Follow Your Track: Precise Skeleton Animation Controlled by 3D Trajectories
Pith reviewed 2026-06-25 21:10 UTC · model grok-4.3
The pith
ACT routes 3D point trajectories from monocular video to skeleton joints for higher-fidelity animations than text or mesh controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
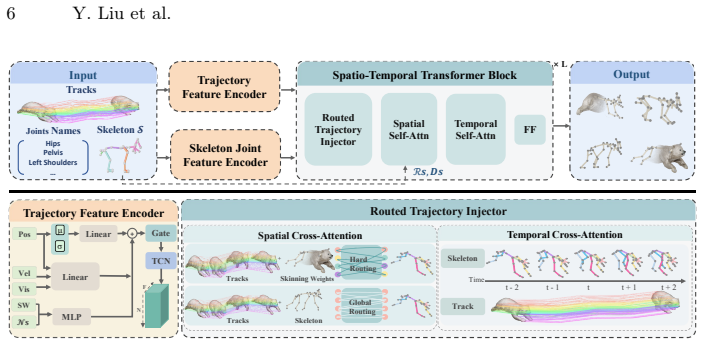
ACT is a trajectory-conditioned framework that treats 3D point trajectories from monocular video as direct motion guidance for topology-general skeletal animation; its Routed Trajectory Injector performs accurate transfer through prior-guided hard routing for skeleton-mesh correspondence, global routing for full-body awareness, and local windowed cross-attention for micro-timing alignment, yielding animations with measurably higher fidelity and temporal consistency than prior methods.
What carries the argument
Routed Trajectory Injector: the module that maps 3D point trajectories to skeleton joints via prior-guided hard routing, global routing, and local windowed cross-attention.
If this is right
- Skeletal representations replace dense meshes or Gaussians, lowering compute cost and allowing longer animation clips.
- Motion guidance remains disentangled from appearance and background, improving controllability over text-only or video-entangled signals.
- The three-part routing design supports arbitrary skeleton topologies without retraining the core injector.
- Temporal consistency improves because local windowed attention aligns tracks at varying motion rates.
- Full-body awareness from global routing reduces identification errors across coordinated multi-limb actions.
Where Pith is reading between the lines
- The same routing mechanism could be tested on retargeting tasks where source and target skeletons differ substantially in proportions.
- If trajectory extraction quality improves with better monocular depth estimators, ACT performance would rise without changes to the injector itself.
- Combining ACT with existing text-to-3D asset generators would produce end-to-end pipelines that accept only text and video while outputting controllable long animations.
- The local windowed attention component might generalize to other sequential control problems such as audio-driven facial animation.
Load-bearing premise
3D point trajectories extracted from monocular video supply accurate, disentangled motion signals that transfer reliably to arbitrary skeleton topologies without depth or tracking errors affecting the result.
What would settle it
A controlled experiment that applies ACT and baseline methods to the same set of monocular videos with independently measured ground-truth joint trajectories and shows that ACT produces no lower average joint-position error or temporal drift than the baselines.
Figures

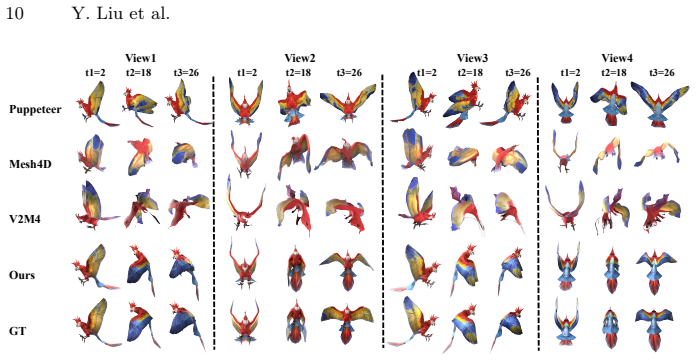
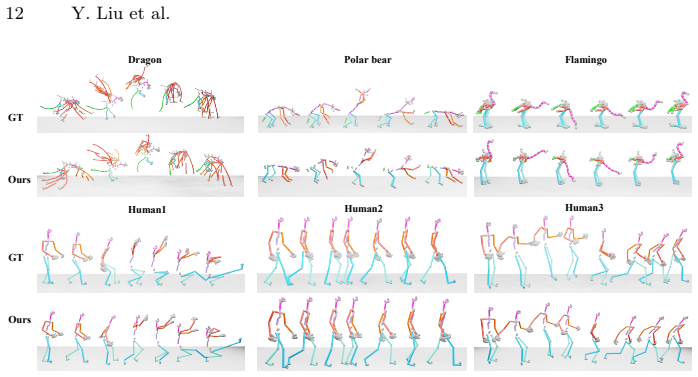

read the original abstract
4D generation aims to animate 3D objects with realistic motion, holding great promise for applications. Existing methods typically decouple 3D asset generation from motion synthesis: acquire a 3D asset, prepare a structural representation like mesh and Gaussians, and synthesize motion from text or video control signals. However, dense mesh and Gaussian representations incur high computational costs and are prone to temporal artifacts, limiting animation quality and duration to only short clips. Meanwhile, text lacks fine-grained spatial and temporal details such as timing and coordination, while video entangles motion with appearance and background. Together, these limitations result in 4D animations that suffer from poor temporal consistency, wrong identification, and limited controllability. We address these issues with \texttt{ACT}, a trajectory-conditioned framework for topology-general skeletal animation. ACT uses skeletons as a compact structured and compute-efficient representation and 3D point trajectories from monocular video as explicit motion guidance which provide detailed motion patterns without appearance entanglement. At the core of ACT is a Routed Trajectory Injector, which achieves accurate and robust trajectory-to-joint transfer through three complementary designs: prior-guided hard routing establishes precise skeleton-to-mesh correspondences, global routing enables holistic joint-track interaction for full-body motion awareness, and local windowed cross-attention enforces fine-grained temporal alignment, improving micro-timing and reducing motion misalignment across varying motion rates. Extensive experiments demonstrate that \texttt{ACT} significantly outperforms existing methods in fidelity and temporal consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ACT, a trajectory-conditioned framework for topology-general skeletal animation. It extracts 3D point trajectories from monocular video as explicit motion guidance and employs a Routed Trajectory Injector (prior-guided hard routing, global routing, and local windowed cross-attention) to map trajectories to skeleton joints, claiming this yields significantly better fidelity and temporal consistency than prior 4D generation methods that rely on dense meshes/Gaussians or entangled text/video controls.
Significance. If the empirical results hold, the work offers a compute-efficient alternative to dense 3D representations for controllable animation, potentially enabling longer clips with improved motion disentanglement; the explicit use of skeleton topology and trajectory routing could generalize across assets if the transfer mechanism proves robust.
major comments (2)
- [Method (Routed Trajectory Injector description)] The central claim that the Routed Trajectory Injector achieves robust trajectory-to-joint transfer rests on the unverified assumption that monocular 3D trajectories supply accurate, disentangled motion signals; no section quantifies depth ambiguity, occlusion drift, or correspondence errors between extracted points and target joints, which directly affects whether the three routing components can deliver the stated gains without explicit robustness mechanisms.
- [Experiments] Experiments section: the outperformance claim in fidelity and temporal consistency is asserted via the three routing designs, yet the manuscript provides no ablation isolating the contribution of prior-guided hard routing versus global routing versus local windowed cross-attention, nor any metrics on trajectory accuracy under varying motion rates or topologies; this leaves the load-bearing role of the injector unverified.
minor comments (1)
- [Abstract] Abstract: states 'extensive experiments demonstrate' outperformance but reports no numerical results, ablation tables, or dataset details, which is atypical for an empirical methods claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the Routed Trajectory Injector and experimental validation. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: The central claim that the Routed Trajectory Injector achieves robust trajectory-to-joint transfer rests on the unverified assumption that monocular 3D trajectories supply accurate, disentangled motion signals; no section quantifies depth ambiguity, occlusion drift, or correspondence errors between extracted points and target joints, which directly affects whether the three routing components can deliver the stated gains without explicit robustness mechanisms.
Authors: We acknowledge that the manuscript does not include explicit quantitative analysis of trajectory extraction errors such as depth ambiguity, occlusion drift, or correspondence mismatches. The three routing components (prior-guided hard routing, global routing, and local windowed cross-attention) are presented as mechanisms to achieve robust transfer, with overall empirical gains shown in the experiments. We will revise the method section to add a discussion of these potential error sources and how the routing designs are intended to provide robustness, supported by additional qualitative visualizations from existing results. revision: partial
-
Referee: Experiments section: the outperformance claim in fidelity and temporal consistency is asserted via the three routing designs, yet the manuscript provides no ablation isolating the contribution of prior-guided hard routing versus global routing versus local windowed cross-attention, nor any metrics on trajectory accuracy under varying motion rates or topologies; this leaves the load-bearing role of the injector unverified.
Authors: We agree that isolating the contributions of each routing component and providing trajectory accuracy metrics would more directly verify the injector's role. The current experiments demonstrate end-to-end improvements over baselines but do not include these breakdowns. In the revised manuscript we will add an ablation study that evaluates performance when each routing component is removed individually, reporting effects on the fidelity and temporal consistency metrics. We will also include trajectory accuracy metrics under different motion conditions where they can be derived from the existing experimental setup. revision: yes
Circularity Check
No circularity: empirical architecture with no derivation chain or self-referential reductions
full rationale
The paper introduces an architectural framework (ACT with Routed Trajectory Injector) and reports empirical outperformance on fidelity and temporal consistency. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on experimental comparisons rather than any step that reduces by construction to its own inputs, satisfying the default expectation of non-circularity for method papers without mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Skeletons serve as a compact, topology-general, and compute-efficient representation sufficient for realistic animation
- domain assumption 3D point trajectories from monocular video provide detailed motion patterns without appearance entanglement
Reference graph
Works this paper leans on
-
[1]
In: European Conference on Computer Vision
Bahmani, S., Liu, X., Yifan, W., Skorokhodov, I., Rong, V., Liu, Z., Liu, X., Park, J.J., Tulyakov, S., Wetzstein, G., et al.: Tc4d: Trajectory-conditioned text-to-4d generation. In: European Conference on Computer Vision. pp. 53–72. Springer (2024)
2024
-
[2]
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable video diffusion: Scaling latent video diffusion models to large datasets (2023),https: //arxiv.org/abs/2311.15127
Pith/arXiv arXiv 2023
-
[3]
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
Pith/arXiv arXiv 2025
-
[4]
Chen, C., Huang, S., Chen, X., Chen, G., Han, X., Zhang, K., Gong, M.: Ct4d: Consistent text-to-4d generation with animatable meshes (2024),https://arxiv. org/abs/2408.08342
arXiv 2024
-
[5]
Chen, J., Zhang, B., Tang, X., Wonka, P.: V2m4: 4d mesh animation reconstruction from a single monocular video (2025),https://arxiv.org/abs/2503.09631
arXiv 2025
-
[6]
Dai, S., Su, X., Hu, R., Xu, K.: Textmesh4d: Text-to-4d mesh generation via jaco- bian deformation field (2025),https://arxiv.org/abs/2506.24121
Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2508.07409 (2025)
Gao, J., Li, J., Liu, W., Zeng, Y., Shen, F., Chen, K., Sun, Y., Zhao, C.: Char- actershot: Controllable and consistent 4d character animation. arXiv preprint arXiv:2508.07409 (2025)
arXiv 2025
-
[8]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Con- ference Papers
Gat, I., Raab, S., Tevet, G., Reshef, Y., Bermano, A.H., Cohen-Or, D.: Anytop: Character animation diffusion with any topology. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Con- ference Papers. pp. 1–10 (2025)
2025
-
[9]
Liu et al
Geng, D., Herrmann, C., Hur, J., Cole, F., Zhang, S., Pfaff, T., Lopez-Guevara, T., Aytar, Y., Rubinstein, M., Sun, C., et al.: Motion prompting: Controlling video 16 Y. Liu et al. generation with motion trajectories. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1–12 (2025)
2025
-
[10]
arXiv preprint arXiv:2512.10881 (2025)
Gong,K.,Wen,Z.,He,W.,Xu,M.,Wang,Q.,Zhang,N.,Li,Z.,Lian,D.,Zhao,W., He, X., et al.: Mocapanything: Unified 3d motion capture for arbitrary skeletons from monocular videos. arXiv preprint arXiv:2512.10881 (2025)
Pith/arXiv arXiv 2025
-
[11]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Guo, Z., Xiang, J., Ma, K., Zhou, W., Li, H., Zhang, R.: Make-it-animatable: An efficient framework for authoring animation-ready 3d characters. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10783–10792 (2025)
2025
-
[12]
Hong, S., Choi, S., Kim, C., Cha, S., Noh, J.: Asmr: Adaptive skeleton-mesh rigging and skinning via 2d generative prior (2025),https://arxiv.org/abs/2503.13579
arXiv 2025
-
[13]
arXiv preprint arXiv:2502.11697 (2025)
Huang, H., Liu, Y., Zheng, G., Wang, J., Dou, Z., Yang, S.: Mvtokenflow: High-quality 4d content generation using multiview token flow. arXiv preprint arXiv:2502.11697 (2025)
arXiv 2025
-
[14]
Huang, Z., Feng, H., Sun, Y., Guo, Y., Cao, Y., Sheng, L.: Animax: Animating the inanimate in 3d with joint video-pose diffusion models (2025),https://arxiv. org/abs/2506.19851
arXiv 2025
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[16]
Huang, Z., Zhang, F., Xu, X., He, Y., Yu, J., Dong, Z., Ma, Q., Chanpaisit, N., Si, C., Jiang, Y., Wang, Y., Chen, X., Chen, Y.C., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench++: Comprehensive and versatile benchmark suite for video generative models. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025). https://doi.org/10.1109/TPAMI.2025.3633890
-
[17]
Advances in Neural Information Processing Systems37, 125879–125906 (2024)
Jiang, Y., Yu, C., Cao, C., Wang, F., Hu, W., Gao, J.: Animate3d: Animating any 3d model with multi-view video diffusion. Advances in Neural Information Processing Systems37, 125879–125906 (2024)
2024
-
[18]
arXiv preprint arXiv:2311.02848 (2023)
Jiang,Y.,Zhang,L.,Gao,J.,Hu,W.,Yao,Y.:Consistent4d:Consistent360{\deg} dynamic object generation from monocular video. arXiv preprint arXiv:2311.02848 (2023)
arXiv 2023
-
[19]
arXiv preprint arXiv:2601.05251 (2026)
Jiang,Z.,Zheng,C.,Laina,I.,Larlus,D.,Vedaldi,A.:Mesh4d:4dmeshreconstruc- tion and tracking from monocular video. arXiv preprint arXiv:2601.05251 (2026)
arXiv 2026
- [20]
-
[21]
Kim, T., Na, Y., Lee, J., Sung, M., Yoon, S.E.: Camo: Category-agnostic 3d motion transfer from monocular 2d videos (2026),https://arxiv.org/abs/2601.02716
arXiv 2026
-
[22]
Li, Q., Xing, Z., Wang, R., Zhang, H., Dai, Q., Wu, Z.: Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance (2025),https://arxiv. org/abs/2503.16421
arXiv 2025
-
[23]
Li, X., Ma, Q., Lin, T.Y., Chen, Y., Jiang, C., Liu, M.Y., Xiang, D.: Articulated kinematics distillation from video diffusion models (2025),https://arxiv.org/ abs/2504.01204
arXiv 2025
-
[24]
Li, Z., Chen, Y., Liu, P.: Dreammesh4d: Video-to-4d generation with sparse- controlled gaussian-mesh hybrid representation (2024),https://arxiv.org/abs/ 2410.06756
arXiv 2024
-
[25]
Liu, I., Xu, Z., Yifan, W., Tan, H., Xu, Z., Wang, X., Su, H., Shi, Z.: Riganything: Template-free autoregressive rigging for diverse 3d assets. ACM Transactions on Graphics44(4), 1–12 (Jul 2025).https://doi.org/10.1145/3731149,http:// dx.doi.org/10.1145/3731149 Follow Your Track 17
-
[26]
Ma, Z., Liang, X., Wu, R., Zhu, X., Lei, Z., Zhang, L.: Progressive rendering distillation: Adapting stable diffusion for instant text-to-mesh generation without 3d data (2025),https://arxiv.org/abs/2503.21694
arXiv 2025
-
[27]
In: International Conference on Com- puter Vision
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: AMASS: Archive of motion capture as surface shapes. In: International Conference on Com- puter Vision. pp. 5442–5451 (Oct 2019)
2019
-
[28]
Nag, S., Cohen-Or, D., Zhang, H., Mahdavi-Amiri, A.: In-2-4d: Inbetweening from two single-view images to 4d generation (2025),https://arxiv.org/abs/2504. 08366
2025
-
[29]
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion (2022),https://arxiv.org/abs/2209.14988
Pith/arXiv arXiv 2022
-
[30]
arXiv preprint arXiv:2412.20422 (2024)
Rahamim, O., Malca, O., Samuel, D., Chechik, G.: Bringing objects to life: training-free 4d generation from 3d objects through view consistent noise. arXiv preprint arXiv:2412.20422 (2024)
arXiv 2024
-
[31]
Ren, J., Xie, K., Mirzaei, A., Liang, H., Zeng, X., Kreis, K., Liu, Z., Torralba, A., Fidler, S., Kim, S.W., Ling, H.: L4gm: Large 4d gaussian reconstruction model (2024),https://arxiv.org/abs/2406.10324
arXiv 2024
-
[32]
arXiv preprint arXiv:2511.16662 (2025)
Sheung, E.P., Liu, Q., Ma, W., Kaushik, P., Xie, J., Yuille, A.: Tridiff-4d: Fast 4d generation through diffusion-based triplane re-posing. arXiv preprint arXiv:2511.16662 (2025)
arXiv 2025
-
[33]
Shi, Y., Liu, Y., Wu, Y., Liu, X., Zhao, C., Luo, J., Zhou, B.: Drive any mesh: 4d latent diffusion for mesh deformation from video (2025),https://arxiv.org/ abs/2506.07489
arXiv 2025
-
[34]
Shim, G., Lee, S., Choo, J.: Gaussianmotion: End-to-end learning of animatable gaussian avatars with pose guidance from text (2025),https://arxiv.org/abs/ 2502.11642
arXiv 2025
-
[35]
arXiv preprint arXiv:2508.10898 (2025)
Song, C., Li, X., Yang, F., Xu, Z., Wei, J., Liu, F., Feng, J., Lin, G., Zhang, J.: Puppeteer: Rig and animate your 3d models. arXiv preprint arXiv:2508.10898 (2025)
arXiv 2025
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sun, M., Chen, J., Dong, J., Chen, Y., Jiang, X., Mao, S., Jiang, P., Wang, J., Dai, B., Huang, R.: Drive: Diffusion-based rigging empowers generation of versatile and expressive characters. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21170–21180 (2025)
2025
-
[37]
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Fvd: A new metric for video generation (2019)
2019
-
[38]
arXiv preprint arXiv:2508.05162 (2025)
Wang, X., Ruan, K., Qian, L., Guo, Z., Su, C., Wang, G.: X-mogen: Unified motion generation across humans and animals. arXiv preprint arXiv:2508.05162 (2025)
arXiv 2025
-
[39]
Wang, Y., Liu, G., Wang, X., Chen, Z., Li, J., Liang, X., Sun, F., Zhu, J.: Video4dgen: Enhancing video and 4d generation through mutual optimization (2025),https://arxiv.org/abs/2504.04153
arXiv 2025
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20310– 20320 (2024)
2024
-
[41]
In: European Conference on Computer Vision
Wu, Z., Yu, C., Jiang, Y., Cao, C., Wang, F., Bai, X.: Sc4d: Sparse-controlled video-to-4d generation and motion transfer. In: European Conference on Computer Vision. pp. 361–379. Springer (2024)
2024
- [42]
-
[43]
Xiao, Y., Wang, J., Xue, N., Karaev, N., Makarov, Y., Kang, B., Zhu, X., Bao, H., Shen, Y., Zhou, X.: Spatialtrackerv2: 3d point tracking made easy (2025), https://arxiv.org/abs/2507.12462
arXiv 2025
-
[44]
Xie, T., Chen, Y., Guo, Y., Yang, Y., Zhou, B., Terzopoulos, D., Jiang, Y., Jiang, C.: Animamimic: Imitating 3d animation from video priors (2025),https: //arxiv.org/abs/2512.14133
arXiv 2025
-
[45]
Yuan, Y.J., Kobbelt, L., Liu, J., Zhang, Y., Wan, P., Lai, Y.K., Gao, L.: 4dynamic: Text-to-4d generation with hybrid priors (2024),https://arxiv.org/abs/2407. 12684
2024
-
[46]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, B., Xu, S., Wang, C., Yang, J., Zhao, F., Chen, D., Guo, B.: Gaussian variation field diffusion for high-fidelity video-to-4d synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12502–12513 (2025)
2025
-
[47]
Zhang, H., Xu, H., Feng, C., Jampani, V., Ahuja, N.: Physrig: Differentiable physics-based skinning and rigging framework for realistic articulated object mod- eling (2025),https://arxiv.org/abs/2506.20936
arXiv 2025
-
[48]
Zhang, J.P., Pu, C.F., Guo, M.H., Cao, Y.P., Hu, S.M.: One model to rig them all: Diverse skeleton rigging with unirig (2025),https://arxiv.org/abs/2504.12451
arXiv 2025
-
[49]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[50]
Zhang, X., Zhou, Y., Wang, K., Wang, Y., Li, Z., Jiao, S., Zhou, D., Hou, Q., Cheng, M.M.: Ar-1-to-3: Single image to consistent 3d object generation via next- view prediction (2025),https://arxiv.org/abs/2503.12929
arXiv 2025
-
[51]
arXiv preprint arXiv:2503.21755 (2025)
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y., Zhang, F., Zhang, Y., He, J., Zheng, W.S., Qiao, Y., Liu, Z.: VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755 (2025)
Pith/arXiv arXiv 2025
-
[52]
CoRRabs/1812.07035(2018),http://arxiv
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation rep- resentations in neural networks. CoRRabs/1812.07035(2018),http://arxiv. org/abs/1812.07035
arXiv 2018
-
[53]
arXiv preprint arXiv:2501.01722 (2025)
Zhu, H., He, T., Yu, X., Guo, J., Chen, Z., Bian, J.: Ar4d: Autoregressive 4d generation from monocular videos. arXiv preprint arXiv:2501.01722 (2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.