Gaussian Mean Field Variational Inference can Overestimate Predictive Variance
Pith reviewed 2026-06-25 19:46 UTC · model grok-4.3
The pith
Mean-field variational inference overestimates predictive variance on in-distribution test points in Bayesian linear regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
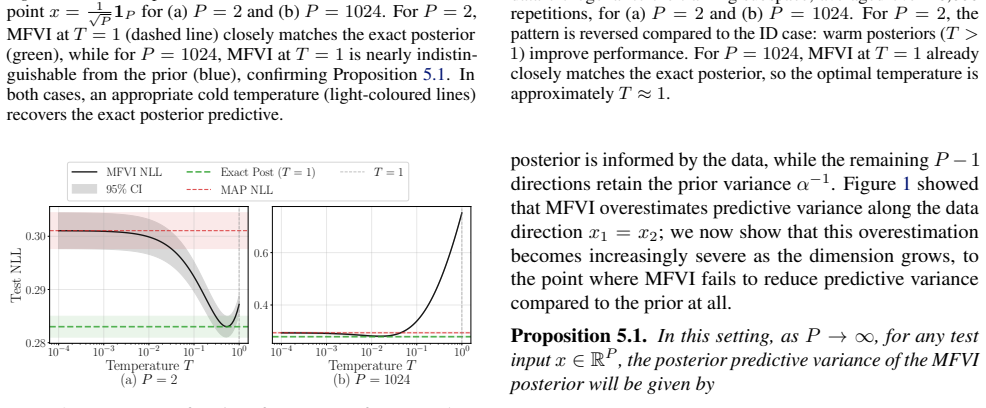
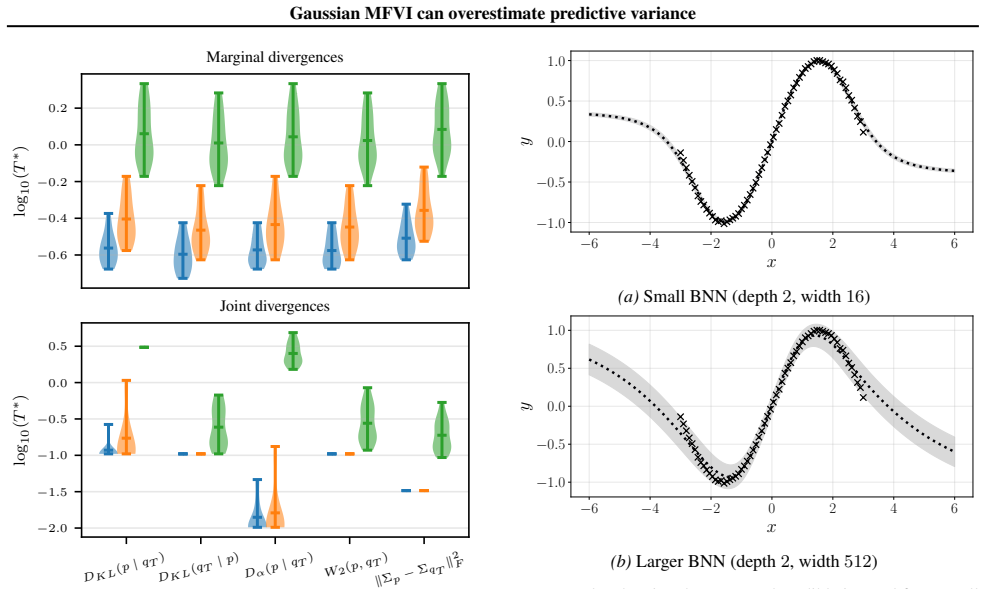
By analyzing conjugate Bayesian linear regression, the authors show that the MFVI posterior underestimates variance in parameter space but overestimates predictive variance compared to the exact posterior, with the overestimation occurring in directions where training data concentrates. This leads to the result that for a test point drawn from the training distribution, MFVI's expected predictive variance exceeds that of the exact posterior. They also identify a pathological case where MFVI fails to reduce predictive variance relative to the prior on in-distribution data and connect the effect to the cold posterior phenomenon by showing that temperature scaling yields predictions closer to t
What carries the argument
The directional decomposition of predictive variance under the mean-field Gaussian approximation versus the exact conjugate posterior in Bayesian linear regression.
If this is right
- For test points drawn from the training distribution, MFVI's expected predictive variance exceeds that of the exact posterior.
- If MFVI underestimates predictive variance in some directions it necessarily overestimates in others, with overestimation concentrated where training data lies.
- Varying the temperature in the MFVI objective can correct the overestimation and produce predictive distributions closer to the exact posterior.
- A pathological case exists in which MFVI fails to reduce predictive variance below the prior level on in-distribution data.
Where Pith is reading between the lines
- The directional bias may partly explain why colder posteriors often improve calibration in variational inference applications.
- The finding suggests evaluating variational methods on predictive quantities rather than parameter-space variance alone when assessing uncertainty quality.
- Similar overestimation effects could arise in non-conjugate or non-Gaussian settings where exact posteriors cannot be computed for comparison.
Load-bearing premise
The central results rely on conjugate Gaussian priors and likelihoods in Bayesian linear regression that permit closed-form exact posteriors and predictive distributions.
What would settle it
Compute the expected predictive variance for a test point sampled from the training distribution under both MFVI and the exact posterior in a simple Bayesian linear regression model and check whether the MFVI value is larger.
Figures





read the original abstract
Mean Field Variational Inference (MFVI) is widely understood to underestimate posterior variance. By analysing conjugate Bayesian Linear Regression (BLR), we show that this characterization is incomplete: while MFVI underestimates the variance in parameter space, it can overestimate the predictive variance compared to the exact posterior. We show that if the MFVI posterior underestimates predictive variances in some directions, it necessarily overestimates them in others. Crucially, this overestimation occurs in directions where the training data concentrates. This leads to the surprising result that, for a test point drawn from the training distribution, MFVI's expected predictive variance exceeds that of the exact posterior. We demonstrate a pathological case of this effect, where the MFVI posterior fails to reduce predictive variance compared to the prior on in distribution data. We connect these results to the Cold Posterior Effect, arguing that varying the temperature can correct this overestimation, yielding predictions closer to those of the exact posterior. We validate our theory on synthetic and real-world regression tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes Gaussian mean-field variational inference (MFVI) for conjugate Bayesian linear regression (BLR). It shows that MFVI underestimates posterior variance in parameter space yet can overestimate predictive variance for test points drawn from the training distribution. The analysis establishes that underestimation in some directions necessarily implies overestimation in others (particularly those aligned with the data Gram matrix), yielding the result that the expected predictive variance under MFVI exceeds that of the exact posterior. The work identifies a pathological case where MFVI predictive variance fails to contract relative to the prior on in-distribution data, connects the phenomenon to the cold posterior effect via temperature scaling, and validates the claims on synthetic and real regression tasks.
Significance. If the central claims hold, the result is significant because it supplies a precise, closed-form counterexample to the standard characterization of MFVI as uniformly underestimating variance. The conjugate BLR setting permits direct comparison of the MFVI diagonal covariance (reciprocals of the diagonal of the posterior precision) against the exact posterior covariance via quadratic forms x^T D x versus x^T Sigma x, reducing to trace comparisons with the empirical Gram matrix. This directional trade-off and the explicit link to temperature correction constitute a substantive refinement of variational inference theory with immediate implications for predictive calibration.
minor comments (3)
- [§3] §3 (or the section deriving the predictive variance): the reduction from the quadratic-form comparison to trace(D X^T X) versus trace(Sigma X^T X) is central; an explicit intermediate equation would make the step from the positive-semidefinite ordering to the expected-variance inequality fully transparent.
- [Pathological case section] The pathological case (where MFVI predictive variance equals the prior variance on in-distribution points) is load-bearing for the overestimation claim; a short appendix deriving the exact condition on the prior precision and Gram matrix would strengthen reproducibility.
- [Notation introduction] Notation for the mean-field covariance (denoted D in the skeptic summary) should be introduced with an equation number at first use and cross-referenced when the trace comparison is stated.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our manuscript, as well as the recommendation for minor revision. No major comments were provided in the report, so we have no specific points to address point-by-point. We will make any minor editorial or formatting changes requested by the editor or in a subsequent round if applicable.
Circularity Check
No significant circularity identified
full rationale
The paper's central result follows from explicit closed-form expressions for both the exact posterior and the optimal MFVI Gaussian in conjugate Bayesian linear regression. The MFVI covariance is defined directly as the diagonal of the inverse posterior precision matrix, and the predictive-variance comparison is obtained by evaluating the resulting quadratic forms on the empirical data Gram matrix; this algebraic identity holds without fitted parameters, self-citations, or ansatzes that presuppose the target inequality. The argument is therefore self-contained and does not reduce any claimed prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conjugate Gaussian prior and likelihood in Bayesian linear regression permit closed-form computation of both the exact posterior and the exact predictive distribution.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2604.21407 , year=
Even More Guarantees for Variational Inference in the Presence of Symmetries , author=. arXiv preprint arXiv:2604.21407 , year=
-
[2]
Journal of Machine Learning Research , volume=
Variational inference for uncertainty quantification: An analysis of trade-offs , author=. Journal of Machine Learning Research , volume=
-
[3]
arXiv preprint arXiv:2604.18310 , year=
Symmetry Guarantees Statistic Recovery in Variational Inference , author=. arXiv preprint arXiv:2604.18310 , year=
-
[4]
Foundations and Trends
Graphical models, exponential families, and variational inference , author=. Foundations and Trends. 2008 , publisher=
2008
-
[5]
arXiv preprint arXiv:2502.01861 , year=
Learning Hyperparameters via a Data-Emphasized Variational Objective , author=. arXiv preprint arXiv:2502.01861 , year=
-
[6]
Neural computation , volume=
Bayesian interpolation , author=. Neural computation , volume=. 1992 , publisher=
1992
-
[7]
Journal of the American statistical Association , volume=
Variational inference: A review for statisticians , author=. Journal of the American statistical Association , volume=. 2017 , publisher=
2017
-
[8]
ICLR: international conference on learning representations , pages=
Adam: A method for stochastic gradient descent , author=. ICLR: international conference on learning representations , pages=
-
[9]
2023 , howpublished =
Kelly, Markelle and Longjohn, Rachel and Nottingham, Kolby , title =. 2023 , howpublished =
2023
-
[10]
Machine learning , volume=
An introduction to variational methods for graphical models , author=. Machine learning , volume=. 1999 , publisher=
1999
-
[11]
Uncertainty in Artificial Intelligence , pages=
The shrinkage-delinkage trade-off: An analysis of factorized gaussian approximations for variational inference , author=. Uncertainty in Artificial Intelligence , pages=. 2023 , organization=
2023
-
[12]
arXiv preprint arXiv:2002.02405 , year=
How good is the bayes posterior in deep neural networks really? , author=. arXiv preprint arXiv:2002.02405 , year=
arXiv 2002
-
[13]
arXiv preprint arXiv:2506.14262 , year=
Knowledge Adaptation as Posterior Correction , author=. arXiv preprint arXiv:2506.14262 , year=
-
[14]
Advances in neural information processing systems , volume=
Linear response methods for accurate covariance estimates from mean field variational Bayes , author=. Advances in neural information processing systems , volume=
-
[15]
Journal of machine learning research , volume=
Covariances, robustness, and variational Bayes , author=. Journal of machine learning research , volume=
-
[16]
Divergence Measures and Message Passing , author =
-
[17]
Two problems with variational expectation maximisation for time series models , booktitle=
Turner, Richard Eric and Sahani, Maneesh , editor=. Two problems with variational expectation maximisation for time series models , booktitle=. 2011 , pages=
2011
-
[18]
Transactions on Machine Learning Research , year=
The cold posterior effect indicates underfitting, and cold posteriors represent a fully bayesian method to mitigate it , author=. Transactions on Machine Learning Research , year=
-
[19]
International conference on machine learning , pages=
What are Bayesian neural network posteriors really like? , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[20]
Uncertainty in Artificial Intelligence , pages=
Data augmentation in Bayesian neural networks and the cold posterior effect , author=. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
2022
-
[21]
arXiv preprint arXiv:2008.00029 , year=
Cold posteriors and aleatoric uncertainty , author=. arXiv preprint arXiv:2008.00029 , year=
arXiv 2008
-
[22]
Third Symposium on Advances in Approximate Bayesian Inference , year=
Why cold posteriors? on the suboptimal generalization of optimal bayes estimates , author=. Third Symposium on Advances in Approximate Bayesian Inference , year=
-
[23]
arXiv preprint arXiv:2008.05912 , year=
A statistical theory of cold posteriors in deep neural networks , author=. arXiv preprint arXiv:2008.05912 , year=
arXiv 2008
-
[24]
Advances in neural information processing systems , volume=
Disentangling the roles of curation, data-augmentation and the prior in the cold posterior effect , author=. Advances in neural information processing systems , volume=
-
[25]
arXiv preprint arXiv:2205.13900 , year=
How tempering fixes data augmentation in Bayesian neural networks , author=. arXiv preprint arXiv:2205.13900 , year=
-
[26]
arXiv preprint arXiv:2102.06571 , year=
Bayesian neural network priors revisited , author=. arXiv preprint arXiv:2102.06571 , year=
-
[27]
Advances in neural information processing systems , volume=
On uncertainty, tempering, and data augmentation in bayesian classification , author=. Advances in neural information processing systems , volume=
-
[28]
arXiv preprint arXiv:2206.11173 , year=
Cold posteriors through pac-bayes , author=. arXiv preprint arXiv:2206.11173 , year=
-
[29]
NeurIPS 2021 Competitions and Demonstrations Track , pages=
Evaluating approximate inference in Bayesian deep learning , author=. NeurIPS 2021 Competitions and Demonstrations Track , pages=. 2022 , organization=
2021
-
[30]
arXiv preprint arXiv:2402.17641 , year=
Variational learning is effective for large deep networks , author=. arXiv preprint arXiv:2402.17641 , year=
-
[31]
arXiv preprint arXiv:2403.01272 , year=
Can a Confident Prior Replace a Cold Posterior? , author=. arXiv preprint arXiv:2403.01272 , year=
-
[32]
Biometrika , pages=
Predictive performance of power posteriors , author=. Biometrika , pages=. 2025 , publisher=
2025
-
[33]
arXiv preprint arXiv:2410.05757 , year=
Temperature Optimization for Bayesian Deep Learning , author=. arXiv preprint arXiv:2410.05757 , year=
-
[34]
arXiv preprint arXiv:1903.05779 , year=
Functional variational Bayesian neural networks , author=. arXiv preprint arXiv:1903.05779 , year=
Pith/arXiv arXiv 1903
-
[35]
arXiv preprint arXiv:2011.09421 , year=
Understanding variational inference in function-space , author=. arXiv preprint arXiv:2011.09421 , year=
arXiv 2011
-
[36]
arXiv preprint arXiv:2406.04317 , year=
Regularized kl-divergence for well-defined function-space variational inference in bayesian neural networks , author=. arXiv preprint arXiv:2406.04317 , year=
-
[37]
arXiv preprint arXiv:2410.11067 , year=
Variational inference in location-scale families: Exact recovery of the mean and correlation matrix , author=. arXiv preprint arXiv:2410.11067 , year=
-
[38]
arXiv preprint arXiv:1906.11537 , year=
'In-Between'Uncertainty in Bayesian Neural Networks , author=. arXiv preprint arXiv:1906.11537 , year=
Pith/arXiv arXiv 1906
-
[40]
Practical Deep Learning with
Osawa, Kazuki and Swaroop, Siddharth and Khan, Mohammad Emtiyaz and Jain, Anirudh and Eschenhagen, Runa and Turner, Richard E and Yokota, Rio , journal=. Practical Deep Learning with
-
[41]
2022 , eprint=
Partitioned Variational Inference: A Framework for Probabilistic Federated Learning , author=. 2022 , eprint=
2022
-
[42]
arXiv preprint arXiv:2510.23684 , year=
VIKING: Deep variational inference with stochastic projections , author=. arXiv preprint arXiv:2510.23684 , year=
-
[43]
arXiv preprint arXiv:1611.07476 , year=
Eigenvalues of the hessian in deep learning: Singularity and beyond , author=. arXiv preprint arXiv:1611.07476 , year=
-
[44]
International Conference on Artificial Intelligence and Statistics , pages=
Wide mean-field Bayesian neural networks ignore the data , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
2022
-
[45]
Variational learning of inducing variables in sparse
Titsias, Michalis , booktitle=. Variational learning of inducing variables in sparse. 2009 , organization=
2009
-
[46]
1992 , publisher=
MacKay, David JC , journal=. 1992 , publisher=
1992
-
[47]
Kingma, Diederik P and Ba, Jimmy Lei , booktitle=
-
[48]
The shrinkage-delinkage trade-off: An analysis of factorized
Margossian, Charles C and Saul, Lawrence K , booktitle=. The shrinkage-delinkage trade-off: An analysis of factorized. 2023 , organization=
2023
-
[49]
How good is the
Wenzel, Florian and Roth, Kevin and Veeling, Bastiaan and Swiatkowski, Jakub and Tran, Linh and Mandt, Stephan and Snoek, Jasper and Salimans, Tim and Jenatton, Rodolphe and Nowozin, Sebastian , booktitle=. How good is the. 2020 , organization=
2020
-
[50]
Linear response methods for accurate covariance estimates from mean field variational
Giordano, Ryan J and Broderick, Tamara and Jordan, Michael I , journal=. Linear response methods for accurate covariance estimates from mean field variational
-
[51]
Covariances, robustness, and variational
Giordano, Ryan and Broderick, Tamara and Jordan, Michael I , journal=. Covariances, robustness, and variational
-
[52]
The cold posterior effect indicates underfitting, and cold posteriors represent a fully
Zhang, Yijie and Wu, Yi-Shan and Ortega, Luis A and Masegosa, Andres R , journal=. The cold posterior effect indicates underfitting, and cold posteriors represent a fully
-
[53]
What are
Izmailov, Pavel and Vikram, Sharad and Hoffman, Matthew D and Wilson, Andrew Gordon Gordon , booktitle=. What are. 2021 , organization=
2021
-
[54]
Data augmentation in
Nabarro, Seth and Ganev, Stoil and Garriga-Alonso, Adri. Data augmentation in. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
2022
-
[55]
ICML Workshop on Uncertainty and Robustness in Deep Learning , year=
Cold posteriors and aleatoric uncertainty , author=. ICML Workshop on Uncertainty and Robustness in Deep Learning , year=
-
[56]
Why cold posteriors? on the suboptimal generalization of optimal
Zeno, Chen and Golan, Itay and Pakman, Ari and Soudry, Daniel , booktitle=. Why cold posteriors? on the suboptimal generalization of optimal
-
[57]
International Conference on Learning Representations , year=
A statistical theory of cold posteriors in deep neural networks , author=. International Conference on Learning Representations , year=
-
[58]
How tempering fixes data augmentation in
Bachmann, Gregor and Noci, Lorenzo and Hofmann, Thomas , booktitle=. How tempering fixes data augmentation in. 2022 , organization=
2022
-
[59]
International Conference on Learning Representations , year=
Fortuin, Vincent and Garriga-Alonso, Adri. International Conference on Learning Representations , year=
-
[60]
On uncertainty, tempering, and data augmentation in
Kapoor, Sanyam and Maddox, Wesley J and Izmailov, Pavel and Wilson, Andrew G , journal=. On uncertainty, tempering, and data augmentation in
-
[61]
Cold posteriors through
Pitas, Konstantinos and Arbel, Julyan , booktitle=. Cold posteriors through
-
[62]
Evaluating approximate inference in
Wilson, Andrew Gordon and Izmailov, Pavel and Hoffman, Matthew D and Gal, Yarin and Li, Yingzhen and Pradier, Melanie F and Vikram, Sharad and Foong, Andrew and Lotfi, Sanae and Farquhar, Sebastian , booktitle=. Evaluating approximate inference in. 2022 , organization=
2022
-
[63]
International Conference on Machine Learning , pages=
Variational learning is effective for large deep networks , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[64]
Temperature Optimization for
Ng, Kenyon and van der Heide, Chris and Hodgkinson, Liam and Wei, Susan , booktitle=. Temperature Optimization for. 2025 , organization=
2025
-
[65]
Functional variational
Sun, Shengyang and Zhang, Guodong and Shi, Jiaxin and Grosse, Roger , booktitle=. Functional variational
-
[66]
Symposium on Advances in Approximate Bayesian Inference , year=
Understanding variational inference in function-space , author=. Symposium on Advances in Approximate Bayesian Inference , year=
-
[67]
Well-Defined Function-Space Variational Inference in
Cinquin, Tristan and Bamler, Robert , booktitle=. Well-Defined Function-Space Variational Inference in. 2025 , organization=
2025
-
[68]
International Conference on Artificial Intelligence and Statistics , pages=
Variational inference in location-scale families: Exact recovery of the mean and correlation matrix , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2025 , organization=
2025
-
[69]
'In-Between' Uncertainty in
Foong, Andrew YK and Li, Yingzhen and Hern. 'In-Between' Uncertainty in. ICML Workshop on Uncertainty and Robustness in Deep Learning , year=
-
[70]
Rasmussen, Carl Edward and Williams, Christopher K. I. , year = 2005, month = nov, eprint =. doi:10.7551/mitpress/3206.001.0001 , isbn =
-
[71]
Advances in Neural Information Processing Systems , year=
Fadel, Samuel G and Roy, Hrittik and Kr. Advances in Neural Information Processing Systems , year=
-
[72]
Eigenvalues of the
Sagun, Levent and Bottou, Leon and LeCun, Yann , journal=. Eigenvalues of the
-
[73]
Wide mean-field
Coker, Beau and Bruinsma, Wessel P and Burt, David R and Pan, Weiwei and Doshi-Velez, Finale , booktitle=. Wide mean-field. 2022 , organization=
2022
-
[74]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[75]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[76]
M. J. Kearns , title =
-
[77]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[78]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[79]
Suppressed for Anonymity , author=
-
[80]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[81]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.