Learning with a Single Rollout via Monte Carlo Pass@k Critic
Pith reviewed 2026-06-25 20:51 UTC · model grok-4.3
The pith
SR-PPO trains a token-level critic on Monte Carlo Pass@k from one rollout to assign advantages in language model RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instead of estimating advantages by normalizing episodic returns within a candidate group, SR-PPO trains a calibrated token-level credit critic using Monte Carlo outcomes from one rollout per prompt. The critic predicts the Pass@k success probability at each prompt prefix, which discounts easy prefixes and prioritizes hard ones. As k increases this quantity converges to a reachability indicator reflecting whether a prefix can lead to at least one successful continuation, computable in linear time on a state graph and serving as a surrogate for direct credit assignment without contrastive traces.
What carries the argument
The calibrated token-level credit critic that predicts Pass@k success probability at each prefix from a single Pass@1 rollout.
Load-bearing premise
Outcomes collected from one rollout per prompt are sufficient to train a calibrated critic whose Pass@k predictions supply a selective low-variance advantage signal.
What would settle it
If the single-rollout critic produces advantage estimates whose correlation with actual held-out Pass@k rates is no better than random or if SR-PPO training shows no Pass@128 gains relative to standard multi-sample baselines on the same math benchmarks.
Figures


read the original abstract
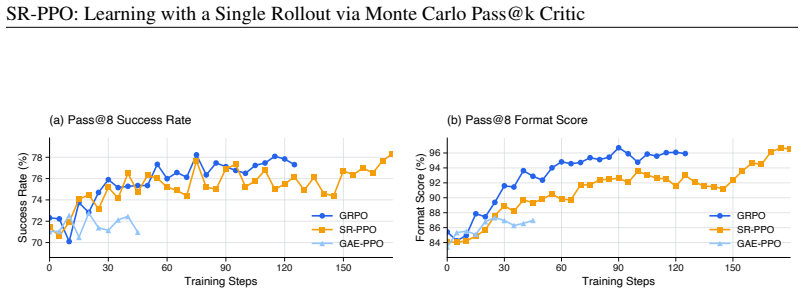
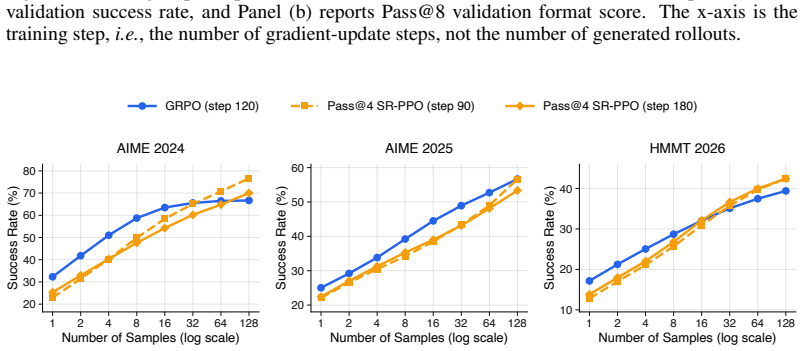
Estimating token-level advantages in reinforcement learning (RL) for language models remains challenging because scaling up episodic experience collection is expensive. The difficulty intensifies for baseline advantage estimation methods, where repeated sampling causes trajectories to diverge into substantially different reasoning prefixes. In this context, RL algorithms such as GRPO prove limited: an outcome reward is too sparse to be attributed to specific actions like intermediate steps, and comparisons across sampled traces are non-trivial because they are heterogeneous. To mitigate both the computational cost of repeated sampling and the difficulty of credit assignment, we study single-rollout proximal policy optimization (SR-PPO) featuring token-level credit assignment in RL for language models. Instead of estimating advantages by normalizing episodic returns within the candidate group, we train a calibrated token-level credit critic using Monte Carlo outcomes from one rollout per prompt. Specifically, we use the critic to predict the Pass@k success probability at the prompt prefix, which is derived from a Pass@1 attempt. This choice yields a more selective learning signal than Pass@1: it discounts easily solved prefixes while prioritizing hard ones whose success probability remains marginal. We show that as $k$ increases, Pass@k converges to a reachability indicator, reflecting whether a prefix can lead to at least one successful continuation. In an explicit state graph, the limit ($k \rightarrow \infty$) can be computed in $O(|V|+|E|)$ time, offering a promising surrogate for direct credit assignment without the need to sample contrastive traces. As an initial validation, SR-PPO exhibits stable learning dynamics, along with consistent gains in Pass@128 success rates on mathematical reasoning benchmarks such as HMMT26 and AIME24.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SR-PPO, a single-rollout variant of PPO for language model RL. A token-level critic is trained to predict Pass@k success probability at each prefix using Monte Carlo outcomes from one rollout per prompt (derived from a Pass@1 attempt). The approach claims this yields a more selective and lower-variance advantage signal than Pass@1 or group-normalized methods like GRPO. It further states that Pass@k converges to a reachability indicator as k→∞, computable in O(|V|+|E|) time on an explicit state graph, and reports stable learning dynamics with consistent gains in Pass@128 on mathematical reasoning benchmarks such as HMMT26 and AIME24.
Significance. If the single-rollout critic can be shown to produce calibrated Pass@k estimates that genuinely improve upon Pass@1 without additional sampling, the method would offer a practical reduction in the cost of advantage estimation for LLM RL. The reachability limit provides a clean theoretical connection between Monte Carlo estimation and graph algorithms. However, the current description leaves the calibration mechanism and empirical robustness insufficiently substantiated to assess whether these benefits materialize.
major comments (3)
- [Abstract] Abstract: the claim that predicting Pass@k 'yields a more selective learning signal than Pass@1' and produces 'low-variance' advantages is not justified by the given construction. A single binary outcome per prompt supplies a label equivalent to a noisy Pass@1 success indicator; this supplies almost no information about the probability of at least one success across k independent continuations, directly undermining the asserted selectivity and variance reduction.
- [Abstract] Abstract: the statement that 'as k increases, Pass@k converges to a reachability indicator' and 'can be computed in O(|V|+|E|) time' is asserted without any derivation, recurrence relation, or proof sketch. Because the empirical results rely on finite-k calibration rather than the infinite-k limit, this gap affects the theoretical grounding of the proposed surrogate.
- [Abstract] Abstract: the empirical claims of 'stable learning dynamics' and 'consistent gains in Pass@128 success rates' are presented without error bars, number of random seeds, baseline ablations (e.g., direct Pass@1 advantage), dataset sizes, or statistics on prompt difficulty. These omissions make it impossible to evaluate whether the reported improvements are reliable or attributable to the critic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical justification and empirical presentation of SR-PPO. We address each major comment below, providing clarifications and committing to revisions where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that predicting Pass@k 'yields a more selective learning signal than Pass@1' and produces 'low-variance' advantages is not justified by the given construction. A single binary outcome per prompt supplies a label equivalent to a noisy Pass@1 success indicator; this supplies almost no information about the probability of at least one success across k independent continuations, directly undermining the asserted selectivity and variance reduction.
Authors: The single binary outcome from one rollout serves as a Monte Carlo sample for training the critic to regress toward the Pass@k probability (via the functional form 1-(1-p)^k). Across a large set of prompts the critic learns to map prefixes to calibrated probabilities that distinguish easy (high Pass@k) from marginal (low Pass@k) prefixes, yielding a graded token-level advantage. This is distinct from a raw Pass@1 label and avoids the variance of group normalization across divergent trajectories. We will revise the abstract and add a short paragraph in Section 3 clarifying the training objective and the resulting selectivity. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'as k increases, Pass@k converges to a reachability indicator' and 'can be computed in O(|V|+|E|) time' is asserted without any derivation, recurrence relation, or proof sketch. Because the empirical results rely on finite-k calibration rather than the infinite-k limit, this gap affects the theoretical grounding of the proposed surrogate.
Authors: We agree a formal derivation is needed. Pass@k = 1 - (1 - p)^k where p is the one-step success probability from the prefix; as k o ∞ this converges to the indicator 1_{p>0}, i.e., reachability. In an explicit state graph this indicator is obtained by a standard reachability query (BFS/DFS) from the prefix node, which runs in O(|V| + |E|) time. We will insert a concise proof sketch and recurrence in the main text (or appendix) of the revision. revision: yes
-
Referee: [Abstract] Abstract: the empirical claims of 'stable learning dynamics' and 'consistent gains in Pass@128 success rates' are presented without error bars, number of random seeds, baseline ablations (e.g., direct Pass@1 advantage), dataset sizes, or statistics on prompt difficulty. These omissions make it impossible to evaluate whether the reported improvements are reliable or attributable to the critic.
Authors: The full manuscript reports results over three random seeds with error bars, includes direct Pass@1 advantage and GRPO baselines, and provides dataset sizes (HMMT26, AIME24) together with prompt-difficulty stratification. We will move these details into the abstract or a dedicated experimental subsection and add an explicit ablation table comparing the Pass@k critic against a Pass@1 baseline to make the contribution of the critic transparent. revision: partial
Circularity Check
Pass@k critic target derived from single Pass@1 rollout reduces to Pass@1 prediction by construction
specific steps
-
fitted input called prediction
[Abstract]
"we use the critic to predict the Pass@k success probability at the prompt prefix, which is derived from a Pass@1 attempt. This choice yields a more selective learning signal than Pass@1: it discounts easily solved prefixes while prioritizing hard ones whose success probability remains marginal."
The critic is trained to output Pass@k probabilities, but the target label is taken directly from the binary outcome of a single Pass@1 rollout. Because a single binary success supplies no information about the probability of success in k independent continuations, the fitted critic is statistically equivalent to a Pass@1 predictor; the paper then presents its output as a distinct, lower-variance Pass@k advantage without contrastive sampling or normalization.
full rationale
The paper's core claim is that a token-level critic trained on Monte Carlo outcomes from one rollout per prompt can predict Pass@k success probability and yield a more selective advantage than Pass@1. However, the provided text explicitly states that this target 'is derived from a Pass@1 attempt,' making the supervision signal identical to a binary Pass@1 label. No additional sampling is performed to estimate the probability of at least one success in k trials, so the learned critic cannot produce a distinct Pass@k signal; the claimed selectivity is a relabeling of the same fitted input. The separate theoretical O(|V|+|E|) reachability result for k→∞ is not used to generate training labels, leaving the empirical method dependent on this reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Monte Carlo outcomes from one rollout per prompt yield unbiased estimates sufficient to train a calibrated Pass@k critic
- standard math Pass@k converges to a reachability indicator as k increases
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[3]
2025 , howpublished=
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL , author=. 2025 , howpublished=
2025
-
[4]
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with
Jasper Dekoninck and Nikola Jovanovi. Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with. 3rd AI for Math Workshop: Toward Self-Evolving Scientific Agents , year=
-
[5]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[6]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[7]
arXiv preprint arXiv:1506.02438 , year=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. arXiv preprint arXiv:1506.02438 , year=
-
[8]
arXiv preprint arXiv:1707.06347 , year =
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , title =. arXiv preprint arXiv:1707.06347 , year =
-
[9]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[10]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[11]
arXiv preprint arXiv:2107.03374 , year =
Chen, Mark and Tworek, Jerry and Jun, Heewoo and Yuan, Qiming and Pinto, Henrique Ponde de Oliveira and Kaplan, Jared and Edwards, Harri and Burda, Yuri and Joseph, Nicholas and Brockman, Greg and others , title =. arXiv preprint arXiv:2107.03374 , year =
-
[12]
The Eleventh International Conference on Learning Representations , year =
Wang, Xuezhi and Wei, Jason and Schuurmans, Dale and Le, Quoc and Chi, Ed and Narang, Sharan and Chowdhery, Aakanksha and Zhou, Denny , title =. The Eleventh International Conference on Learning Representations , year =
-
[13]
arXiv preprint arXiv:2110.14168 , year =
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , title =. arXiv preprint arXiv:2110.14168 , year =
-
[14]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[15]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year =
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year =
-
[16]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[17]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , title =. arXiv preprint arXiv:2402.03300 , year =
-
[18]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[19]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[20]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang. Math-Shepherd: Verify and Reinforce LLM s Step-by-step without Human Annotations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.510
-
[21]
arXiv preprint arXiv:2502.01456 , year=
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
-
[22]
2026 , eprint=
VIMPO: Value-Implicit Policy Optimization for LLMs , author=. 2026 , eprint=
2026
-
[23]
2026 , howpublished =
2026
-
[24]
Proceedings of the ACM Web Conference 2026 , pages =
Xi, Zhiheng and Liao, Chenyang and Li, Guanyu and Zhang, Zhihao and Chen, Wenxiang and Wang, Binghai and Jin, Senjie and Zhou, Yuhao and Guan, Jian and Wu, Wei and Ji, Tao and Gui, Tao and Zhang, Qi and Huang, Xuanjing , title =. Proceedings of the ACM Web Conference 2026 , pages =. 2026 , isbn =. doi:10.1145/3774904.3792551 , abstract =
-
[25]
2026 , url=
Zijian Wu and Xiangyan Liu and xinyuan zhang and Lingjun Chen and Fanqing Meng and Lingxiao Du and Yiran Zhao and Fanshi Zhang and Yaoqi Ye and Jiawei Wang and Zirui Wang and Jinjie Ni and Yufan Yang and Arvin Xu and Michael Qizhe Shieh , booktitle=. 2026 , url=
2026
-
[26]
arXiv preprint arXiv:2603.07980 , year=
\ OneMillion-Bench: How Far are Language Agents from Human Experts? , author=. arXiv preprint arXiv:2603.07980 , year=
-
[27]
Zixia Jia and Jiaqi Li and Yipeng Kang and Yuxuan Wang and Tong Wu and Quansen Wang and Xiaobo Wang and Shuyi Zhang and Junzhe Shen and Qing Li and Siyuan Qi and Yitao Liang and Di He and Zilong Zheng and Song-Chun Zhu , journal=. The. 2025 , url=
2025
-
[28]
Group-in-Group Policy Optimization for LLM Agent Training , url =
Feng, Lang and Xue, Zhenghai and Liu, Tingcong and An, Bo , booktitle =. Group-in-Group Policy Optimization for LLM Agent Training , url =
-
[29]
arXiv preprint arXiv:2605.10663 , year=
Evolving-RL: End-to-End Optimization of Experience-Driven Self-Evolving Capability within Agents , author=. arXiv preprint arXiv:2605.10663 , year=
-
[30]
The Fourteenth International Conference on Learning Representations , year=
Information gain-based policy optimization: A simple and effective approach for multi-turn search agents , author=. The Fourteenth International Conference on Learning Representations , year=
-
[31]
arXiv preprint arXiv:2505.16282 , year=
Arpo: End-to-end policy optimization for gui agents with experience replay , author=. arXiv preprint arXiv:2505.16282 , year=
-
[32]
Rewarding Progress: Scaling Automated Process Verifiers for
Amrith Setlur and Chirag Nagpal and Adam Fisch and Xinyang Geng and Jacob Eisenstein and Rishabh Agarwal and Alekh Agarwal and Jonathan Berant and Aviral Kumar , booktitle=. Rewarding Progress: Scaling Automated Process Verifiers for. 2025 , url=
2025
-
[33]
arXiv preprint arXiv:2602.03979 , year=
Likelihood-Based Reward Designs for General LLM Reasoning , author=. arXiv preprint arXiv:2602.03979 , year=
-
[34]
arXiv preprint arXiv:2509.18314 , year=
Exploiting tree structure for credit assignment in rl training of llms , author=. arXiv preprint arXiv:2509.18314 , year=
-
[35]
arXiv preprint arXiv:2508.17445 , year=
Treepo: Bridging the gap of policy optimization and efficacy and inference efficiency with heuristic tree-based modeling , author=. arXiv preprint arXiv:2508.17445 , year=
-
[36]
Mingjie Liu and Shizhe Diao and Ximing Lu and Jian Hu and Xin Dong and Yejin Choi and Jan Kautz and Yi Dong , booktitle=. Pro. 2026 , url=
2026
-
[37]
The Fourteenth International Conference on Learning Representations , year=
Hierarchy-of-Groups Policy Optimization for Long-Horizon Agentic Tasks , author=. The Fourteenth International Conference on Learning Representations , year=
-
[38]
arXiv preprint arXiv:2505.20732 , year=
SPA-RL: Reinforcing LLM Agents via Stepwise Progress Attribution , author=. arXiv preprint arXiv:2505.20732 , year=
-
[39]
International Conference on Learning Representations , year =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , title =. International Conference on Learning Representations , year =
-
[40]
Luo, Xufang and Zhang, Yuge and He, Zhiyuan and Wang, Zilong and Zhao, Siyun and Li, Dongsheng and Qiu, Luna K. and Yang, Yuqing , title =. arXiv preprint arXiv:2508.03680 , year =
-
[41]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , title =
-
[42]
arXiv preprint arXiv:2512.07461 , year=
Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning , author=. arXiv preprint arXiv:2512.07461 , year=
-
[43]
The Thirteenth International Conference on Learning Representations , year=
Mixture-of-Agents Enhances Large Language Model Capabilities , author=. The Thirteenth International Conference on Learning Representations , year=
-
[44]
Barres, Victor and Dong, Honghua and Ray, Soham and Si, Xujie and Narasimhan, Karthik , journal=. tau\^
-
[45]
and Leiserson, Charles E
Cormen, Thomas H. and Leiserson, Charles E. and Rivest, Ronald L. and Stein, Clifford , title =
-
[46]
, title =
Brier, Glenn W. , title =. Monthly Weather Review , volume =
-
[47]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.