FlowPipe: LLM-Enhanced Conditional Generative Flow Networks for Data Preparation Pipeline Construction
Pith reviewed 2026-06-26 00:12 UTC · model grok-4.3
The pith
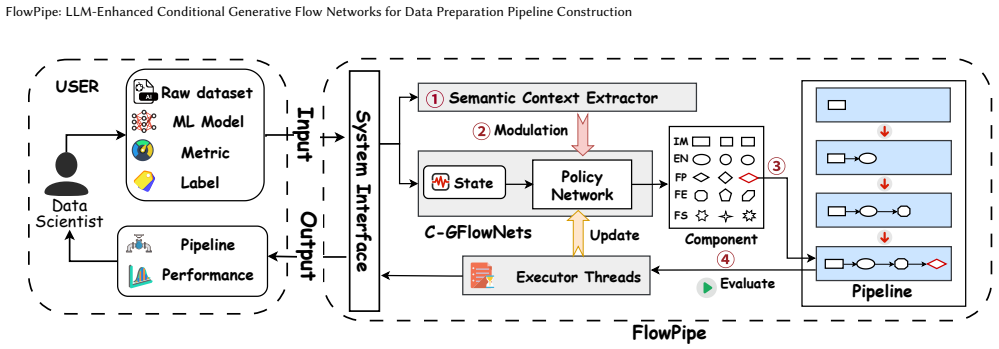
FlowPipe models data preparation as conditional flow generation over a DAG to link early operator choices directly to final validation rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
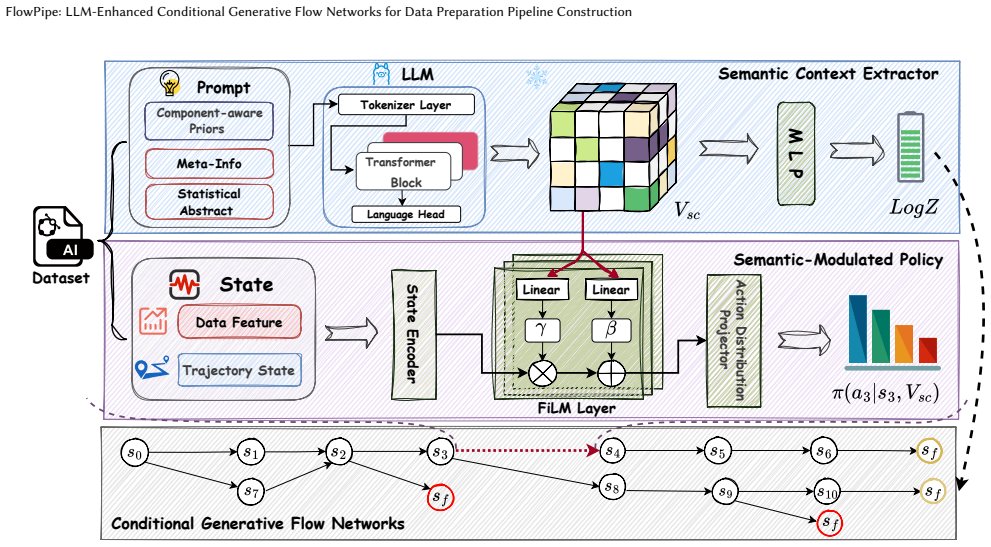
By casting pipeline synthesis as conditional flow generation, C-GFlowNets with Trajectory Balance connect terminal rewards to early decisions, FiLM modulation injects LLM logical priors according to dataset semantics, and failure awareness steers search away from invalid states, yielding 11.96 percent average accuracy gains and 12.5 times faster convergence over Multi-DQN baselines.
What carries the argument
Conditional Generative Flow Networks using a Trajectory Balance objective, modulated via Feature-wise Linear Modulation from LLM priors and augmented with failure awareness to avoid invalid states.
Load-bearing premise
The Trajectory Balance objective together with FiLM modulation from LLM priors is assumed to provide effective long-horizon credit assignment and dataset-context injection without introducing instability or bias in the learned flow.
What would settle it
An ablation experiment that removes either the Trajectory Balance objective or the LLM-derived FiLM conditioning and checks whether the reported accuracy and convergence advantages over Multi-DQN baselines disappear on the same 74 datasets.
Figures




read the original abstract
Data preparation pipelines improve data quality in machine learning by transforming raw tables into learning-ready data through sequential cleaning and feature transformation operators. However, automatically constructing such pipelines is computationally difficult because operator sequences are combinatorial and end-to-end evaluation is expensive. Existing state-of-the-art (SOTA) Multi-DQN methods still face three key limitations: decoupled value estimators weaken long-horizon credit assignment, dataset context is only weakly injected into the policy, and exploration is inefficient in a sparse search space with many invalid states. To address these issues, we propose FlowPipe, a unified framework that formulates pipeline synthesis as conditional probabilistic flow generation over a directed acyclic graph. FlowPipe uses Conditional Generative Flow Networks (C-GFlowNets) with a Trajectory Balance objective to connect terminal validation rewards with early pipeline decisions. It further introduces Deep Semantic Modulation through Feature-wise Linear Modulation (FiLM), allowing LLM-derived logical priors to condition the policy's internal activations according to dataset semantics. In addition, FlowPipe incorporates failure awareness into the flow objective to avoid invalid states and concentrate search on high-potential regions. Experiments on two benchmark suites with 74 real-world datasets show that FlowPipe outperforms SOTA baselines, improving accuracy by 11.96% on average and achieving 12.5x faster training convergence. Source code is available at https://github.com/KunyuNi/FlowPipe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FlowPipe, a framework that formulates data preparation pipeline construction as conditional probabilistic flow generation over a DAG. It employs Conditional Generative Flow Networks (C-GFlowNets) with a Trajectory Balance objective to improve long-horizon credit assignment, Feature-wise Linear Modulation (FiLM) to inject LLM-derived logical priors for dataset-context conditioning, and failure awareness in the flow objective to avoid invalid states. The central empirical claim, based on experiments across two benchmark suites with 74 real-world datasets, is that FlowPipe outperforms SOTA Multi-DQN baselines by 11.96% average accuracy while achieving 12.5x faster training convergence. Source code is released at the cited GitHub repository.
Significance. If the empirical results hold under detailed scrutiny, the work provides a coherent and targeted advance in automated data preparation by directly addressing credit assignment, weak context injection, and inefficient exploration in sparse spaces. The combination of C-GFlowNets with LLM priors via FiLM is a timely integration of generative modeling and semantic conditioning. Explicit credit is due for the public code release, which supports reproducibility and allows independent verification of the reported gains on the 74 datasets.
minor comments (2)
- The abstract states quantitative gains without naming the two benchmark suites or indicating whether they are public (e.g., OpenML-derived or custom); adding this detail would improve immediate context for readers.
- Acronyms such as C-GFlowNets and FiLM are introduced in the abstract; ensure they receive explicit definitions on first use in the main text body.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of the proposed FlowPipe framework, and recommendation for minor revision. We appreciate the recognition of the integration of C-GFlowNets with LLM priors via FiLM, the public code release, and the empirical results on 74 datasets. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper's central claim is an empirical performance comparison on 74 real-world datasets against SOTA baselines, with no mathematical derivation chain, equations, or self-referential definitions presented that would reduce the reported accuracy gains or convergence speed to quantities fitted or defined within the same work. The method description (C-GFlowNets, Trajectory Balance, FiLM modulation, failure awareness) invokes standard components from prior literature without self-citation load-bearing or ansatz smuggling that forces the outcome. The load-bearing element remains the external benchmark results, which are falsifiable and not constructed by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ziawasch Abedjan, Xu Chul, Dong Deng, Raul Castro Fernandez, Ihab F Ilyasl, Mourad Ouzzani, Paolo Papotti, Michael Stonebraker, and Nan Tang. 2016. De- tecting Data Errors: Where are we and what needs to be done?Proceedings of the VLDB Endowment9, 12 (2016)
2016
-
[2]
Arthur Asuncion, David Newman, et al. 2007. UCI machine learning repository
2007
-
[3]
Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. 2021. Flow network based generative models for non-iterative diverse candidate generation.Advances in neural information processing systems34 (2021), 27381–27394
2021
-
[4]
Yoshua Bengio, Salem Lahlou, Tristan Deleu, Edward J Hu, Mo Tiwari, and Emmanuel Bengio. 2023. Gflownet foundations.Journal of Machine Learning Research24, 210 (2023), 1–55
2023
-
[5]
Laure Berti-Equille. 2019. Learn2clean: Optimizing the sequence of tasks for web data preparation. InThe world wide web conference. 2580–2586
2019
-
[6]
Matthias Boehm, Iulian Antonov, Sebastian Baunsgaard, Mark Dokter, Robert Ginthör, Kevin Innerebner, Florijan Klezin, Stefanie Lindstaedt, Arnab Phani, Benjamin Rath, et al. 2019. SystemDS: A declarative machine learning system for the end-to-end data science lifecycle.arXiv preprint arXiv:1909.02976(2019)
arXiv 2019
-
[7]
Chengliang Chai, Nan Tang, Ju Fan, and Yuyu Luo. 2023. Demystifying arti- ficial intelligence for data preparation. InCompanion of the 2023 International Conference on Management of Data. 13–20
2023
-
[8]
Jing Chang, Chang Liu, Jinbin Huang, Shuyuan Zheng, Rui Mao, and Jianbin Qin
-
[9]
ShapleyPipe: Hierarchical Shapley Search for Data Preparation Pipeline Construction.arXiv preprint arXiv:2510.27168(2025)
arXiv 2025
-
[10]
Sibei Chen, Hanbing Liu, Waiting Jin, Xiangyu Sun, Xiaoyao Feng, Ju Fan, Xi- aoyong Du, and Nan Tang. 2024. Chatpipe: Orchestrating data preparation pipelines by optimizing human-chatgpt interactions. InCompanion of the 2024 International Conference on Management of Data. 484–487
2024
-
[11]
Sibei Chen, Nan Tang, Ju Fan, Xuemi Yan, Chengliang Chai, Guoliang Li, and Xi- aoyong Du. 2023. Haipipe: Combining human-generated and machine-generated pipelines for data preparation.Proceedings of the ACM on Management of Data1, 1 (2023), 1–26
2023
-
[12]
Xu Chu, Ihab F Ilyas, Sanjay Krishnan, and Jiannan Wang. 2016. Data cleaning: Overview and emerging challenges. InProceedings of the 2016 international conference on management of data. 2201–2206
2016
-
[13]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[14]
Wei Fan, Kunpeng Liu, Hao Liu, Pengyang Wang, Yong Ge, and Yanjie Fu. 2020. Autofs: Automated feature selection via diversity-aware interactive reinforce- ment learning. In2020 IEEE International Conference on Data Mining (ICDM). IEEE, 1008–1013
2020
-
[15]
Saeed Fathollahzadeh, Essam Mansour, and Matthias Boehm. 2025. CatDB: Data- catalog-guided, LLM-based Generation of Data-centric ML Pipelines.Proceedings of the VLDB Endowment18, 8 (2025), 2639–2652
2025
-
[16]
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. 2015. Efficient and robust automated machine learning.Advances in neural information processing systems28 (2015)
2015
-
[17]
Haotian Gao, Shaofeng Cai, Tien Tuan Anh Dinh, Zhiyong Huang, and Beng Chin Ooi. 2024. CtxPipe: Context-aware Data Preparation Pipeline Construction for Machine Learning.Proceedings of the ACM on Management of Data2, 6 (2024), 1–27
2024
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
Pith/arXiv arXiv 2024
-
[19]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. 2022. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems35 (2022), 507–520
2022
-
[20]
Mazhar Hameed and Felix Naumann. 2020. Data preparation: A survey of commercial tools.ACM sigmod record49, 3 (2020), 18–29
2020
-
[21]
Yuval Heffetz, Roman Vainshtein, Gilad Katz, and Lior Rokach. 2020. Deepline: Automl tool for pipelines generation using deep reinforcement learning and hierarchical actions filtering. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2103–2113
2020
-
[22]
Benjamin Hilprecht, Christian Hammacher, Eduardo S Reis, Mohamed Abdelaal, and Carsten Binnig. 2023. Diffml: End-to-end differentiable ML pipelines. In Proceedings of the Seventh Workshop on Data Management for End-to-End Machine Learning. 1–7
2023
-
[23]
Edward J Hu, Nikolay Malkin, Moksh Jain, Katie E Everett, Alexandros Graikos, and Yoshua Bengio. 2023. GFlowNet-EM for learning compositional latent variable models. InInternational Conference on Machine Learning. PMLR, 13528– 13549
2023
-
[24]
Moksh Jain, Emmanuel Bengio, Alex Hernandez-Garcia, Jarrid Rector-Brooks, Bonaventure FP Dossou, Chanakya Ajit Ekbote, Jie Fu, Tianyu Zhang, Michael Kilgour, Dinghuai Zhang, et al. 2022. Biological sequence design with gflownets. InInternational Conference on Machine Learning. PMLR, 9786–9801
2022
-
[25]
Min Soo Kang, Sung Yul Park, Myung-Ae Chung, and Dong-hun Han. 2024. Azure Automated Machine Learning. InNO-CODE AI: Concepts and Applications in Machine Learning, Visualization, and Cloud Platforms. World Scientific, 263–282
2024
-
[26]
Udayan Khurana, Horst Samulowitz, and Deepak Turaga. 2018. Feature engi- neering for predictive modeling using reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[27]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. 2020. Conserva- tive q-learning for offline reinforcement learning.Advances in neural information processing systems33 (2020), 1179–1191
2020
-
[28]
Erin LeDell, Sebastien Poirier, et al. 2020. H2o automl: Scalable automatic machine learning. InProceedings of the AutoML Workshop at ICML, Vol. 2020. 24
2020
-
[29]
Chonho Lee, Zhaojing Luo, Kee Yuan Ngiam, Meihui Zhang, Kaiping Zheng, Gang Chen, Beng Chin Ooi, and Wei Luen James Yip. 2017. Big healthcare data analytics: Challenges and applications.Handbook of large-scale distributed computing in smart healthcare(2017), 11–41
2017
-
[30]
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. 2018. Hyperband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research18, 185 (2018), 1–52
2018
-
[31]
Liangwei Li, Yiyi Zhang, and Ning Wang. 2025. SwiftDP: An Efficient Frame- work for Automated Data Preparation Pipeline Generation. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 4572–4575
2025
-
[32]
Peng Li, Zhiyi Chen, Xu Chu, and Kexin Rong. 2023. Diffprep: Differentiable data preprocessing pipeline search for learning over tabular data.Proceedings of the ACM on Management of Data1, 2 (2023), 1–26
2023
-
[33]
Peng Li, Yeye He, Dror Yashar, Weiwei Cui, Song Ge, Haidong Zhang, Danielle Rifinski Fainman, Dongmei Zhang, and Surajit Chaudhuri. 2024. Table-gpt: Table fine-tuned gpt for diverse table tasks.Proceedings of the ACM on Management of Data2, 3 (2024), 1–28
2024
-
[34]
Yonggang Li, Guosheng Hu, Yongtao Wang, Timothy Hospedales, Neil M Robert- son, and Yongxin Yang. 2020. Differentiable automatic data augmentation. In European conference on computer vision. Springer, 580–595
2020
-
[35]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281(2023)
Pith/arXiv arXiv 2023
-
[36]
Hanxiao Liu, Karen Simonyan, and Yiming Yang. [n. d.]. DARTS: Differentiable Architecture Search. InInternational Conference on Learning Representations
-
[37]
Zhaojing Luo, Sai Ho Yeung, Meihui Zhang, Kaiping Zheng, Lei Zhu, Gang Chen, Feiyi Fan, Qian Lin, Kee Yuan Ngiam, and Beng Chin Ooi. 2021. MLCask: Efficient management of component evolution in collaborative data analytics pipelines. In2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 1655–1666
2021
-
[38]
Angelo Mozzillo, Luca Zecchini, Luca Gagliardelli, Adeel Aslam, Sonia Bergam- aschi, and Giovanni Simonini. 2023. Evaluation of dataframe libraries for data preparation on a single machine.arXiv preprint arXiv:2312.11122(2023)
arXiv 2023
-
[39]
Avanika Narayan, Ines Chami, Laurel Orr, and Christopher Ré. 2022. Can Foun- dation Models Wrangle Your Data?Proceedings of the VLDB Endowment16, 4 (2022), 738–746
2022
-
[40]
Puhua Niu, Shili Wu, Mingzhou Fan, and Xiaoning Qian. 2024. GFlowNet training by policy gradients. InProceedings of the 41st International Conference on Machine Learning. 38344–38380
2024
-
[41]
Randal S Olson and Jason H Moore. 2016. TPOT: A tree-based pipeline optimiza- tion tool for automating machine learning. InWorkshop on automatic machine learning. PMLR, 66–74
2016
-
[42]
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. 2018. Film: Visual reasoning with a general conditioning layer. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[43]
Hieu Pham, Melody Y Guan, Barret Zoph, Quoc V Le, and Jeff Dean. [n. d.]. Efficient Neural Architecture Search via Parameter Sharing. ([n. d.])
-
[44]
Neoklis Polyzotis, Martin Zinkevich, Sudip Roy, Eric Breck, and Steven Whang
-
[45]
Data validation for machine learning.Proceedings of machine learning and systems1 (2019), 334–347
2019
-
[46]
Sebastian Schelter, Dustin Lange, Philipp Schmidt, Meltem Celikel, Felix Biess- mann, and Andreas Grafberger. 2018. Automating large-scale data quality verifi- cation.Proceedings of the VLDB Endowment11, 12 (2018), 1781–1794
2018
-
[47]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[48]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
Pith/arXiv arXiv 2017
-
[49]
David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Diet- mar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. 2015. Hidden technical debt in machine learning systems.Advances in neural information processing systems28 (2015)
2015
-
[50]
Zeyuan Shang, Emanuel Zgraggen, Benedetto Buratti, Ferdinand Kossmann, Philipp Eichmann, Yeounoh Chung, Carsten Binnig, Eli Upfal, and Tim Kraska
-
[51]
14 FlowPipe: LLM-Enhanced Conditional Generative Flow Networks for Data Preparation Pipeline Construction InProceedings of the 2019 international conference on management of data
Democratizing data science through interactive curation of ml pipelines. 14 FlowPipe: LLM-Enhanced Conditional Generative Flow Networks for Data Preparation Pipeline Construction InProceedings of the 2019 international conference on management of data. 1171– 1188
2019
-
[52]
Ravid Shwartz-Ziv and Amitai Armon. 2022. Tabular data: Deep learning is not all you need.Information Fusion81 (2022), 84–90
2022
-
[53]
Shafaq Siddiqi, Roman Kern, and Matthias Boehm. 2023. SAGA: A scalable frame- work for optimizing data cleaning pipelines for machine learning applications. Proceedings of the ACM on Management of Data1, 3 (2023), 1–26
2023
-
[54]
Tiago Silva, Rodrigo Barreto Alves, Eliezer de Souza da Silva, Amauri H Souza, Vikas Garg, Samuel Kaski, and Diego Mesquita. 2025. When do GFlowNets learn the right distribution?. InThe Thirteenth International Conference on Learning Representations
2025
-
[55]
Chris Thornton, Frank Hutter, Holger H Hoos, and Kevin Leyton-Brown. 2013. Auto-WEKA: Combined selection and hyperparameter optimization of classifica- tion algorithms. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 847–855
2013
-
[56]
Hado Van Hasselt, Arthur Guez, and David Silver. 2016. Deep reinforcement learning with double q-learning. InProceedings of the AAAI conference on artificial intelligence, Vol. 30
2016
-
[57]
Joaquin Vanschoren, Jan N Van Rijn, Bernd Bischl, and Luis Torgo. 2014. OpenML: networked science in machine learning.ACM SIGKDD Explorations Newsletter 15, 2 (2014), 49–60
2014
-
[58]
Shuhei Watanabe. 2023. Tree-structured parzen estimator: Understanding its algorithm components and their roles for better empirical performance.arXiv preprint arXiv:2304.11127(2023)
Pith/arXiv arXiv 2023
-
[59]
Doris Xin, Hui Miao, Aditya Parameswaran, and Neoklis Polyzotis. 2021. Pro- duction machine learning pipelines: Empirical analysis and optimization oppor- tunities. InProceedings of the 2021 international conference on management of data. 2639–2652
2021
-
[60]
Chengrun Yang, Yuji Akimoto, Dae Won Kim, and Madeleine Udell. 2019. OBOE: Collaborative filtering for AutoML model selection. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 1173–1183
2019
-
[61]
Junwen Yang, Yeye He, and Surajit Chaudhuri. 2021. Auto-pipeline: synthesiz- ing complex data pipelines by-target using reinforcement learning and search. Proceedings of the VLDB Endowment14, 11 (2021), 2563–2575
2021
-
[62]
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 8413–8426
2020
-
[63]
Gyeong-In Yu, Saeed Amizadeh, Sehoon Kim, Artidoro Pagnoni, Ce Zhang, Byung-Gon Chun, Markus Weimer, and Matteo Interlandi. 2021. WindTunnel: towards differentiable ML pipelines beyond a single model.Proceedings of the VLDB Endowment15, 1 (2021), 11–20
2021
-
[64]
Ehtisham Zaidi, Rita Sallam, and Shubhangi Vashisth. 2017. Market Guide for Data Preparation.cit. on(2017), 2
2017
-
[65]
Dinghuai Zhang, Hanjun Dai, Nikolay Malkin, Aaron C Courville, Yoshua Bengio, and Ling Pan. 2023. Let the flows tell: Solving graph combinatorial problems with gflownets.Advances in neural information processing systems36 (2023), 11952–11969
2023
-
[66]
Haochen Zhang, Yuyang Dong, Chuan Xiao, and Masafumi Oyamada. 2023. Large language models as data preprocessors.arXiv preprint arXiv:2308.16361 (2023). 15 Ni et al. A Supplementary Results In this appendix, we provide the full evaluation results of FlowPipe across the DiffPrep and DeepLine datasets. These results substan- tiate the claims made in Section ...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.