SAFARI: Scaling Long Horizon Agentic Fault Attribution via Active Investigation
Pith reviewed 2026-06-25 23:30 UTC · model grok-4.3
The pith
SAFARI uses a tool-augmented diagnostic loop with segment search tools and persistent short-term memory to attribute faults in agent trajectories that exceed LLM context windows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
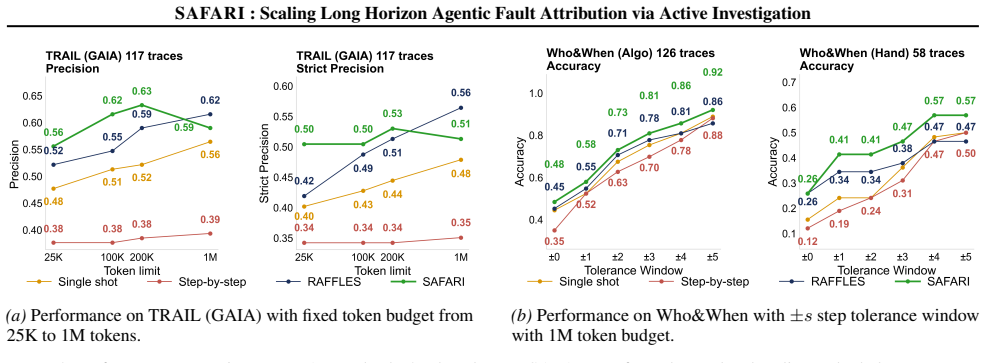
SAFARI replaces linear context loading with a tool-augmented diagnostic loop. By equipping LLMs with a specialized toolbox to read and search trajectory segments alongside a persistent Short-Term Memory for cross-turn reasoning, the framework decouples diagnostic accuracy from architectural context limits. Experiments show it outperforms prior results by 20 percent on the Who&When dataset inside a 1M token budget and by 19 percent on the TRAIL GAIA subset inside a 25K token budget, while still reaching 0.58 precision when the target fault lies 5 times beyond the model's native context window.
What carries the argument
The tool-augmented diagnostic loop that uses a toolbox for reading and searching trajectory segments together with persistent Short-Term Memory to investigate without full context loading.
If this is right
- Fault diagnosis accuracy becomes independent of whether the entire execution trace fits inside the model's context window.
- Performance on the Who&When benchmark rises by 20 percent inside a 1M token budget relative to earlier evaluators.
- Precision holds at 0.58 on faults located 5 times past the native context limit, a regime where full-trajectory methods return no usable result.
- On the TRAIL GAIA subset the same loop improves results by 19 percent inside a 25K token budget.
Where Pith is reading between the lines
- The same pattern of targeted segment access plus running memory could be tried on other long-sequence diagnostic problems such as program execution traces or multi-step scientific experiments.
- Systems that avoid loading full histories might lower the token cost of repeated agent evaluations even when context windows continue to grow.
- One could test whether the toolbox needs to be enlarged when the underlying agent itself uses multiple interacting models rather than a single one.
Load-bearing premise
A specialized toolbox for reading and searching trajectory segments plus a persistent short-term memory can preserve all information necessary for accurate fault attribution without the full trajectory in context.
What would settle it
A concrete test trajectory in which the decisive fault evidence sits in a segment the search tools never retrieve and the memory never retains, causing SAFARI to output an incorrect attribution while any method that loads the full trace succeeds.
Figures

read the original abstract
As autonomous agents tackle increasingly complex multi-step, multi-agent tasks, their execution trajectories have scaled beyond the constraints of even the largest context windows. Current methods for effectively diagnosing agent failures load the full trajectory into an LLM's context window, which suffers from attention dilution and fails when agentic traces inevitably exceed context limits. To address this, we introduce SAFARI (Scaling long-horizon Agentic Fault AttRibution via active Investigation), a framework that replaces linear context loading with a tool-augmented diagnostic loop. By equipping LLMs with a specialized toolbox to read and search trajectory segments alongside a persistent Short-Term Memory (STM) for cross-turn reasoning, SAFARI effectively decouples diagnostic accuracy from architectural context limits. Our experiments demonstrate that SAFARI outperforms state-of-the-art results by 20% on the Who&When dataset within a 1M token budget, and by 19% on TRAIL GAIA subset on a 25K token budget. Most significantly, SAFARI maintains a 0.58 precision even when the target fault resides 5x beyond the model's native context window, a scenario where traditional evaluators fail entirely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAFARI, a framework that replaces full-trajectory context loading with a tool-augmented diagnostic loop consisting of a specialized toolbox for reading and searching trajectory segments plus a persistent Short-Term Memory (STM). It claims this decouples diagnostic accuracy from LLM context limits, yielding 20% improvement over SOTA on the Who&When dataset (1M token budget), 19% on the TRAIL GAIA subset (25K token budget), and 0.58 precision when the target fault lies 5x beyond the native context window (where traditional evaluators fail entirely).
Significance. If the empirical results hold under rigorous verification, the work addresses a practical scalability barrier in diagnosing failures of complex multi-agent systems whose traces exceed current context windows, offering a concrete alternative to attention-dilution problems.
major comments (2)
- [Abstract] Abstract: the central performance claims (20% and 19% deltas, 0.58 precision at 5x context distance) are presented without any experimental protocol, baseline definitions, dataset statistics, or error analysis, so the comparisons cannot be assessed.
- [Abstract] Abstract: the claim that toolbox-guided search plus STM recovers all fault-relevant segments and cross-segment dependencies without information loss is load-bearing for the 5x-context result, yet the text supplies neither the search algorithm, the STM update rule, nor any completeness argument for arbitrary long-horizon traces.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's presentation of results and framework details. We address each comment below and will revise the abstract accordingly while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (20% and 19% deltas, 0.58 precision at 5x context distance) are presented without any experimental protocol, baseline definitions, dataset statistics, or error analysis, so the comparisons cannot be assessed.
Authors: We agree the abstract is too terse for full assessment of the claims. The full experimental protocol, baselines (SOTA methods), dataset statistics (Who&When at 1M tokens, TRAIL GAIA at 25K tokens), and error analysis appear in Section 4. In revision we will expand the abstract with a concise clause such as 'evaluated on Who&When (1M token budget) and TRAIL GAIA (25K token budget) against SOTA baselines' while keeping length constraints in mind. revision: yes
-
Referee: [Abstract] Abstract: the claim that toolbox-guided search plus STM recovers all fault-relevant segments and cross-segment dependencies without information loss is load-bearing for the 5x-context result, yet the text supplies neither the search algorithm, the STM update rule, nor any completeness argument for arbitrary long-horizon traces.
Authors: The abstract summarizes at a high level; the search algorithm, STM update rule, and supporting arguments for segment recovery are detailed in Section 3 (Methodology), including the toolbox design and persistent memory mechanics. We will revise the abstract to add a brief clause referencing the active investigation loop and Section 3, and to qualify the 'without information loss' phrasing as empirically supported rather than a universal guarantee. revision: yes
Circularity Check
No circularity; empirical results on external datasets
full rationale
The paper introduces the SAFARI framework and reports direct empirical performance numbers (20% and 19% outperformance, 0.58 precision at 5x context distance) on named external datasets (Who&When, TRAIL GAIA subset). No equations, fitted parameters, self-definitional quantities, or load-bearing self-citations appear in the provided claims. The results are presented as measured outcomes rather than quantities derived by construction from the method's own inputs or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Raffles: Reasoning-based attribution of faults for llm systems , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems , author=
-
[3]
arXiv preprint arXiv:2509.25370 , year=
Where llm agents fail and how they can learn from failures , author=. arXiv preprint arXiv:2509.25370 , year=
-
[4]
arXiv preprint arXiv:2505.08638 , year=
Trail: Trace reasoning and agentic issue localization , author=. arXiv preprint arXiv:2505.08638 , year=
-
[5]
arXiv preprint arXiv:2411.04468 , year=
Magentic-one: A generalist multi-agent system for solving complex tasks , author=. arXiv preprint arXiv:2411.04468 , year=
-
[6]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Assistantbench: Can web agents solve realistic and time-consuming tasks? , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[7]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[8]
arXiv preprint arXiv:2510.24699 , year=
AgentFold: Long-Horizon Web Agents with Proactive Context Management , author=. arXiv preprint arXiv:2510.24699 , year=
-
[9]
arXiv preprint arXiv:2510.27246 , year=
Beyond a million tokens: Benchmarking and enhancing long-term memory in llms , author=. arXiv preprint arXiv:2510.27246 , year=
-
[10]
arXiv preprint arXiv:2405.19425 , year=
Adaptive in-conversation team building for language model agents , author=. arXiv preprint arXiv:2405.19425 , year=
-
[11]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Interactive debugging and steering of multi-agent ai systems , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[12]
arXiv preprint arXiv:2509.24088 , year=
CORRECT: COndensed eRror RECognition via knowledge Transfer in multi-agent systems , author=. arXiv preprint arXiv:2509.24088 , year=
-
[13]
and Yang, Shuyi and Agrawal, Lakshya A
Cemri, Mert and Pan, Melissa Z. and Yang, Shuyi and Agrawal, Lakshya A. and Chopra, Bhavya and Tiwari, Rishabh and Keutzer, Kurt and Parameswaran, Aditya and Klein, Dan and Ramchandran, Kannan and Zaharia, Matei and Gonzalez, Joseph E. and Stoica, Ion , title =. arXiv preprint arXiv:2503.13657 , year =
-
[14]
arXiv preprint arXiv:2509.13782 , year =
Ge, Yu and Xie, Linna and Li, Zhong and Pei, Yu and Zhang, Tian , title =. arXiv preprint arXiv:2509.13782 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.