Sequential Probability Ratio Test using Z-Statistics (SPRT-z): A Practical Approach for Online Experimentation
Pith reviewed 2026-06-25 22:08 UTC · model grok-4.3
The pith
SPRT-z revives the sequential probability ratio test for online A/B experiments by adding Z-statistic approximations, futility stopping, and bias correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPRT-z is an adaptation of Hajnal's sequential t-test that replaces the exact t-distribution with the large-sample normal approximation, thereby enabling Brownian-motion calibration and estimation procedures; when paired with Scale-Free Horizon Calibration and the Brownian median unbiased estimator, the resulting workflow controls both error types, supports early futility stopping tied to a minimum detectable effect, and corrects the estimation bias induced by optional stopping across all stopping regions.
What carries the argument
SPRT-z, the Z-statistic form of the sequential probability ratio test that replaces exact distributions with the normal approximation so that Brownian-motion techniques can be used for horizon calibration and bias-corrected inference.
If this is right
- Early stopping for futility becomes feasible without inflating Type I error.
- Launch decisions can be tied directly to a pre-specified minimum detectable effect while still controlling power.
- Point estimates and confidence intervals after early stopping exhibit reduced bias and near-nominal coverage.
- Expected sample size is smaller than under fixed-horizon testing at the same error rates.
Where Pith is reading between the lines
- If the normal approximation proves robust, the same calibration and ordering ideas could be ported to sequential tests for non-normal outcomes such as conversion rates or count data.
- The six-region stagewise ordering may offer a template for bias correction in other sequential designs that allow both efficacy and futility boundaries.
- Performance under model misspecification or dependence between successive observations remains an open question that could be checked with targeted simulations.
Load-bearing premise
The large-sample normal approximation stays accurate enough under the discrete monitoring and early-stopping schedules that occur in real A/B tests, and the Monte Carlo bisection correctly finds the maximum sample size that preserves nominal power when futility stopping is active.
What would settle it
A Monte Carlo experiment that applies the full SPRT-z workflow to data generated under the null and finds that the realized Type I error rate substantially exceeds the nominal alpha level.
Figures

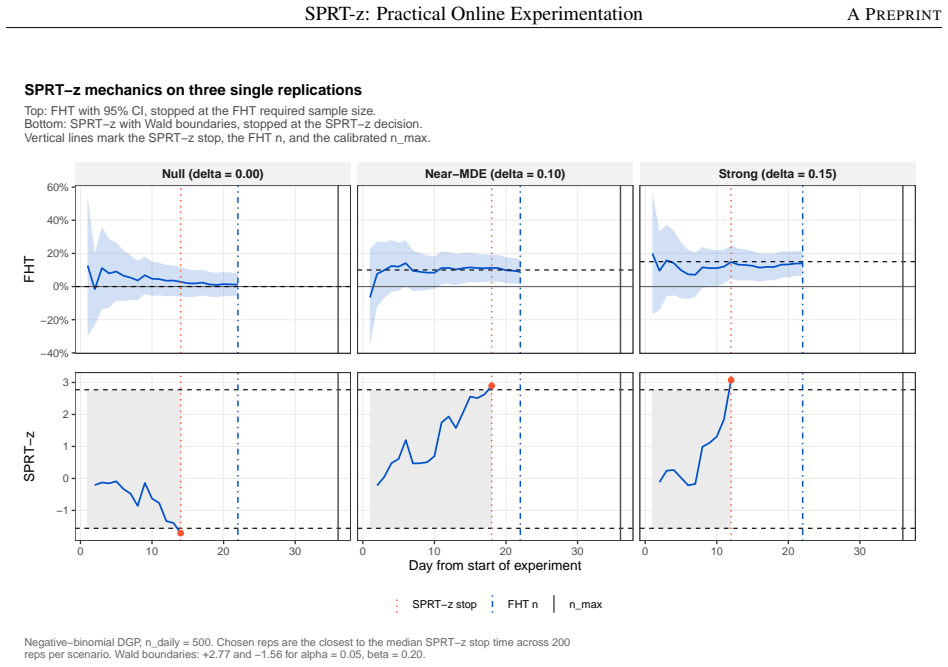
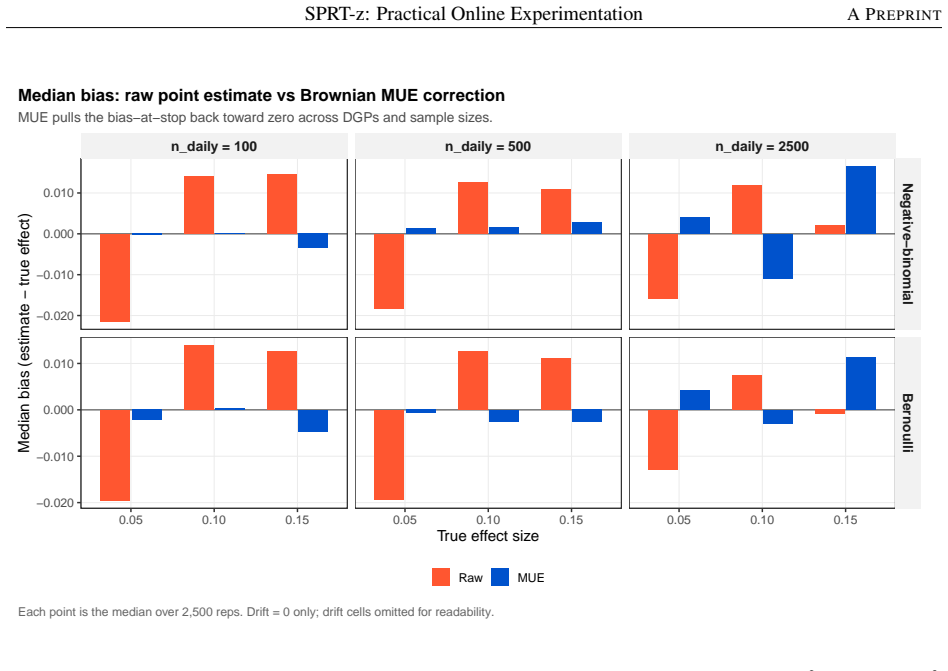
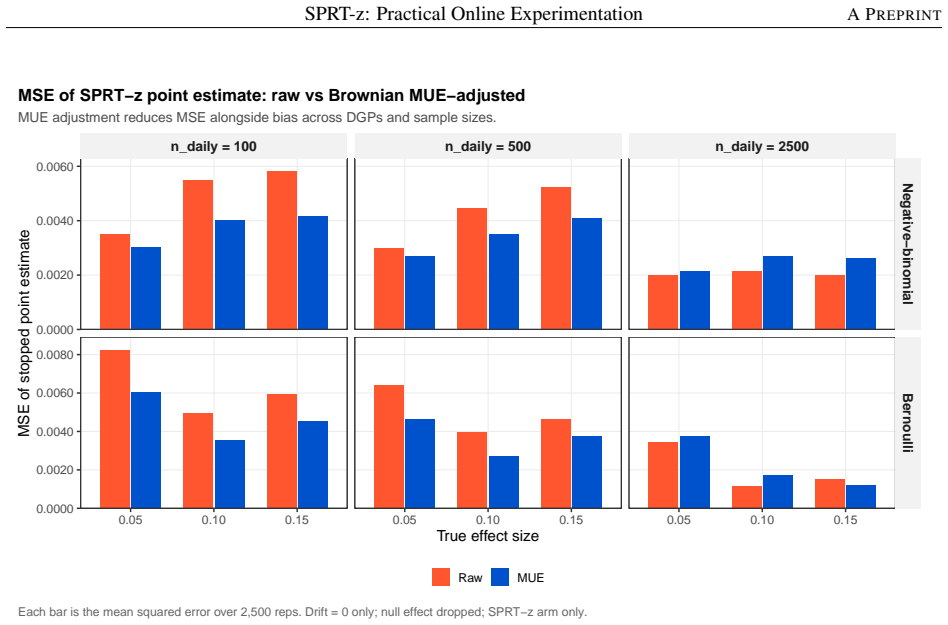
read the original abstract
Modern online experimentation platforms produce data at scale and continuously. However, practitioners routinely apply Fixed Horizon Testing (FHT) under repeated peeking, inflating Type I error and reducing decision quality. Popular always valid sequential methods control Type I error under peeking and enable early stopping for efficacy, but do not natively support early futility stopping, launch criteria tied to a business-relevant minimum detectable effect, or Type II error control. As an alternative that satisfies these useful properties, we revive Wald's Sequential Probability Ratio Test (SPRT) for online experimentation with three novel contributions: (1) SPRT-z, an adaptation of Hajnal's sequential $t$-test, leverages large sample normal approximation to eliminate computational bottlenecks inherent to the scale of modern A/B tests and enables the Brownian motion-based methods used in (2) and (3); (2) Scale-Free Horizon Calibration (SFHC) is a Monte Carlo bisection procedure on the standardised $Z$-scale that sets a maximum sample size preserving nominal power under discrete monitoring with futility stopping; (3) A Brownian Median Unbiased Estimator and accompanying confidence intervals correct the upward bias induced by early stopping across all stopping regions via a six-region stagewise ordering of the sample space. A simulation study shows this workflow appropriately controls Type I and II error, reduces sample size relative to FHT, and ameliorates estimation bias from early stopping with close-to-nominal confidence interval coverage in most scenarios studied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPRT-z, an adaptation of Wald's SPRT using large-sample Z-statistics (via Hajnal's sequential t-test approximation) for online A/B testing. It adds (1) Scale-Free Horizon Calibration (SFHC), a Monte Carlo bisection on the Z-scale to choose maximum sample size that preserves nominal power under discrete monitoring with futility stopping; (2) a Brownian-motion median-unbiased estimator with six-region stagewise ordering of the sample space to produce bias-corrected point estimates and confidence intervals after early stopping. A simulation study is reported to demonstrate Type I/II error control, sample-size savings versus fixed-horizon testing, and near-nominal CI coverage.
Significance. If the large-sample normal approximation and the SFHC calibration remain accurate under realistic discrete peeking and futility boundaries, the workflow supplies a practical, computationally lightweight sequential procedure that simultaneously controls both error rates, supports business-relevant launch criteria, and supplies bias-corrected inference—features missing from most always-valid sequential methods currently deployed in online experimentation platforms. The explicit Monte Carlo calibration and the stagewise ordering for median-unbiased estimation are concrete, reproducible contributions.
major comments (2)
- [Abstract, §4] Abstract and §4 (simulation design): the reported error-rate control, power preservation, and CI coverage rest on Monte Carlo experiments whose data-generating processes, exact parameter grids, exclusion rules for early stopping, and number of replications are not specified. Without these details it is impossible to determine whether the claimed performance is robust or sensitive to post-hoc choices in the simulation protocol.
- [§2, §3] §2 (SPRT-z derivation) and §3 (SFHC): the entire workflow invokes the continuous-time Brownian-motion approximation for the discrete Z-process under early futility stopping. No analytic error bounds, Edgeworth expansions, or direct comparisons against exact binomial or hypergeometric sequential tests are supplied to quantify the approximation error at the finite N values returned by SFHC. If the error is non-negligible, both the calibrated thresholds and the six-region CI construction can fail to deliver nominal coverage.
minor comments (2)
- [§3] Notation for the SFHC bisection tolerance and the exact definition of the six stopping regions should be stated explicitly with equation numbers rather than described only in prose.
- [§4] Figure captions for the simulation results should include the precise grid of effect sizes, variance assumptions, and monitoring frequencies used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. Below we provide point-by-point responses to the major comments. We will revise the manuscript to address the issues raised where possible.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (simulation design): the reported error-rate control, power preservation, and CI coverage rest on Monte Carlo experiments whose data-generating processes, exact parameter grids, exclusion rules for early stopping, and number of replications are not specified. Without these details it is impossible to determine whether the claimed performance is robust or sensitive to post-hoc choices in the simulation protocol.
Authors: We agree that these details are essential for evaluating the simulation results. The omission was an oversight. In the revised manuscript, we will add a comprehensive description of the simulation design, including the data-generating processes, parameter grids, exclusion rules, and the number of Monte Carlo replications. This will allow readers to fully assess the robustness of the reported error control, power, and coverage. revision: yes
-
Referee: [§2, §3] §2 (SPRT-z derivation) and §3 (SFHC): the entire workflow invokes the continuous-time Brownian-motion approximation for the discrete Z-process under early futility stopping. No analytic error bounds, Edgeworth expansions, or direct comparisons against exact binomial or hypergeometric sequential tests are supplied to quantify the approximation error at the finite N values returned by SFHC. If the error is non-negligible, both the calibrated thresholds and the six-region CI construction can fail to deliver nominal coverage.
Authors: The manuscript does not provide analytic error bounds or Edgeworth expansions, relying instead on simulation evidence to support the accuracy of the Brownian motion approximation for the sample sizes calibrated by SFHC. We acknowledge this as a limitation. In the revision, we will include additional discussion on the potential approximation error, its implications, and further simulation-based sensitivity checks. Direct comparisons with exact tests are computationally intensive for large N but could be added for small cases if space permits. revision: partial
- Providing analytic error bounds or Edgeworth expansions to quantify the Brownian motion approximation error under discrete monitoring and futility stopping
Circularity Check
No circularity: classical SPRT foundations plus explicit Monte Carlo calibration
full rationale
The paper revives Wald's SPRT and Hajnal's sequential t-test via large-sample normal approximation (SPRT-z), then uses Monte Carlo bisection (SFHC) to set max N and a Brownian-motion median-unbiased estimator for bias correction. All performance claims (Type I/II control, sample-size reduction, CI coverage) are obtained from a separate simulation study rather than from any fitted parameter or self-referential equation. No load-bearing step reduces a reported result to a quantity defined by the same inputs; the derivation chain is externally anchored in classical sequential analysis and does not rely on self-citation chains or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
free parameters (2)
- Maximum sample size via SFHC
- SPRT decision thresholds
axioms (2)
- domain assumption Large-sample normal approximation holds for z-statistics under sequential monitoring
- domain assumption Brownian motion provides a valid continuous approximation for the discrete sequential process
Reference graph
Works this paper leans on
-
[1]
Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=
Anytime validity is free: inducing sequential tests , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=. 2026 , publisher=
2026
-
[2]
Statistical Science , volume=
Game-theoretic statistics and safe anytime-valid inference , author=. Statistical Science , volume=. 2023 , publisher=
2023
-
[3]
The Annals of Statistics , volume=
Time-uniform, nonparametric, nonasymptotic confidence sequences , author=. The Annals of Statistics , volume=. 2021 , publisher=
2021
-
[4]
Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=
Real-time segmentation of on-line handwritten arabic script , author=. Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=. 2014 , organization=
2014
-
[5]
Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=
Fast classification of handwritten on-line Arabic characters , author=. Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=. 2014 , organization=
2014
-
[6]
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
1947 , publisher=
Sequential analysis , author=. 1947 , publisher=
1947
-
[8]
Biometrika , volume=
A two-sample sequential t-test , author=. Biometrika , volume=
-
[9]
Psychological Methods , volume=
Controlling Decision Errors With Minimal Costs: The Sequential Probability Ratio t Test , author=. Psychological Methods , volume=
-
[10]
Biometrika , volume=
On the bias of maximum likelihood estimation following a sequential test , author=. Biometrika , volume=
-
[11]
arXiv preprint arXiv:2310.03722 , year=
Anytime-valid t-tests and confidence sequences for Gaussian means with unknown variance , author=. arXiv preprint arXiv:2310.03722 , year=
-
[12]
Handbook of Sequential Analysis , editor=
The Sequential Probability Ratio Test , author=. Handbook of Sequential Analysis , editor=. 1991 , publisher=
1991
-
[13]
Journal of the Royal Statistical Society Series B , year=
Safe Testing , author=. Journal of the Royal Statistical Society Series B , year=
-
[14]
The Annals of Mathematical Statistics , volume=
On information and sufficiency , author=. The Annals of Mathematical Statistics , volume=
-
[15]
Operations Research , volume=
Always valid inference: Continuous monitoring of A/B tests , author=. Operations Research , volume=
-
[16]
1999 , publisher=
Group Sequential Methods with Applications to Clinical Trials , author=. 1999 , publisher=
1999
-
[17]
Journal of the American Statistical Association , volume=
Semiparametric efficiency and its implication on the design and analysis of group-sequential studies , author=. Journal of the American Statistical Association , volume=. 1997 , publisher=
1997
-
[18]
Journal of the Royal Statistical Society
Present Position and Potential Developments: Some Personal Views: Statistical Theory: The Prequential Approach , author=. Journal of the Royal Statistical Society. Series A (General) , volume=. 1984 , publisher=
1984
-
[19]
2020 , publisher=
Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing , author=. 2020 , publisher=
2020
-
[20]
Biometrics , pages=
Exact confidence intervals following a group sequential test , author=. Biometrics , pages=. 1984 , publisher=
1984
-
[21]
Journal of the Royal Statistical Society: Series A (General) , volume=
Repeated significance tests on accumulating data , author=. Journal of the Royal Statistical Society: Series A (General) , volume=. 1969 , publisher=
1969
-
[22]
Biometrika , volume=
Discrete sequential boundaries for clinical trials , author=. Biometrika , volume=. 1983 , publisher=
1983
-
[23]
2004 , publisher=
Monte Carlo methods in financial engineering , author=. 2004 , publisher=
2004
-
[24]
1985 , publisher=
Sequential Analysis: Tests and Confidence Intervals , author=. 1985 , publisher=
1985
-
[25]
The Annals of Mathematical Statistics , volume=
Statistical methods related to the law of the iterated logarithm , author=. The Annals of Mathematical Statistics , volume=. 1970 , publisher=
1970
-
[26]
The Annals of Statistics , volume=
On confidence sequences , author=. The Annals of Statistics , volume=. 1976 , publisher=
1976
-
[27]
Continuous Monitoring of
Deng, Alex and Lu, Jiannan and Chen, Shouyuan , booktitle=. Continuous Monitoring of. 2016 , publisher=
2016
-
[28]
On Post-Selection Inference in
Deng, Alex and Li, Yicheng and Lu, Jiannan and Ramamurthy, Vivek , booktitle=. On Post-Selection Inference in. 2021 , publisher=. 1910.03788 , archivePrefix=
-
[29]
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD '18) , pages=
Winner's Curse: Bias Estimation for Total Effects of Features in Online Controlled Experiments , author=. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD '18) , pages=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.