One Index for Subsumption and Roll-up across Time, Geography, and Ontology
Pith reviewed 2026-06-25 21:32 UTC · model grok-4.3
The pith
OEH supplies one declarable index that answers both subsumption and monoid roll-up on hierarchies by probing structure to pick order-embedding or chain decomposition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OEH encodes a hierarchy as a nested-set order-embedding for trees or a chain decomposition for low-width DAGs via a structural probe, enabling both subsumption queries and index-resident monoid roll-up from one structure, with performance matching 2-hop indexes on trees but with added roll-up and faster build.
What carries the argument
The structural probe that selects between nested-set order-embedding and chain decomposition to unify subsumption and roll-up in one index.
If this is right
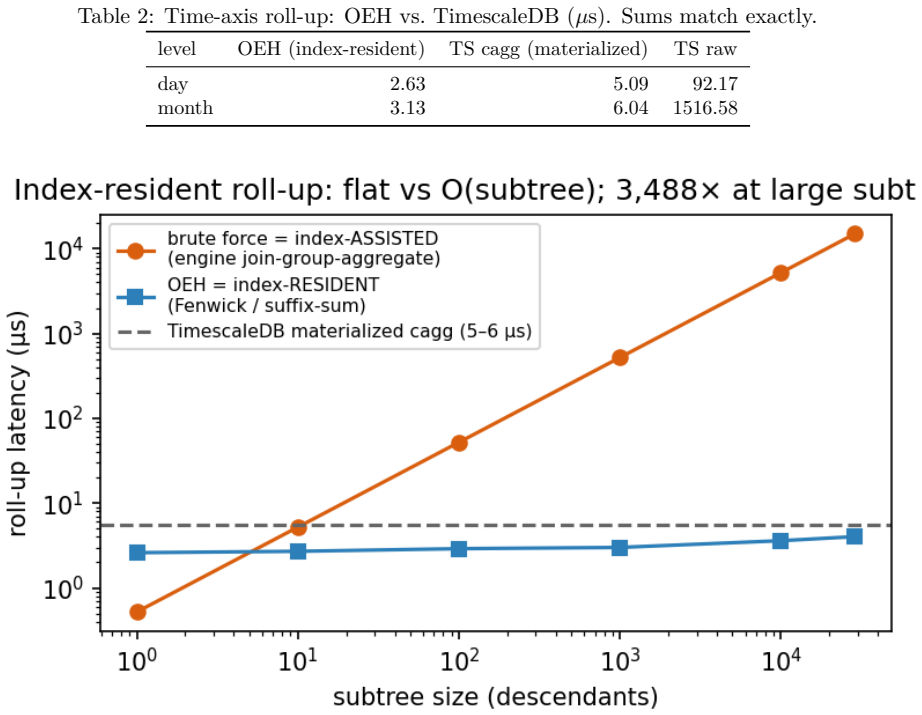
- On trees OEH matches 2-hop query latency while using about half the space and building 6-7 times faster.
- OEH adds index-resident monoid roll-up that 2-hop cannot provide and matches TimescaleDB continuous aggregates exactly in the same latency regime.
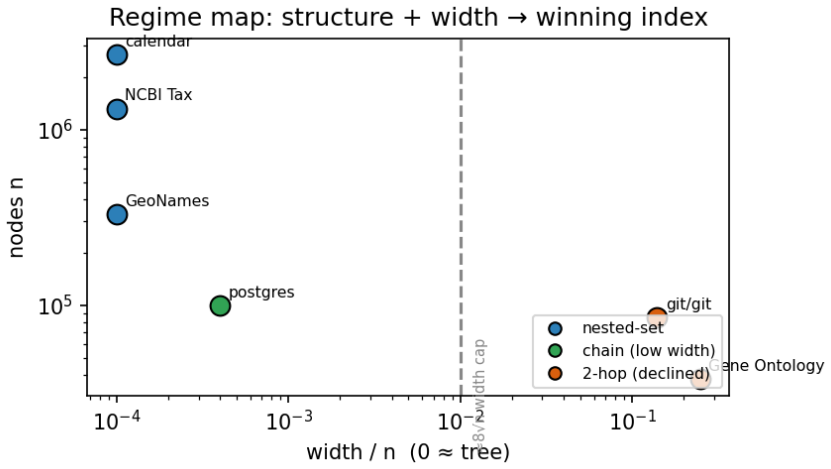
- On high-width DAGs the probe declines the chain encoding and 2-hop dominates.
- The same structure works across calendar, geospatial, and ontology hierarchies without separate silos.
Where Pith is reading between the lines
- Systems that already maintain separate indexes for time, geography, and ontology could replace them with one OEH instance when the hierarchies are trees or narrow DAGs.
- The probe-based selection may extend to other poset workloads such as reachability or ancestor aggregates if the monoid property holds.
- Wider DAGs or hierarchies with changing structure over time would require re-running the probe or hybrid indexes.
Load-bearing premise
A cheap structural probe exists that reliably selects between order-embedding and chain decomposition while preserving correctness of subsumption and exactness of monoid roll-up across the tested hierarchy widths.
What would settle it
A hierarchy on which the structural probe selects the wrong encoding and thereby produces either an incorrect subsumption answer or an inexact monoid roll-up result.
Figures

read the original abstract
Time-series, geospatial, and ontology systems each maintain a hierarchy -- day <= month <= year, zip <= city, is-a / part-of -- and each indexes it in a separate silo. We observe these are all subsumption posets, with one recurring workload: order testing (is x under y?) and hierarchical roll-up (aggregate a measure over everything under y). We present OEH, a single declarable index that, by a cheap structural probe, encodes a hierarchy as a nested-set order-embedding (trees) or a chain decomposition (low-width DAGs), and answers both subsumption and index-resident monoid roll-up from one structure. On five real hierarchies -- Gene Ontology, NCBI Taxonomy (1.3M), GeoNames (330k), a 2.6M-node calendar, and git commit DAGs -- OEH on trees matches a 2-hop index on query latency using about half the space and building 6--7x faster, and adds roll-up that 2-hop cannot. Its roll-up matches TimescaleDB's continuous aggregates exactly and in the same latency regime, while also answering subsumption. On high-width DAGs the chain index is declined and 2-hop dominates. Order-embedding is classical; our contribution is the unification and the structure-selected index over subsumption and index-resident roll-up.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OEH, a single declarable index for subsumption (order testing) and index-resident monoid roll-up on hierarchies modeled as posets. A cheap structural probe selects between nested-set order-embedding for trees and chain decomposition for low-width DAGs. On five real hierarchies (Gene Ontology, NCBI Taxonomy with 1.3M nodes, GeoNames with 330k nodes, a 2.6M-node calendar, and git commit DAGs), OEH on trees matches 2-hop latency with roughly half the space and 6-7x faster build time while adding exact roll-up; roll-up matches TimescaleDB continuous aggregates exactly in the same latency regime; on high-width DAGs the chain option is declined in favor of 2-hop.
Significance. If the empirical results hold, the work unifies indexing for time-series, geospatial, and ontology hierarchies under one structure that supports both subsumption and roll-up without separate silos. Credit is due for the concrete evaluation on large real hierarchies (NCBI Taxonomy, GeoNames) showing space/build advantages plus exact TimescaleDB matching, and for the structure-selected fallback that preserves correctness on high-width DAGs.
minor comments (3)
- [§4] §4 (or equivalent methods section): the description of the structural probe should include pseudocode or a precise decision procedure so that the selection between order-embedding and chain decomposition can be reproduced from the text alone.
- [Table 2] Table 2 (or results table): report the exact space and build-time ratios alongside the latency numbers for each hierarchy to make the 'half the space, 6-7x faster' claim directly verifiable.
- [Results] The abstract states 'exact matching to TimescaleDB' for roll-up; the corresponding section should clarify whether this is byte-for-byte result identity or only latency equivalence under the tested monoids.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were enumerated in the report, so we have no specific points requiring rebuttal or revision at this stage. We remain available to address any minor suggestions or clarifications the editor or referee may wish to raise.
Circularity Check
No significant circularity
full rationale
The paper introduces OEH as a unification of classical order-embedding (for trees) and chain decomposition (for low-width DAGs) to support both subsumption queries and monoid roll-up from one index. The abstract explicitly notes that order-embedding is classical and positions the contribution as the structure-selected index plus unification, backed by concrete empirical results on five external real-world hierarchies (NCBI Taxonomy, GeoNames, etc.). No equations, fitted parameters, self-citations, or ansatzes are described that would make any claimed result equivalent to its inputs by construction. The structure probe and performance claims rest on direct measurement rather than reduction to prior fitted quantities or author-only theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hierarchies in the target domains are subsumption posets
invented entities (1)
-
OEH index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CC BY 4.0
The gene ontology (go-basic, release 2026-05-19).http://geneontology.org, 2026. CC BY 4.0
2026
-
[2]
CC BY 4.0
GeoNames geographical database.https://www.geonames.org, 2026. CC BY 4.0
2026
-
[3]
NCBI taxonomy database.https://ftp.ncbi.nih.gov/pub/taxonomy/, 2026
2026
-
[4]
TimescaleDB: Hierarchical continuous aggregates.https://docs.timescale.com, 2026
2026
-
[5]
Rakesh Agrawal, Alexander Borgida, and H. V. Jagadish. Efficient management of transitive relationships in large data and knowledge bases. InSIGMOD, 1989. doi: 10.1145/67544.66950
-
[6]
Efficient implementation of lattice operations.ACM TOPLAS, 11(1), 1989
Hassan Aït-Kaci, Robert Boyer, Patrick Lincoln, and Roger Nasr. Efficient implementation of lattice operations.ACM TOPLAS, 11(1), 1989. doi: 10.1145/59287.59293
-
[7]
In: Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data
Takuya Akiba, Yoichi Iwata, and Yuichi Yoshida. Fast exact shortest-path distance queries on large networks by pruned landmark labeling. InSIGMOD, 2013. doi: 10.1145/2463676.2465315
-
[8]
Supporting hierarchical data in SAP HANA
Robert Brunel, Jan Finis, Gerald Franz, Norman May, Alfons Kemper, Thomas Neumann, and Franz Faerber. Supporting hierarchical data in SAP HANA. InICDE, 2015. doi: 10.1109/ICDE.2015.7113393. 6
-
[9]
Interactive browsing and navigation in relational databases,
Robert Brunel, Norman May, and Alfons Kemper. Index-assisted hierarchical computations in main-memory RDBMS.PVLDB, 9(12), 2016. doi: 10.14778/2994509.2994524
-
[10]
An incremental reachability index
Laurent Bulteau, Julien David, Florian Horn, and Mathieu Tran-Girard. An incremental reachability index. InSEA, 2025. doi: 10.4230/LIPIcs.SEA.2025.9
-
[11]
Reachability and distance queries via 2-hop labels.SIAM J
Edith Cohen, Eran Halperin, Haim Kaplan, and Uri Zwick. Reachability and distance queries via 2-hop labels.SIAM J. Comput., 32(5), 2003. doi: 10.1137/S0097539702403098
-
[12]
Robert P. Dilworth. A decomposition theorem for partially ordered sets.Annals of Mathematics, 51(1), 1950. doi: 10.2307/1969503
-
[13]
Ben Dushnik and E. W. Miller. Partially ordered sets.American Journal of Mathematics, 63 (3), 1941. doi: 10.2307/2371374
-
[14]
Nadeef: a commodity data cleaning system,
Jan Finis, Robert Brunel, Alfons Kemper, Thomas Neumann, Franz Faerber, and Norman May. DeltaNI: An efficient labeling scheme for versioned hierarchical data. InSIGMOD, 2013. doi: 10.1145/2463676.2465329
-
[15]
Indexing highly dynamic hierarchical data.PVLDB, 8(10), 2015
Jan Finis, Robert Brunel, Alfons Kemper, Thomas Neumann, Norman May, and Franz Faerber. Indexing highly dynamic hierarchical data.PVLDB, 8(10), 2015. doi: 10.14778/2794367. 2794369
-
[16]
Accelerating XPath location steps
Torsten Grust. Accelerating XPath location steps. InSIGMOD, 2002. doi: 10.1145/564691. 564705
-
[17]
Venky Harinarayan, Anand Rajaraman, and Jeffrey D. Ullman. Implementing data cubes efficiently. InSIGMOD, 1996. doi: 10.1145/233269.233333
-
[18]
H. V. Jagadish. A compression technique to materialize transitive closure.ACM TODS, 15(4),
-
[19]
doi: 10.1145/88636.88888
-
[20]
Folklore sampling is optimal for exact hopsets: Confirming the √n barrier
Tuukka Korhonen, Konrad Majewski, Wojciech Nadara, Michał Pilipczuk, and Marek Sołtys. Dynamic treewidth. InFOCS, 2023. doi: 10.1109/FOCS57990.2023.00102
-
[21]
Panagiotis Lionakis, Giacomo Ortali, and Ioannis G. Tollis. Constant-time reachability in DAGs using multidimensional dominance drawings.SN Computer Science, 2, 2021. doi: 10.1007/s42979-021-00713-6
-
[22]
Jensen, and Curtis E
Torben Bach Pedersen, Christian S. Jensen, and Curtis E. Dyreson. A foundation for capturing and querying complex multidimensional data.Information Systems, 26(5), 2001. doi: 10.1016/ S0306-4379(01)00023-0
2001
-
[23]
Renan Veloso, Loïc Cerf, Wagner Meira Jr., and Mohammed J. Zaki. Reachability queries in very large graphs: A fast refined online search approach. InEDBT, 2014
2014
-
[24]
Hilmi Yildirim, Vineet Chaoji, and Mohammed J. Zaki. GRAIL: Scalable reachability index for large graphs. InVLDB, 2010. doi: 10.14778/1920841.1920879
-
[25]
Graph cube: On warehousing and OLAP multidimensional networks
Peixiang Zhao, Xiaolei Li, Dong Xin, and Jiawei Han. Graph cube: On warehousing and OLAP multidimensional networks. InSIGMOD, 2011. doi: 10.1145/1989323.1989413. 7
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.