
The geometric reasoning pipeline together with the EgoPoint-CoT trajectories will successfully internalize geometric understanding inside the MLLM when the model is trained by supervised fine-tuning and reinforcement learning.
What would settle it
An experiment in which models trained without the geometric reasoning pipeline or without the EgoPoint-CoT dataset achieve mIoU scores statistically indistinguishable from the baseline on the same pointing-based grounding benchmarks.
Figures





read the original abstract
Pointing-based visual grounding requires models to precisely locate target objects by deciphering complex spatial relationships between the visual scene and pointing gestures. Traditional methods typically encode input images into static feature representations and perform reasoning primarily within the linguistic domain, often overlooking the rich perceptual cues and explicit spatial geometry inherent in images. In this study, we aim to mitigate the cognitive vulnerability of models in interpreting gestural spatial relations by proposing PointVG-R, a reasoning-guided Multi-modal Large Language Model (MLLM). PointVG-R introduces geometric-aware reasoning for pointing-based grounding, enabling the model to think with images through the strategic integration of Reinforcement Learning (RL) and cold-start data. Specifically, we design a novel geometric reasoning pipeline that simulates the iterative cognitive process humans employ when interpreting pointing gestures. Furthermore, we construct EgoPoint-CoT, a high-quality visual Chain-of-Thought (CoT) dataset featuring detailed reasoning trajectories to guide the model via Supervised Fine-Tuning (SFT) and RL. To address the varying quality of learning signals encountered during training, we further propose an Adaptive Importance Weighting strategy based on Group Variance, which dynamically adjusts reward signals to optimize the learning process. Experimental results demonstrate that PointVG-R achieves SOTA performance, outperforming the baseline by $\textbf{15.86}$ points in mIoU. Extensive ablation studies further validate the efficacy of our proposed modules. Code: https://github.com/lingli1724/PointVG-R.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PointVG-R, a reasoning-guided MLLM for pointing-based visual grounding. It introduces a geometric reasoning pipeline simulating human iterative cognitive processes for interpreting pointing gestures, constructs the EgoPoint-CoT visual Chain-of-Thought dataset with detailed reasoning trajectories for training via SFT and RL, and proposes an Adaptive Importance Weighting strategy based on Group Variance to handle varying quality of learning signals. Experimental results claim SOTA performance with a 15.86 mIoU improvement over the baseline, supported by ablation studies validating the proposed modules.
Significance. If the performance gains and internalization of geometric reasoning are rigorously validated through detailed trajectory analysis and controls, this could meaningfully advance multimodal models by improving their handling of spatial relations in gestural inputs, a persistent weakness in current MLLMs. The combination of visual CoT, RL, and adaptive weighting represents a targeted approach to perceptual reasoning that, if substantiated, would be of interest to the CV and multimodal communities.
major comments (1)
- [Abstract] Abstract: The central claim attributes the 15.86 mIoU SOTA gain specifically to the geometric reasoning pipeline, EgoPoint-CoT trajectories, and Adaptive Importance Weighting enabling internalization of geometric understanding. However, the abstract supplies no information on trajectory generation (human vs. synthetic), correctness validation, coverage of pointing variations, or differentiation from standard visual CoT, which is load-bearing for distinguishing true geometric internalization from data-volume or memorization effects.
minor comments (1)
- [Abstract] The abstract refers to 'extensive ablation studies' validating the modules but provides no quantitative summary of key ablation results (e.g., contribution of each component to the mIoU gain).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the 15.86 mIoU SOTA gain specifically to the geometric reasoning pipeline, EgoPoint-CoT trajectories, and Adaptive Importance Weighting enabling internalization of geometric understanding. However, the abstract supplies no information on trajectory generation (human vs. synthetic), correctness validation, coverage of pointing variations, or differentiation from standard visual CoT, which is load-bearing for distinguishing true geometric internalization from data-volume or memorization effects.
Authors: We agree that the abstract should be self-contained to better support the central claim. While the manuscript body details the synthetic generation of EgoPoint-CoT trajectories (via geometric simulation) with human verification for correctness, their coverage of pointing variations, and differentiation from standard visual CoT through explicit iterative geometric steps, we will revise the abstract to concisely include these elements. This will help clarify how the reported gains reflect internalized geometric reasoning. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an empirical architecture (PointVG-R) with a geometric reasoning pipeline, a new dataset (EgoPoint-CoT) of visual CoT trajectories, and an Adaptive Importance Weighting strategy based on group variance. Performance gains (15.86 mIoU) are reported from SFT+RL training and ablations. No equations, fitted parameters presented as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or description. Claims rest on experimental results rather than derivations that reduce to inputs by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. 2025. LLaVA- OneVision-1.5: Fully Open Framework for Democratized Multimodal Training. arXiv preprint arXiv:2509.23661(2025)
Pith/arXiv arXiv 2025
-
[2]
Dhruv Anand and Ehsan Shareghi. 2025. Cube Bench: A Benchmark for Spatial Visual Reasoning in MLLMs.arXiv preprint arXiv:2512.20595(2025)
arXiv 2025
-
[3]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünder- hauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and- Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3674–3683
2018
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. 2025. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631(2025)
Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yi- heng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical R...
Pith/arXiv arXiv 2025
-
[6]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. 2025. UniVG-R1: Reasoning Guided Universal Visual Grounding with Reinforcement Learning.arXiv preprint arXiv:2505.14231(2025)
arXiv 2025
-
[7]
Siddhant Bansal, Chetan Arora, and CV Jawahar. 2022. My View is the Best View: Procedure Learning from Egocentric Videos. InProceedings of the European Conference on Computer Vision. 657–675
2022
-
[8]
Ian Berlot-Attwell. 2021. Neuro-Symbolic VQA: A Review from the Perspective of AGI Desiderata.arXiv preprint arXiv:2104.06365(2021)
arXiv 2021
-
[10]
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. 2024. The Revolu- tion of Multimodal Large Language Models: A Survey.Findings of the Association for Computational Linguistics: ACL 2024(2024), 13590–13618
2024
-
[11]
Jie Cao and Jing Xiao. 2022. An Augmented Benchmark Dataset for Geometric Question Answering through Dual Parallel Text Encoding. InProceedings of the International Conference on Computational Linguistics. 1511–1520
2022
-
[12]
Himanshu Chandel and Sonia Vatta. 2015. Occlusion Detection and Handling: A Review.International Journal of Computer Applications(2015), 33–38
2015
-
[13]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14455–14465
2024
-
[14]
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. 2025. Towards Rea- soning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models.arXiv preprint arXiv:2503.09567(2025)
Pith/arXiv arXiv 2025
-
[15]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2022. Pro- gram of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks.arXiv preprint arXiv:2211.12588(2022)
Pith/arXiv arXiv 2022
-
[16]
Yixin Chen, Qing Li, Deqian Kong, Yik Lun Kei, Song-Chun Zhu, Tao Gao, Yixin Zhu, and Siyuan Huang. 2021. YouRefIt: Embodied Reference Understand- ing with Language and Gesture. InProceedings of the IEEE/CVF International Conference on Computer Vision. 1385–1395
2021
-
[17]
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. 2024. YOLO-World: Real-Time Open-Vocabulary Object Detection. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16901–16911
2024
-
[18]
MMPose Contributors. 2020. OpenMMLab Pose Estimation Toolbox and Bench- mark. https://github.com/open-mmlab/mmpose
2020
-
[19]
Peng Cui, Guande He, Dan Zhang, Zhijie Deng, Yinpeng Dong, and Jun Zhu
-
[20]
Exploring Aleatoric Uncertainty in Object Detection via Vision Foundation Models.arXiv preprint arXiv:2411.17767(2024)
arXiv 2024
-
[21]
Ming Dai, Lingfeng Yang, Yihao Xu, Zhenhua Feng, and Wankou Yang. 2024. SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion. InProceedings of the Advances in Neural Information Processing Systems. 121670–121698
2024
-
[22]
Ahmad Darkhalil, Rhodri Guerrier, Adam W Harley, and Dima Damen. 2025. EgoPoints: Advancing Point Tracking for Egocentric Videos. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 8556–8565
2025
-
[23]
Anna Deichler and Jonas Beskow. 2025. Look and Tell: A Dataset for Mul- timodal Grounding Across Egocentric and Exocentric Views.arXiv preprint Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. arXiv:2510.22672(2025)
arXiv 2025
-
[24]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. 2022. Ego4D: Around the World in 3,000 Hours of Egocentric Video. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18995–19012
2022
-
[26]
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. 2024. Ego-Exo4D: Understanding Skilled Human Activ- ity from First- and Third-Person Perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. ...
2024
-
[27]
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. 2025. Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains.arXiv preprint arXiv:2507.17746(2025)
Pith/arXiv arXiv 2025
-
[28]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948(2025)
Pith/arXiv arXiv 2025
-
[29]
Hao Guo, Jianfei Zhu, Wei Fan, Chunzhi Yi, and Feng Jiang. 2025. Beyond Object Categories: Multi-Attribute Reference Understanding for Visual Grounding. arXiv preprint arXiv:2503.19240(2025)
arXiv 2025
-
[30]
Keyu Guo, Yongle Huang, Tinglei Jia, Xiangyu Song, Shijie Sun, Hongkai Wei, Xian-Feng Han, Shuwen Huang, Nicola Strisciuglio, and Shuyan Li. 2025. Visual Grounding in 2D and 3D: A Unified Perspective and Survey.Information Fusion (2025), 103625
2025
-
[31]
Tanmay Gupta and Aniruddha Kembhavi. 2023. Visual Programming: Com- positional Visual Reasoning Without Training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14953–14962
2023
-
[32]
Abdirahman Osman Hashi, Siti Zaiton Mohd Hashim, and Azurah Bte Asamah
-
[33]
A Systematic Review of Hand Gesture Recognition: An Update from 2018 to 2024.IEEE Access(2024), 143599–143626
2018
-
[34]
Ruozhen He, Paola Cascante-Bonilla, Ziyan Yang, Alexander C Berg, and Vicente Ordonez. 2024. Improved Visual Grounding through Self-Consistent Explana- tions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13095–13105
2024
-
[35]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. LoRA: Low-Rank Adaptation of Large Language Models.ICLR(2022), 3
2022
-
[36]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al
-
[37]
OpenAI o1 System Card.arXiv preprint arXiv:2412.16720(2024)
Pith/arXiv arXiv 2024
-
[38]
Xinyi Jiang, Guoming Wang, Huanhuan Li, Qinghua Xia, Rongxing Lu, and Siliang Tang. 2024. TALON: Improving Large Language Model Cognition with Tactility-Vision Fusion. InProceedings of the IEEE International Conference on Industrial Electronics and Applications. 1–6
2024
-
[39]
Zhengbo Jiao, Shaobo Wang, Zifan Zhang, Wei Wang, Bing Zhao, Hu Wei, and Linfeng Zhang. 2026. Credit Where It is Due: Cross-Modality Connectivity Drives Precise Reinforcement Learning for MLLM Reasoning.arXiv preprint arXiv:2602.11455(2026)
arXiv 2026
-
[40]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large Language Models are Zero-Shot Reasoners.Advances in Neural Information Processing Systems(2022), 22199–22213
2022
-
[41]
Solomon Kullback and Richard A Leibler. 1951. On Information and Sufficiency. The Annals of Mathematical Statistics(1951), 79–86
1951
-
[42]
Hanyu Lai, Xiao Liu, Junjie Gao, Jiale Cheng, Zehan Qi, Yifan Xu, Shuntian Yao, Dan Zhang, Jinhua Du, Zhenyu Hou, et al . 2025. A Survey of Post-Training Scaling in Large Language Models. InProceedings of the Meeting of the Association for Computational Linguistics. 2771–2791
2025
-
[43]
Matthias Lehmann. 2024. The Definitive Guide to Policy Gradients in Deep Reinforcement Learning: Theory, Algorithms and Implementations.arXiv preprint arXiv:2401.13662(2024)
arXiv 2024
-
[44]
Chengzu Li, Wenshan Wu, Huanyu Zhang, Qingtao Li, Zeyu Gao, Yan Xia, José Hernández-Orallo, Ivan Vulić, and Furu Wei. 2025. 11PLUS-BENCH: Demys- tifying Multimodal LLM Spatial Reasoning with Cognitive-Inspired Analysis. arXiv preprint arXiv:2508.20068(2025)
arXiv 2025
-
[45]
F Li, DC Hogg, and AG Cohn. 2024. Reframing Spatial Reasoning Evaluation in Language Models: A Real-World Simulation Benchmark for Qualitative Reason- ing. InProceedings of the International Joint Conference on Artificial Intelligence. 6342–6349
2024
-
[46]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. InProceedings of the International Conference on Machine Learning. 12888–12900
2022
-
[47]
Linjie Li, Mahtab Bigverdi, Jiawei Gu, Zixian Ma, Yinuo Yang, Ziang Li, Yejin Choi, and Ranjay Krishna. 2025. Unfolding Spatial Cognition: Evaluating Multi- modal Models on Visual Simulations.arXiv preprint arXiv:2506.04633(2025)
arXiv 2025
-
[48]
Ling Li, Bowen Liu, Zinuo Zhan, Peng Jie, Jianhui Zhong, Kenglun Chang, and Zhidong Deng. 2026. Beyond Language: Grounding Referring Expressions with Hand Pointing in Egocentric Vision. arXiv:2603.26646 [cs.CV] https: //arxiv.org/abs/2603.26646
arXiv 2026
-
[49]
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al
-
[50]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grounded Language-Image Pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10965–10975
-
[51]
Rang Li, Lei Li, Shuhuai Ren, Hao Tian, Shuhao Gu, Shicheng Li, Zihao Yue, Yudong Wang, Wenhan Ma, Zhe Yang, et al. 2025. GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation.arXiv preprint arXiv:2512.17495(2025)
arXiv 2025
-
[52]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft COCO: Com- mon Objects in Context. InProceedings of the European Conference on Computer Vision. 740–755
2014
-
[53]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved Base- lines with Visual Instruction Tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26296–26306
2024
-
[54]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. LLaVA-NeXT: Improved Reasoning, OCR, and World Knowledge
2024
-
[56]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction Tuning.Advances in Neural Information Processing Systems(2023), 34892–34916
2023
-
[57]
Jingping Liu, Ziyan Liu, Zhedong Cen, Yan Zhou, Yinan Zou, Weiyan Zhang, Haiyun Jiang, and Tong Ruan. 2025. Can Multimodal Large Language Models Understand Spatial Relations?. InProceedings of the Meeting of the Association for Computational Linguistics. 620–632
2025
-
[58]
Shi Liu, Weijie Su, Xizhou Zhu, Wenhai Wang, and Jifeng Dai. 2025. CoMemo: LVLMs Need Image Context with Image Memory. InProceedings of the Interna- tional Conference on Machine Learning. 39535–39551
2025
-
[59]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al . 2024. Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection. In Proceedings of the European Conference on Computer Vision. 38–55
2024
-
[60]
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. 2025. Visual-RFT: Visual Reinforcement Fine-Tuning. arXiv preprint arXiv:2503.01785(2025)
Pith/arXiv arXiv 2025
-
[61]
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Ha- jishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. 2023. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts.arXiv preprint arXiv:2310.02255(2023)
Pith/arXiv arXiv 2023
-
[62]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. Advances in Neural Information Processing Systems(2022), 2507–2521
2022
-
[63]
Yunze Man, De-An Huang, Guilin Liu, Shiwei Sheng, Shilong Liu, Liang-Yan Gui, Jan Kautz, Yu-Xiong Wang, and Zhiding Yu. 2025. Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought. InProceedings of the Computer Vision and Pattern Recognition Conference. 14268–14280
2025
-
[64]
Atharv Mahesh Mane, Dulanga Weerakoon, Vigneshwaran Subbaraju, Sougata Sen, Sanjay E Sarma, and Archan Misra. 2025. Ges3ViG: Incorporating Pointing Gestures into Language-Based 3D Visual Grounding for Embodied Reference Understanding. InProceedings of the Computer Vision and Pattern Recognition Conference. 9017–9026
2025
-
[65]
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. 2016. Generation and Comprehension of Unambiguous Object Descriptions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 11–20
2016
-
[66]
Ibomoiye Domor Mienye, Ebenezer Esenogho, and Cameron Modisane. 2026. Deep Reinforcement Learning in the Era of Foundation Models: A Survey. Computers(2026), 40
2026
-
[67]
Varun K Nagaraja, Vlad I Morariu, and Larry S Davis. 2016. Modeling Context between Objects for Referring Expression Understanding. InProceedings of the European Conference on Computer Vision. 792–807
2016
-
[68]
Minheng Ni, Yutao Fan, Lei Zhang, and Wangmeng Zuo. 2024. Visual-O1: Understanding Ambiguous Instructions via Multi-modal Multi-turn Chain-of- thoughts Reasoning.arXiv preprint arXiv:2410.03321(2024)
arXiv 2024
-
[69]
Noriki Nishida, Koji Inoue, Hideki Nakayama, Mayumi Bono, and Katsuya Takanashi. 2025. Do Multimodal Large Language Models Truly See What We Point At? Investigating Indexical, Iconic, and Symbolic Gesture Comprehension. PointVG-R: Internalizing Geometric Reasoning in MLLMs for Precise Pointing Localization via Visual Chain of Thought Conference acronym ’X...
2025
-
[70]
Kent O’Sullivan, Nicole R Schneider, and Hanan Samet. 2024. Metric Reasoning in Large Language Models. InProceedings of the ACM International Conference on Advances in Geographic Information Systems. 501–504
2024
-
[71]
Cong Pang, Xuyu Feng, Yujie Yi, Zixuan Chen, Jiawei Hong, Tiankuo Yao, Nang Yuan, Jiapeng Luo, Lewei Lu, and Xin Lou. 2026. ICA: Information-Aware Credit Assignment for Visually Grounded Long-Horizon Information-Seeking Agents. arXiv preprint arXiv:2602.10863(2026)
arXiv 2026
-
[72]
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. 2023. EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision. 5285–5297
2023
-
[73]
Jiaxu Qian, Chendong Wang, Yifan Yang, Chaoyun Zhang, Huiqiang Jiang, Xufang Luo, Yu Kang, Qingwei Lin, Anlan Zhang, Shiqi Jiang, et al . 2025. Zoomer: Adaptive Image Focus Optimization for Black-box MLLM.arXiv preprint arXiv:2505.00742(2025)
arXiv 2025
-
[74]
Kevin Qu, Haozhe Qi, Mihai Dusmanu, Mahdi Rad, Rui Wang, and Marc Pollefeys
-
[75]
Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision- Language Models.arXiv preprint arXiv:2603.18002(2026)
arXiv 2026
-
[76]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. 2024. Visual CoT: Advancing Multi-Modal Language Models with a Comprehensive Dataset and Benchmark for Chain-of-Thought Reasoning.Advances in Neural Information Processing Systems(2024), 8612– 8642
2024
-
[77]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
Pith/arXiv arXiv 2024
-
[78]
Chuming Shen, Wei Wei, Xiaoye Qu, and Yu Cheng. 2025. SATORI-R1: In- centivizing Multimodal Reasoning through Explicit Visual Anchoring.arXiv preprint arXiv:2505.19094(2025)
arXiv 2025
-
[79]
Fatemeh Shiri, Xiao-Yu Guo, Mona Golestan Far, Xin Yu, Reza Haf, and Yuan- Fang Li. 2024. An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models. InProceedings of the Conference on Empirical Methods in Natural Language Processing. 21440–21455
2024
-
[80]
Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu. 2025. Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains.arXiv preprint arXiv:2503.23829(2025)
arXiv 2025
-
[81]
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. 2025. Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers.arXiv preprint arXiv:2506.23918(2025)
Pith/arXiv arXiv 2025
-
[82]
Dídac Surís, Sachit Menon, and Carl Vondrick. 2023. ViperGPT: Visual Inference via Python Execution for Reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 11888–11898
2023
-
[83]
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. 1999. Policy Gradient Methods for Reinforcement Learning with Function Approxi- mation.Advances in Neural Information Processing Systems(1999), 1–7
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.