DREAM: Dense Retrieval Embeddings via Autoregressive Modeling
Pith reviewed 2026-06-26 00:03 UTC · model grok-4.3
The pith
Retriever similarity scores injected into a frozen LLM's attention heads let the LLM's next-token loss train the retriever without labeled pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DREAM trains a dense retriever by injecting its query-document similarity scores into selected attention heads of a frozen LLM so that relevant documents receive more attention while the LLM predicts the target output; the resulting next-token prediction loss then supplies gradients that update the retriever.
What carries the argument
Injection of retriever-generated similarity scores into selected attention heads of a frozen LLM to modulate document attention during next-token prediction.
If this is right
- Dense retrievers can be trained without any labeled positive-negative pairs.
- The same training signal works across embedding backbones from 0.5B to 3B parameters.
- A frozen LLM can serve as the sole source of supervision for retrieval models.
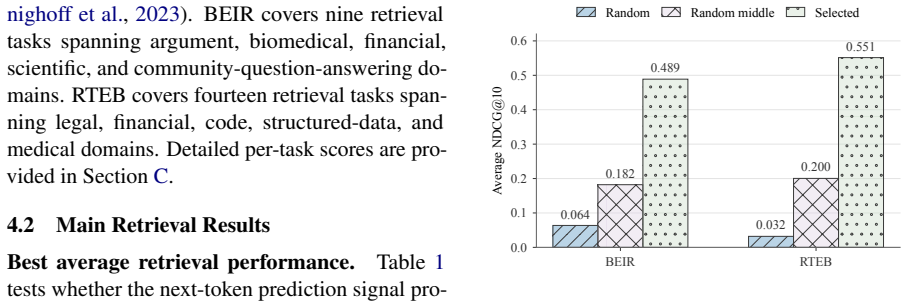
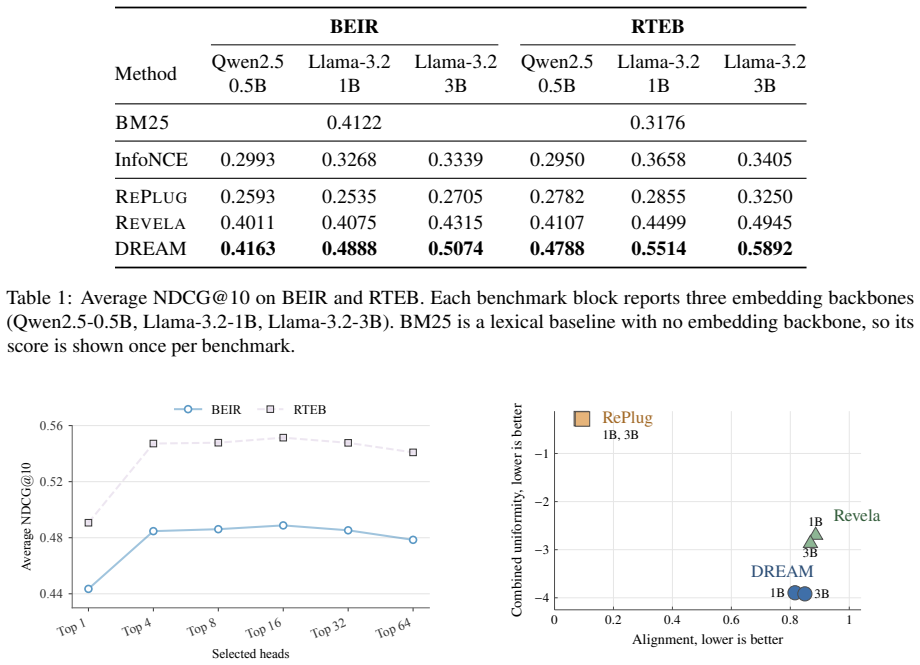
- Performance gains appear on both BEIR and RTEB benchmarks.
Where Pith is reading between the lines
- The approach could extend to training retrievers on purely unlabeled query-document collections by using any available LLM.
- Similar attention-injection tricks might let next-token losses supervise other embedding tasks such as reranking or clustering.
- If the attention-head injection generalizes, retrieval training cost could drop because labeled data collection is no longer required.
Load-bearing premise
The next-token prediction loss computed inside the LLM can effectively supervise the separate retriever model when similarity scores are injected into its attention heads.
What would settle it
Train DREAM on one retrieval benchmark and test whether it still outperforms contrastive baselines when both are evaluated on the full BEIR suite.
Figures



read the original abstract
Dense retrieval embedding models are a fundamental component of modern retrieval-based AI systems. Most dense retrievers are trained with contrastive objectives, which require labeled positive and negative document pairs that are often costly and difficult to obtain. In this work, we investigate whether the autoregressive next-token prediction objective of a large language model (LLM) can provide supervision for dense retrieval. The intuition is simple: if a document contains information relevant to a query, conditioning on that document should make the target output easier for the LLM to predict. A key challenge is that the next-token prediction loss is computed inside the LLM, while the retriever is a separate embedding model. To address this challenge, we propose DREAM (Dense Retrieval Embeddings via Autoregressive Modeling), which injects retriever-generated query-document similarity scores into selected attention heads of a frozen LLM. During training, these scores determine how much attention each candidate document receives while the LLM predicts the target output. The resulting prediction loss provides gradients for retriever training through the attention mechanism. We evaluate DREAM on retrieval benchmarks BEIR and RTEB using embedding backbones ranging from 0.5B to 3B parameters. DREAM consistently outperforms existing baselines across different model scales. These results demonstrate that DREAM provides a promising approach for training dense retrievers through autoregressive modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DREAM, a method to train dense retrievers without contrastive pairs by injecting retriever-generated query-document similarity scores into selected attention heads of a frozen LLM. The LLM's next-token prediction loss on a target output then supplies gradients back to the retriever. Experiments across 0.5B–3B embedding backbones report consistent outperformance over baselines on the BEIR and RTEB benchmarks.
Significance. If the central claim holds, the work offers a label-efficient alternative to contrastive training by repurposing an external LLM's autoregressive objective. The approach is technically interesting for its use of attention injection as a differentiable bridge between embedding and language modeling. Credit is due for the reproducible experimental scale (multiple model sizes) and the attempt to avoid direct fitting to LLM outputs.
major comments (3)
- [§3.2] §3.2: the precise injection operator (additive bias to attention logits, scaling of values, or other) and the exact target output sequence used for the LLM loss are not specified with sufficient formality. Without these, it is impossible to verify whether the resulting gradient signal correlates with retrieval relevance rather than LLM-internal priors, which is load-bearing for the outperformance claim.
- [§4.1] §4.1 and Table 2: the paper reports consistent gains on BEIR/RTEB but provides no statistical significance tests, run-to-run variance, or ablation on the number of candidate documents tokenized into the LLM context. This weakens the cross-scale and cross-benchmark conclusions.
- [§3.3] §3.3, Eq. (3): the claim that the supervision is 'parameter-free' with respect to the LLM is undercut if the choice of which attention heads receive the injection is itself a hyperparameter tuned on the retrieval validation set; this choice must be shown to be fixed across all reported experiments.
minor comments (2)
- [Figure 2] Figure 2: the diagram of attention injection would benefit from an explicit equation showing how the similarity score modifies the attention matrix.
- [§2] Related work section: several recent papers on LLM-as-retriever or distillation from frozen LLMs are cited only in passing; a more systematic comparison of supervision signals would strengthen the positioning.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and will incorporate clarifications and additional analyses into the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2: the precise injection operator (additive bias to attention logits, scaling of values, or other) and the exact target output sequence used for the LLM loss are not specified with sufficient formality. Without these, it is impossible to verify whether the resulting gradient signal correlates with retrieval relevance rather than LLM-internal priors, which is load-bearing for the outperformance claim.
Authors: We agree that a more formal specification is needed to make the gradient pathway explicit. In the revision we will add a precise mathematical definition in §3.2 of the injection operator (additive bias to the attention logits of the selected heads) together with the exact target token sequence on which the autoregressive loss is computed. This will allow readers to verify that the supervision signal is modulated by the retriever scores rather than solely by LLM-internal priors. revision: yes
-
Referee: [§4.1] §4.1 and Table 2: the paper reports consistent gains on BEIR/RTEB but provides no statistical significance tests, run-to-run variance, or ablation on the number of candidate documents tokenized into the LLM context. This weakens the cross-scale and cross-benchmark conclusions.
Authors: We acknowledge the value of statistical rigor and sensitivity analysis. The revised manuscript will report standard deviations across multiple random seeds, include paired statistical significance tests on the BEIR and RTEB results, and add an ablation varying the number of candidate documents passed to the LLM context. revision: yes
-
Referee: [§3.3] §3.3, Eq. (3): the claim that the supervision is 'parameter-free' with respect to the LLM is undercut if the choice of which attention heads receive the injection is itself a hyperparameter tuned on the retrieval validation set; this choice must be shown to be fixed across all reported experiments.
Authors: The attention-head selection was determined once via preliminary experiments on a separate development split and then held fixed for all model scales and all reported benchmarks. We will add an explicit statement in the revised §3.3 confirming that this choice is constant across experiments and is not re-tuned on the validation sets used for the final results, thereby preserving the parameter-free claim with respect to the LLM. revision: yes
Circularity Check
No circularity; supervision is external LLM loss
full rationale
The derivation chain trains a separate retriever by backpropagating through injected similarity scores into a frozen external LLM's attention heads, using the LLM's next-token prediction loss on target sequences as the objective. This is not self-definitional, not a fitted input renamed as prediction, and contains no self-citation load-bearing steps or uniqueness theorems. The method is self-contained against external benchmarks (BEIR, RTEB) with no reduction of the claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption If a document contains information relevant to a query, conditioning on that document should make the target output easier for the LLM to predict.
Reference graph
Works this paper leans on
-
[1]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[2]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Simcse: Simple contrastive learning of sentence embeddings , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[3]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improving text embeddings with large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[4]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[6]
Transactions on Machine Learning Research , issn=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[7]
Following the Navigation: Enhancing Small Language Models Contextual Reasoning with
Xiaoqi Ni and Jie Wang and Lin Yang and Yiyang Lu and Hanzhu Chen and Rui Liu and Jianye HAO , booktitle=. Following the Navigation: Enhancing Small Language Models Contextual Reasoning with. 2026 , url=
2026
-
[8]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Precise zero-shot dense retrieval without relevance labels , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
International Conference on Learning Representations , year=
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author=. International Conference on Learning Representations , year=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Mitigating the impact of false negative in dense retrieval with contrastive confidence regularization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Replug: Retrieval-augmented black-box language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[12]
The Fourteenth International Conference on Learning Representations , year=
Revela: Dense Retriever Learning via Language Modeling , author=. The Fourteenth International Conference on Learning Representations , year=
-
[13]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Nandan Thakur and Nils Reimers and Andreas R. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[14]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
Mteb: Massive text embedding benchmark , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[15]
2025 , month = oct, howpublished =
Introducing. 2025 , month = oct, howpublished =
2025
-
[16]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[17]
Tri Nguyen and Mir Rosenberg and Xia Song and Jianfeng Gao and Saurabh Tiwary and Rangan Majumder and Li Deng , editor =. Proceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Systems
2016
-
[18]
RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering , booktitle =
Yingqi Qu and Yuchen Ding and Jing Liu and Kai Liu and Ruiyang Ren and Wayne Xin Zhao and Daxiang Dong and Hua Wu and Haifeng Wang , editor =. RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering , booktitle =
-
[19]
CoRR , volume =
Liang Wang and Nan Yang and Xiaolong Huang and Binxing Jiao and Linjun Yang and Daxin Jiang and Rangan Majumder and Furu Wei , title =. CoRR , volume =. 2022 , doi =
2022
-
[20]
CoRR , volume =
Luiz Henrique Bonifacio and Hugo Queiroz Abonizio and Marzieh Fadaee and Rodrigo Nogueira , title =. CoRR , volume =. 2022 , url =
2022
-
[21]
International conference on machine learning , pages=
Retrieval augmented language model pre-training , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[22]
arXiv preprint arXiv:2605.05806 , year=
Retrieval from Within: An Intrinsic Capability of Attention-Based Models , author=. arXiv preprint arXiv:2605.05806 , year=
-
[23]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[24]
arXiv preprint arXiv:2209.11895 , year=
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
-
[25]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Query-focused retrieval heads improve long-context reasoning and re-ranking , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[26]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[27]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[28]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[29]
2018 , url=
Improving Language Understanding by Generative Pre-Training , author=. 2018 , url=
2018
-
[30]
2019 , url=
Language Models are Unsupervised Multitask Learners , author=. 2019 , url=
2019
-
[31]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[32]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
C-pack: Packed resources for general chinese embeddings , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[33]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 embedding: Advancing text embedding and reranking through foundation models , author=. arXiv preprint arXiv:2506.05176 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.