SHERLOC: Structured Diagnostic Localization for Code Repair Agents
Pith reviewed 2026-06-25 23:45 UTC · model grok-4.3
The pith
SHERLOC supplies repair agents with diagnostic fault locations that raise resolve rates and cut token use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
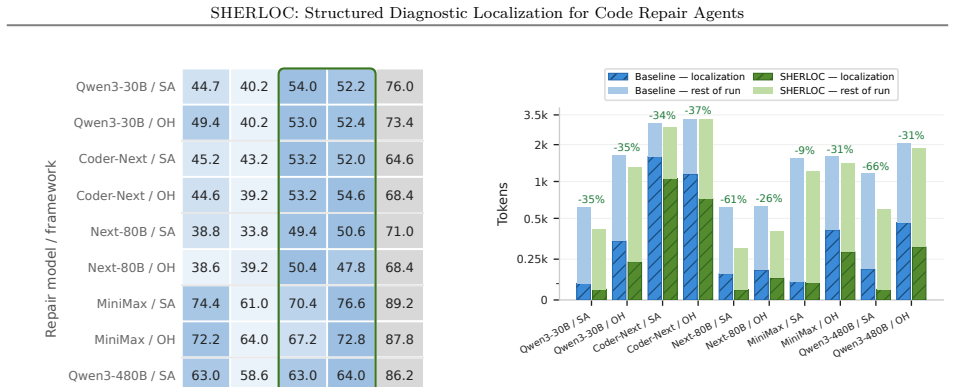
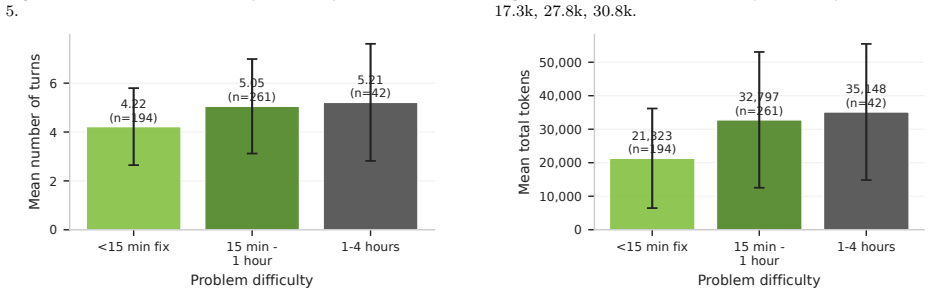
SHERLOC reaches 84.33% accuracy@1 on SWE-Bench Lite and 81.27% recall@1 on SWE-Bench Verified across model scales; at roughly 30B parameters it matches or exceeds other agentic localization methods. When its locations and diagnostic findings are injected into repair agents, resolve rate on SWE-Bench Verified rises by 5.95 percentage points on average while localization tokens drop 36.7% and total tokens drop 23.1%.
What carries the argument
SHERLOC, a training-free framework that pairs hypothesis-driven exploration by a reasoning LLM with compact repository tools and a self-recovery loop to produce actionable diagnostic locations.
If this is right
- Repair agents achieve measurably higher success on repository-level coding tasks.
- Localization and total token budgets shrink by roughly one-third and one-quarter respectively.
- Localization accuracy holds or improves as model size increases to around 30B parameters.
- Diagnostic context makes raw file locations more immediately usable for editing steps.
Where Pith is reading between the lines
- The same structured hypothesis-and-recovery pattern could reduce wasted steps in other multi-turn agent domains that currently spend budget on search without diagnosis.
- Testing whether the self-recovery mechanism transfers to repositories outside the SWE-Bench distribution would clarify its robustness.
- Combining the training-free outputs with light fine-tuning on the diagnostic format might compound the observed gains.
Load-bearing premise
The diagnostic context and locations generated by SHERLOC can be used directly by downstream repair agents without further adaptation or that the self-recovery step reliably fixes errors on unseen repositories.
What would settle it
Running SHERLOC-augmented repair agents on a fresh collection of repositories and observing no gain in resolve rate or no reduction in token consumption.
Figures











read the original abstract
LLM agents solve repository-level coding tasks through multi-turn tool use, but utilize half their budget on locating faults before editing. Dedicated localization frameworks have emerged, yet are still evaluated as file retrieval rather than actionable diagnosis, producing locations without the diagnostic context a repair agent needs. We introduce SHERLOC (Structured Hypothesis-driven Exploration and Reasoning for Localization), a training-free framework pairing a reasoning LLM with compact repository tools and self-recovery, without fine-tuning or multi-agent orchestration. SHERLOC reaches state-of-the-art localization across model scales: 84.33% accuracy@1 on SWE-Bench Lite and 81.27% recall@1 on SWE-Bench Verified; at ~30B parameters, it matches or outperforms other agentic methods. Injecting our locations and diagnostic findings into repair agents yields, on average, +5.95 pp resolve rate on SWE-Bench Verified while cutting localization and total tokens by 36.7% and 23.1%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SHERLOC, a training-free framework that pairs a reasoning LLM with compact repository tools and a self-recovery mechanism to perform structured hypothesis-driven localization for repository-level code repair. It reports SOTA localization results (84.33% accuracy@1 on SWE-Bench Lite; 81.27% recall@1 on SWE-Bench Verified) across model scales and claims that injecting the produced locations plus diagnostic findings into existing repair agents yields an average +5.95 pp resolve-rate lift on SWE-Bench Verified together with 36.7% and 23.1% reductions in localization and total tokens.
Significance. If the empirical claims are substantiated, the work would be significant for agentic coding systems: it reframes localization as the production of actionable diagnostic hypotheses rather than simple file retrieval, demonstrates training-free scaling, and quantifies downstream efficiency and accuracy gains on public benchmarks. The absence of fine-tuning or multi-agent orchestration is a practical strength.
major comments (3)
- [Abstract] Abstract: the central practical claim (+5.95 pp resolve-rate improvement and token savings) rests on the assumption that SHERLOC's structured diagnostic outputs are directly consumable by downstream repair agents without reformatting or additional adaptation; the manuscript supplies no interface specification, consumption protocol, or ablation demonstrating plug-and-play usage.
- [Abstract] Abstract / Evaluation section: the self-recovery mechanism is invoked to correct localization errors, yet no error analysis, failure-case breakdown, or out-of-distribution evaluation on repositories beyond the SWE-Bench distribution is reported; without this, the transferability of both the localization numbers and the downstream gains cannot be assessed.
- [Abstract] Abstract: concrete benchmark numbers are given but the manuscript provides no methodological details, ablation studies, or implementation description of the hypothesis generation, tool use, or recovery loop, rendering the soundness of the reported accuracy@1 and recall@1 figures impossible to verify from the supplied text.
minor comments (2)
- [Abstract] Abstract: the precise definitions of accuracy@1 and recall@1 (e.g., whether they are file-level, function-level, or line-level) should be stated explicitly.
- The paper would benefit from a short related-work table contrasting SHERLOC against prior localization-only baselines on the same SWE-Bench splits.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below with clarifications from the full text and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central practical claim (+5.95 pp resolve-rate improvement and token savings) rests on the assumption that SHERLOC's structured diagnostic outputs are directly consumable by downstream repair agents without reformatting or additional adaptation; the manuscript supplies no interface specification, consumption protocol, or ablation demonstrating plug-and-play usage.
Authors: The evaluation section describes the direct injection of SHERLOC's locations and diagnostic findings into repair agents to produce the reported gains. To strengthen clarity, we will add an explicit interface specification, consumption protocol, and a dedicated ablation on plug-and-play usage in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract / Evaluation section: the self-recovery mechanism is invoked to correct localization errors, yet no error analysis, failure-case breakdown, or out-of-distribution evaluation on repositories beyond the SWE-Bench distribution is reported; without this, the transferability of both the localization numbers and the downstream gains cannot be assessed.
Authors: Section 3.3 details the self-recovery mechanism and its role in error correction. We agree that a failure-case breakdown would improve the paper and will add one in revision. A full OOD evaluation on non-SWE-Bench repositories lies outside the current experimental scope but we will discuss transferability implications. revision: partial
-
Referee: [Abstract] Abstract: concrete benchmark numbers are given but the manuscript provides no methodological details, ablation studies, or implementation description of the hypothesis generation, tool use, or recovery loop, rendering the soundness of the reported accuracy@1 and recall@1 figures impossible to verify from the supplied text.
Authors: Sections 3 and 4 of the full manuscript supply the methodological details on hypothesis generation, tool use, the recovery loop, and supporting ablations. The abstract is a concise summary; we will expand implementation descriptions if needed for easier verification in the revision. revision: yes
Circularity Check
No circularity: empirical framework with benchmark evaluations only
full rationale
The paper introduces a training-free localization framework and reports accuracy/recall numbers plus downstream resolve-rate gains on public SWE-Bench benchmarks. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. All performance claims rest on external, independently verifiable test sets rather than any reduction of outputs to inputs by construction. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SWE-Bench Lite and Verified are appropriate proxies for measuring actionable diagnostic localization in code repair agents.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. 2025 , eprint=
2025
-
[2]
2024 , eprint=
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? , author=. 2024 , eprint=
2024
-
[3]
2024 , eprint=
Agentless: Demystifying LLM-based Software Engineering Agents , author=. 2024 , eprint=
2024
-
[4]
2024 , eprint=
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , author=. 2024 , eprint=
2024
-
[5]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[6]
2025 , eprint=
SweRank: Software Issue Localization with Code Ranking , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
Tool-integrated Reinforcement Learning for Repo Deep Search , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
PatchPilot: A Cost-Efficient Software Engineering Agent with Early Attempts on Formal Verification , author=. 2025 , eprint=
2025
-
[9]
arXiv preprint arXiv:2507.23348 , year=
Swe-debate: Competitive multi-agent debate for software issue resolution , author=. arXiv preprint arXiv:2507.23348 , year=
-
[10]
arXiv preprint arXiv:2502.00350 , year=
Orcaloca: An llm agent framework for software issue localization , author=. arXiv preprint arXiv:2502.00350 , year=
-
[11]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[12]
Proceedings of the 24th International Conference on Software Engineering (ICSE) , pages=
Visualization of test information to assist fault localization , author=. Proceedings of the 24th International Conference on Software Engineering (ICSE) , pages=
-
[13]
Testing: Academic and Industrial Conference Practice and Research Techniques , pages=
On the accuracy of spectrum-based fault localization , author=. Testing: Academic and Industrial Conference Practice and Research Techniques , pages=. 2007 , publisher=
2007
-
[14]
Proceedings of the IEEE International Conference on Software Testing, Verification and Validation (ICST) , pages=
Ask the mutants: Mutating faulty programs for fault localization , author=. Proceedings of the IEEE International Conference on Software Testing, Verification and Validation (ICST) , pages=
-
[15]
Software Testing, Verification and Reliability , volume=
Metallaxis-FL: mutation-based fault localization , author=. Software Testing, Verification and Reliability , volume=
-
[16]
Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA) , pages=
DeepFL: Integrating multiple fault diagnosis dimensions for deep fault localization , author=. Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA) , pages=
-
[17]
Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) , pages=
Boosting coverage-based fault localization via graph-based representation learning , author=. Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) , pages=
-
[18]
2025 , eprint=
CoSIL: Issue Localization via LLM-Driven Code Graph Searching , author=. 2025 , eprint=
2025
-
[19]
2025 , howpublished=
GPT-5 System Card , author=. 2025 , howpublished=
2025
-
[20]
2025 , howpublished=
2025
-
[21]
Proceedings of the 34th International Conference on Software Engineering (ICSE) , pages=
Where should the bugs be fixed? More accurate information retrieval-based bug localization based on bug reports , author=. Proceedings of the 34th International Conference on Software Engineering (ICSE) , pages=
-
[22]
2024 , eprint=
SGLang: Efficient Execution of Structured Language Model Programs , author=. 2024 , eprint=
2024
-
[23]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[24]
2022 , url=
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , journal=. 2022 , url=
2022
-
[25]
arXiv preprint arXiv:2302.04761 , year=
Toolformer: Language models can teach themselves to use tools , author=. arXiv preprint arXiv:2302.04761 , year=
-
[26]
2025 , eprint=
The SWE-Bench Illusion: When State-of-the-Art LLMs Remember Instead of Reason , author=. 2025 , eprint=
2025
-
[27]
LocAgent: Graph-Guided LLM Agents for Code Localization , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , publisher=. doi:10.18653/v1/2025.acl-long.426 , url=
-
[28]
Proceedings of the ACM on Software Engineering , volume=
A Quantitative and Qualitative Evaluation of LLM-Based Explainable Fault Localization , author=. Proceedings of the ACM on Software Engineering , volume=. 2024 , doi=
2024
-
[29]
Proceedings of the 28th IEEE/ACM International Conference on Automated Software Engineering , pages=
Improving Bug Localization Using Structured Information Retrieval , author=. Proceedings of the 28th IEEE/ACM International Conference on Automated Software Engineering , pages=
-
[30]
Proceedings of the 22nd International Conference on Program Comprehension , pages=
Version History, Similar Report, and Structure: Putting Them Together for Improved Bug Localization , author=. Proceedings of the 22nd International Conference on Program Comprehension , pages=
-
[31]
2024 , eprint=
AutoCodeRover: Autonomous Program Improvement , author=. 2024 , eprint=
2024
-
[32]
2025 , eprint=
Training Software Engineering Agents and Verifiers with SWE-Gym , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
Executable Code Actions Elicit Better LLM Agents , author=. 2024 , eprint=
2024
-
[34]
2025 , eprint=
SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
SWE-bench Goes Live! , author=. 2025 , eprint=
2025
-
[36]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Thought Calibration: Efficient and Confident Test-Time Scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , publisher=. doi:10.18653/v1/2025.emnlp-main.722 , url=
-
[37]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
T ^2 : An Adaptive Test-Time Scaling Strategy for Contextual Question Answering , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , publisher=. doi:10.18653/v1/2025.emnlp-main.185 , url=
-
[38]
2024 , eprint=
DeepSeek-V3 Technical Report , author=. 2024 , eprint=
2024
-
[39]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[40]
Claude 3.5 Sonnet , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.