When Does Synthetic Data Augmentation Improve Score-Based Imbalanced Classification?
Pith reviewed 2026-06-25 19:01 UTC · model grok-4.3
The pith
Under well-specified score models, synthetic augmentation cannot fundamentally improve population-level performance on imbalance metrics beyond possible variance reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under well-specified score models, the raw estimator already targets the likelihood-ratio ordering, which is population-optimal for the metrics considered. Consequently, augmentation cannot provide a fundamental population-level improvement beyond possible finite-sample variance reduction, and may introduce additional bias through synthetic distributional error. We further establish minimax lower bounds showing that the raw estimator already achieves the optimal metric-regret rate in the well-specified regime. Under misspecification, however, augmentation can play a qualitatively different role: by changing the effective class balance, it can alter the restricted-class projection and correct
What carries the argument
Decomposition of augmentation effects into effective class weighting change and synthetic-true minority distributional discrepancy, used to derive improvement conditions and bounds.
Load-bearing premise
The effect of augmentation can be separated into a change in effective class weighting and a discrepancy between the synthetic and true minority distributions.
What would settle it
A controlled simulation with a known well-specified score model where the augmented estimator's metric value is compared to the raw estimator after accounting for finite-sample variance; consistent outperformance by the augmented version would falsify the optimality claim.
Figures

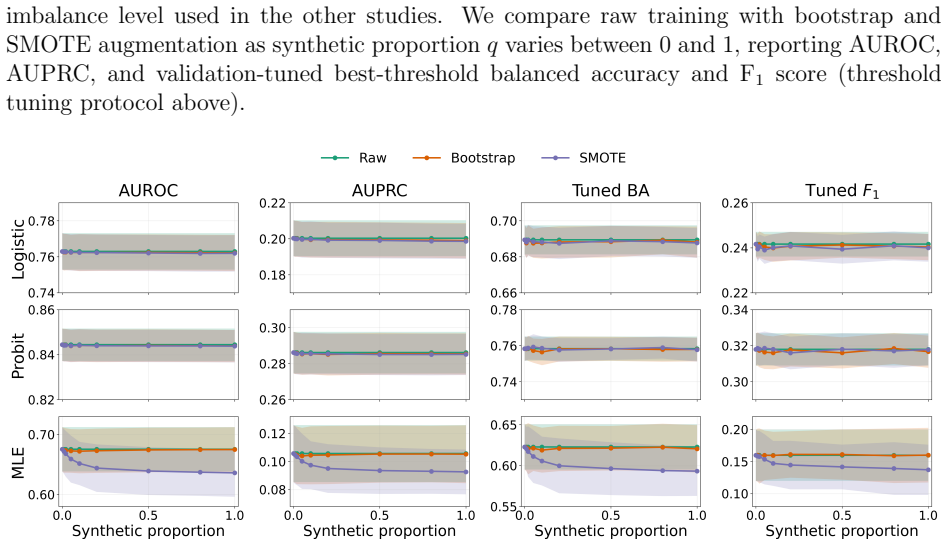
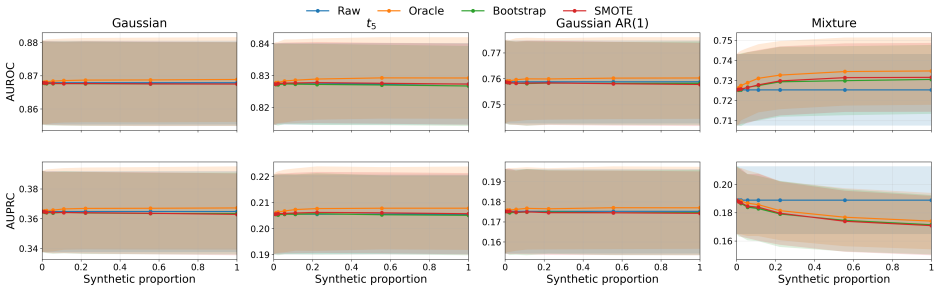
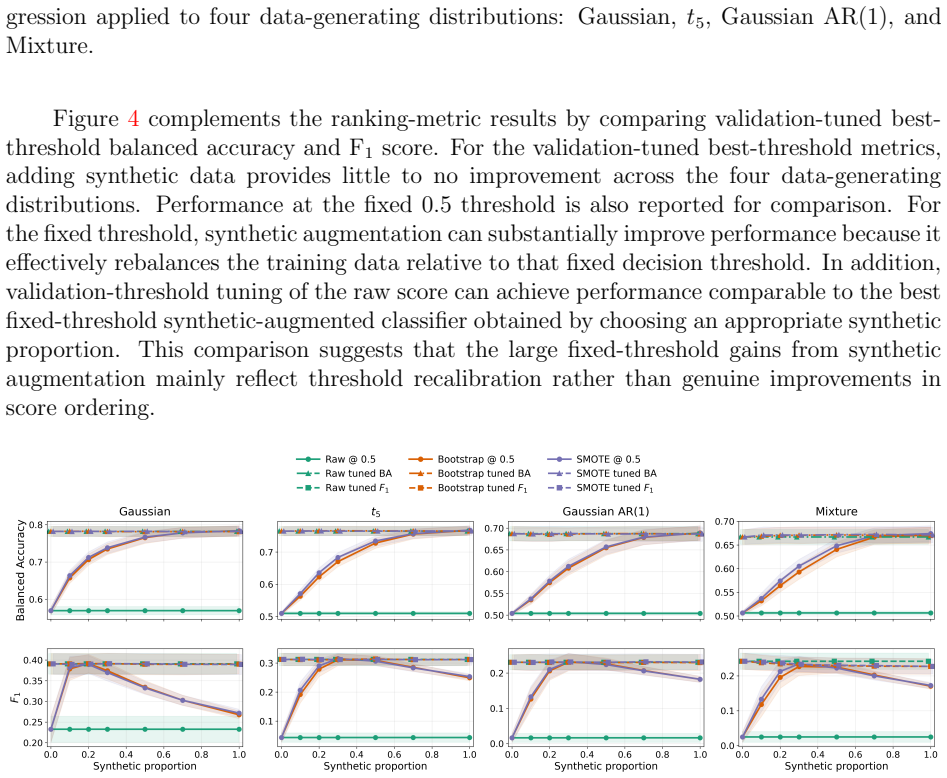

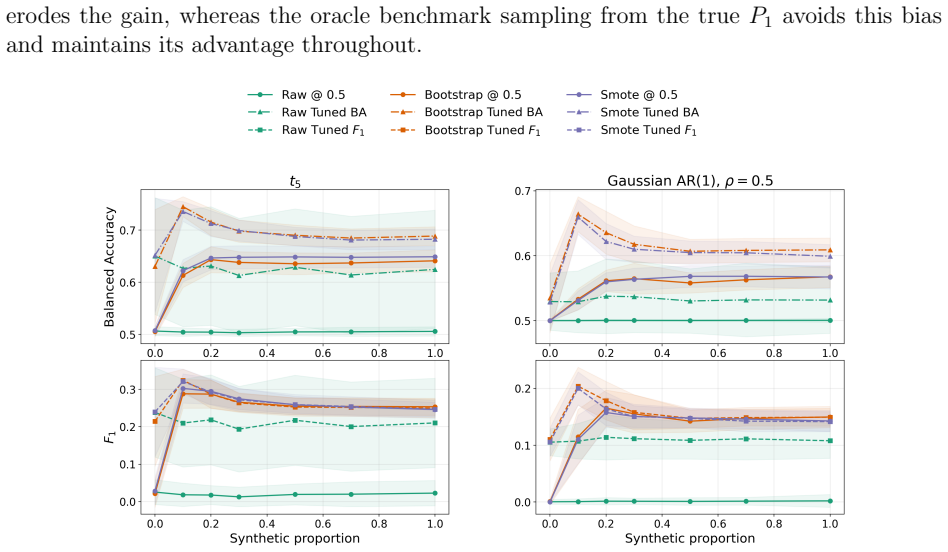
read the original abstract
Synthetic data augmentation is widely used to mitigate class imbalance, but its theoretical effects on score-based classification remain poorly understood. This paper develops a framework for characterizing when synthetic minority augmentation can improve threshold-integrated and threshold-optimized metrics, including AUROC, AUPRC, best-threshold balanced accuracy, and best-threshold \(\F_1\) score. We separate the effect of augmentation into two components: a change in effective class weighting and a discrepancy between the synthetic and true minority distributions. Under well-specified score models, the raw estimator already targets the likelihood-ratio ordering, which is population-optimal for the metrics considered. Consequently, augmentation cannot provide a fundamental population-level improvement beyond possible finite-sample variance reduction, and may introduce additional bias through synthetic distributional error. We further establish minimax lower bounds showing that the raw estimator already achieves the optimal metric-regret rate in the well-specified regime. Under misspecification, however, augmentation can play a qualitatively different role: by changing the effective class balance, it can alter the restricted-class projection and correct ranking errors induced by the raw imbalanced objective. We provide explicit improvement bounds quantifying the roles of approximation error, finite-sample estimation error, and synthetic distributional error. Simulation studies corroborate the theory, demonstrating limited gains under well-specification and nontrivial but nonmonotone improvements under misspecification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a framework for analyzing synthetic minority augmentation in score-based imbalanced classification. It decomposes augmentation effects into effective class weighting and synthetic-true minority distributional discrepancy. Under well-specified score models, the raw estimator targets the likelihood-ratio ordering (population-optimal for AUROC, AUPRC, best-threshold balanced accuracy, and F1), so augmentation yields no fundamental population-level gain beyond possible finite-sample variance reduction and may add bias; minimax lower bounds are established showing the raw estimator attains the optimal metric-regret rate. Under misspecification, augmentation can improve by altering the restricted-class projection and correcting ranking errors, with explicit bounds on approximation, estimation, and distributional errors. Simulations support the claims.
Significance. If the derivations hold, the work supplies rigorous conditions distinguishing when augmentation helps versus harms for these metrics, with practical implications for imbalanced learning. The population-level optimality argument, explicit improvement bounds, and minimax lower bounds (if verified) constitute a clear strength, offering falsifiable predictions grounded in standard MLE consistency rather than ad-hoc assumptions.
major comments (2)
- [Abstract and framework section] The decomposition into effective class weighting and distributional discrepancy (abstract) is load-bearing for both the well-specified optimality claim and the misspecification improvement bounds. If residual interaction terms between weighting and discrepancy remain after the separation, the explicit improvement bounds and the conclusion that augmentation cannot improve the ordering under well-specification do not follow.
- [Minimax analysis section] The minimax lower-bound claim (abstract) that the raw estimator achieves the optimal metric-regret rate relies on the population maximizer recovering the true likelihood ratio. The specific rate derivation and its dependence on the metric definitions (e.g., threshold-integrated vs. threshold-optimized) must be checked to ensure the bound is not an artifact of the well-specified parametric assumption.
minor comments (2)
- Clarify notation for the score model and the exact form of the metrics (AUROC, AUPRC, etc.) at first use to avoid ambiguity in the population vs. empirical distinction.
- [Simulation studies] The simulation section should report the precise degree of misspecification used and confirm that the observed nonmonotone improvements align quantitatively with the derived bounds.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract and framework section] The decomposition into effective class weighting and distributional discrepancy (abstract) is load-bearing for both the well-specified optimality claim and the misspecification improvement bounds. If residual interaction terms between weighting and discrepancy remain after the separation, the explicit improvement bounds and the conclusion that augmentation cannot improve the ordering under well-specification do not follow.
Authors: The decomposition in Section 3 is exact: the population limit of the augmented estimator separates additively into the effective weighting shift and the distributional discrepancy term, with all cross terms vanishing under the score-model normalization. This separation is used to establish both the well-specified optimality (no ordering improvement possible) and the misspecification improvement bounds. We will add one clarifying sentence in the framework section noting that the interaction terms are identically zero under the maintained assumptions. revision: partial
-
Referee: [Minimax analysis section] The minimax lower-bound claim (abstract) that the raw estimator achieves the optimal metric-regret rate relies on the population maximizer recovering the true likelihood ratio. The specific rate derivation and its dependence on the metric definitions (e.g., threshold-integrated vs. threshold-optimized) must be checked to ensure the bound is not an artifact of the well-specified parametric assumption.
Authors: The minimax lower bounds are derived under the well-specified parametric regime in which the MLE recovers the true likelihood ratio (the population maximizer for all four metrics). Separate regret rates are obtained for threshold-integrated metrics (AUROC, AUPRC) and threshold-optimized metrics (best-threshold balanced accuracy, F1), and the resulting lower bounds match the upper bounds attained by the raw estimator, confirming tightness rather than an artifact of the parametric assumption. revision: no
Circularity Check
No significant circularity; claims follow from standard MLE consistency under well-specification
full rationale
The paper's derivation separates augmentation into effective weighting and synthetic discrepancy components, then invokes the standard result that under correct score-model specification the MLE recovers the true likelihood-ratio ordering (population-optimal for the listed metrics). This is an external property of maximum-likelihood estimation, not a quantity fitted from the same data used to evaluate the metrics or defined in terms of the augmentation effect itself. The minimax lower-bound claim is presented as an information-theoretic consequence of that optimality, and the misspecification case is handled by explicit approximation-error bounds; none of these steps reduce by construction to the paper's own inputs or to self-citations whose content is unverified.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Score models are well-specified in the primary analysis regime
- domain assumption Augmentation effects separate into effective class weighting change and synthetic-true distribution discrepancy
Reference graph
Works this paper leans on
-
[1]
Journal of Big Data , volume=
Impact of random oversampling and random undersampling on the performance of prediction models developed using observational health data , author=. Journal of Big Data , volume=. 2024 , publisher=
2024
-
[2]
BMC bioinformatics , volume=
SMOTE for high-dimensional class-imbalanced data , author=. BMC bioinformatics , volume=. 2013 , publisher=
2013
-
[3]
Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence , year=
The Foundations of Cost-Sensitive Learning , author=. Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence , year=
-
[4]
Optimal Transport for Applied Mathematicians: Calculus of Variations, PDEs, and Modeling , author=
-
[5]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[6]
2019 , publisher=
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
2019
-
[7]
Journal of Chemical Information and Modeling , volume=
GHOST: adjusting the decision threshold to handle imbalanced data in machine learning , author=. Journal of Chemical Information and Modeling , volume=. 2021 , publisher=
2021
-
[8]
IEEE Access , volume=
Thors: An efficient approach for making classifiers cost-sensitive , author=. IEEE Access , volume=. 2019 , publisher=
2019
-
[9]
Journal of the American Statistical Association , volume=
Least ambiguous set-valued classifiers with bounded error levels , author=. Journal of the American Statistical Association , volume=. 2019 , publisher=
2019
-
[10]
The Annals of Statistics , pages=
Ranking and Empirical Minimization of U-Statistics , author=. The Annals of Statistics , pages=. 2008 , publisher=
2008
-
[11]
The Stata Journal , volume=
When to consult precision-recall curves , author=. The Stata Journal , volume=. 2020 , publisher=
2020
-
[12]
The Annals of Applied Statistics , year=
Boosting data analytics with synthetic volume expansion , author=. The Annals of Applied Statistics , year=
-
[13]
Nature , volume=
AI models collapse when trained on recursively generated data , author=. Nature , volume=. 2024 , publisher=
2024
-
[14]
arXiv preprint arXiv:2304.10283 , year=
Is augmentation effective to improve prediction in imbalanced text datasets? , author=. arXiv preprint arXiv:2304.10283 , year=
-
[15]
Advances in neural information processing systems , volume=
Modeling tabular data using conditional gan , author=. Advances in neural information processing systems , volume=
-
[16]
Statistica Sinica , volume=
One Step to Efficient Synthetic Data , author=. Statistica Sinica , volume=
-
[17]
arXiv preprint arXiv:2503.21968 , year=
GLM Inference with AI-Generated Synthetic Data Using Misspecified Linear Regression , author=. arXiv preprint arXiv:2503.21968 , year=
-
[18]
International Journal of Knowledge Engineering and Soft Data Paradigms , volume=
Borderline over-sampling for imbalanced data classification , author=. International Journal of Knowledge Engineering and Soft Data Paradigms , volume=. 2011 , publisher=
2011
-
[19]
Information Sciences , volume=
Geometric SMOTE a geometric-based synthetic oversampling method for imbalanced classification , author=. Information Sciences , volume=. 2019 , publisher=
2019
-
[20]
arXiv preprint arXiv:1711.00837 , year=
Oversampling for imbalanced learning based on K-means and SMOTE , author=. arXiv preprint arXiv:1711.00837 , year=
-
[21]
European conference on principles of data mining and knowledge discovery , pages=
SMOTEBoost: Improving prediction of the minority class in boosting , author=. European conference on principles of data mining and knowledge discovery , pages=. 2003 , organization=
2003
-
[22]
ACM SIGKDD explorations newsletter , volume=
A study of the behavior of several methods for balancing machine learning training data , author=. ACM SIGKDD explorations newsletter , volume=. 2004 , publisher=
2004
-
[23]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
A road to classification in high dimensional space: the regularized optimal affine discriminant , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2012 , publisher=
2012
-
[24]
Advances in neural information processing systems , volume=
On spectral clustering: Analysis and an algorithm , author=. Advances in neural information processing systems , volume=
-
[25]
IEEE journal of biomedical and health informatics , volume=
Synthetic patient data generation and evaluation in disease prediction using small and imbalanced datasets , author=. IEEE journal of biomedical and health informatics , volume=. 2022 , publisher=
2022
-
[26]
Nature Medicine , volume=
Self-improving generative foundation model for synthetic medical image generation and clinical applications , author=. Nature Medicine , volume=. 2025 , publisher=
2025
-
[27]
Nature Medicine , volume=
Generative models improve fairness of medical classifiers under distribution shifts , author=. Nature Medicine , volume=. 2024 , publisher=
2024
-
[28]
Journal of artificial intelligence research , volume=
SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary , author=. Journal of artificial intelligence research , volume=
-
[29]
arXiv preprint arXiv:2510.26046 , year=
Bias-Corrected Data Synthesis for Imbalanced Learning , author=. arXiv preprint arXiv:2510.26046 , year=
-
[30]
, author=
Estimating causal effects of treatments in randomized and nonrandomized studies. , author=. Journal of Educational Psychology , volume=. 1974 , publisher=
1974
-
[31]
Statistics in Medicine , volume=
Stratification and weighting via the propensity score in estimation of causal treatment effects: A comparative study , author=. Statistics in Medicine , volume=. 2004 , publisher=
2004
-
[32]
The Annals of Statistics , volume=
Semi-supervised inference: General theory and estimation of means , author=. The Annals of Statistics , volume=
-
[33]
2008 , organization=
He, Haibo and Bai, Yang and Garcia, Edwardo A and Li, Shutao , booktitle=. 2008 , organization=
2008
-
[34]
arXiv preprint arXiv:2502.11323 , year=
A statistical theory of overfitting for imbalanced classification , author=. arXiv preprint arXiv:2502.11323 , year=
-
[35]
Chawla, Nitesh V and Bowyer, Kevin W and Hall, Lawrence O and Kegelmeyer, W Philip , journal=
-
[36]
A theoretical distribution analysis of synthetic minority oversampling technique (
Elreedy, Dina and Atiya, Amir F and Kamalov, Firuz , journal=. A theoretical distribution analysis of synthetic minority oversampling technique (. 2024 , publisher=
2024
-
[37]
Do we need rebalancing strategies?
Sakho, Abdoulaye and Malherbe, Emmanuel and Scornet, Erwan , journal=. Do we need rebalancing strategies?
-
[38]
Asymptotic behavior of
Kamalov, Firuz , journal=. Asymptotic behavior of
-
[39]
New England Journal of Medicine , volume=
Machine learning in medicine , author=. New England Journal of Medicine , volume=. 2019 , publisher=
2019
-
[40]
Orphanet Journal of Rare Diseases , volume=
Diagnosis support systems for rare diseases: a scoping review , author=. Orphanet Journal of Rare Diseases , volume=. 2020 , publisher=
2020
-
[41]
2018 2nd International Conference on Data Science and Business Analytics (ICDSBA) , pages=
Effect of class imbalanceness in detecting automobile insurance fraud , author=. 2018 2nd International Conference on Data Science and Business Analytics (ICDSBA) , pages=. 2018 , organization=
2018
-
[42]
International Conference on Parallel Problem Solving from Nature , pages=
Improving imbalanced classification by anomaly detection , author=. International Conference on Parallel Problem Solving from Nature , pages=. 2020 , organization=
2020
-
[43]
Internet of Things , volume=
A machine learning based robust prediction model for real-life mobile phone data , author=. Internet of Things , volume=. 2019 , publisher=
2019
-
[44]
2020 11th International Conference on Information and Communication Systems (ICICS) , pages=
Machine learning with oversampling and undersampling techniques: Overview study and experimental results , author=. 2020 11th International Conference on Information and Communication Systems (ICICS) , pages=. 2020 , organization=
2020
-
[45]
A generalization of the k-
Tomek, Ivan , journal=. A generalization of the k-. 1976 , publisher=
1976
-
[46]
Journal of Machine Learning Research , volume=
Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning , author=. Journal of Machine Learning Research , volume=
-
[47]
1994 , publisher=
An introduction to the bootstrap , author=. 1994 , publisher=
1994
-
[48]
Borderline-
Han, Hui and Wang, Wen Yuan and Mao, Bing Huan , booktitle=. Borderline-. 2005 , organization=
2005
-
[49]
Safe-level-
Bunkhumpornpat, Chumphol and Sinapiromsaran, Krung and Lursinsap, Chidchanok , booktitle=. Safe-level-. 2009 , organization=
2009
-
[50]
arXiv preprint arXiv:2504.07426 , year=
Conditional data synthesis augmentation , author=. arXiv preprint arXiv:2504.07426 , year=
-
[51]
Zhang, Hongyi and Cisse, Moustapha and Dauphin, Yann N and Lopez-Paz, David , journal=
-
[52]
How does
Zhang, Linjun and Deng, Zhun and Kawaguchi, Kenji and Ghorbani, Amirata and Zou, James , journal=. How does
-
[53]
When and how
Zhang, Linjun and Deng, Zhun and Kawaguchi, Kenji and Zou, James , booktitle=. When and how. 2022 , organization=
2022
-
[54]
Obtaining well calibrated probabilities using
Naeini, Mahdi Pakdaman and Cooper, Gregory and Hauskrecht, Milos , booktitle=. Obtaining well calibrated probabilities using
-
[55]
The Annals of Statistics , pages=
Bayesian inference for causal effects: The role of randomization , author=. The Annals of Statistics , pages=. 1978 , publisher=
1978
-
[56]
Biometrika , volume=
The central role of the propensity score in observational studies for causal effects , author=. Biometrika , volume=. 1983 , publisher=
1983
-
[57]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey on transfer learning , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2009 , publisher=
2009
-
[58]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey on multi-task learning , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2021 , publisher=
2021
-
[59]
Machine Learning , volume=
Multitask learning , author=. Machine Learning , volume=. 1997 , publisher=
1997
-
[60]
Proceedings of the 27th ACM International Conference on Information and Knowledge Management , pages=
Imbalanced sentiment classification with multi-task learning , author=. Proceedings of the 27th ACM International Conference on Information and Knowledge Management , pages=
-
[61]
arXiv preprint arXiv:2509.23915 , year=
Revisit the Imbalance Optimization in Multi-task Learning: An Experimental Analysis , author=. arXiv preprint arXiv:2509.23915 , year=
-
[62]
Multi-modal multi-task learning for joint prediction of clinical scores in
Zhang, Daoqiang and Shen, Dinggang , booktitle=. Multi-modal multi-task learning for joint prediction of clinical scores in. 2011 , organization=
2011
-
[63]
Journal of the American Statistical Association , volume=
Analysis of semiparametric regression models for repeated outcomes in the presence of missing data , author=. Journal of the American Statistical Association , volume=. 1995 , publisher=
1995
-
[64]
Political Analysis , volume=
An introduction to the augmented inverse propensity weighted estimator , author=. Political Analysis , volume=. 2010 , publisher=
2010
-
[65]
2017 , publisher=
Classification and regression trees , author=. 2017 , publisher=
2017
-
[66]
2000 , publisher=
Finite mixture models , author=. 2000 , publisher=
2000
-
[67]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[68]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[69]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=
-
[71]
Advances in neural information processing systems , volume=
Generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[72]
Communications of the ACM , volume=
Generative adversarial networks , author=. Communications of the ACM , volume=. 2020 , publisher=
2020
-
[73]
International conference on machine learning , pages=
Variational inference with normalizing flows , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[74]
Auto-encoding variational
Kingma, Diederik P and Welling, Max , journal=. Auto-encoding variational
-
[75]
Survey on synthetic data generation, evaluation methods and
Figueira, Alvaro and Vaz, Bruno , journal=. Survey on synthetic data generation, evaluation methods and. 2022 , publisher=
2022
-
[76]
arXiv preprint arXiv:2302.04062 , year=
Machine learning for synthetic data generation: a review , author=. arXiv preprint arXiv:2302.04062 , year=
-
[77]
LeCun, Yann , journal=. The
-
[78]
arXiv preprint arXiv:2209.11215 , year=
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions , author=. arXiv preprint arXiv:2209.11215 , year=
-
[79]
, author=
The meaning and use of the area under a receiver operating characteristic (ROC) curve. , author=. Radiology , volume=
-
[80]
Pattern recognition letters , volume=
An introduction to ROC analysis , author=. Pattern recognition letters , volume=. 2006 , publisher=
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.