Revealing Training Data Exposure in Vision Language Large Models via Parameter Gradients
Pith reviewed 2026-06-26 00:24 UTC · model grok-4.3
The pith
GradAudit uses gradient signatures to detect training data exposure in vision-language large models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
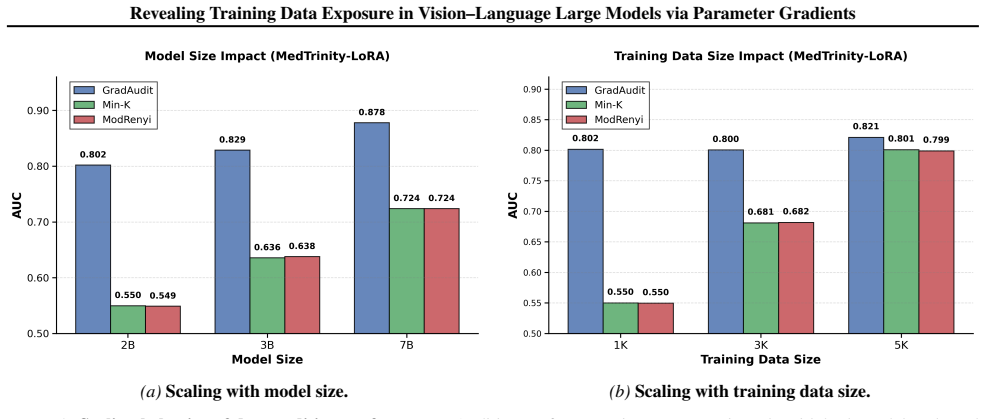
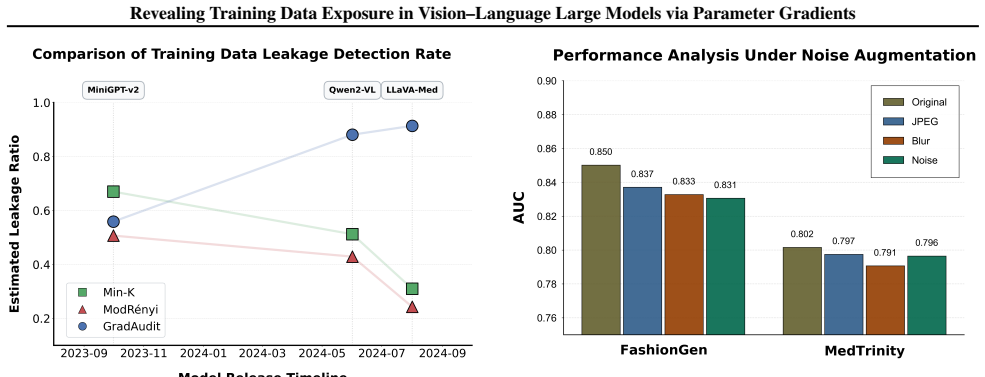
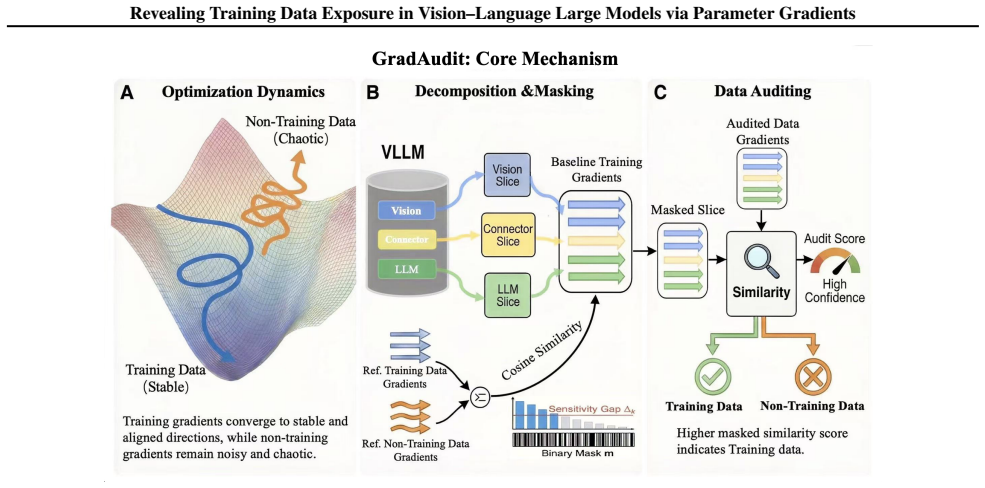
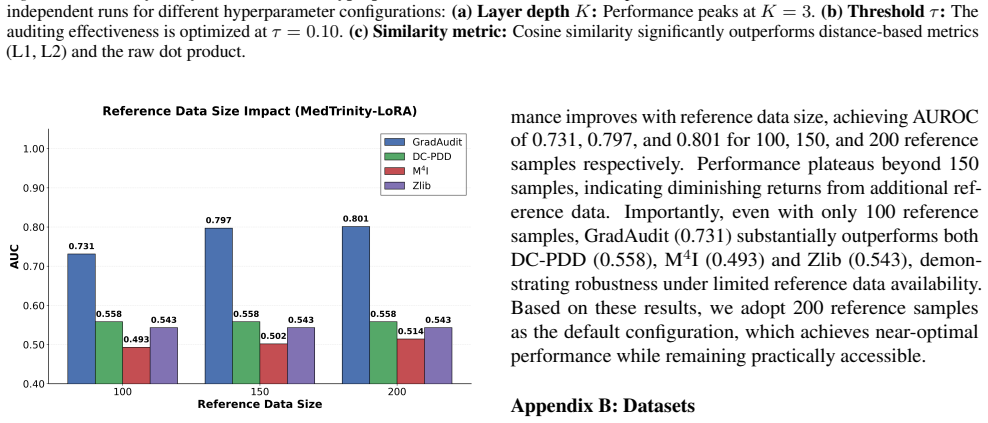
The central discovery is that VLLM parameters converge such that gradients on training image-text pairs become stable and well-aligned, unlike the inconsistent gradients on non-training pairs. GradAudit leverages these signatures to audit for training data exposure, detecting cross-modal associations rather than just modality membership. It outperforms baselines empirically and demonstrates underestimation of data usage by prior methods, particularly in recent advanced models.
What carries the argument
GradAudit, the gradient-based auditing framework that examines internal optimization dynamics through analysis of gradient stability and alignment on candidate image-text pairs.
If this is right
- If correct, GradAudit enables detection of training data without relying on output signals or black-box access.
- The method can be applied to both pretraining and fine-tuning stages of VLLMs.
- It reveals that existing methods underestimate unauthorized data usage, with the gap increasing for more advanced models.
- Particularly useful for healthcare to safeguard patient medical image-report pairs.
Where Pith is reading between the lines
- Similar gradient auditing could be applied to other multimodal large models to check data provenance.
- Model providers might integrate gradient checks to certify training data origins.
- Further experiments could test the method's robustness on very large scale models or different architectures.
Load-bearing premise
The key observation that model parameters converge to regions where gradients on training samples become stable and well-aligned, whereas gradients on non-training samples remain noisy and inconsistent, holds reliably enough to enable detection of training data exposure.
What would settle it
A direct comparison showing equivalent gradient stability and alignment for both training and non-training image-text pairs in a trained VLLM would falsify the approach.
Figures


read the original abstract
Vision-Language Large Models (VLLMs) trained on massive crawled corpora raise pressing copyright and data-provenance concerns. These concerns are particularly acute in healthcare, where patient medical images paired with clinical reports demand rigorous privacy safeguards. However, existing training data detection methods either fail in cross-modal scenarios or rely on superficial output signals with insufficient discriminative power. We introduce GradAudit, a gradient-based auditing framework that examines internal optimization dynamics rather than treating VLLMs as black boxes. Our approach builds on a key observation: model parameters converge to regions where gradients on training samples become stable and well-aligned, whereas gradients on non-training samples remain noisy and inconsistent. By analyzing these gradient signatures, GradAudit achieves strong separability and detects genuine image-text associations learned during training, not merely individual modality membership. Empirically, across both medical and general-domain datasets, GradAudit substantially outperforms state-of-the-art baselines in both pretraining and fine-tuning VLLMs. In a case study employing copyrighted content, we show that existing training data detection methods not only underestimate the extent of unauthorized data usage, but that this underestimation becomes more pronounced as models become more recent and more advanced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GradAudit, a gradient-based auditing framework for detecting training data exposure in Vision-Language Large Models (VLLMs). It is grounded in the observation that converged model parameters produce stable, well-aligned gradients on training samples but noisy, inconsistent gradients on non-training samples. This signature is used to identify genuine image-text associations learned during training (rather than single-modality membership). The approach is evaluated across medical and general-domain datasets for both pretraining and fine-tuning regimes, with claims of substantial outperformance over state-of-the-art baselines; a case study on copyrighted content further argues that existing methods underestimate unauthorized data usage, with the gap widening for more recent models.
Significance. If the gradient-stability observation and separability results hold under rigorous validation, the work would be significant for privacy, copyright, and data-provenance auditing in multimodal models, especially in regulated domains such as healthcare. The internal, optimization-dynamics perspective is a clear departure from black-box output-signal methods and could inform future auditing tools.
minor comments (1)
- The provided manuscript text consists only of the abstract; without access to the methods, experimental protocols, dataset descriptions, quantitative results, or ablation studies, the soundness of the central empirical claims cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their review of our manuscript on GradAudit. The report provides a clear summary of our contributions and notes the potential significance for privacy and copyright auditing in VLLMs, particularly in healthcare. We note that the recommendation is listed as uncertain, but no specific major comments were enumerated in the provided report. We are prepared to address any additional points or clarifications the referee may have.
Circularity Check
No significant circularity
full rationale
The paper introduces GradAudit as an empirical auditing method grounded in the observed property that gradients on training samples stabilize while those on non-training samples remain noisy. This observation is presented as a starting point for experiments across datasets, with performance claims validated by direct comparison to baselines rather than any derivation that reduces to fitted parameters, self-definitions, or self-citation chains. No equations or steps in the provided abstract or described approach equate outputs to inputs by construction; the work is self-contained as an observational detection technique without load-bearing reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
2023
-
[2]
Editorial. A data-driven look at ai’s transformative impact on the future of science.Nature Research In- telligence, 631:S16–S17, 2025. doi: 10.1038/d42473- 025-00164-0. URL https://www.nature.com/ articles/d42473-025-00164-0
-
[3]
Minigpt-4: Enhancing vision- language understanding with advanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision- language understanding with advanced large language models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[4]
Vision-language models for vision tasks: A survey
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey. IEEE transactions on pattern analysis and machine intelligence, 46(8):5625–5644, 2024
2024
-
[5]
Scal- ing up vision-language pre-training for image caption- ing
Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. Scal- ing up vision-language pre-training for image caption- ing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17980– 17989, 2022
2022
-
[6]
Prompt-rsvqa: Prompting visual context to a language model for re- mote sensing visual question answering
Christel Chappuis, Val´erie Zermatten, Sylvain Lobry, Bertrand Le Saux, and Devis Tuia. Prompt-rsvqa: Prompting visual context to a language model for re- mote sensing visual question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1372–1381, 2022
2022
-
[7]
Jiannan Wu, Muyan Zhong, Sen Xing, Zeqiang Lai, Zhaoyang Liu, Zhe Chen, Wenhai Wang, Xizhou Zhu, Lewei Lu, Tong Lu, et al. Visionllm v2: An end-to- end generalist multimodal large language model for hundreds of vision-language tasks.Advances in Neu- ral Information Processing Systems, 37:69925–69975, 2024
2024
-
[8]
The growing data privacy con- cerns with ai: What you need to know
DataGuard. The growing data privacy con- cerns with ai: What you need to know. https://www.dataguard.com/blog/ growing-data-privacy-concerns-ai/ ,
-
[9]
Google and the uni- versity of chicago are sued over data shar- ing.The New York Times, June 2019
Wakabayashi Daisuke. Google and the uni- versity of chicago are sued over data shar- ing.The New York Times, June 2019. URL https://www.nytimes.com/2019/06/ 26/technology/google-university- chicago-data-sharing-lawsuit.html
2019
-
[10]
Amazon may launch a market- place where media sites can sell their content to ai companies
Lucas Ropek. Amazon may launch a market- place where media sites can sell their content to ai companies. https://techcrunch.com/ 2025/11/03/studio-ghibli-and-other- japanese-publishers-want-openai-to- stop-training-on-their-work/ , 2026. Accessed: 2026
2025
-
[11]
Getty images v
UK Judiciary. Getty images v. stability AI judgment. https://www.judiciary.uk/ wp-content/uploads/2025/11/Getty- Images-v-Stability-AI.pdf , 2025. Ac- cessed: 2025
2025
-
[12]
A unified method to revoke the private data of patients in intelligent healthcare with audit to forget.Nature Communications, 14(1):6255, 2023
Juexiao Zhou, Haoyang Li, Xingyu Liao, Bin Zhang, Wenjia He, Zhongxiao Li, Longxi Zhou, and Xin Gao. A unified method to revoke the private data of patients in intelligent healthcare with audit to forget.Nature Communications, 14(1):6255, 2023
2023
-
[13]
Towards trans- parency by design for artificial intelligence.Science and engineering ethics, 26(6):3333–3361, 2020
Heike Felzmann, Eduard Fosch-Villaronga, Christoph Lutz, and Aurelia Tam `o-Larrieux. Towards trans- parency by design for artificial intelligence.Science and engineering ethics, 26(6):3333–3361, 2020
2020
-
[14]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[15]
Canary in a coalmine: Better membership in- ference with ensembled adversarial queries
Yuxin Wen, Arpit Bansal, Hamid Kazemi, Eitan Borg- nia, Micah Goldblum, Jonas Geiping, and Tom Gold- stein. Canary in a coalmine: Better membership in- ference with ensembled adversarial queries. InThe Eleventh International Conference on Learning Repre- sentations, 2023. 11 Revealing Training Data Exposure in Vision–Language Large Models via Parameter Gradients
2023
-
[16]
Membership inference attacks against large vision-language models
Zhan Li, Yongtao Wu, Yihang Chen, Francesco Tonin, Elias Abad Rocamora, and V olkan Cevher. Membership inference attacks against large vision-language models. Advances in Neural Information Processing Systems, 37:98645–98674, 2024
2024
-
[17]
The inverse variance–flatness relation in stochastic gradient descent is critical for find- ing flat minima.Proceedings of the National Academy of Sciences, 118:e2015617118, 2021
Yu Feng and Yuhai Tu. The inverse variance–flatness relation in stochastic gradient descent is critical for find- ing flat minima.Proceedings of the National Academy of Sciences, 118:e2015617118, 2021
2021
-
[18]
Com- prehensive privacy analysis of deep learning
Milad Nasr, Reza Shokri, and Amir Houmansadr. Com- prehensive privacy analysis of deep learning. InPro- ceedings of the 2019 IEEE Symposium on Security and Privacy (SP), volume 2018, pages 1–15, 2018
2019
-
[19]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915, 2023
Pith/arXiv arXiv 2023
-
[20]
Sedigheh Eslami, Christoph Meinel, and Gerard De Melo. Pubmedclip: How much does clip bene- fit visual question answering in the medical domain? InFindings of the Association for Computational Lin- guistics: EACL 2023, pages 1181–1193, 2023
2023
-
[21]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
2022
-
[22]
Llava- med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Infor- mation Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Nau- mann, Hoifung Poon, and Jianfeng Gao. Llava- med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Infor- mation Processing Systems, 36:28541–28564, 2023
2023
-
[23]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhi- hao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolu- tion.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[24]
Pmc- clip: Contrastive language-image pre-training using biomedical documents
Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc- clip: Contrastive language-image pre-training using biomedical documents. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 525–536. Springer, 2023
2023
-
[25]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[26]
Seco de Herrera, et al
Johannes R ¨uckert, Louise Bloch, Raphael Br ¨ungel, Ahmad Idrissi-Yaghir, Henning Sch ¨afer, Cynthia S Schmidt, Sven Koitka, Obioma Pelka, Asma Ben Abacha, Alba G. Seco de Herrera, et al. Rocov2: Radiol- ogy objects in context version 2, an updated multimodal image dataset.Scientific Data, 11(1):688, 2024
2024
-
[27]
Medtrinity-25m: A large-scale multimodal dataset with multigranular annotations for medicine
Yunfei Xie, Ce Zhou, Lang Gao, Juncheng Wu, Xian- hang Li, Hong-Yu Zhou, Sheng Liu, Lei Xing, James Zou, Cihang Xie, et al. Medtrinity-25m: A large-scale multimodal dataset with multigranular annotations for medicine. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Fashion-gen: The genera- tive fashion dataset and challenge.arXiv preprint arXiv:1806.08317, 2018
Negar Rostamzadeh, Seyedarian Hosseini, Thomas Boquet, Wojciech Stokowiec, Ying Zhang, Christian Jauvin, and Chris Pal. Fashion-gen: The genera- tive fashion dataset and challenge.arXiv preprint arXiv:1806.08317, 2018
Pith/arXiv arXiv 2018
-
[29]
Lora: Low-rank adaptation of large lan- guage models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large lan- guage models.ICLR, 1(2):3, 2022
2022
-
[30]
Privacy risk in machine learning: Analyz- ing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyz- ing the connection to overfitting. In2018 IEEE 31st computer security foundations symposium (CSF), pages 268–282. IEEE, 2018
2018
-
[31]
Systematic evaluation of privacy risks of machine learning models
Liwei Song and Prateek Mittal. Systematic evaluation of privacy risks of machine learning models. In30th USENIX security symposium (USENIX security 21), pages 2615–2632, 2021
2021
-
[32]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlings- son, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[33]
Min-k%++: Improved baseline for pre-training data de- tection from large language models
Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Frank Yang, and Hai Li. Min-k%++: Improved baseline for pre-training data de- tection from large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[34]
Pretraining data detection for large language models: A divergence- based calibration method
Weichao Zhang, Ruqing Zhang, Jiafeng Guo, Maarten Rijke, Yixing Fan, and Xueqi Cheng. Pretraining data detection for large language models: A divergence- based calibration method. InProceedings of the 2024 12 Revealing Training Data Exposure in Vision–Language Large Models via Parameter Gradients Conference on Empirical Methods in Natural Language Process...
2024
-
[35]
Zongyu Wu, Minhua Lin, Zhiwei Zhang, Fali Wang, Xianren Zhang, Xiang Zhang, and Suhang Wang. Im- age corruption-inspired membership inference attacks against large vision-language models.arXiv preprint arXiv:2506.12340, 2025
arXiv 2025
-
[36]
M 4i: Multi-modal models membership inference.Advances in Neural Information Processing Systems, 35:1867–1882, 2022
Pingyi Hu, Zihan Wang, Ruoxi Sun, Hu Wang, and Minhui Xue. M 4i: Multi-modal models membership inference.Advances in Neural Information Processing Systems, 35:1867–1882, 2022
2022
-
[37]
Temporal scaling law for large language models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Wei Huang, Jianwei Niu, Jungong Han, et al. Temporal scaling law for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24474–24494, 2025
2025
-
[38]
Scal- ing laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scal- ing laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[39]
Identifying pre-training data in llms: A neuron activation-based detection framework
Hongyi Tang, Zhihao Zhu, and Yi Yang. Identifying pre-training data in llms: A neuron activation-based detection framework. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 18738–18751, 2025
2025
-
[40]
Studio ghibli image-caption dataset
Nechintosh. Studio ghibli image-caption dataset. https://huggingface.co/datasets/ Nechintosh/ghibli, 2025. Accessed: 2026
2025
-
[41]
Mmbench: Is your multi-modal model an all-around player? InEu- ropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEu- ropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[42]
Vlmevalkit: An open- source toolkit for evaluating large multi-modality mod- els
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open- source toolkit for evaluating large multi-modality mod- els. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024
2024
-
[43]
The size of datasets used to train language models doubles approximately every six months, 2024
Robi Rahman and David Owen. The size of datasets used to train language models doubles approximately every six months, 2024. URLhttps://epoch.ai/ data-insights/dataset-size-trend . Ac- cessed: 2026-02-10
2024
-
[44]
Quantifying memorization across neural language mod- els
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language mod- els. InThe Eleventh International Conference on Learn- ing Representations, 2022
2022
-
[45]
Adversarial prompt and fine-tuning attacks threaten medical large language models.Nature Communica- tions, 16(1):9011, 2025
Yifan Yang, Qiao Jin, Furong Huang, and Zhiyong Lu. Adversarial prompt and fine-tuning attacks threaten medical large language models.Nature Communica- tions, 16(1):9011, 2025
2025
-
[46]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vi- taly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[47]
Memguard: Defend- ing against black-box membership inference attacks via adversarial examples
Jinyuan Jia, Ahmed Salem, Michael Backes, Yang Zhang, and Neil Zhenqiang Gong. Memguard: Defend- ing against black-box membership inference attacks via adversarial examples. InProceedings of the 2019 ACM SIGSAC conference on computer and communications security, pages 259–274, 2019
2019
-
[48]
Con-recall: Detect- ing pre-training data in llms via contrastive decoding
Cheng Wang, Yiwei Wang, Bryan Hooi, Yujun Cai, Nanyun Peng, and Kai-Wei Chang. Con-recall: Detect- ing pre-training data in llms via contrastive decoding. InProceedings of the 31st International Conference on Computational Linguistics, pages 1013–1026, 2025
2025
-
[49]
Ar- tificial intelligence and the future of the internal audit function.Humanities and Social Sciences Communica- tions, 11(1):1–13, 2024
Fekadu Agmas Wassie and L´aszl´o P´eter Lakatos. Ar- tificial intelligence and the future of the internal audit function.Humanities and Social Sciences Communica- tions, 11(1):1–13, 2024
2024
-
[50]
Outsider oversight: Designing a third party audit ecosystem for ai governance
Inioluwa Deborah Raji, Peggy Xu, Colleen Honigsberg, and Daniel Ho. Outsider oversight: Designing a third party audit ecosystem for ai governance. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, pages 557–571, 2022
2022
-
[51]
Foundation models defining a new era in vision: a sur- vey and outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Muhammad Awais, Muzammal Naseer, Salman Khan, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Foundation models defining a new era in vision: a sur- vey and outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[52]
Parameter-efficient fine-tuning of large-scale pre-trained language models
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zong- han Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature machine intelligence, 5(3):220–235, 2023
2023
-
[53]
Network dissection: Quantify- ing interpretability of deep visual representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantify- ing interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6541–6549, 2017. 13 Revealing Training Data Exposure in Vision–Language Large Models via Parameter Gradients
2017
-
[54]
Gradsafe: detecting unsafe prompts for llms via safety- critical gradient analysis
Yueqi Xie, Minghong Fang, Renjie Pi, and Neil Gong. Gradsafe: detecting unsafe prompts for llms via safety- critical gradient analysis. InProc. 62nd Annual Meeting of the Association for Computational Linguistics (Long Papers), 2024
2024
-
[55]
Gaprune: Gradient- alignment pruning for domain-aware embeddings
Yixuan Tang and Yi Yang. Gaprune: Gradient- alignment pruning for domain-aware embeddings. arXiv preprint arXiv:2509.10844, 2025
arXiv 2025
-
[56]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[57]
Reference
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.Transactions on Machine Learning Research, 2024. Author contributions Y .Y . led the research project. Y .Y . and Z.Z. conceived the idea of this work. H.T. implemented the models and con- ducted all experiments. Z.Z. a...
2024
-
[58]
Parameters are estimated via Expectation- Maximization (EM) with the clean component fixed
represents the clean component (estimated from ∆null and held fixed), p1(∆) =N(µ 1, σ2 1) represents the leak component, and π denotes the mix- ture weight. Parameters are estimated via Expectation- Maximization (EM) with the clean component fixed. 18 Revealing Training Data Exposure in Vision–Language Large Models via Parameter Gradients Algorithm 1 Grad...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.