DiffusionBench: On Holistic Evaluation of Diffusion Transformers
Pith reviewed 2026-06-26 00:04 UTC · model grok-4.3
The pith
ImageNet rankings show no strong correlation with text-to-image performance for diffusion transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
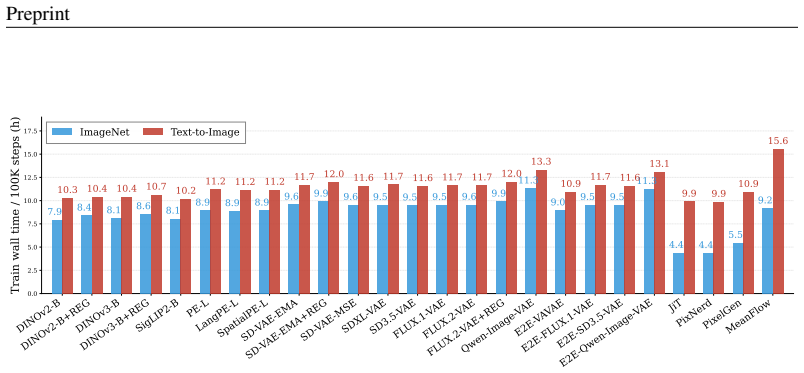
After training 21 latent diffusion models with NanoGen, method ranking shows no strong correlation between ImageNet and T2I generation: Pearson correlation is between -0.377 and -0.580 across three metrics. This suggests that a method which improves class-conditional ImageNet FID may show no corresponding improvement on T2I, clearly indicating the necessity of evaluating DiTs on both tasks. DiffusionBench summarizes ImageNet and text-to-image results to serve as a holistic benchmark.
What carries the argument
NanoGen, a unified DiT training and evaluation framework that supports RAE, VAE, pixel-space, and MeanFlow methods under both ImageNet and T2I with only 12 lines of configuration change.
If this is right
- A method that improves ImageNet FID may produce no gain, or even a loss, on text-to-image generation.
- Reporting only ImageNet results can mask lack of broader progress in DiT generative modeling.
- DiffusionBench supplies a combined evaluation that better tracks advances applicable to both tasks.
- T2I training under NanoGen requires compute comparable to ImageNet training.
Where Pith is reading between the lines
- The observed decoupling may appear for generation tasks other than text-to-image.
- Methods could be developed that deliberately optimize for consistent ranking across multiple conditioning types.
- Benchmark designers might add further tasks to test whether ImageNet remains an outlier.
- Practitioners may need to redesign optimization or data pipelines to avoid task-specific overfitting.
Load-bearing premise
The 12-line configuration change in NanoGen produces training setups that are sufficiently equivalent and unbiased across ImageNet and T2I so that method rankings can be directly compared.
What would settle it
Re-training the same 21 models under NanoGen with altered random seeds or minor hyper-parameter shifts and checking whether the reported Pearson correlations remain negative.
Figures




read the original abstract
Diffusion transformer (DiT) research on image generation has converged to a single evaluation setup: class-conditional generation on ImageNet. While methods improve the FID and related metrics, it is increasingly unclear whether they reflect real progress in generative modeling. The natural alternative, i.e., text-to-image (T2I) generation, is perceived as too costly or inconvenient to train and evaluate and is often skipped. We argue that this perception no longer holds. We introduce NanoGen, a unified DiT training and evaluation framework. NanoGen matches state-of-the-art DiT baselines on ImageNet and, with 12 lines of configuration change, also trains competitive text-to-image models. It currently supports RAE, VAE, pixel-space, and MeanFlow diffusion methods under both ImageNet and T2I setups. Under NanoGen, training T2I requires comparable compute to ImageNet. After training 21 latent diffusion models with NanoGen, we observe that method ranking shows no strong correlation between ImageNet and T2I generation: Pearson correlation is between -0.377 and -0.580 across three metrics. This suggests that a method which improves class-conditional ImageNet FID may show no corresponding improvement on T2I, clearly indicating the necessity of evaluating DiTs on both tasks. To this end, we summarize ImageNet and text-to-image results, which yields DiffusionBench, a holistic benchmark for DiT research. We recommend reporting DiffusionBench in place of ImageNet alone: methods that improve DiffusionBench are more likely to reflect broader progress.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NanoGen, a unified DiT training and evaluation framework that matches SOTA on class-conditional ImageNet generation and, via a 12-line configuration change, also supports competitive text-to-image (T2I) models with comparable compute. After training 21 latent diffusion models under NanoGen (supporting RAE, VAE, pixel-space, and MeanFlow methods), the authors report Pearson correlations between -0.377 and -0.580 across three metrics for method rankings on ImageNet vs. T2I, concluding that ImageNet improvements do not reliably transfer and proposing DiffusionBench as a holistic benchmark that should replace ImageNet-only evaluation.
Significance. If the reported negative correlations are shown to arise from task differences rather than optimization artifacts, the work would provide concrete evidence that single-task ImageNet evaluation is insufficient for tracking progress in diffusion transformers, with the NanoGen framework serving as a practical, reproducible contribution that makes dual-task evaluation feasible. The explicit training of 21 models under a shared codebase is a strength that supports the empirical nature of the correlation measurements.
major comments (2)
- [NanoGen Framework] NanoGen Framework section: the central claim that method rankings show no strong correlation (Pearson r between -0.377 and -0.580) rests on the assumption that the 12-line configuration switch produces equivalent and unbiased training regimes for ImageNet and T2I; the manuscript provides no ablations or analysis confirming that learning-rate schedules, batch statistics, data-augmentation pipelines, or optimizer states remain identically behaved after the switch, leaving open the possibility that the anti-correlation is an artifact of unequal optimization rather than evidence of non-transfer.
- [Experiments] Experiments section: the soundness of the no-correlation conclusion is limited by the absence of statistical testing, error bars, or explicit data exclusion rules for the 21 models; without these, it is unclear whether the reported Pearson values are robust or sensitive to particular model subsets or metric choices.
minor comments (2)
- [Abstract] Abstract: the three metrics underlying the Pearson correlations are not named, making it difficult to assess which aspects of generation quality are being compared.
- The manuscript would benefit from a table explicitly listing the 12 configuration lines that differ between ImageNet and T2I setups for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address both major comments by committing to revisions that add ablations on training equivalence and statistical analyses for the correlations, providing stronger evidence that the negative correlations reflect genuine task differences.
read point-by-point responses
-
Referee: [NanoGen Framework] NanoGen Framework section: the central claim that method rankings show no strong correlation (Pearson r between -0.377 and -0.580) rests on the assumption that the 12-line configuration switch produces equivalent and unbiased training regimes for ImageNet and T2I; the manuscript provides no ablations or analysis confirming that learning-rate schedules, batch statistics, data-augmentation pipelines, or optimizer states remain identically behaved after the switch, leaving open the possibility that the anti-correlation is an artifact of unequal optimization rather than evidence of non-transfer.
Authors: We agree that explicit verification would strengthen the claim. The 12-line change primarily affects data loading and conditioning (class vs. text) while keeping the optimizer, LR schedule, and architecture identical. In revision we will add an ablation comparing loss curves, gradient norms, and batch statistics across both setups for representative models, showing the regimes behave comparably and supporting that the anti-correlation is not an optimization artifact. revision: yes
-
Referee: [Experiments] Experiments section: the soundness of the no-correlation conclusion is limited by the absence of statistical testing, error bars, or explicit data exclusion rules for the 21 models; without these, it is unclear whether the reported Pearson values are robust or sensitive to particular model subsets or metric choices.
Authors: We accept that statistical measures would improve rigor. The revision will add bootstrap confidence intervals and p-values for the Pearson correlations. We will also include a sensitivity table showing correlations after excluding outlier models and across metric subsets, demonstrating robustness of the negative values (-0.377 to -0.580). revision: yes
Circularity Check
No significant circularity; central result is direct empirical measurement.
full rationale
The paper's headline finding (Pearson correlations of -0.377 to -0.580 across 21 models) is obtained by training separate latent diffusion models under NanoGen and computing correlations on their observed FID/metric rankings for ImageNet vs. T2I. No equations, fitted parameters, or self-citations are invoked to derive these values; they are reported as raw experimental outcomes. The 12-line configuration change is presented as an implementation detail enabling the experiments rather than a definitional or fitted input that forces the reported anti-correlation. The derivation chain therefore remains self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be trained effectively on both class-conditional ImageNet and text-to-image tasks using similar compute resources under a unified framework.
invented entities (2)
-
NanoGen
no independent evidence
-
DiffusionBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[2]
Transactions on Machine Learning Research Journal , pages=
DINOv2: Learning Robust Visual Features without Supervision , author=. Transactions on Machine Learning Research Journal , pages=
-
[3]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
An empirical study of training self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[4]
European Conference on Computer Vision , pages=
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[6]
arXiv preprint arXiv:2410.06940 , year=
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think , author=. arXiv preprint arXiv:2410.06940 , year=
-
[7]
arXiv preprint arXiv:2505.13447 , year=
Mean flows for one-step generative modeling , author=. arXiv preprint arXiv:2505.13447 , year=
-
[8]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[9]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[10]
Neural networks , volume=
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning , author=. Neural networks , volume=. 2018 , publisher=
2018
-
[11]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[12]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[13]
arXiv preprint arXiv:2207.12598 , year=
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
-
[14]
arXiv preprint arXiv:2404.07724 , year=
Applying guidance in a limited interval improves sample and distribution quality in diffusion models , author=. arXiv preprint arXiv:2404.07724 , year=
-
[15]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[16]
arXiv preprint arXiv:1312.6114 , year=
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Autoregressive image generation without vector quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Maskgit: Masked generative image transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
arXiv preprint arXiv:2406.06525 , year=
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation , author=. arXiv preprint arXiv:2406.06525 , year=
-
[21]
arXiv preprint arXiv:2310.05737 , year=
Language Model Beats Diffusion--Tokenizer is Key to Visual Generation , author=. arXiv preprint arXiv:2310.05737 , year=
-
[22]
arXiv preprint arXiv:2306.09305 , year=
Fast training of diffusion models with masked transformers , author=. arXiv preprint arXiv:2306.09305 , year=
-
[23]
arXiv preprint arXiv:2410.10356 , year=
FasterDiT: Towards Faster Diffusion Transformers Training without Architecture Modification , author=. arXiv preprint arXiv:2410.10356 , year=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Masked diffusion transformer is a strong image synthesizer , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
arXiv preprint arXiv:2303.14389 , year=
MDTv2: Masked Diffusion Transformer is a Strong Image Synthesizer , author=. arXiv preprint arXiv:2303.14389 , year=
-
[26]
Generation: Taming Optimization Dilemma in Latent Diffusion Models , author=
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models , author=. arXiv preprint arXiv:2501.01423 , year=
-
[27]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Taming transformers for high-resolution image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[30]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[31]
International Conference on Machine Learning , pages=
A Simple Framework for Contrastive Learning of Visual Representations , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[33]
Proceedings of the sixth National conference on Artificial intelligence-Volume 1 , pages=
Modular learning in neural networks , author=. Proceedings of the sixth National conference on Artificial intelligence-Volume 1 , pages=
-
[34]
The Twelfth International Conference on Learning Representations , year=
Dustin Podell and Zion English and Kyle Lacey and Andreas Blattmann and Tim Dockhorn and Jonas M. The Twelfth International Conference on Learning Representations , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
An image is worth 32 tokens for reconstruction and generation , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:2412.05796 , year=
Language-Guided Image Tokenization for Generation , author=. arXiv preprint arXiv:2412.05796 , year=
-
[37]
arXiv preprint arXiv:2501.07730 , year=
Democratizing Text-to-Image Masked Generative Models with Compact Text-Aware One-Dimensional Tokens , author=. arXiv preprint arXiv:2501.07730 , year=
-
[38]
Forty-first International Conference on Machine Learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first International Conference on Machine Learning , year=
-
[39]
Medical image computing and computer-assisted intervention--MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. Medical image computing and computer-assisted intervention--MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 , pages=. 2015 , organization=
2015
-
[40]
Flow Matching for Generative Modeling , author=
-
[41]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=
-
[42]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[44]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[45]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[46]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[47]
arXiv preprint arXiv:2310.00426 , year=
Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis , author=. arXiv preprint arXiv:2310.00426 , year=
-
[48]
The Twelfth International Conference on Learning Representations , year=
Vdt: General-purpose video diffusion transformers via mask modeling , author=. The Twelfth International Conference on Learning Representations , year=
-
[49]
2024 , howpublished =
OpenAI , title =. 2024 , howpublished =
2024
-
[50]
arXiv preprint arXiv:2405.05945 , year=
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers , author=. arXiv preprint arXiv:2405.05945 , year=
-
[51]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[52]
2025 , howpublished=
Black Forest Labs , title=. 2025 , howpublished=
2025
-
[53]
International conference on machine learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[54]
International Conference on Machine Learning , year=
The Platonic Representation Hypothesis , author=. International Conference on Machine Learning , year=
-
[55]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[56]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[57]
International journal of computer vision , volume=
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale , author=. International journal of computer vision , volume=. 2020 , publisher=
2020
-
[58]
Pernias, Pablo and Rampas, Dominic and Richter, Mats Leon and Pal, Christopher and Aubreville, Marc , booktitle=. W
-
[59]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Denoising diffusion autoencoders are unified self-supervised learners , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[60]
arXiv preprint arXiv:2307.08702 , year=
Diffusion models beat gans on image classification , author=. arXiv preprint arXiv:2307.08702 , year=
-
[61]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Your diffusion model is secretly a zero-shot classifier , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[62]
arXiv preprint arXiv:2502.09509 , year=
EQ-VAE: Equivariance Regularized Latent Space for Improved Generative Image Modeling , author=. arXiv preprint arXiv:2502.09509 , year=
-
[63]
arXiv preprint arXiv:2502.14831 , year=
Improving the Diffusability of Autoencoders , author=. arXiv preprint arXiv:2502.14831 , year=
-
[64]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Rich feature hierarchies for accurate object detection and semantic segmentation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[65]
Proceedings of the IEEE international conference on computer vision , pages=
Fast r-cnn , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[66]
IEEE transactions on pattern analysis and machine intelligence , volume=
Faster R-CNN: Towards real-time object detection with region proposal networks , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2016 , publisher=
2016
-
[67]
Communications of the ACM , volume=
Generative adversarial networks , author=. Communications of the ACM , volume=. 2020 , publisher=
2020
-
[68]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-supervised learning from images with a joint-embedding predictive architecture , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[70]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[71]
International Conference on Machine Learning , pages=
Generating images with sparse representations , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[72]
Advances in neural information processing systems , volume=
Improved techniques for training gans , author=. Advances in neural information processing systems , volume=
-
[73]
Advances in neural information processing systems , volume=
Improved precision and recall metric for assessing generative models , author=. Advances in neural information processing systems , volume=
-
[74]
, author =
Improved Autoencoders ... , author =
-
[75]
Nonlinear total variation based noise removal algorithms , journal =. 1992 , issn =. doi:https://doi.org/10.1016/0167-2789(92)90242-F , url =
-
[76]
Score-based Generative Modeling in Latent Space , url =
Vahdat, Arash and Kreis, Karsten and Kautz, Jan , booktitle =. Score-based Generative Modeling in Latent Space , url =
-
[77]
Proceedings of the 41st International Conference on Machine Learning , pages =
Neural Diffusion Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[78]
2025 , journal=
REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers , author=. 2025 , journal=
2025
-
[79]
arXiv preprint arXiv:2504.01017 , year=
Scaling language-free visual representation learning , author=. arXiv preprint arXiv:2504.01017 , year=
-
[80]
Perception Encoder: The best visual embeddings are not at the output of the network , author=. arXiv:2504.13181 , year=
-
[81]
arXiv preprint arXiv:2502.14786 , year=
Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features , author=. arXiv preprint arXiv:2502.14786 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.