CineCap: Structured Reasoning with Spatio-Temporal Anchors for Cinematographic Video Captioning
Pith reviewed 2026-06-25 23:27 UTC · model grok-4.3
The pith
CineCap shows that structured reasoning over spatio-temporal anchors plus reinforcement learning rewards for comprehensiveness, accuracy, and gated coverage produces more complete and factually correct cinematographic video captions than pr
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
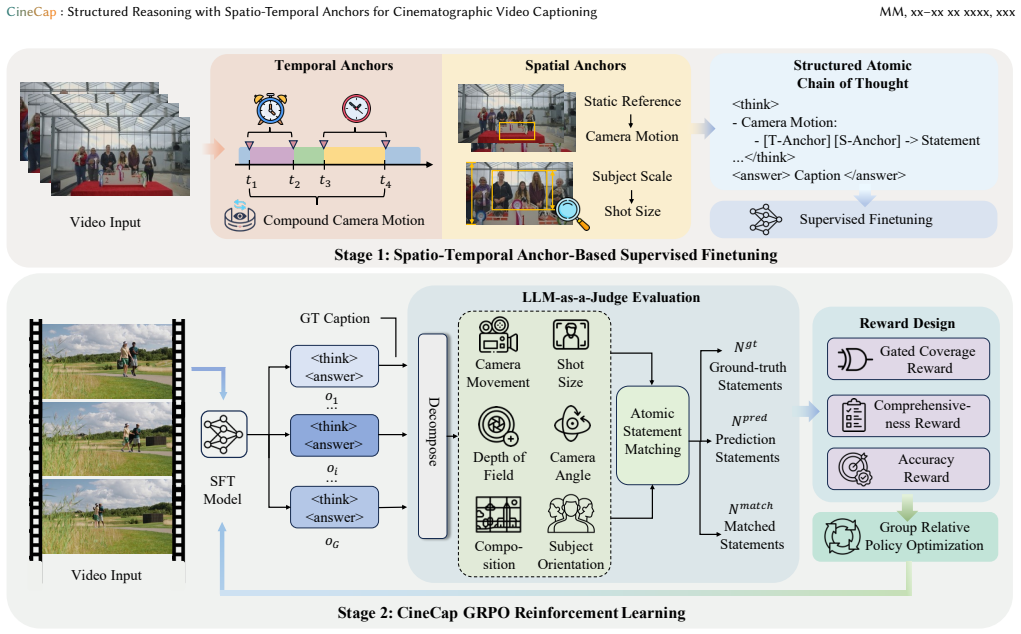
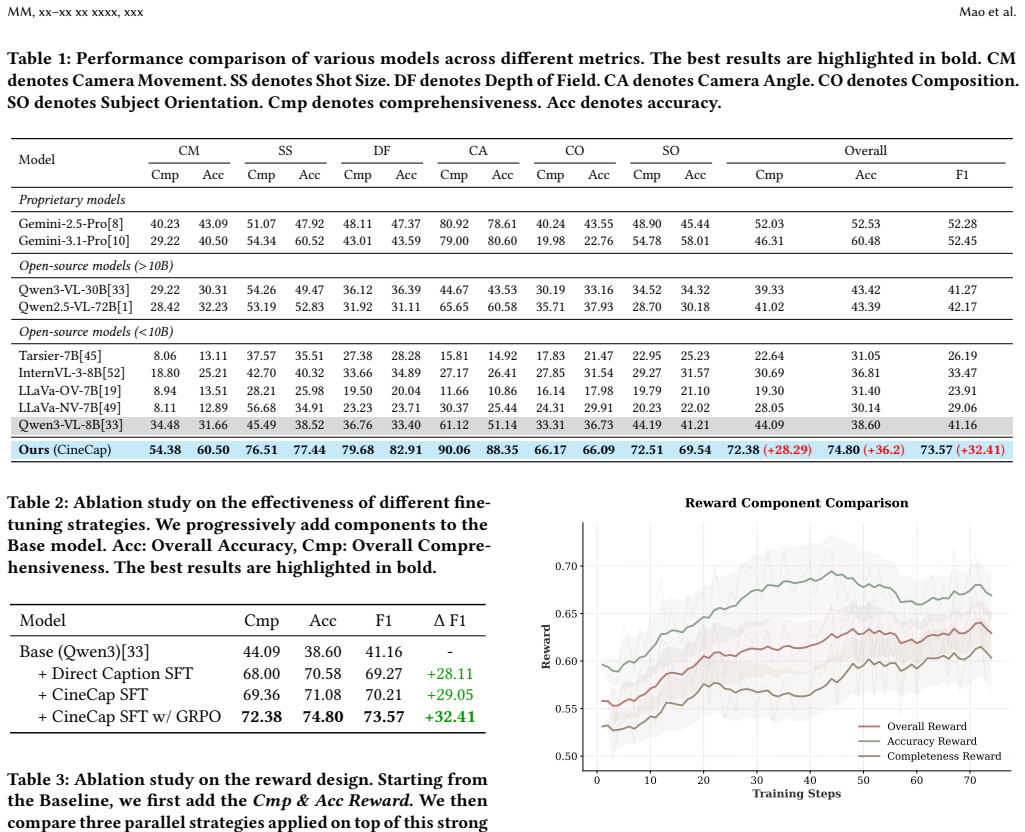
CineCap combines structured reasoning with spatio-temporal anchors, which grounds professional cinematographic descriptions in explicit visual evidence and organizes them into compact atomic reasoning for supervised fine-tuning, together with reinforcement learning that uses comprehensiveness, accuracy, and gated coverage rewards to improve the balance between descriptive completeness and factual correctness; on the CineCap Bench this yields captions that outperform strong baselines and establish a new state of the art.
What carries the argument
Structured reasoning with spatio-temporal anchors, which grounds professional cinematographic descriptions in explicit visual evidence and organizes them into compact atomic reasoning steps for fine-tuning.
If this is right
- Enables finer-grained video understanding expressed in professional film-language terms.
- Supports controllable movie-quality video generation that can follow explicit cinematographic instructions.
- Provides a reusable benchmark for systematic comparison of cinematographic captioning methods.
- Demonstrates that separating grounding from reward-driven refinement improves both coverage and correctness in open-form video descriptions.
Where Pith is reading between the lines
- The same anchor-plus-reward pattern could be tested on other professional-description tasks such as sports or medical video analysis.
- If the atomic reasoning steps prove reusable, they might reduce the need for large amounts of new human annotation when adapting to related captioning domains.
- The gated coverage reward offers a concrete mechanism for trading off detail against hallucination that might apply to other multimodal generation settings.
Load-bearing premise
The assumption that structured reasoning with spatio-temporal anchors combined with the specific reinforcement learning rewards will produce captions that are both comprehensive and factually correct on videos not seen during training.
What would settle it
Human expert ratings on a fresh set of unseen videos showing that CineCap captions score no higher than strong baseline models on combined measures of accuracy and completeness.
Figures

read the original abstract
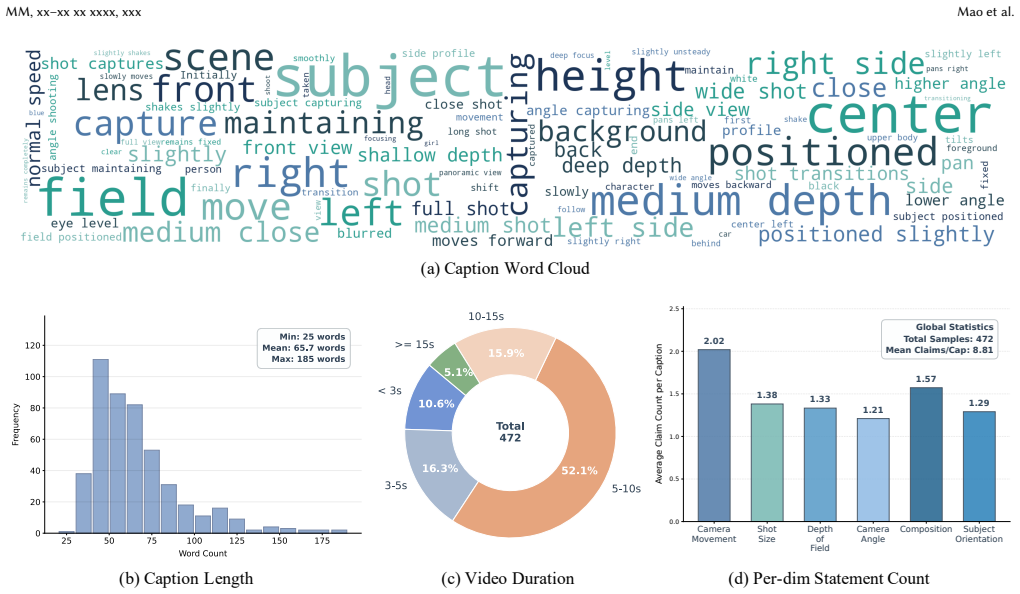
Cinematographic captioning aims to describe how a video is filmed using professional film-language concepts such as camera movement, shot size, depth of field, composition, and shooting angle. This capability is important for fine-grained video understanding and controllable movie-quality video generation, yet remains underexplored in existing multimodal large language models. Unlike question-answering-based evaluation of cinematic understanding, cinematographic captioning requires a unified open-form description over multiple cinematographic dimensions. This task is challenging for two main reasons: the model must infer professional cinematographic concepts from subtle visual evidence, and it must generate captions that are both comprehensive and accurate. Accordingly, we propose CineCap, a framework that combines structured reasoning with spatio-temporal anchors and reinforcement learning with comprehensiveness, accuracy, and gated coverage rewards. The former grounds professional cinematographic descriptions in explicit visual evidence and organizes them into compact atomic reasoning for supervised fine-tuning, while the latter improves the balance between descriptive completeness and factual correctness. In addition, we construct CineCap Bench, a benchmark of 472 manually annotated video-caption pairs for systematic evaluation. Extensive experiments show that CineCap consistently outperforms strong proprietary and open-source baselines, establishing a new state of the art for cinematographic captioning. The code, model checkpoint, and benchmark are publicly available in https://github.com/Hectormxy/CineCap.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce CineCap, a framework for cinematographic video captioning that integrates structured reasoning using spatio-temporal anchors for supervised fine-tuning and reinforcement learning with rewards for comprehensiveness, accuracy, and gated coverage. It also constructs the CineCap Bench benchmark consisting of 472 manually annotated video-caption pairs. The authors assert that extensive experiments demonstrate CineCap outperforming strong proprietary and open-source baselines, thereby establishing a new state of the art for the task.
Significance. If the empirical results hold, this work would be significant as it addresses an underexplored capability in multimodal large language models for describing professional cinematographic concepts from visual evidence. This has potential implications for fine-grained video understanding and controllable movie-quality video generation. The public release of code, model, and benchmark is a positive contribution to reproducibility.
major comments (1)
- [Abstract] Abstract: The claim that 'CineCap consistently outperforms strong proprietary and open-source baselines, establishing a new state of the art for cinematographic captioning' is presented without any quantitative results, specific metrics, error analysis, or details on the method implementation. This is load-bearing for the central claim, as the abstract provides no evidence to support the outperformance or the effectiveness of the structured reasoning and RL components in balancing completeness and factual correctness.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the single major comment below and indicate where a revision will be made.
read point-by-point responses
-
Referee: The claim that 'CineCap consistently outperforms strong proprietary and open-source baselines, establishing a new state of the art for cinematographic captioning' is presented without any quantitative results, specific metrics, error analysis, or details on the method implementation. This is load-bearing for the central claim, as the abstract provides no evidence to support the outperformance or the effectiveness of the structured reasoning and RL components in balancing completeness and factual correctness.
Authors: We agree that the abstract, as currently written, states the performance claim at a high level without accompanying metrics. While this is common practice to preserve brevity, the absence of any numerical support does make the claim harder to evaluate from the abstract alone. The full manuscript provides quantitative results, ablation studies on the structured-reasoning and RL components, and error analysis in Sections 4 and 5. To directly address the concern, we will revise the abstract to include the key performance deltas on CineCap Bench (and the primary metrics used) so that the central claim is supported by concrete evidence at the abstract level as well. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new framework (structured reasoning + spatio-temporal anchors + RL rewards for comprehensiveness/accuracy/gated coverage) and a new manually annotated benchmark (CineCap Bench, 472 pairs), then reports performance against external proprietary and open-source baselines. No derivation, equation, or central claim reduces by construction to a fitted input, self-definition, or self-citation chain; the evaluation is externally falsifiable via the public benchmark and code. This is the most common honest finding for a methods-plus-benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
Pith/arXiv arXiv 2025
-
[2]
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Yuanzhen Li, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, and Inbar Mosseri. 2024. Lumiere: A Space-Time Diffusion Model for Video Generation. InACM SIGGRAPH / ACM Multimedia conference (or relevant venue, see reference). https://arxiv.org/abs...
arXiv 2024
-
[3]
Digbalay Bose, Rajat Hebbar, Krishna Somandepalli, Haoyang Zhang, Yin Cui, Kree Cole-McLaughlin, Huisheng Wang, and Shrikanth Narayanan. 2023. Movieclip: Visual scene recognition in movies. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2083–2092
2023
-
[4]
2025.PySceneDetect
Brandon Castellano. 2025.PySceneDetect. https://github.com/Breakthrough/ PySceneDetect Python and OpenCV-based scene cut and transition detection library, accessed 2026-03-31
2025
-
[5]
Agneet Chatterjee, Rahim Entezari, Maksym Zhuravinskyi, Maksim Lapin, Reshinth Adithyan, Amit Raj, Chitta Baral, Yezhou Yang, and Varun Jampani
-
[6]
Stable Cinemetrics: Structured Taxonomy and Evaluation for Professional Video Generation.arXiv preprint arXiv:2509.26555(2025)
arXiv 2025
-
[7]
Xinlong Chen, Yue Ding, Weihong Lin, Jingyun Hua, Linli Yao, Yang Shi, Bozhou Li, Yuanxing Zhang, Qiang Liu, Pengfei Wan, et al. 2025. Avocado: An audiovisual video captioner driven by temporal orchestration.arXiv preprint arXiv:2510.10395 (2025)
arXiv 2025
-
[8]
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Benyou Wang, and Xiangyu Yue. 2025. Video-R1: Reinforcing Video Reasoning in MLLMs.arXiv preprint arXiv:2503.21776(2025)
Pith/arXiv arXiv 2025
-
[9]
Google DeepMind. 2025. Gemini 2.5 Pro Model Card. https://deepmind.google/ models/model-cards/. Accessed: 2026-04-02
2025
-
[10]
Google DeepMind. 2025. Gemini 3 Pro: the frontier of vision AI. https://blog. google/innovation-and-ai/technology/developers-tools/gemini-3-pro-vision/
2025
-
[11]
Google DeepMind. 2026. Gemini 3.1 Pro Model Card. https://deepmind.google/ models/model-cards/gemini-3-1-pro/. Accessed: 2026-04-02
2026
-
[12]
D Guo et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.Nature(2025). https://www.nature.com/articles/s41586- 025-09422-z
2025
-
[13]
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. 2025. Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos.arXiv preprint arXiv:2501.13826(2025)
Pith/arXiv arXiv 2025
-
[14]
Haoyang Huang, Guoqing Ma, Nan Duan, Xing Chen, Changyi Wan, Ranchen Ming, Tianyu Wang, Bo Wang, Zhiying Lu, Aojie Li, Xianfang Zeng, Xinhao Zhang, Gang Yu, Yuhe Yin, Qiling Wu, Wen Sun, Kang An, Xin Han, Deshan Sun, Wei Ji, Bizhu Huang, Brian Li, Chenfei Wu, Guanzhe Huang, Huixin Xiong, Jiaxin He, Jianchang Wu, Jianlong Yuan, Jie Wu, Jiashuai Liu, Junjin...
arXiv 2025
-
[15]
Qingqiu Huang, Yu Xiong, Anyi Rao, Jiaze Wang, and Dahua Lin. 2020. Movienet: A holistic dataset for movie understanding. InEuropean conference on computer vision. Springer, 709–727
2020
-
[16]
Tzu-Heng Huang, Sirajul Salekin, Javier Movellan, Frederic Sala, and Manjot Bilkhu. 2026. RubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning.arXiv preprint arXiv:2603.09160(2026)
arXiv 2026
-
[17]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. 2025. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749(2025)
Pith/arXiv arXiv 2025
-
[18]
Justin Johnson, Andrej Karpathy, and Li Fei-Fei. 2016. DenseCap: Fully Convolu- tional Localization Networks for Dense Captioning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4565–4574
2016
-
[19]
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles
-
[20]
InProceedings of the IEEE International Conference on Computer Vision
Dense-Captioning Events in Videos. InProceedings of the IEEE International Conference on Computer Vision. 706–715
-
[21]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
Pith/arXiv arXiv 2024
-
[22]
Zhiqiu Lin, Siyuan Cen, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, et al. 2025. Towards Understanding Camera Motions in Any Video.arXiv preprint arXiv:2504.15376 (2025)
arXiv 2025
-
[23]
Hongbo Liu, Jingwen He, Yi Jin, Dian Zheng, Yuhao Dong, Fan Zhang, Ziqi Huang, Yinan He, Yangguang Li, Weichao Chen, et al. 2025. ShotBench: Expert- Level Cinematic Understanding in Vision-Language Models.arXiv preprint arXiv:2506.21356(2025)
arXiv 2025
-
[24]
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. 2024. Latte: Latent Diffusion Transformer for Video Generation.arXiv preprint arXiv:2401.03048(2024). https://arxiv.org/abs/2401. 03048
Pith/arXiv arXiv 2024
-
[25]
Desen Meng, Rui Huang, Zhilin Dai, Xinhao Li, Yifan Xu, Jun Zhang, Zhen- peng Huang, Meng Zhang, Lingshu Zhang, Yi Liu, et al . 2025. Videocap-r1: Enhancing mllms for video captioning via structured thinking.arXiv preprint arXiv:2506.01725(2025)
arXiv 2025
-
[26]
Jonghwan Mun, Linjie Yang, Zhou Ren, Ning Xu, and Bohyung Han. 2019. Stream- lined Dense Video Captioning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6588–6597
2019
-
[27]
Anyi Rao, Jiaze Wang, Linning Xu, Xuekun Jiang, Qingqiu Huang, Bolei Zhou, and Dahua Lin. 2020. A unified framework for shot type classification based on subject centric lens. InEuropean Conference on Computer Vision. Springer, 17–34
2020
-
[28]
Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel
Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel. 2017. Self-Critical Sequence Training for Image Captioning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7008–7024
2017
-
[29]
Mattia Savardi, András Bálint Kovács, Alberto Signoroni, and Sergio Benini. 2023. CineScale2: a dataset of cinematic camera features in movies.Data in Brief51 (2023), 109627
2023
-
[30]
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. 2025. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615(2025)
Pith/arXiv arXiv 2025
-
[31]
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. 2024. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18221– 18232
2024
-
[32]
Yunlong Tang, Junjia Guo, Hang Hua, Susan Liang, Mingqian Feng, Xinyang Li, Rui Mao, Chao Huang, Jing Bi, Zeliang Zhang, et al. 2025. Vidcomposition: Can mllms analyze compositions in compiled videos?. InProceedings of the Computer Vision and Pattern Recognition Conference. 8490–8500
2025
-
[33]
Zhijiang Tang, Linhua Wang, Jiaxin Qi, Weihao Jiang, Peng Hou, Anxiang Zeng, and Jianqiang Huang. 2026. CCCaption: Dual-Reward Reinforcement Learning for Complete and Correct Image Captioning.arXiv preprint arXiv:2602.21655 (2026)
arXiv 2026
-
[34]
Makarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun, and Sanja Fidler. 2016. Movieqa: Understanding stories in movies through question-answering. InProceedings of the IEEE conference on computer vision and pattern recognition. 4631–4640
2016
-
[35]
2025.Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action
Alibaba Cloud Qwen Team. 2025.Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action. Technical Report. ArXiv / Qwen Blog. https://qwen.ai/blog?from=research.latest-advancements- list&id=99f0335c4ad9ff615418d48535ab6d8afef
2025
-
[36]
2025.MiniCPM-V 4.5: A GPT-4o Level MLLM for Single Image, Multi Image and High-FPS Video Understanding
OpenBMB Team. 2025.MiniCPM-V 4.5: A GPT-4o Level MLLM for Single Image, Multi Image and High-FPS Video Understanding. Technical Report. GitHub / OpenBMB. https://github.com/OpenBMB/MiniCPM-V
2025
-
[37]
Paul Vicol, Makarand Tapaswi, Lluis Castrejon, and Sanja Fidler. 2018. Moviegraphs: Towards understanding human-centric situations from videos. InProceedings of the IEEE conference on computer vision and pattern recognition. 8581–8590
2018
-
[38]
Fei Wang, Wenxuan Zhou, James Y Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. 2024. mdpo: Conditional preference optimization for multimodal large language models.arXiv preprint arXiv:2406.11839(2024)
arXiv 2024
-
[39]
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. 2025. VideoRFT: Incentivizing Video Reasoning Capability in MLLMs via Reinforced Fine-Tuning. arXiv preprint arXiv:2505.12434(2025)
arXiv 2025
-
[40]
Xin Wang, Wenhu Chen, Jiawei Wu, Yuan-Fang Wang, and William Yang Wang
-
[41]
InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Video Captioning via Hierarchical Reinforcement Learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4213–4222
-
[42]
Xinran Wang, Songyu Xu, Xiangxuan Shan, Yuxuan Zhang, Muxi Diao, Xueyan Duan, Yanhua Huang, Kongming Liang, and Zhanyu Ma. 2025. CineTechBench: A Benchmark for Cinematographic Technique Understanding and Generation. arXiv preprint arXiv:2505.15145(2025)
arXiv 2025
-
[43]
Yifeng Wang et al. 2026. VideoAuto-R1: Video Auto Reasoning via Thinking Once, Streaming for the Rest.arXiv preprint arXiv:2601.05175(2026)
arXiv 2026
-
[44]
Hang Wu, Yujun Cai, Zehao Li, Haonan Ge, Bowen Sun, Junsong Yuan, and Yiwei Wang. 2026. CamReasoner: Reinforcing Camera Movement Understanding via MM, xx–xx xx xxxx, xxx Mao et al. Structured Spatial Reasoning.arXiv preprint arXiv:2602.00181(2026)
Pith/arXiv arXiv 2026
-
[45]
Long Xing, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Jianze Liang, Qidong Huang, Jiaqi Wang, Feng Wu, and Dahua Lin. 2025. CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning.arXiv preprint arXiv:2509.22647 (2025)
arXiv 2025
-
[46]
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. 2025. VideoChat-R1.5: Visual Test-Time Scaling to Reinforce Multimodal Reasoning by Iterative Perception.arXiv preprint arXiv:2509.21100(2025)
arXiv 2025
-
[47]
Linli Yao, Yuancheng Wei, Yaojie Zhang, Lei Li, Xinlong Chen, Feifan Song, Ziyue Wang, Kun Ouyang, Yuanxin Liu, Lingpeng Kong, et al. 2026. TimeChat- Captioner: Scripting Multi-Scene Videos with Time-Aware and Structural Audio- Visual Captions.arXiv preprint arXiv:2602.08711(2026)
arXiv 2026
-
[48]
Liping Yuan, Jiawei Wang, Haomiao Sun, Yuchen Zhang, and Yuan Lin. 2024. Tarsier: Recipes for Training and Evaluating Large Video Language Models.arXiv preprint arXiv:2407.00634(2024)
arXiv 2024
-
[49]
Liping Yuan, Jiawei Wang, Haomiao Sun, Yuchen Zhang, and Yuan Lin. 2025. Tarsier2: Advancing large vision-language models from detailed video description to comprehensive video understanding.arXiv preprint arXiv:2501.07888(2025)
arXiv 2025
-
[50]
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. 2025. R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization.arXiv preprint arXiv:2503.12937(2025)
Pith/arXiv arXiv 2025
-
[51]
Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chunyuan Li, Alexander G Hauptmann, Yonatan Bisk, et al. 2025. Direct preference optimization of video large multimodal models from language model reward. InProceedings of the 2025 Conference of the Nations of the Ameri- cas Chapter of the Association for Computational L...
2025
-
[52]
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. 2024. LLaVA-NeXT: A Strong Zero-shot Video Understanding Model. https://llava-vl.github.io/blog/2024-04-30-llava-next- video/
2024
-
[53]
Yabo Zhang, Yuxiang Wei, Dongsheng Jiang, Xiaopeng Zhang, Wangmeng Zuo, and Qi Tian. 2023. ControlVideo: Training-free Controllable Text-to-Video Gen- eration.arXiv preprint arXiv:2305.13077(2023). https://arxiv.org/abs/2305.13077
arXiv 2023
-
[54]
Yiyang Zhou, Chenhang Cui, Rafael Rafailov, Chelsea Finn, and Huaxiu Yao. 2024. Aligning modalities in vision large language models via preference fine-tuning. arXiv preprint arXiv:2402.11411(2024)
Pith/arXiv arXiv 2024
-
[55]
2025.InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Yue Cao, Yangzhou Liu, Weiye Xu, Hao Li, Jiahao Wang, Han Lv, Dengnian Chen, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zhang, Wenqi Shao, Junjun He, Yingtong Xiong, Wenw...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.