Frequency-Aware Self-Supervised Music Representation Learning
Pith reviewed 2026-06-30 10:01 UTC · model grok-4.3
The pith
A visual JEPA trained on 2D spectrograms learns stronger music representations than 1D sequence models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
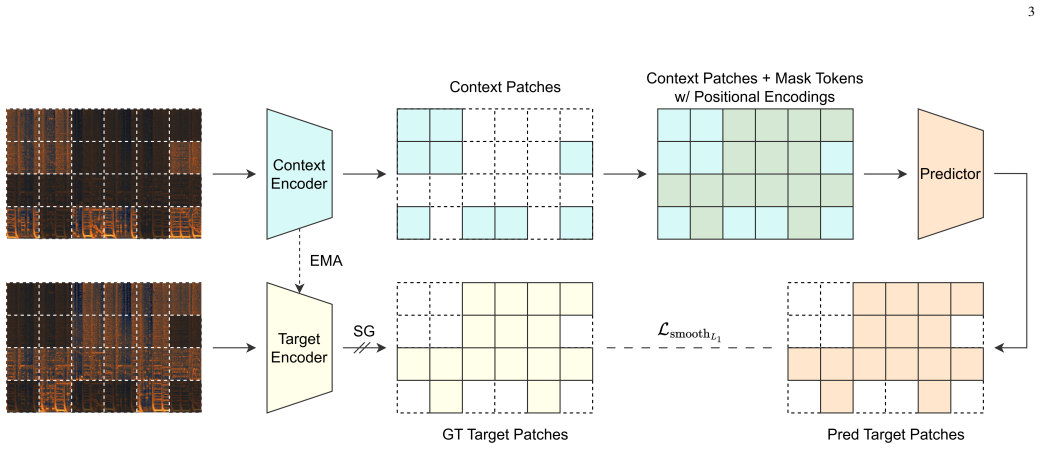
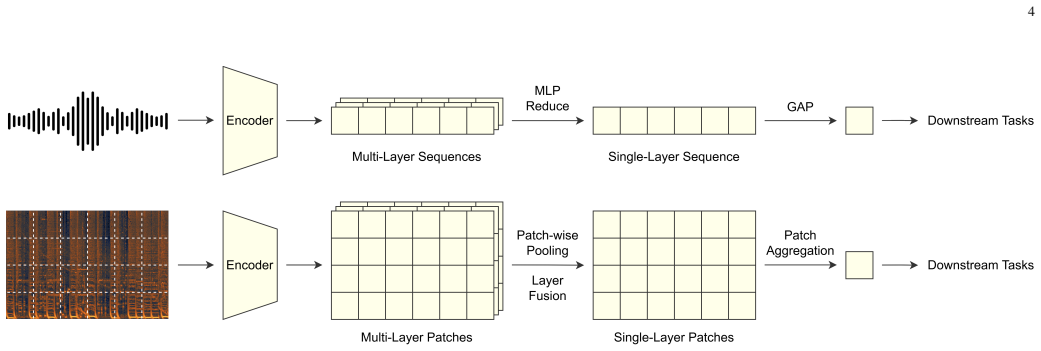
PupuJEPA demonstrates that a visual JEPA trained to predict latent embeddings of masked 2D spectrogram patches, after music-specific adaptations, produces representations that outperform 1D sequence-based SSL models on multiple music information retrieval tasks when evaluated by linear probing on the MARBLE benchmark.
What carries the argument
PupuJEPA, a visual Joint-Embedding Predictive Architecture that predicts latent embeddings of masked 2D spectrogram patches from unmasked context rather than applying masked language modeling to 1D sequences.
If this is right
- Representations from 2D patch prediction improve linear-probing accuracy on multiple MIR tasks relative to 1D sequence SSL models.
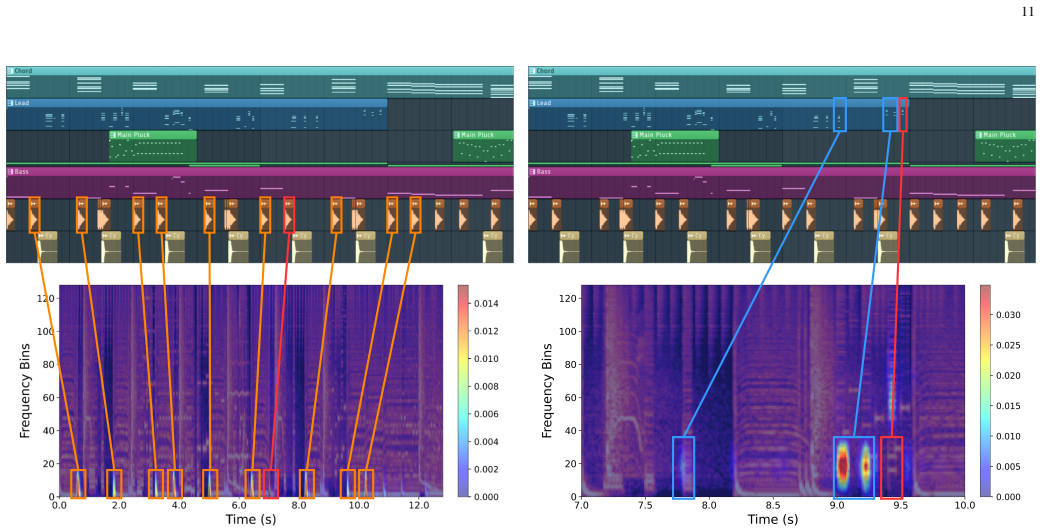
- Attention maps inside the model highlight musically meaningful time-frequency patterns.
- The same 2D JEPA approach can be applied to any audio task that benefits from explicit time-frequency grid structure.
Where Pith is reading between the lines
- If the 2D advantage holds, future music SSL work may shift from waveform or flattened-spectrogram inputs toward native 2D patch models.
- The approach could extend to other domains where signals have an intrinsic 2D grid, such as vibration analysis or radar returns.
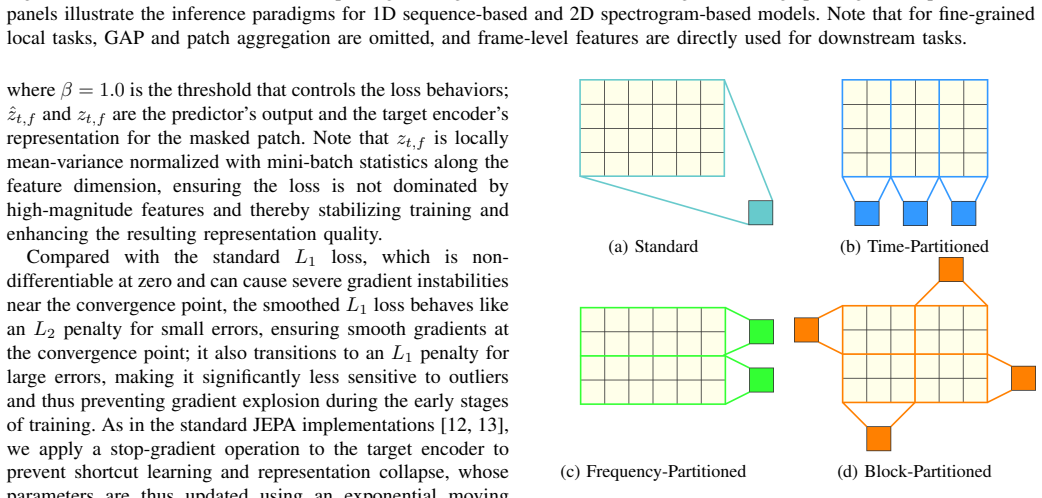
- Ablation results imply that the choice of masking strategy and prediction target in 2D space is at least as important as the base architecture.
Load-bearing premise
The domain-specific modifications to the visual JEPA architecture, training scheme, and inference are generally effective for music signals rather than tuned only to the MARBLE benchmark tasks.
What would settle it
Retraining the same base JEPA on the identical spectrograms but without the listed domain modifications and measuring whether linear-probing accuracy on MARBLE drops to or below the level of the best 1D SSL baseline.
Figures


read the original abstract
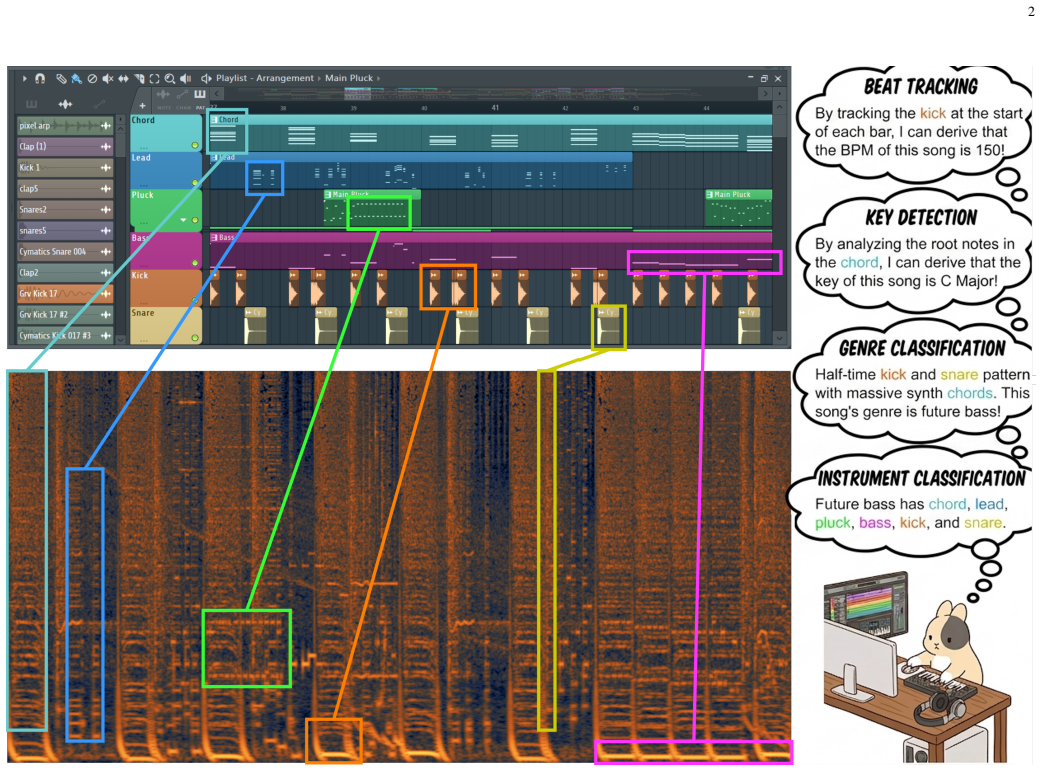
Self-supervised learning (SSL) has emerged as an essential paradigm for music information retrieval (MIR). While current SSL models achieve state-of-the-art performance across various MIR tasks, they typically treat audio as 1D sequences, either operating on time-domain waveforms or on flattened time-frequency-domain spectrograms. This discards the rich spatial and structural information in time-frequency representations and overlooks a fundamental intuition in music production. In particular, music is naturally represented as time-frequency grids in MIDI-based workflows, a structure that tightly corresponds to 2D spectrograms and inherently makes many MIR tasks trivial. Motivated by this intuition, we propose PupuJEPA, a visual Joint-Embedding Predictive Architecture (JEPA) that is trained directly on 2D spectrograms. Instead of applying masked language modeling (MLM) to 1D sequences, PupuJEPA learns robust representations by predicting the latent embeddings of masked 2D spectrogram patches from unmasked contexts. To optimally adapt such a visual framework to music signals, we also apply domain-specific modifications to model architecture, training scheme, and inference paradigm, with comprehensive ablation studies showing their effectiveness. Evaluations on the MARBLE benchmark show that PupuJEPA outperforms the 1D sequence-based SSL models across multiple MIR tasks in linear probing. Additionally, case studies of the attention maps also confirm that PupuJEPA captures musically meaningful patterns within the 2D time-frequency domain. Codes and checkpoints are available at: https://www.yichenggu.com/PupuJEPA/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PupuJEPA, a visual JEPA model trained directly on 2D spectrograms for self-supervised music representation learning. It applies domain-specific modifications to architecture, training scheme, and inference, claims these are validated by comprehensive ablations, and reports that the model outperforms 1D sequence-based SSL baselines across multiple MIR tasks on the MARBLE benchmark under linear probing, with qualitative attention-map case studies supporting musically meaningful patterns. Code and checkpoints are released.
Significance. If the empirical claims hold and the modifications are shown to be general rather than benchmark-tuned, the work could meaningfully shift SSL approaches in MIR toward explicit 2D time-frequency modeling. The public release of code and checkpoints is a clear strength for reproducibility.
major comments (1)
- [Abstract] Abstract: the claim that 'comprehensive ablation studies' demonstrate effectiveness of the domain-specific modifications to architecture, training scheme, and inference is load-bearing for the central contribution, yet all evaluations and ablations are confined to the MARBLE benchmark; this setup cannot distinguish genuine domain adaptation from design choices that overfit the benchmark's particular task suite and label distributions.
minor comments (1)
- [Abstract] The abstract states outperformance 'across multiple MIR tasks' but does not list the specific tasks or report per-task metrics with error bars or statistical significance.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our manuscript. We address the major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'comprehensive ablation studies' demonstrate effectiveness of the domain-specific modifications to architecture, training scheme, and inference is load-bearing for the central contribution, yet all evaluations and ablations are confined to the MARBLE benchmark; this setup cannot distinguish genuine domain adaptation from design choices that overfit the benchmark's particular task suite and label distributions.
Authors: We appreciate the referee's observation that our ablation studies and evaluations are performed exclusively on the MARBLE benchmark. MARBLE was selected because it aggregates multiple MIR tasks with heterogeneous label distributions and evaluation protocols, providing a more rigorous test than single-task benchmarks. The ablations demonstrate that each domain-specific modification yields measurable gains across this task suite rather than isolated improvements. Nevertheless, we acknowledge that this does not fully rule out benchmark-specific tuning. In the revised manuscript we will qualify the abstract claim to specify that the ablations show effectiveness on MARBLE, add a limitations paragraph discussing the scope of the current evaluation, and note the value of future cross-benchmark validation. revision: partial
Circularity Check
No circularity: empirical proposal with external benchmark evaluation
full rationale
The paper proposes PupuJEPA as an adaptation of visual JEPA to 2D spectrograms, reports linear-probe results on the external MARBLE benchmark, and includes ablations confined to that benchmark. No mathematical derivation chain, equations, or predictions are presented that reduce by construction to fitted inputs or self-citations. The central claims rest on empirical comparisons rather than any self-definitional, fitted-prediction, or uniqueness-imported steps. This is the expected non-finding for a model-proposal paper whose results are externally falsifiable on a public benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MusicCNN: Pre-trained Convo- lutional Neural Networks for Music Audio Tagging,
J. Pons and X. Serra, “MusicCNN: Pre-trained Convo- lutional Neural Networks for Music Audio Tagging,” in Proc. ISMIR, 2019
2019
-
[2]
Codified Audio Language Modeling Learns Useful Representations for Music Information Retrieval,
R. Castellon, C. Donahue, and P. Liang, “Codified Audio Language Modeling Learns Useful Representations for Music Information Retrieval,” inISMIR, 2021, pp. 88– 96
2021
-
[3]
Jukebox: A Generative Model for Music
P. Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever, “Jukebox: A generative model for music,”arXiv:2005.00341, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[4]
Contrastive Learning of Musical Representations,
J. Spijkervet and J. A. Burgoyne, “Contrastive Learning of Musical Representations,” inISMIR, 2021, pp. 673– 681
2021
-
[5]
Supervised and Unsu- pervised Learning of Audio Representations for Music Understanding,
M. C. McCallum, F. Korzeniowski, S. Oramas, F. Gouyon, and A. F. Ehmann, “Supervised and Unsu- pervised Learning of Audio Representations for Music Understanding,” inISMIR, 2022, pp. 256–263
2022
-
[6]
BERT: Pre-training of Deep Bidirectional Transformers for Lan- guage Understanding,
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Lan- guage Understanding,” inProc. NAACL, 2019, pp. 4171– 4186
2019
-
[7]
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training,
Y . Li, R. Yuan, G. Zhang, Y . Ma, X. Chen, H. Yin, C. Xiao, C. Lin, A. Ragni, E. Benetos, N. Gyenge, R. B. Dannenberg, R. Liu, W. Chen, G. Xia, Y . Shi, W. Huang, Z. Wang, Y . Guo, and J. Fu, “MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training,” inProc. ICLR, 2024
2024
-
[8]
High Fidelity Neural Audio Compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High Fidelity Neural Audio Compression,”Trans. Mach. Learn. Res., vol. 2023, 2023
2023
-
[9]
A Foundation Model for Music Informatics,
M. Won, Y . Hung, and D. Le, “A Foundation Model for Music Informatics,” inProc. Int. Conf. Acoust. Speech Signal Process., 2024, pp. 1226–1230
2024
-
[10]
MuQ: Self-Supervised Music Representation Learning with Mel Residual Vector Quantization,
H. Zhu, Y . Zhou, H. Chen, J. Yu, Z. Ma, R. Gu, Y . Luo, W. Tan, and X. Chen, “MuQ: Self-Supervised Music Representation Learning with Mel Residual Vector Quantization,”IEEE/ACM Trans. Audio Speech Lang. Process., 2025
2025
-
[11]
Masked Autoencoders Are Scalable Vision Learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. B. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” inProc. CVPR, 2022, pp. 15 979–15 988
2022
-
[12]
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture,
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. G. Rabbat, Y . LeCun, and N. Ballas, “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture,” inProc. CVPR, 2023, pp. 15 619–15 629
2023
-
[13]
Revisiting Fea- ture Prediction for Learning Visual Representations from Video,
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . LeCun, M. Assran, and N. Ballas, “Revisiting Fea- ture Prediction for Learning Visual Representations from Video,”Trans. Mach. Learn. Res., vol. 2024, 2024
2024
-
[14]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zho- luset al., “V-JEPA 2: Self-supervised Video Mod- els Enable Understanding, Prediction and Planning,” arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
iBOT: Image BERT Pre-Training with Online Tokenizer
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong, “iBOT: Image BERT Pre-Training with Online Tokenizer,”arXiv:2111.07832, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Emerging Properties in Self-Supervised Vision Transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging Properties in Self-Supervised Vision Transformers,” inProc. ICCV, 2021, pp. 9630–9640. 13
2021
-
[17]
DINOv2: Learning Robust Visual Features without Supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P. Huang, S. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. J ´egou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “DINOv2: Learning Robust Visual Features without Super...
2024
-
[18]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoaet al., “Dinov3,”arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Masked Autoencoders that Listen,
P. Huang, H. Xu, J. Li, A. Baevski, M. Auli, W. Galuba, F. Metze, and C. Feichtenhofer, “Masked Autoencoders that Listen,” inProc. NeurIPS, 2022
2022
-
[20]
AudioMAE++: Learning Better Masked Audio Representations with Swiglu FFNS,
S. Yadav, S. Theodoridis, and Z. Tan, “AudioMAE++: Learning Better Masked Audio Representations with Swiglu FFNS,” inIEEE Int. Workshop Mach. Learn. Signal Process., 2025, pp. 1–6
2025
-
[21]
Masked Spectrogram Modeling using Masked Autoencoders for Learning General-purpose Au- dio Representation,
D. Niizumi, D. Takeuchi, Y . Ohishi, N. Harada, and K. Kashino, “Masked Spectrogram Modeling using Masked Autoencoders for Learning General-purpose Au- dio Representation,” inProc. NeurIPS, 2021, pp. 1–24
2021
-
[22]
Masked Spectrogram Prediction for Self-Supervised Audio Pre- Training,
D. Chong, H. Wang, P. Zhou, and Q. Zeng, “Masked Spectrogram Prediction for Self-Supervised Audio Pre- Training,” inProc. Int. Conf. Acoust. Speech Signal Process., 2023, pp. 1–5
2023
-
[23]
MAE-AST: Masked Autoencoding Audio Spectrogram Transformer,
A. Baade, P. Peng, and D. Harwath, “MAE-AST: Masked Autoencoding Audio Spectrogram Transformer,” inProc Interspeech, 2022, pp. 2438–2442
2022
-
[24]
BEATs: Audio Pre-Training with Acoustic Tokenizers,
S. Chen, Y . Wu, C. Wang, S. Liu, D. Tompkins, Z. Chen, W. Che, X. Yu, and F. Wei, “BEATs: Audio Pre-Training with Acoustic Tokenizers,” inProc. ICML, 2023, pp. 5178–5193
2023
-
[25]
EAT: Self-Supervised Pre-Training with Efficient Audio Transformer,
W. Chen, Y . Liang, Z. Ma, Z. Zheng, and X. Chen, “EAT: Self-Supervised Pre-Training with Efficient Audio Transformer,” inProc. IJCAI, 2024, pp. 3807–3815
2024
-
[26]
Self-Supervised Audio Teacher-Student Transformer for Both Clip-Level and Frame-Level Tasks,
X. Li, N. Shao, and X. Li, “Self-Supervised Audio Teacher-Student Transformer for Both Clip-Level and Frame-Level Tasks,”IEEE/ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 1336–1351, 2024
2024
-
[27]
Masked Modeling Duo: Towards a Univer- sal Audio Pre-Training Framework,
D. Niizumi, D. Takeuchi, Y . Ohishi, N. Harada, and K. Kashino, “Masked Modeling Duo: Towards a Univer- sal Audio Pre-Training Framework,”IEEE/ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 2391–2406, 2024
2024
-
[28]
Inves- tigating Design Choices in Joint-Embedding Predictive Architectures for General Audio Representation Learn- ing,
A. Riou, S. Lattner, G. Hadjeres, and G. Peeters, “Inves- tigating Design Choices in Joint-Embedding Predictive Architectures for General Audio Representation Learn- ing,” inProc. Int. Conf. Acoust. Speech Signal Process. Workshop, 2024, pp. 680–684
2024
-
[29]
Masked Latent Prediction and Classification for Self- Supervised Audio Representation Learning,
A. Quelennec, P. Chouteau, G. Peeters, and S. Essid, “Masked Latent Prediction and Classification for Self- Supervised Audio Representation Learning,” inProc. Int. Conf. Acoust. Speech Signal Process., 2025, pp. 1–5
2025
-
[30]
MATPAC++: Enhanced Masked Latent Predic- tion for Self-Supervised Audio Representation Learning,
——, “MATPAC++: Enhanced Masked Latent Predic- tion for Self-Supervised Audio Representation Learning,” arXiv:2508.12709, 2025
-
[31]
A-Jepa: Joint-Embedding Predictive Architecture can Listen,
Z. Fei, M. Fan, and J. Huang, “A-Jepa: Joint-Embedding Predictive Architecture can Listen,”arXiv:2311.15830, 2023
-
[32]
Audio-JEPA: Joint-Embedding Predictive Architecture for Audio Representation Learning,
L. Tuncay, E. Labb ´e, E. Benetos, and T. Pellegrini, “Audio-JEPA: Joint-Embedding Predictive Architecture for Audio Representation Learning,”arXiv:2507.02915, 2025
-
[33]
Scaling Up Masked Audio Encoder Learning for General Audio Classification,
H. Dinkel, Z. Yan, Y . Wang, J. Zhang, Y . Wang, and B. Wang, “Scaling Up Masked Audio Encoder Learning for General Audio Classification,” inProc. Interspeech, 2024
2024
-
[34]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weis- senborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” inProc. ICLR, 2021
2021
-
[35]
RoFormer: Enhanced transformer with Rotary Posi- tion Embedding,
J. Su, M. H. M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: Enhanced transformer with Rotary Posi- tion Embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[36]
GLU Variants Improve Transformer
N. Shazeer, “GLU Variants Improve Transformer,” arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[37]
MARBLE: Music Audio Representation Benchmark for Universal Evaluation,
R. Yuan, Y . Ma, Y . Li, G. Zhang, X. Chen, H. Yin, L. Zhuo, Y . Liu, J. Huang, Z. Tian, B. Deng, N. Wang, C. Lin, E. Benetos, A. Ragni, N. Gyenge, R. B. Dan- nenberg, W. Chen, G. Xia, W. Xue, S. Liu, S. Wang, R. Liu, Y . Guo, and J. Fu, “MARBLE: Music Audio Representation Benchmark for Universal Evaluation,” in Proc. NeurIPS, 2023
2023
-
[38]
Layer-Wise Investigation of Large-Scale Self-Supervised Music Representation Models,
Y . Zhou, H. Zhu, and H. Chen, “Layer-Wise Investigation of Large-Scale Self-Supervised Music Representation Models,”arXiv:2505.16306, 2025
-
[39]
1000 songs for emotional analysis of music,
M. Soleymani, M. N. Caro, E. M. Schmidt, C. Sha, and Y . Yang, “1000 songs for emotional analysis of music,” inProc. ACM MM, 2013, pp. 1–6
2013
-
[40]
Two Data Sets for Tempo Estimation and Key Detection in Electronic Dance Music Annotated from User Corrections,
P. Knees, ´A. Faraldo, P. Herrera, R. V ogl, S. B ¨ock, F. H ¨orschl¨ager, and M. L. Goff, “Two Data Sets for Tempo Estimation and Key Detection in Electronic Dance Music Annotated from User Corrections,” inProc. ISMIR, 2015, pp. 364–370
2015
-
[41]
Melody tran- scription via generative pre-training,
C. Donahue, J. Thickstun, and P. Liang, “Melody tran- scription via generative pre-training,” inProc. ISMIR, 2022, pp. 485–492
2022
-
[42]
MIR EV AL: A Transparent Implementation of Common MIR Met- rics,
C. Raffel, B. McFee, E. J. Humphrey, J. Salamon, O. Ni- eto, D. Liang, D. P. Ellis, and C. C. Raffel, “MIR EV AL: A Transparent Implementation of Common MIR Met- rics,” inProc. ISMIR, vol. 10, 2014, p. 2014
2014
-
[43]
Musical Genre Classifica- tion of Audio Signals,
G. Tzanetakis and P. R. Cook, “Musical Genre Classifica- tion of Audio Signals,”IEEE/ACM Trans. Audio Speech Lang. Process., vol. 10, no. 5, pp. 293–302, 2002
2002
-
[44]
The MTG-Jamendo Dataset for Automatic Music Tagging,
D. Bogdanov, M. Won, P. Tovstogan, A. Porter, and X. Serra, “The MTG-Jamendo Dataset for Automatic Music Tagging,” inProc. ICML, 2019, pp. 1–3
2019
-
[45]
Evaluation of Algorithms Using Games: The Case of Music Tagging,
E. Law, K. West, M. I. Mandel, M. Bay, and J. S. Downie, “Evaluation of Algorithms Using Games: The Case of Music Tagging,” inProc. ISMIR, 2009, pp. 387–392
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.